


图片来源:由无界AI生成
DeepSeek频频回复的"服务器繁忙,请稍后再试",正在让各地用户抓狂。
此前不太被大众所知的DeepSeek,因2024年12月26日推出对标GPT 4o的语言模型V3而声名鹊起。在1月20日DeepSeek又发布对标OpenAI o1的语言模型R1,之后因为"深度思考"模式生成的答案优质度高,以及其创新揭示出模型训练前期成本可能骤降的积极信号,令该公司和应用彻底出圈。之后,DeepSeek R1就一直在经历拥堵,它的联网搜索功能间歇性瘫痪,深度思考模式则高频率提示"服务器繁忙",此类现象让大量用户倍感困扰。
十几日前,DeepSeek开始经历服务器中断,1月27日中午,DeepSeek官网已数次显示"deepseek网页/api不可用",当日,DeepSeek成为周末期间iPhone下载量最高的应用程序,在美区下载榜超越了ChatGPT。
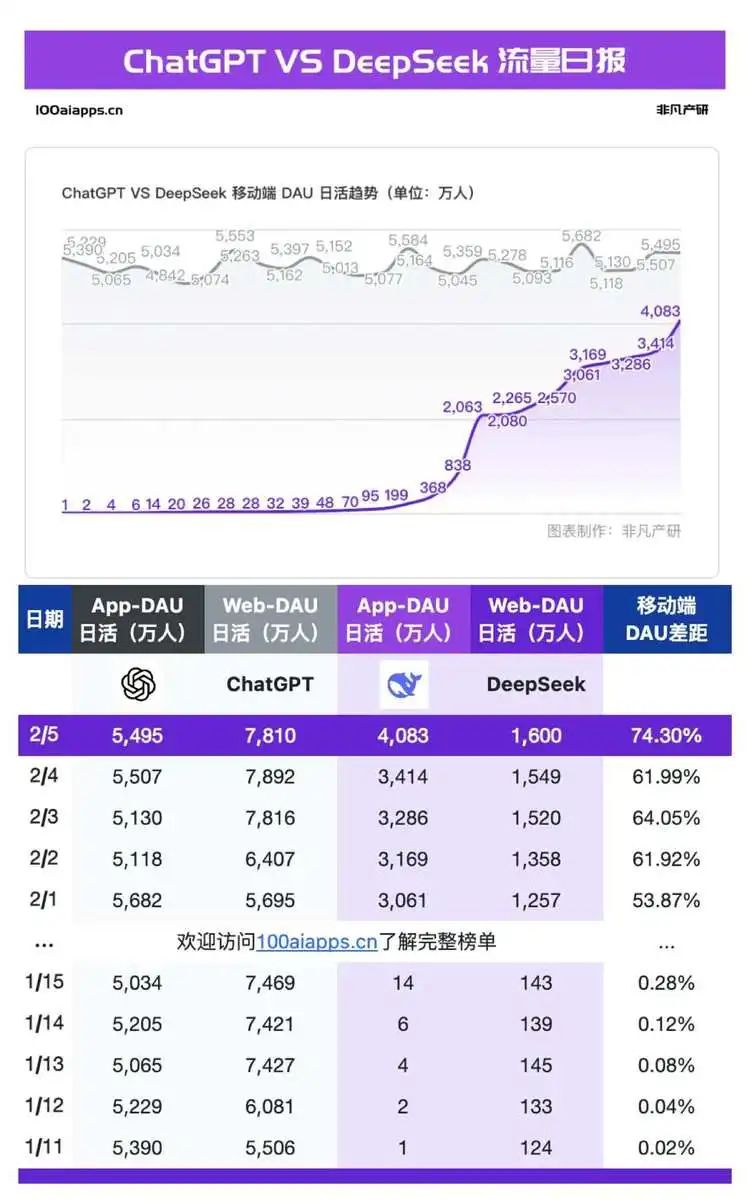
2月5日,DeepSeek移动端上线26天,日活突破4000万,ChatGPT移动端日活为5495万,DeepSeek为ChatGPT的74.3%。几乎在DeepSeek走出陡峭增长曲线的同时,关于其服务器繁忙的吐槽纷至沓来,全世界用户都开始遭遇问几个问题就发生宕机的不便,各类替代访问也开始出现,比如DeepSeek的平替网站,各大云服务商、芯片厂商和基础设施公司都纷纷上线,个人部署教程也到处都是。但人们的抓狂却没有缓解:全球几乎所有重要厂商都宣称支持部署了DeepSeek,但各地用户却依然在吐槽服务的不稳定。
这背后到底发生了什么?
1、习惯了ChatGPT的人们,受不了打不开的DeepSeek
人们对"DeepSeek服务器繁忙"的不满,来自于此前以ChatGPT为主的AI顶流应用们,甚少出现卡顿。
自OpenAI服务推出以来,ChatGPT虽然也经历了几次P0级别(最严重的事故级别)宕机事故,但总体来说,它相对可靠,已然在创新和稳定性之间找到平衡,并逐步成为类似传统云服务的关键组成部分。

ChatGPT大范围宕机次数并不算多
ChatGPT的推理过程相对稳定,包括编码和解码两个步骤,编码阶段把输入文本转换成向量,向量包含输入文本的语义信息,解码阶段,ChatGPT使用先前生成的文本作为上下文,通过Transformer模型生成下一个单词或短语,直到生成符合需求的完整语句,大模型本身属于Decoder(解码器)架构,解码阶段就是一个个token(大模型处理文本时的最小单位)的输出过程,每向ChatGPT提问一次,就启动一次推理流程。
举例来说,如果向ChatGPT提问,"你今天心情如何",ChatGPT会对这句话进行编码,生成每层的注意力表示,根据之前所有token的注意力表示,预测得到第一个输出token "我",之后进行解码,将"我"拼接到"你今天心情如何?",后面得到"你今天心情如何?我",得到新的注意力表示,然后预测下一个token :"的",之后按照第一步,第二步循环,最终得到"你今天心情如何?我的心情很好。"
编排容器的工具Kubernetes是ChatGPT的"幕后指挥官",它负责调度和分配服务器资源。当涌入的用户承载完全超出Kubernetes控制平面的承受能力时,就会导致ChatGPT系统的全面瘫痪。
ChatGPT发生瘫痪的总次数不算太多,但这背后是它依靠的强大资源作为支撑,维持稳定运转背后是强大算力,而这是人们忽视的地方。
一般而言,由于推理处理的数据规模往往较小,因此对算力的要求不如训练般高。有业界人士估算指出,在正常大模型推理过程中,显存的主要占用模型参数权重占大头,大概占比在80%以上。现实情况是,在ChatGPT内置的多个模型中,里面默认模型尺寸都比DeepSeek-R1 的671B要小,加上ChatGPT拥有比DS- R1多得多的GPU算力,自然展现出比DS- R1更为稳定的表现。
DeepSeek-V3与R1都是一个671B的模型,模型启动过程就是推理的过程,推理时的算力储备需要与用户量相衬,比如有1亿用户量就需配备1亿用户量的显卡,不仅庞大,且与训练时的算力储备独立开来,并不相关。从各方信息看,DS的显卡和算力储备明显不足,于是频频卡顿。
这种对比让适应了ChatGPT丝滑体验的用户并不习惯,特别是他们对R1的兴趣愈发高涨的当下。
2、卡,卡,还是卡
而且,仔细对比,OpenAI和DeepSeek遇到的情况是很不同的。
前者有微软做后盾,作为OpenAI的独家平台,微软Azure云服务搭载了ChatGPT、Dalle-E 2图像生成器、GitHub Copilot自动编码工具,此后,这一组合成为了云+AI的经典范式,并快速普及成为业界标配;后者虽是初创,却大部分情况下依靠自建数据中心,与谷歌类似,而不依赖第三方云计算提供商。硅星人查阅公开信息后发现,DeepSeek在任何层面都没有跟云厂商、芯片厂商开启合作(虽然春节期间云厂商纷纷宣布让DeepSeek模型跑在其上,但他们并没有开展任何真正意义的合作)。
而且,DeepSeek遇到了史无前例的用户增长,这意味着它对应激情况的准备时间也比ChatGPT更少。
DeepSeek的良好性能来自其在硬件和系统层面做出的整体优化。DeepSeek的母公司幻方量化,早在2019年就花了2亿打造萤火一号超算集群,到22年就默默存储万张A100显卡,为了更高效的并行训练,DeepSeek自研了HAI LLM训练框架。业界认为,萤火集群可能采用了数千至数万张高性能GPU(如英伟达A100/H100或国产芯片),以提供强大的并行计算能力。目前萤火集群支撑了DeepSeek-R1、DeepSeek-MoE等模型训练,这些模型在数学、代码等复杂任务中表现接近于GPT-4水平。
萤火集群代表着DeepSeek在全新架构和方法上的探索历程,也让外界认为,通过这类创新技术,DS降低了训练的成本,可以仅需西方最先进模型几分之一的算力,就训练出与顶级AI模型性能相当的R1。SemiAnalysis经推算指出,DeepSeek实际拥有庞大的算力储备:DeepSeek共堆砌了6万张英伟达GPU卡,其中包括1万张A100、1万张H100、1万张"特供版"H800以及3万张"特供版"H20。
这似乎意味着R1的卡量比较充足。但实际上,作为推理模型的R1,对标的是OpenAI的O3,这类推理模型需要部署更多算力用于应答环节,但DS在训练成本侧节约的算力,与推理成本侧骤增的算力,孰高孰低,目前并不明确。
值得一提的是,DeepSeek-V3和DeepSeek-R1都是大语言模型,但运作方式有差。DeepSeek-V3 是指令模型,类似ChatGPT,接收提示词生成相应文本进行回复。但DeepSeek-R1是推理模型,用户向R1提问时,它会首先进行大量的推理过程,然后再生成最终答案。R1生成的token中首先出现的是大量的思维链过程,模型在生成答案之前,会先解释问题,分解问题,所有这些推理过程都会以token的形式快速生成。
후오비 토큰(HT) 부사장 웬팅찬에 따르면, 앞서 언급한 DeepSeek의 막대한 해시레이트 보유는 학습 단계를 의미하며, 학습 단계의 해시레이트는 팀이 계획하고 예측할 수 있어 부족함이 발생하지 않지만, 추론 해시레이트는 불확실성이 크다고 합니다. 이는 주로 사용자 규모와 사용량에 따라 달라지며 탄력성이 크기 때문입니다. "추론 해시레이트는 일정한 규칙에 따라 증가하지만, DeepSeek가 현상급 제품이 되면서 단기간에 사용자 규모와 사용량이 폭발적으로 증가하여 추론 단계의 해시레이트 수요가 폭발적으로 증가하여 지연이 발생했습니다."
즉시 활성화된 모델 제품 설계사이자 독립 개발자인 귀장은 용량 부족이 DeepSeek 지연의 주요 원인이라고 인정했습니다. 그는 DS가 현재 전 세계 140개 시장에서 가장 많이 다운로드된 모바일 애플리케이션이지만, 현재의 지연은 어떤 방식으로도 견딜 수 없으며, 새로운 카드를 사용해도 마찬가지라고 말했습니다. 이는 "새로운 카드를 클라우드에 배포하는 데 시간이 걸리기 때문"입니다.
"엔비디아 A100, H100 등 칩셋을 1시간 동안 실행하는 비용은 공정한 시장 가격이 있지만, DeepSeek의 토큰 출력 추론 비용은 OpenAI의 유사 모델보다 90% 이상 저렴합니다. 이는 대부분의 계산 편차와 크게 다르지 않습니다. 따라서 모델 아키텍처 MOE 자체가 가장 큰 문제는 아니지만, DS가 보유한 GPU 수량이 그들이 매분 생산할 수 있는 토큰 수를 결정합니다. 더 많은 GPU를 추론 서비스에 사용하고 사전 학습 연구에 사용하지 않더라도 한계가 있습니다."라고 AI 네이티브 애플리케이션 소프트웨어 개발자 천운비도 유사한 견해를 밝혔습니다.
업계 관계자들은 실리콘 스타에게 DeepSeek의 지연 본질은 프라이빗 클라우드가 제대로 준비되지 않았기 때문이라고 언급했습니다.
해킹 공격은 R1 지연의 또 다른 요인입니다. 1월 30일, 미디어는 사이버 보안 기업 Qihoo 360으로부터 DeepSeek 온라인 서비스에 대한 공격 강도가 갑자기 높아졌다는 사실을 알게 되었습니다. 공격 명령은 1월 28일보다 100배 이상 증가했습니다. Qihoo 360 Xlab 실험실은 최소 2개의 좀비 네트워크가 공격에 참여하고 있음을 관찰했습니다.
그러나 이러한 R1 자체 서비스의 지연에는 비교적 명확한 해결책이 있습니다. 바로 제3자 서비스 제공입니다. 이는 우리가 설 연휴 기간 동안 목격한 가장 활발한 현상이었습니다. 각 업체들이 서비스를 배포하여 DeepSeek에 대한 수요를 충족시켰습니다.
1월 31일, 엔비디아는 NVIDIA NIM이 DeepSeek-R1을 사용할 수 있다고 발표했습니다. 이전에 엔비디아는 DeepSeek의 영향으로 하루 만에 시총이 약 6000억 달러 증발했습니다. 같은 날, Amazon Web Services(AWS) 사용자는 Amazon Bedrock와 Amazon SageMaker AI에서 DeepSeek의 최신 R1 기본 모델을 배포할 수 있습니다. 이후 Perplexity, Cursor 등 AI 애플리케이션 신생기업들도 DeepSeek에 대량 접속했습니다. 마이크로소프트는 아마존과 엔비디아보다 먼저 DeepSeek-R1을 Azure 클라우드 서비스와 GitHub에 배포했습니다.
2월 1일 음력 설 연휴 기간 중, 화웨이 클라우드, 알리바바 클라우드, 바이트댄스의 화산 엔진, 텐센트 클라우드 등도 참여했습니다. 이들은 일반적으로 DeepSeek 전 시리즈와 전 규모 모델 배포 서비스를 제공합니다. 이후에는 벽인 과기, 한보 반도체, 승천, 무희 등 AI 칩 제조업체들이 DeepSeek 원본 또는 더 작은 크기의 증류 버전을 적응시켰다고 밝혔습니다. 소프트웨어 회사 측면에서는 용우, 금디 등이 일부 제품에서 DeepSeek 모델을 접목하여 제품력을 강화했습니다. 마지막으로 레노버, 화웨이, 영광 등 일부 단말기 제조업체들도 DeepSeek 모델을 탑재하여 엣지 개인 비서와 자동차 스마트 콕핏에 활용했습니다.
지금까지 DeepSeek는 자체 가치로 방대한 친구 네트워크를 끌어들였습니다. 국내외 클라우드 업체, 통신사, 증권사, 국가급 플랫폼 등이 망라되어 있습니다. DeepSeek-R1이 완전 오픈소스 모델이기 때문에, 접속한 서비스 업체들이 모두 DS 모델의 수혜자가 되었습니다. 이는 DS의 영향력을 크게 높였지만, 동시에 더 빈번한 지연 현상을 초래했습니다. 서비스 업체와 DS 자체가 쇄도하는 사용자에 점점 더 시달리고 있지만, 안정적인 사용 문제의 핵심 해결책을 찾지 못하고 있습니다.
DeepSeek V3와 R1 두 모델 원본이 모두 6710억 개의 매개변수에 달해 클라우드에서 실행하기에 적합하다는 점을 고려할 때, 클라우드 업체 자체가 더 풍부한 해시레이트와 추론 능력을 보유하고 있기 때문에, DeepSeek 관련 배포 서비스를 런칭한 것은 기업 사용의 진입 장벽을 낮추기 위해서입니다. 이들이 DeepSeek 모델을 배포한 후 외부에 DS 모델 API를 제공하는 것은 DS 자체가 제공하는 API보다 더 나은 사용 경험을 제공할 것으로 여겨졌습니다.
그러나 현실에서는 DeepSeek-R1 모델 자체의 실행 경험 문제가 각 서비스에서 해결되지 않았습니다. 외부에서는 서비스 업체들이 카드 부족이 아니라고 생각하지만, 실제로 그들이 배포한 R1에 대한 개발자들의 불안정한 반응 피드백 빈도가 R1과 완전히 일치하는 것은, R1에 할당할 수 있는 카드 용량이 많지 않기 때문입니다.
"R1의 인기가 높게 유지되고 있어 서비스 업체들은 다른 모델에 대한 접속도 고려해야 하므로 R1에 제공할 수 있는 카드가 매우 제한적입니다. R1의 인기가 높은데 상대적으로 낮은 가격으로 제공하면 금방 무너질 것입니다."라고 모델 제품 설계사이자 독립 개발자인 귀장이 실리콘 스타에게 설명했습니다.
모델 배포 최적화는 다양한 단계를 포함하는 광범위한 분야이지만, DeepSeek의 지연 사건에 대해서는 너무 큰 모델과 출시 전 최적화 준비 부족 등 보다 단순한 이유일 수 있습니다.
인기 있는 대규모 모델이 출시되기 전에는 기술, 엔지니어링, 비즈니스 등 다양한 과제에 직면하게 됩니다. 예를 들어 학습 데이터와 실제 환경 데이터의 일관성, 데이터 지연과 실시간성이 모델 추론 효과에 미치는 영향, 온라인 추론 효율과 리소스 사용량 과다, 모델 일반화 능력 부족, 서비스 안정성, API와 시스템 통합 등 엔지니어링 측면의 문제 등입니다.
많은 인기 있는 대규모 모델들은 출시 전 추론 최적화에 큰 관심을 기울입니다. 이는 계산 시간과 메모리 문제 때문입니다. 전자는 추론 지연이 너무 길어 사용자 경험이 나쁘거나 지연 요구 사항을 충족하지 못하는 것을 의미하며, 후자는 모델 매개변수가 많아 비디오 메모리를 소모하여 단일 GPU 카드에 탑재할 수 없어 지연을 초래할 수 있습니다.
웬팅찬은 실리콘 스타에게 서비스 업체들이 R1 서비스를 제공하면서 직면한 과제는 본질적으로 DS 모델 구조가 특수하고 모델이 너무 크며 MOE(전문가 혼합 구조) 아키텍처 때문이라고 설명했습니다. "최적화에는 시간이 필요하지만 시장 열기는 시간 창이 있기 때문에 충분히 최적화하지 않고 먼저 출시하는 것입니다."
R1을 안정적으로 실행하려면 현재 핵심은 추론 측의 리소스와 최적화 능력입니다. DeepSeek가 해야 할 일은 추론 비용을 낮추고 카드 출력, 단일 출력 토큰 수를 줄이는 방법을 찾는 것입니다.
동시에 지연 현상은 DS 자체의 해시레이트 보유량도 SemiAnalysis가 언급한 것만큼 크지 않을 수 있음을 시사합니다. 환방 펀드 회사가 카드를 사용하고 DeepSeek 학습 팀도 카드를 사용해야 하므로, 사용자에게 제공할 수 있는 카드는 항상 부족했습니다. 현재 발전 상황을 볼 때, 단기적으로 DeepSeek가 비용을 들여 서비스를 제공하고 사용자에게 더 나은 경험을 제공할 동기가 없을 것 같습니다. 그들은 첫 번째 C-end 비즈니스 모델을 정리한 후에 서비스 임대 문제를 고려할 가능성이 더 크며, 이는 지연 현상이 상당 기간 지속될 것임을 의미합니다.
"그들은 대략 두 가지 조치를 취해야 할 것 같습니다. 1) 유료 메커니즘을 도입하여 무료 사용자의 모델 사용량을 제한하고, 2) 클라우드 서비스 업체와 협력하여 다른 사람의 GPU 리소스를 활용하는 것입니다."라고 개발자 천운비가 제시한 임시 해결책이





