In a garment factory in India, workers are sorting fabrics as usual, but this time, they are equipped with cameras above their heads to record first-person videos of themselves working.
These videos will be processed into data assets and sold to embodied intelligence companies that need large amounts of data to train robots.
Starting this year, similar businesses are rapidly forming a new industrial chain, and the rise of this industrial chain stems from the biggest obstacle currently encountered by the embodied intelligence industry: data.
"Demand has clearly picked up this year," an industry insider involved in robot data collection told Radio 42. The European and American robotics companies his team serves are purchasing large amounts of human work data. Currently, the team has nearly 100 data collectors involved in robot training data production, consistently generating thousands of hours of human first-person perspective video data per month.
Data collectors need to follow standard procedures to complete tasks such as tidying clothes, organizing the kitchen, and grabbing items. During the process, they wear head-mounted cameras, and some tasks require the use of data gloves to record more precise hand movements.
"Previously, the industry was all about models and hardware, but now more and more people are asking, 'Can the data be supplied stably?'"
People began to clearly realize that the biggest problem was the insufficient scale of data, which prevented the model from making a breakthrough.
With the huge data gap in embodied models, a new business of data collection has begun to emerge rapidly.
Why are robots starting to lack data?
If we turn back the clock three years, robots were more like traditional automation industries.
Most robots are stationary in factories, with highly structured workflows: welding, handling, painting, and assembly. They do not need to understand complex environments or learn generalization abilities; they only need to repeat actions within predetermined trajectories.
Now, many companies are no longer aiming to create traditional industrial robots. From Tesla and Figure to PI, the industry is trying to train robots like large models, giving them general-purpose capabilities.
Therefore, the path taken by embodied models is becoming more and more like that of large language models (LLM), except that the path taken by embodied models is more difficult than that of LLM, especially in the field of data.
For LLM, the internet itself is a natural goldmine of data. The web pages, books, papers, code repositories, etc. accumulated over decades constitute a massive amount of training data. Model companies usually only need to solve the problem of how to filter and clean the data, and rarely need to create data from scratch.
But embodied models are different; they face the physical world, a data wasteland. Robot motion data doesn't arise out of thin air. Even though there are many videos of humans working on the internet, the amount of data is still insufficient for robots, and the overall quality is not high enough.
If LLM was born in a library, then robotics is more like being born in a desert.
Therefore, while AI has entered the stage of computing power competition and reasoning optimization, the embodied intelligence industry is still trapped in the most fundamental question: where does the data come from?
This is why, even with increasingly complex model architectures, robots are still a long way from truly entering homes and complex scenarios.
Because the model lacks sufficient real-world experience.
Previously, Figure founder Brett Adcock made a very direct point: "If we could just snap our fingers and cram all the massive amounts of data we really needed into the Helix model, we could immediately get general-purpose robots working."
The problem is, where does the data come from?
How is one hour's worth of data generated?
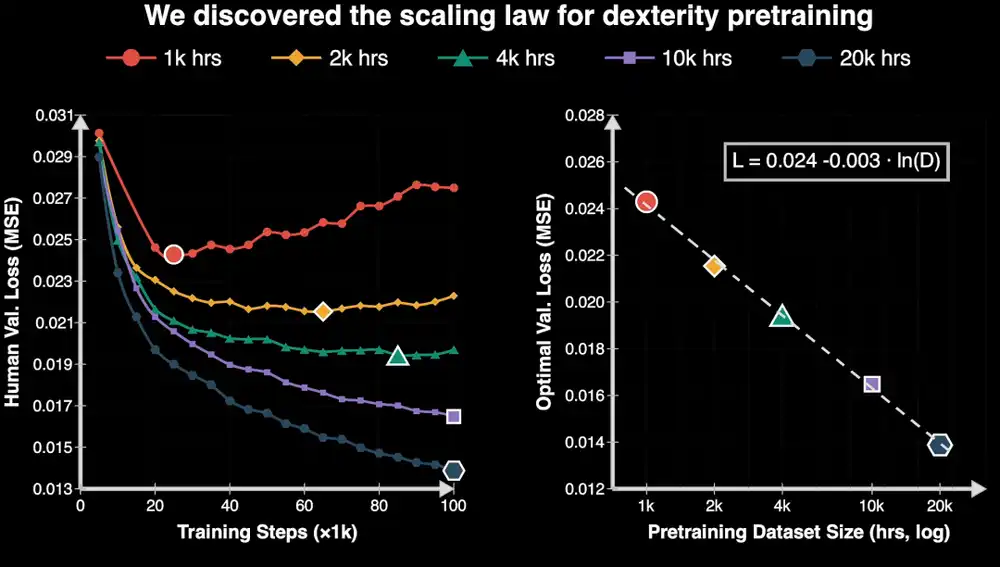
In February of this year, a research finding began to excite the industry.
NVIDIA's team released EgoScale, which, through over 20,000 hours of pre-trained models using human first-person perspective videos with motion annotations, and further fine-tuned with a small amount of robot data, enables the Sharpa Wave 22-DOF dexterous hand to perform tasks such as twisting bottle caps and folding clothes.

More importantly, the study found that as the scale of human data increases, the model's performance steadily improves, and this improvement is predictable.
This research is very important for the embodied industry, because a scaling data path means that the growth of robot capabilities has the potential to enter a positive cycle of "more data, more capabilities," just like large models.
For a long time, the embodied technology industry has been plagued by an anxiety: even with increased investment, improvements in model capabilities remain highly unpredictable. This is because real-world data is scarce and prohibitively expensive, deterring many from investing heavily in data analytics.
But EgoScale has proven one thing to some extent: at least with human first-person perspective data (Ego Data), scale can indeed bring stable benefits to dexterity manipulation.
At the same time, more and more robotics companies are moving towards a path of using a large amount of human data plus a small amount of robot data.
Human first-person perspective videos are responsible for showing the model how to complete the task, while robot data is responsible for teaching the model what its body should do.
Therefore, the main value of Ego Data is as a type of prior knowledge that is easier to scale, allowing robots to understand the physical world first, and then complete the adaptation with a small amount of real machine data.
As a result, the new industrial chain surrounding Ego Data has also begun to accelerate significantly this year.
Humans wear a camera on their head or chest and perform specific tasks, such as organizing clothes, tidying up the kitchen, or sorting packages. The camera records first-person perspective videos of the human working.
In a sense, humans are the most sophisticated general-purpose robots in the world. When entering a kitchen, a person naturally judges what to put in first and what to put in last, and if there is not enough space, they will use their other hand. When handling fragile items, they will subconsciously adjust the force applied.
Behind these seemingly instinctive actions lies a wealth of spatial understanding, task planning, and object interaction logic.
In the past, robots had almost never systematically acquired this kind of experience.

However, Ego Data doesn't just shoot videos randomly, and shooting a large enough amount of video isn't the biggest challenge. The key is how to turn these experiences into a data product that can be truly used by the model.
An industry professional who started accelerating the deployment of Ego Data this year told Radio 42 that the actual data collection usually begins with a task specification document sent by the client.
These types of documents don't simply state "collect kitchen organization data"; they usually include clear guidelines:
What is the task type? Do both hands have to be fully in the frame? Does the camera need to be positioned at the head or chest? Is it permissible to interrupt the action? How many environmental variations are needed? Are failure samples required? Does the final delivery format need to be compatible with the training framework?
For example, when tidying up a kitchen, a client might require that the process involve multiple steps in a continuous sequence, such as opening cabinet doors, finding containers, making room, taking and putting away items, and closing doors, without any skipping or significant obstruction.
In some ways, it's more like producing an industrial product, and the entire process at the collection site is far more "factory-like" than one might imagine.
In some data acquisition centers, data collectors take turns entering the prepared kitchen, cloakroom, and shelving areas to repeatedly perform tasks according to a unified standard operating procedure (SOP).
Some people are responsible for organizing clothes, some practice repeatedly grabbing items of different sizes, and others collect data on kitchen organization and moving.
The same action often needs to be repeated by people of different heights, with different dominant hands, and with different operating habits, in an attempt to exhaust all possible situations in the physical world. After all, robots ultimately face a complex real world, not a single standard answer.
When putting a cup into a cabinet, some people make room first, some switch hands, and some habitually open the cabinet door first. These subtle differences are precisely part of a robot's generalization ability.
Therefore, for many embodied models, what they need to learn is the logic of "how humans usually accomplish this task".
Compared to real device data, this type of data is easier to mass-produce. Given the huge demand in the industry, as long as the scale is sufficient and the labor costs are low, there is a basis for profitability and it is relatively easy to generate cash flow.
However, if the data does not meet the customer's requirements, rework is necessary. The actual amount of data that the customer approves is far less than the original shooting time, and the effective time that can be directly entered into the training process is more important.
From here, the industry gradually developed increasingly distinct stratifications. Because different types of data have vastly different values, a "data pyramid" can be roughly formed from a comprehensive perspective of cost, value, and other factors.
Different types of data have vastly different values.
In the "data pyramid", the bottom layer is internet data, which has almost no collection cost and is also quite large in scale.
Robots can learn what objects look like and the general layout of a kitchen from videos. But the problem is obvious: it can only help robots "know," not "do." The real challenge in the real world lies in movement, friction, weight, material changes, spatial constraints, and collision risks—all of which cannot be learned from ordinary videos alone.
Above that is a higher level of human data, and Ego Data is the most important part of it. It can tell the model how humans operate from a first-person perspective. This part of the video data can be used for pre-training on a large scale, just like what is done in EgoScale.
But robots ultimately need to figure out how their bodies should behave. For example, twisting a bottle cap is something a human can easily do, but a robot might fail repeatedly.
Therefore, the sensory data provided by data gloves is becoming increasingly important. Ordinary Ego Data can only tell the model what it has seen and what tasks it has completed. But ultimately, the robot also needs to know when to increase its intensity and when to relax.
These subtle movements are difficult to infer from videos alone, so more and more companies are starting to try to align hand motion capture, posture estimation, joint trajectory and visual data.
Video provides spatial understanding, gloves provide motion details, and remote control data from the actual machine further helps the robot understand how its body should perform its actions.

However, a very real problem remains in the industry: glove standards are still very inconsistent. Different devices vary greatly in sampling frequency, joint definition, accuracy, and motion representation methods. How to stably map human movements to different robot bodies remains a significant challenge.
Therefore, if you don't wear data gloves and only use a head-mounted camera to take pictures, the price of Ego Data is not too high. However, once you add data gloves, the price will rise rapidly.
Above the pyramid lies simulation data. Through a digital twin environment, robots can train at high speed in a virtual world, repeatedly undergoing millions of grasping, navigation, and obstacle avoidance maneuvers. The amount of data that would take a month to complete in reality can be processed in just a few days in the simulation environment.
However, simulation is ultimately not the real world. Although it is mass-produced and low-cost, it is difficult to completely replicate the friction, material changes, reflections and other accidental factors in reality. This is what the industry often refers to as the "Sim-to-Real Gap". Robots learn very well in simulation, but once they enter the real environment, their abilities are often greatly reduced.
At the top of the pyramid is the highest quality, most expensive, and rarest real machine data. This data is mainly obtained by operators remotely controlling the robot to complete specific tasks. The robot will simultaneously record vision, motion, control signals, and sensor status.
Unlike human data, it is naturally present in the robot's action space, so the model no longer needs to struggle to understand how human actions are mapped to the robot's body. In addition, real machine data also includes autonomous working data generated during application, but robots are not yet widely used, so the data they produce is also scarce.
Moreover, the key issue with real machine data is that production efficiency is very low. To increase the data scale, more robots and operators are needed, and there are also high costs for site and equipment depreciation, all of which will quickly drive up prices.
According to several industry insiders, the simplest Ego Data often costs only tens of yuan per hour, while the price of remotely controlled robot body data usually rises to hundreds or even thousands of yuan per hour.
In the training process of robot models from different manufacturers, the different layers of the data pyramid play different roles. As a result, upstream data companies with different focuses, such as simulation and human first-person perspective data, have emerged in the industry.
Who is trading this data?
When a massive industry emerges, the first to profit are often the upstream "water sellers".
The same is true for the embodied intelligence industry. In the past year or two, a large number of robotics startups have emerged globally, and talents from all walks of life are flocking to this field.
Almost every day, new companies announce the completion of financing, and more and more companies in China are being valued at tens of billions of yuan. Some companies have even embarked on the path of IPO. Turning our attention overseas, Figure has reached a valuation of $39 billion after completing its Series C financing last year, ranking first among humanoid robot companies.
Everyone wants to make general-purpose humanoid robots, and all of them need massive amounts of data. At the same time, due to the continuous influx of capital, the entire industry is not short of money.
Therefore, behind these companies with strong data needs and sufficient R&D funds, there are more and more "water sellers" in the upstream of the robotics industry, thus gradually forming a data production chain for the robotics industry.
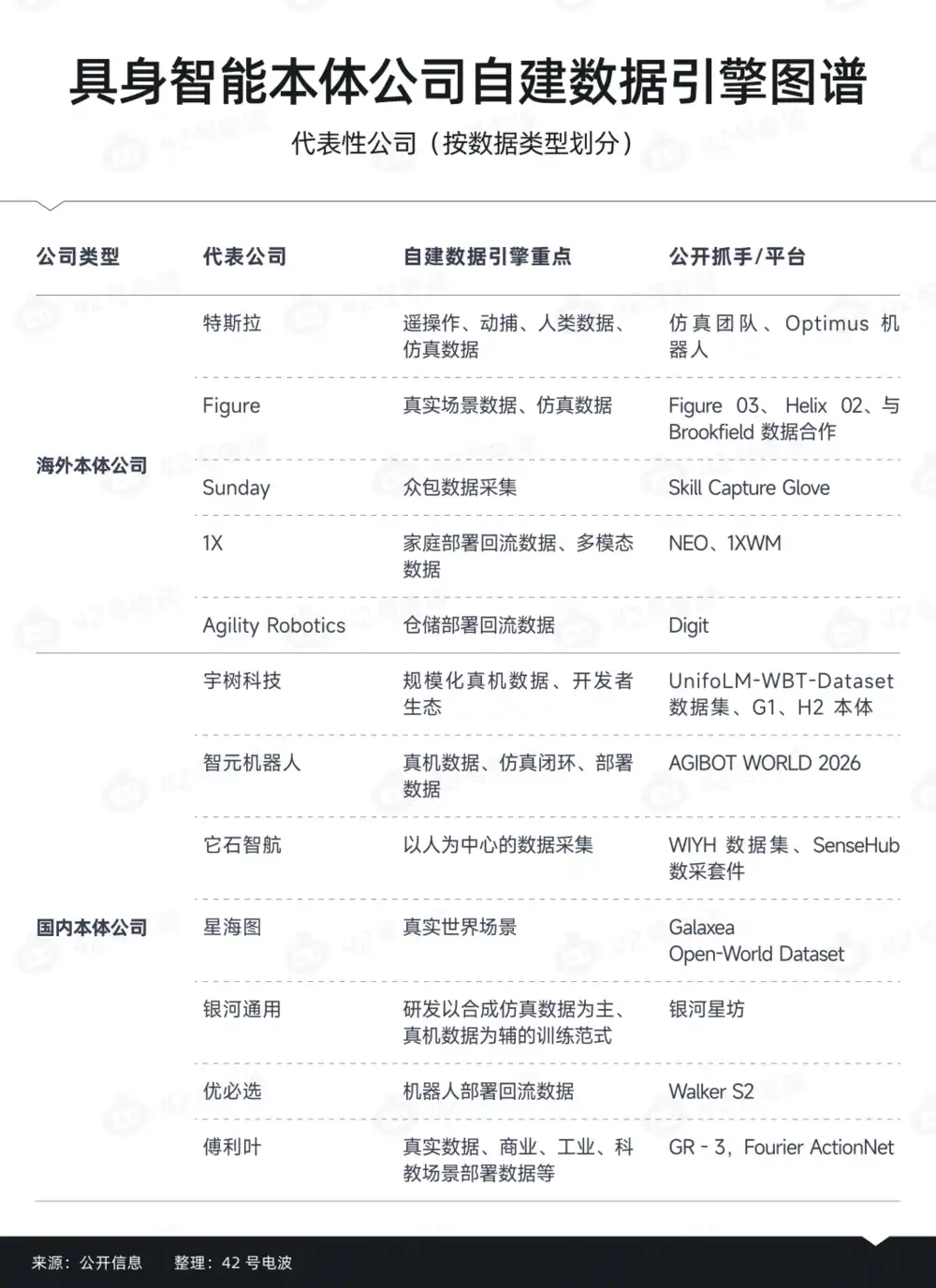
Moreover, as the industry develops, these upstream companies have begun to form a clear stratification around the data required for robot training. From the current industry structure, they can be roughly divided into five types of players.

The first type is low-cost data factories, which focus on collecting Ego Data. In India, Thailand, and other places, more and more teams are starting to organize low-cost labor to build data collection networks.
For example, a startup called Neocambrian AI recently launched a robotic data factory project in India to collect human motion data for embodied models. In particular, Ego Data's founder emphasized that India's large labor force is a major advantage for developing physical AI datasets.
Data collectors wear head-mounted cameras and motion capture gloves, complete their work according to the task flow, and then the back-end team cleans, labels, and accepts the data before finally delivering it to the robotics company.
In terms of business model, they are very similar to the data labeling companies that served large models in the early years, except that in the past they labeled text, images and voice, and now they are starting to produce physical world experiences.
An industry insider also told us that they have clearly felt an increase in demand from overseas clients over the past year. This is especially true for European and American robotics companies, "who are more specific about their data specifications and know exactly what they want."
Because robot data is not as simple as "shooting videos," many customers really need a set of data that can be directly integrated into the training pipeline, including time series, multi-view images, motion trajectories, sensor status, hand poses, environmental metadata, and finally, a suitable training format.
In this process, more and more companies are realizing that relying solely on low-cost labor is unlikely to create a long-term competitive advantage. In the future, the biggest competitive barrier for these low-cost data factories will depend on whether the delivered data can be used more easily and directly.
Moreover, the problem is also very real: this kind of business is naturally easy to commoditize. If one team can do it, another team can theoretically do it as well. As prices become more transparent, profit margins are often squeezed.
Therefore, their ability to deliver at low cost is their biggest advantage, but it may also become their ceiling.
The second category is motion capture and alignment layers. Compared to simply capturing video, these players are trying to solve the problem of "how the machine can truly understand the motion". Their focus is not just on the amount of data, but on the expression of the motion.
Examples include data gloves, motion capture, hand tracking, motion redirection, and operation acquisition interfaces.
The real challenge for robots often lies not in understanding what they do, but in how they move. Even when trying to grasp a cup, different robots have varying degrees of freedom in their dexterous hands, different finger structures, and different force control capabilities.
This raises a crucial question: how can human movements be stably mapped to different robot bodies?
Therefore, more and more companies are beginning to pay more attention to action retargeting. In this process, the video is responsible for telling the robot what the human did, while the action layer further answers what the robot should do.
The real value of this layer often lies not in the hardware itself, but in achieving more stable "motion translation".
The third category is the Robot-Native data layer, which is generally a third-party remote control and real device data service provider. The core characteristic of this type of player is that they are closer to the robot itself, and in many cases, they need to be deeply tied to the robot company.
Compared to other data collection sub-segments, real machine data relies heavily on a large number of specific robots. Different companies have different robot hardware, with significant differences in degrees of freedom, motion space, and control interfaces. Even for the same grasping task, a different robot may require re-collection.
During the process, they will provide remote operators, venues, and real machine data collection capabilities to help robotics companies quickly accumulate training data, especially in the early verification stage of models. When robotics companies themselves do not yet have enough teams and venues, external service providers can often get started faster.
The fourth category consists of simulation and synthetic data companies. They don't just sell data; their focus is on trying to create a more complete data capability.
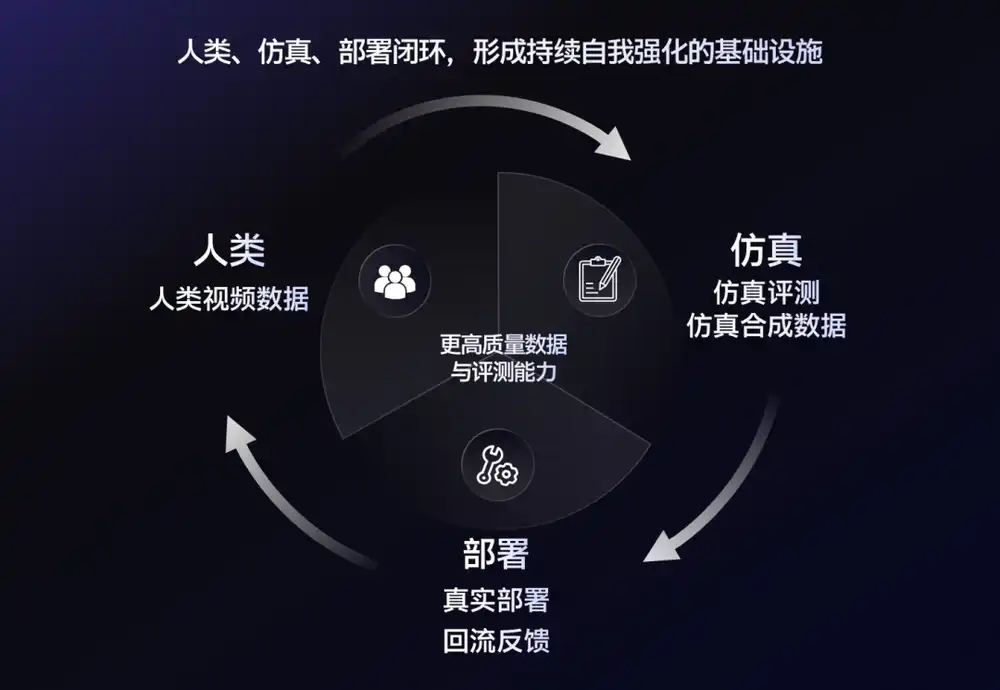
While generating data, they also help clients answer questions such as why robots fail to complete tasks and how to collect the next batch of data. This is a new approach that many companies are taking today.
The logic is simple: a robot might only accumulate a few hours of valid trajectories in a day of training. But in the simulated world, the same amount of time can be used for millions of failures, including grasping failures, path planning errors, collisions, and falls, all of which can be repeated indefinitely.
Therefore, the industry has gradually formed a new combination: real data is responsible for anchoring reality, while simulated synthetic data is responsible for scaling.
NVIDIA has repeatedly emphasized in its GR00T roadmap that the basic robot model requires not only human demonstration data but also a large amount of synthetic data. Developers can first obtain prior knowledge through real-world data collection and then expand the task scale with the help of simulation.
The more a model fails in simulation, the better it knows what data is missing, and whoever can produce this data the fastest has a greater chance of gaining an advantage.
The fifth type of player is more inclined towards data standards and platform layers, exploring how to make the data supply itself more standardized and easier to circulate while expanding the scale of data.
As the number of robotics companies increases, data becomes highly fragmented, with different collection methods, different action expressions, and different format standards. In many cases, the same data is even difficult to reuse directly.
Against this backdrop, attempts to standardize and collaboratively collect embodied data have increased significantly this year.
For the robotics industry today, the lack of data is only one problem; the ability to generate data consistently and stably, and to make it easier to incorporate into the training process, is equally crucial.
However, regardless of whether it's human data, real machine data, or simulation data, all data players ultimately have to answer this question: Will robotics companies hand over these core capabilities to external suppliers?
After all, for most embodied companies today, data is not only a cost, but also a barrier to entry.
Should robotics companies buy data or collect it themselves?
Entering this year, data has become increasingly important in the robotics industry, and everyone knows that robots lack data.
Compared to the past, there are now more and more data supply options on the market, with different data types having their own suppliers. For robotics companies, buying data is becoming increasingly easier.
However, the reality is somewhat different. On one hand, more and more robotics companies are starting to purchase data, while on the other hand, leading companies are desperately building their own data teams.
If you break it down further, you'll find that different data determine completely different organizational methods.
To some extent, what robotics companies have truly developed is a "tiered procurement" logic.
The first layer consists of basic, general data, which is the easiest layer to outsource.
For example, behaviors such as kitchen organization, table tidying, basic grasping, sorting, and moving have a common characteristic: regardless of what the robot looks like, it ultimately needs to understand how humans complete the tasks.
For example, when a robot enters the kitchen, when should it free up one hand first, when should it organize large objects first and then small objects, and how should the space be reorganized when there are too many items?
These abilities are essentially part of the general understanding of the physical world, and are not exclusive to any particular robot.
If you were to collect Ego data like this from scratch, you would need to build a team, which would result in high management costs.
In contrast, external teams can rapidly expand their data collection scale in regions such as Southeast Asia and India, and can stably produce thousands of hours per month.
For robotics companies, buying robots is often more cost-effective than building their own team. This is because at this stage, the goal is not to make the robots work reliably, but to understand the world first.
Therefore, outsourcing this type of data is a reasonable, and even more efficient, choice.
The second layer is personalized data, which robotics companies tend to collect themselves.
After pre-training with a large amount of basic data, the training then begins to involve the core aspect of the actual deployment of the robot: task alignment.
Therefore, the logic begins to change because the robots from different companies are very different in terms of their degrees of freedom, dexterity, and joint capabilities. Ultimately, the movement logic that the robots need to learn will also differ significantly.
The closer you get to the action execution layer, the less universal the data becomes. Therefore, many companies, despite purchasing large amounts of Ego Data, still build internal data collection teams to gather real-device data. This is because at this layer, the true competitiveness of the model begins to emerge.
The third layer consists of deployment data and failure data, which is a crucial layer and often occurs after actual deployment.
After robots are deployed in real-world application scenarios, they often encounter various unforeseen situations in their working environment. The deployment data generated in these real-world scenarios, whether successful or not, is extremely valuable. Moreover, these situations are rarely encountered in the initial data collection and are difficult to design in advance. They can only be accumulated little by little in the real environment.
Furthermore, many companies find it difficult to deploy their robots in large numbers in real-world scenarios, so real-world deployment data is out of the question.
During deployment, the robot continuously accumulates data in a variety of environments. Even failure data helps the team to identify the root causes and develop countermeasures to optimize the model and further promote the large-scale deployment of the robot.
These are core data points belonging to leading robotics companies, and they are also the barriers that differentiate them from their competitors.
This also limits the ceiling for data companies to some extent. They can help robots "get started," but the data that truly determines the upper limit of capabilities is something that many leading companies will ultimately choose to control themselves.
Therefore, the two different paths that have diverged in the data industry can be traced: one is the data factory, and the other is the data engine.
Data factories are currently the fastest-growing and most numerous type of company in the industry, and they are also the easiest to generate cash flow.
Among them, low-cost data factories place more emphasis on human behavior data, rely on the advantage of low-cost labor, charge by the hour, pursue scale and delivery capabilities, and may quickly turn positive cash flow. However, the barriers to entry are limited, and the number of competitors entering the market is increasing rapidly, especially after EgoScale, a large number of startups have begun to flock to human data.
More complex data factories, based on human behavior data, deploy robots in batches to collect large amounts of real machine data through remote control or autonomous operation.
Another approach attempts to create a data engine, which involves organizing a task classification system, building a data structure, implementing action redirection, connecting to a simulation platform, implementing model evaluation, and iteratively generating datasets based on model failure samples.
In other words, what they are doing is not just selling data, but focusing on enabling robots to continuously become smarter.
Will a robotic version of Scale AI emerge?
If we place today's robotics industry back into the grand scheme of 2022, we'll find a striking similarity.
The industry at the time also discovered that what truly determines the upper limit of a model's capabilities is data.
As a result, a number of new companies have emerged rapidly in the fields of data cleaning, RLHF, evaluation, and post-training, the most classic example being Scale AI.
This company helped autonomous driving companies label data in the early stages. Starting in 2019, Scale AI was deeply integrated with OpenAI in the GPT-2 stage, undertaking RLHF human feedback labeling, large model evaluation, red team testing, and reverse engineering of edge cases to generate data.
After ChatGPT became a hit, Meta Llama, Anthropic, Microsoft Azure and other companies quickly adopted it. The demand for high-quality annotation, evaluation and synthetic data for large models surged, and the company's revenue more than quadrupled in 3 years.
Later, the company gradually moved into deeper infrastructure layers, such as data management, model evaluation, and AI workflow.
Because of Scale AI's success, many people are wondering if a similar company will emerge in the robotics industry.
Given the current shortage of data, it is very likely, but not entirely possible, to replicate.
Because the data required by robots is much more complex than text, it is relatively easy to determine whether an answer is right or wrong for large models. However, in the world of robots, whether an action is successful is often full of ambiguity.
The cup was picked up, but at the wrong angle. The item was put back, but it knocked over other objects. And often, there are multiple correct paths to complete a task.
Therefore, what the robotics industry truly needs is not a simple data platform, but rather a complete data loop encompassing data collection, annotation, motion mapping, simulation augmentation, model evaluation, and failure feedback.
What robots truly lack is not just data, but even more so the ability to continuously generate effective experience.
Therefore, more and more companies are shifting their competitive focus from robot bodies and model architecture to data systems.
Since the beginning of this year, whether it's Figure, 1X, PI, or NVIDIA's GR00T roadmap, they have all repeatedly emphasized a common direction: increasing robot capabilities. Hardware upgrades are only part of the equation; more data and more effective training are becoming the main drivers.
To some extent, with the start of mass production and implementation in the robotics industry, we are moving from "building machines" to a new era of "feeding machines."
At a stage where robots cannot stand up or walk, the biggest competitive advantage of embodied companies lies in their ability to master hardware and motion control.
However, when robots can run and jump, and their performance in many competitions surpasses that of humans, the ability to work autonomously becomes the industry's biggest goal. Driven by this goal, the industry's main focus has become large-scale, high-quality data.
For robots to succeed in the complex real world, they need to encounter enough real-world tasks in physical space, to know that cups might be knocked over, clothes might get tangled, and space might be insufficient. This experience does not exist naturally on the internet; it can only be produced little by little.
Therefore, this data industry chain has quietly taken shape behind the robot craze of the past two years.
At one end of the chain are humans wearing cameras in an Indian factory and robots that keep falling down in a simulation.
On the other end are robotics companies valued at billions, tens of billions, or even hundreds of billions of dollars, which are trying to bring robots into homes and factories.
From India's data factories and robots in simulation to major robotics companies around the world, a new production chain has begun to take shape. This time, however, what is being produced is not parts, but data.
This article is from the WeChat Official Account: Radio Wave 42 , author: Lan Bo, editor: James, original title: "Robots Start 'Eating Data': From India's Data Factory to the Hidden Production Chain of Multi-Billion Dollar Humanoid Robots"