저자: 사원,기술 뉴스

이미지 출처: 무한 AI에 의해 생성됨
AI 시대에 사용자가 입력한 정보는 더 이상 개인 정보만이 아니라 대형 모델 발전의 '디딤돌'이 되었습니다.
"PPT 좀 만들어 주세요", "새해 포스터 좀 만들어 주세요", "문서 내용 좀 정리해 주세요", 대형 모델이 유행하면서 AI 도구를 활용한 업무 효율화가 화이트칼라들의 일상이 되었고, 심지어 음식 배달이나 호텔 예약에도 AI를 이용하는 사람들이 늘고 있습니다.
그러나 이러한 데이터 수집과 사용 방식은 큰 프라이버시 위험을 초래하고 있습니다. 많은 사용자들이 디지털 시대에 디지털 기술과 도구를 사용하면서 겪는 주요 문제인 투명성 부족을 간과하고 있습니다. 이들은 이러한 AI 도구들이 어떻게 데이터를 수집, 처리, 저장하는지 알지 못하며, 데이터가 악용되거나 유출되는지 확실하지 않습니다.
올해 3월, OpenAI는 ChatGPT에 취약점이 있어 일부 사용자의 과거 채팅 기록이 유출되었다고 인정했습니다. 이 사건은 대형 모델의 데이터 보안과 개인 정보 보호에 대한 대중의 우려를 불러일으켰습니다. ChatGPT 데이터 유출 사건 외에도 Meta의 AI 모델이 저작권을 침해했다는 논란이 있었습니다. 올해 4월 미국 작가, 예술가 등이 Meta의 AI 모델이 그들의 저작물을 훈련에 무단 사용했다고 고소했습니다.
국내에서도 유사한 사건이 발생했습니다. 최근 아이치와 '대형 모델 6소녀' 중 하나인 희우 과학기술(MiniMax)이 저작권 분쟁으로 주목을 받았습니다. 아이치는 해초 AI가 허가 없이 자사의 저작권 소재를 모델 훈련에 사용했다고 고소했으며, 이는 국내 최초의 동영상 플랫폼과 AI 동영상 대형 모델 간 저작권 침해 소송입니다.
이러한 사건들은 대형 모델 훈련 데이터의 출처와 저작권 문제에 대한 외부의 관심을 불러일으켰으며, AI 기술 발전은 사용자 프라이버시 보호를 기반으로 이루어져야 한다는 점을 보여줍니다.
현재 국내 대형 모델의 정보 공개 투명성 현황을 파악하기 위해 「기술 뉴스」는 두부, 문심일언, kimi, 텐센트 혼원, 별화 대형 모델, 통의천문, 콰이셔우 가능 등 7개 주요 대형 모델 제품을 샘플로 선정하여 개인정보 정책과 사용자 계약, 제품 기능 설계 경험 등을 평가했습니다. 그 결과 많은 제품들이 이 부분에서 뛰어나지 않은 것으로 나타났으며, 사용자 데이터와 AI 제품 간의 민감한 관계를 명확히 볼 수 있었습니다.
01. 철회권은 형식적
첫째, 「기술 뉴스」는 로그인 페이지에서 7개 국내 대형 모델 제품 모두가 인터넷 앱의 '표준' 사용 계약과 개인정보 정책을 따르고 있으며, 개인정보 정책 문서에도 다양한 장에서 개인 정보 수집 및 사용 방식을 설명하고 있음을 확인했습니다.
이들 제품의 설명도 대체로 일치하는데, "서비스 경험 최적화 및 개선을 위해 사용자의 출력 내용 피드백과 사용 과정의 문제점 등을 활용할 수 있습니다. 안전한 암호화 기술 처리와 엄격한 익명화 전제 하에 사용자가 AI에 입력한 데이터, 내린 명령, AI가 생성한 응답, 제품 접속 및 사용 정보 등을 분석하여 모델 훈련에 활용할 수 있습니다."
실제로 사용자 데이터를 활용해 제품을 개선하고 다시 사용자에게 제공하는 것은 긍정적인 순환이지만, 사용자가 관심을 가지는 것은 이러한 데이터 '제공'을 거부하거나 철회할 수 있는지 여부입니다.
「기술 뉴스」가 이 7개 AI 제품을 살펴본 결과, 두부, 시아오펑, 통의천문, 가능 등 4개 업체만이 개인정보 조항에서 "개인정보 수집 범위를 변경하거나 승인을 철회할 수 있다"고 명시했습니다.
두부의 경우 주로 음성 정보의 철회 승인에 집중되어 있는데, "음성 정보를 모델 훈련 및 최적화에 사용하고 싶지 않다면 '설정'-'계정 설정'-'음성 서비스 개선'에서 승인을 철회할 수 있습니다." 그러나 다른 정보에 대해서는 공개된 연락처로 문의해야 데이터 사용 승인을 변경할 수 있습니다.

출처 / (두부)
실제 사용 과정에서 음성 서비스 승인 취소는 어렵지 않지만, 다른 정보에 대한 사용 승인 철회의 경우 「기술 뉴스」가 두부 측에 문의했음에도 답변을 받지 못했습니다.
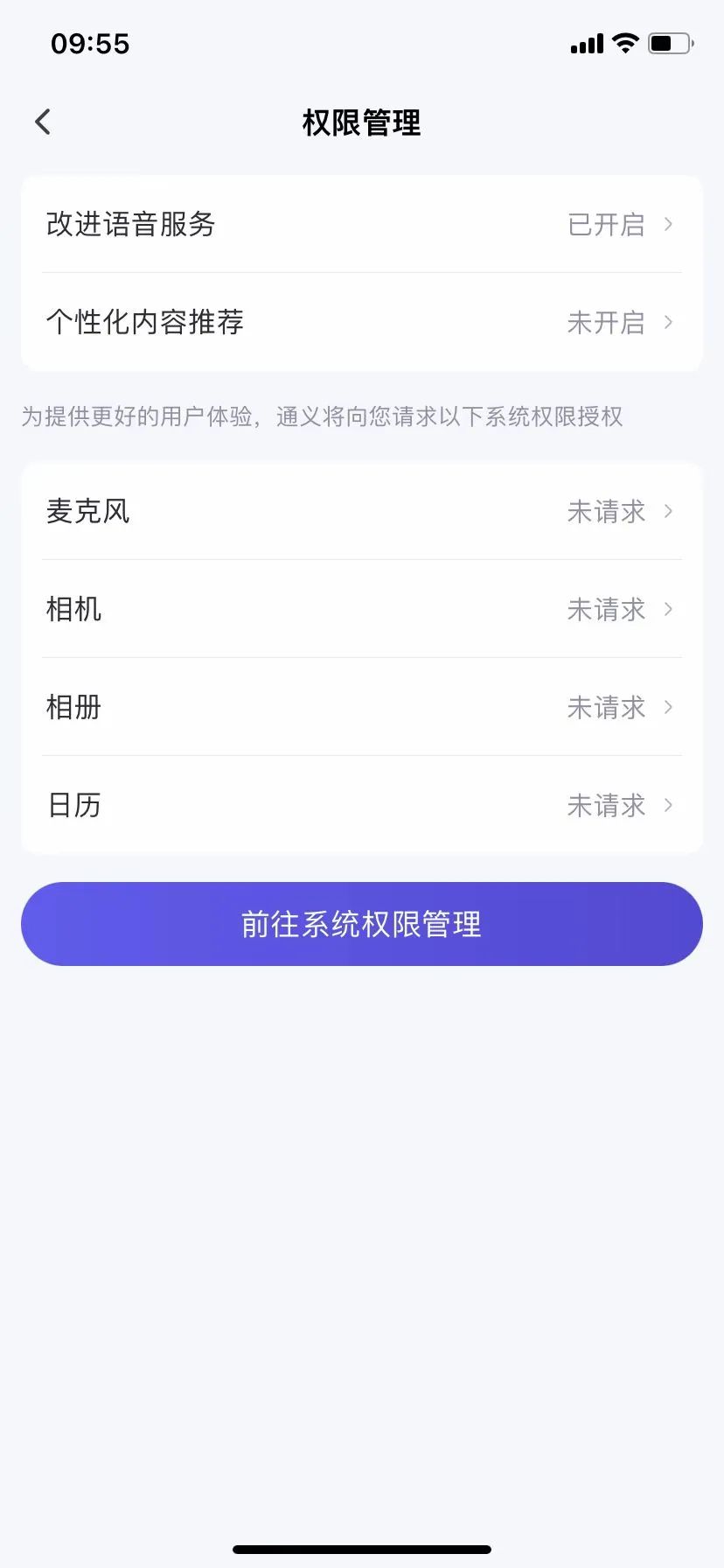
출처 / (두부)
통의천문도 두부와 유사하게 음성 서비스 승인 철회만 가능하고, 다른 정보에 대해서는 공개된 연락처로 문의해야 한다고 명시했습니다.

출처 / (통의천문)
가능은 얼굴 사용과 관련해 "사용자의 얼굴 화소 정보를 다른 용도로 사용하거나 제3자와 공유하지 않는다"고 밝혔지만, 승인 철회를 위해서는 이메일로 문의해야 한다고 했습니다.

출처 / (가능)
두부, 통의천문, 가능과 달리 시아오펑 별화의 요구 사항은 더 엄격합니다. 사용자가 개인정보 수집 범위를 변경하거나 철회하려면 계정 삭제 절차를 거쳐야 합니다.

출처 / (시아오펑 별화)
주목할 만한 점은 텐센트 원보의 경우 조항에 철회 방법이 명시되어 있지 않지만, 앱 내에 "음성 기능 개선 프로그램" 스위치가 있다는 것입니다.

출처 / (텐센트 원보)
Kimi는 개인정보 정책에서 음성 정보의 제3자 공유를 철회할 수 있다고 명시했지만, 「기술 뉴스」가 오랫동안 찾아봐도 관련 설정 메뉴를 찾지 못했습니다. 문자 정보에 대한 철회 조항도 찾을 수 없었습니다.

출처 / (Kimi 개인정보 정책)
실제로 주요 대형 모델 애플리케이션을 살펴보면, 각 업체는 사용자의 음성 정보 관리에 더 신경 쓰고 있음을 알 수 있습니다. 두부, 통의천문 등은 자체적으로 승인을 취소할 수 있지만, 위치, 카메라, 마이크 등 특정 상호작용 상황에서의 기본 승인은 자체적으로 차단할 수 있어도 '제공'한 데이터를 철회하는 것은 그렇지 않습니다.
주목할 만한 점은 해외 대형 모델에서도 유사한 방식을 취하고 있다는 것입니다. 구글의 Gemini 관련 조항은 "향후 대화 내용을 검토하거나 Google의 기계 학습 기술 개선에 사용하고 싶지 않다면 Gemini 앱 활동 기록을 끄세요."라고 명시하고 있습니다.
또한 Gemini는 사용자가 자신의 앱 활동 기록을 삭제하더라도 이미 인간 검토자에 의해 검토되거나 주석이 달린 대화 내용(언어, 기기 유형, 위치 정보, 피드백 등 관련 데이터 포함)은 삭제되지 않으며, 최대 3년간 보관된다고 밝혔습니다.
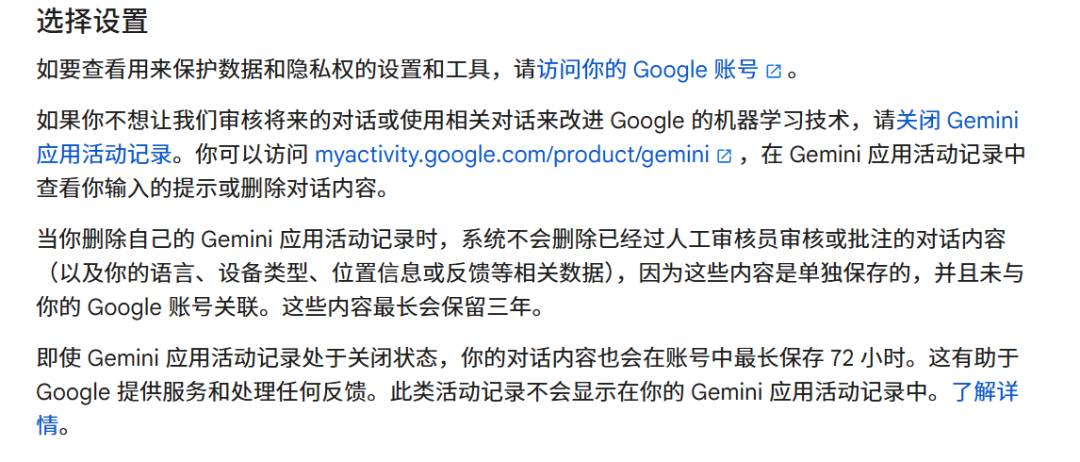
출처 / (Gemini 약관)
ChatGPT의 규정은 다소 모호한데, 사용자가 개인 데이터 처리를 제한할 권리가 있다고 명시했지만, 실제 사용 시 Plus 사용자는 데이터 훈련 사용을 금지할 수 있지만 무료 사용자의 경우 데이터가 기본적으로 수집 및 활용되며, 이를 거부하려면 별도로 연락해야 합니다.

출처 / (ChatGPT 약관)
이러한 대형 모델 제품의 약관을 살펴보면, 사용자 입력 정보 수집이 이미 공통적인 관행이 된 것 같습니다. 다만 음성, 얼굴 등 더 민감한
在严格管控的数据获取行为中,互联网社交时代已成为人工智能时代的常态。用户输入的信息已被大模型制造商以"训练语料"的名义随意获取,用户数据不再被视为需要严格保护的个人隐私,而是模型进步的"垫脚石"。
除了用户数据,对于大模型的尝试来说,训练语料的透明度也至关重要。这些语料是否合理合法,是否构成侵权,对于用户的使用是否存在潜在风险等都是问题。我们对7款大模型产品进行了深入挖掘和评测,结果令人震惊。
02、训练语料"投喂"隐患
大模型的训练除了算力外,高质量的语料更为重要。然而,这些语料往往包含受版权保护的文本、图片、视频等多样化作品,未经授权使用显然会构成侵权。
「科技新知」实测后发现,7款大模型产品在协议中都未提及大模型训练数据的具体来源,也没有公开版权数据。

大家都默契不公开训练语料的原因很简单,一方面可能是因为数据使用不当很容易出现版权争端,而AI公司将版权产品用作训练语料是否合规合法,目前还未有相关规定;另一方面或与企业之间的竞争有关,企业公开训练语料就相当于食品公司将原材料告诉了同行,同行可以很快进行复刻,提高产品水平。
值得一提的是,大多数模型的政策协议中都提到,会将用户和大模型的交互后所得到的信息用于模型和服务优化、相关研究、品牌推广与宣传、市场营销、用户调研等。
用户数据的质量参差不齐、场景深度不够、边际效应存在等多方面原因,很难提高模型能力,甚至还可能带来额外的数据清洗成本。但即便如此,用户数据的价值仍然存在。它们不再是提升模型能力的关键,而是企业获取商业利益的新途径。
不过,也需要注意的是,实时处理过程中产生的数据会上传到云端进行处理,也同样会被存储至云端,虽然大多数大模型在隐私协议中提到使用不低于行业同行的加密技术、匿名化处理及相关可行的手段保护个人信息,但这些措施的实际效果仍有担忧。

所以,当大模型公司以"为了提升模型性能"而收集数据时,我们需要更警惕去思考,这是模型进步的必要条件,还是企业基于商业目的而对用户的数据滥用。
03、数据安全模糊地带
除了常规大模型应用外,智能体、端侧<机器学习>的应用带来的隐私泄漏风险更为复杂。
相比聊天机器人等<机器学习>工具,智能体、端侧<机器学习>在使用时需要获取的个人信息会更详细且更具有价值。以往手机获取的信息主要包括用户设备及应用信息、日志信息、底层权限信息等;在端侧<机器学习>场景以及当前主要基于读屏录屏的技术方式,除上述全面的信息权限外,终端智能体往往还可以获取录屏的文件本身,并进一步通过<机器学习>分析,获取其所展现的身份、位置、支付等各类敏感信息。

往往厂商会以提供更好服务来当作说辞,当放到整个行业量来看,这也并非"正当理由"。
毋庸置疑,当前主流大模型在透明度方面存在诸多亟待解决的问题。无论是用户数据撤回的艰难,还是训练语料来源的不透明,亦或是智能体、端侧<机器学习>带来的复杂隐私风险,都在不断侵蚀着用户对大模型的信任基石。

大模型作为推动数字化进程的关键力量,其透明度的提升已刻不容缓。这不仅关乎用户个人信息安全与隐私保护,更是决定整个大模型行业能否健康、可持续发展的核心要素。
未来,期待各大模型厂商能积极响应,主动优化产品设计与隐私政策,以更加开放、透明的姿态,向用户清晰阐释数据的来龙去脉,让用户能够放心地使用大模型技术。同时,监管部门也应加快完善相关法律法规,明确数据使用规范与责任边界,为大模型行业营造一个既充满创新活力又安全有序的发展环境,使大模型真正成为造福人类的强大工具。