

OpenAI가 SearchGPT를 출시한 지 며칠 되지 않아 오픈 소스 버전도 나왔습니다.
홍콩 중문대학교 MMLab, 상하이 AI Lab, 텐센트 팀이 Vision Search Assistant를 간단히 구현했습니다. 모델 설계가 간단해 2대의 RTX3090으로도 구현할 수 있습니다.

Vision Search Assistant(VSA)는 비주얼 언어 모델(VLM)을 기반으로 웹 검색 기능을 巧妙하게 융합하여 VLM 내부의 지식을 실시간으로 업데이트하여 더 유연하고 지능적으로 만들었습니다.
현재 VSA는 일반 이미지에 대한 실험을 진행했으며, 시각화와 정량화 결과가 좋습니다. 그러나 다양한 유형의 이미지(예: 표, 의료 등)에 대해 더 특화된 VSA 애플리케이션을 구축할 수 있습니다.
더욱 고무적인 것은 VSA의 잠재력이 이미지 처리에만 국한되지 않는다는 것입니다. 비디오, 3D 모델, 음성 등 더 광범위한 영역을 탐구할 수 있어 멀티모달 연구를 새로운 높이로 끌어올릴 것으로 기대됩니다.

VLM이 이전에 보지 못한 이미지와 새로운 개념을 처리하게 하기
대규모 언어 모델(LLM)의 등장으로 인간은 모델의 강력한 제로 샷 질문 답변 능력을 활용하여 생소한 지식을 얻을 수 있게 되었습니다.
이를 기반으로 검색 증강 생성(RAG) 등의 기술이 LLM의 지식 집약적이고 개방형 질문 답변 작업 성능을 더욱 향상시켰습니다. 그러나 VLM은 이전에 보지 못한 이미지와 새로운 개념에 직면할 때 인터넷의 최신 멀티모달 지식을 잘 활용하지 못했습니다.
기존의 웹 에이전트는 주로 사용자 질문에 대한 검색에 의존하고 검색 결과의 HTML 텍스트 내용을 요약하기 때문에, 이미지 또는 기타 시각적 콘텐츠가 포함된 작업을 처리할 때 명백한 한계가 있습니다. 즉, 시각 정보가 무시되거나 충분히 처리되지 않습니다.
이 문제를 해결하기 위해 팀은 Vision Search Assistant를 제안했습니다. Vision Search Assistant는 VLM 모델을 기반으로 하며, 사람이 인터넷에서 검색하고 문제를 해결하는 과정과 유사하게 이전에 보지 못한 이미지나 새로운 개념에 대한 질문에 답변할 수 있습니다. 이 과정에는 다음이 포함됩니다:
- 질문 이해
- 이미지에서 어떤 객체에 초점을 맞추고 객체 간 관련성을 추론해야 할지 결정
- 객체별로 질의 텍스트 생성
- 질의 텍스트와 추론된 관련성을 바탕으로 검색 엔진 결과 분석
- 검색 결과의 시각 및 텍스트 정보가 답변을 생성하기에 충분한지 판단하고, 필요하다면 위 과정을 반복 및 개선
- 검색 결과를 종합하여 사용자 질문에 답변
시각적 콘텐츠 설명
시각적 콘텐츠 설명 모듈은 이미지의 객체 수준 설명과 객체 간 관련성을 추출하는 데 사용됩니다. 그 프로세스는 다음과 같습니다.
먼저 오픈 도메인 감지 모델을 사용하여 주목할 만한 이미지 영역을 얻습니다. 그런 다음 각 감지된 영역에 대해 VLM을 사용하여 객체 수준의 텍스트 설명을 얻습니다.
마지막으로, 시각적 콘텐츠를 더 완전히 표현하기 위해 VLM을 사용하여 다른 시각 영역과의 관련성을 통해 각 영역의 설명을 개선합니다.

구체적으로, 사용자 입력 이미지를 , 사용자 질문을 라고 하자. 오픈 도메인 감지 모델 을 통해 개의 관심 영역을 얻을 수 있습니다:
그런 다음 사전 학습된 VLM 모델 을 사용하여 이 개 영역의 시각적 콘텐츠를 각각 설명합니다:
서로 다른 영역의 정보를 연관시켜 설명의 정확도를 높이기 위해, 영역 의 설명에 다른 영역 의 설명을 결합하여 VLM이 영역 의 설명을 수정하도록 할 수 있습니다:
이로써 사용자 입력으로부터 개의 관련 시각 영역에 대한 정확한 설명 를 얻을 수 있습니다.
웹 지식 검색: "검색 체인"
웹 지식 검색의 핵심은 "검색 체인"이라는 반복 알고리즘으로, 관련 시각 설명에 대한 종합적인 웹 지식을 얻는 것을 목표로 합니다. 그 프로세스는 다음과 같습니다.

Vision Search Assistant에서는 LLM을 사용하여 답변과 관련된 하위 질문을 생성하는데, 이를 "계획 에이전트"라고 합니다. 검색 엔진이 반환한 페이지는 동일한 LLM으로 분석, 선택 및 요약되며, "검색 에이전트"로 불립니다. 이를 통해 시각적 콘텐츠와 관련된 웹 지식을 얻을 수 있습니다.
구체적으로, 검색은 각 영역의 시각적 콘텐츠 설명별로 수행되므로, 영역 를 예로 들면(상첨자 생략), 이 모듈에서는 동일한 LLM 모델 를 사용하여 계획 에이전트와 검색 에이전트를 구축합니다. 계획 에이전트는 전체 검색 체인 프로세스를 제어하고, 검색 에이전트는 검색 엔진과 상호 작용하여 웹 페이지 정보를 필터링하고 요약합니다.
첫 번째 반복을 예로 들면, 계획 에이전트는 질문 를 개의 하위 검색 질문 로 분할하여 검색 에이전트에게 전달합니다. 검색 에이전트는 각 를 검색 엔진에 제출하고 가장 관련성 높은 페이지 집합(인덱스 집합 )을 얻습니다.
선택된 이 페이지들에 대해 검색 에이전트는 내용을 자세히 읽고 요약합니다:
마지막으로, 개 하위 질문의 요약이 계획 에이전트에게 전달되어 첫 번째 반복 후의 웹 지식 가 생성됩니다.
이 반복 과정을 번 반복하거나 계획 에이전트가 현재 웹 지식으로 원래 질문에 답변할 수 있다고 판단하면 검색 체인이 중지되어 최종 웹 지식 가 얻어집니다.
협력 생성
마지막으로, 원본 이미지 , 시각적 설명 , 웹 지식 를 바탕으로 VLM을 사용하여 사용자 질문 에 답변합니다. 구체적인 최종 답변 는 다음과 같습니다.

실험 결과
개방형 질문 답변 시각화 비교
아래 그림은 새로운 이벤트(상위 2행)와 새로운 이미지(하위 2행)에 대한 개방형 질문 답변 결과를 비교한 것입니다.
Vision Search Assistant와 Qwen2-VL-72B, InternVL2-76B를 비교했는데, Vision Search Assistant가 더 최신, 정확, 자세한 결과를 생성하는 것을 알 수 있습니다.
예를 들어, 첫 번째 예에서 Vision Search Assistant는 2024년 Tesla 회사 상황을 요약했지만, Qwen2-VL은 2023년 정보에 국한되었고, InternVL2는 해당 회사의 최신 상황을 제공할 수 없다고 명시했습니다.

개방형 질문 답변 평가
개방형 질문 답변 평가에서 총 10명의 인간 전문가가 2022년 7월 15일부터 9월 25일 사이 뉴스에서 수집한 100개의 이미지-텍스트 쌍(새로운 이미지와 이벤트 포함)을 대상으로 비교 평가를 수행했습니다.
인간 전문가는 진실성, 관련성, 지원성의 3가지 핵심 차원에서 평가했습니다.
아래 그림과 같이 Perplexity.ai Pro와 GPT-4-Web에 비해 Vision Search Assistant가 모든 차원에서 우수한 성능을 보였습니다.
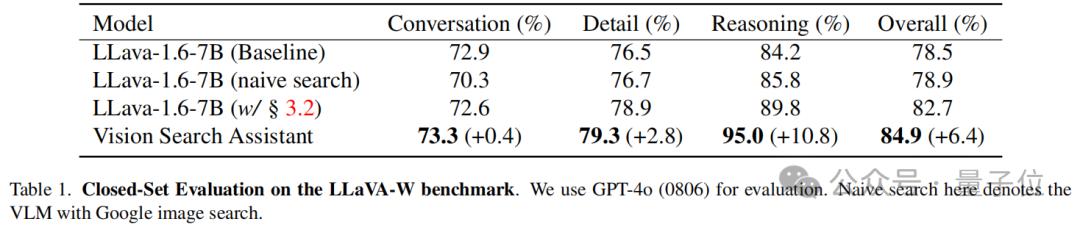
 모델을 사용하여 평가를 수행했으며, 기준 모델로 LLaVA-1.6-7B를 사용했습니다. 이 모델은 표준 모드와 간단한 Google 이미지 검색 구성 요소를 사용하는)
또한 검색 체인 모듈이 장착된 LLaVA-1.6-7B의 향상된 버전도 평가되었습니다.
표에서 볼 수 있듯이, Vision Search Assistant가 모든 범주에서 가장 강력한 성능을 보였습니다. 구체적으로 대화 범주에서 73.3%의 점수를 얻어 LLaVA 모델보다 약간 향상되었습니다(+0.4%). 세부 사항 범주에서는 79.3%의 점수로 가장 좋은 LLaVA 변형보다 +2.8% 높았습니다.
추론 측면에서는 VSA 방법이 최고의 LLaVA 모델보다 +10.8% 높았습니다. 이는 Vision Search Assistant의 시각적 및 텍스트 검색에 대한 고급 통합이 추론 능력을 크게 향상시켰음을 보여줍니다.
Vision Search Assistant의 전반적인 성능은 84.9%로, 기준 모델보다 +6.4% 향상되었습니다. 이는 Vision Search Assistant가 대화 및 추론 작업에서 뛰어난 성능을 보여 야외 질문 답변 능력에서 명확한 우위를 가지고 있음을 나타냅니다.
논문: https://arxiv.org/abs/2410.21220
홈페이지: https://cnzzx.github.io/VSA/
코드: https://github.com/cnzzx/VSA
이 기사는 WeChat 공식 계정 "量子位"에서 가져온 것이며, 저자는 VSA 팀이고 36Kr의 승인을 받아 게시되었습니다.





