作者:王璐,定焦 One(dingjiaoone)原创
DeepSeek彻底让全球都坐不住了。
昨天,马斯克携"地球上最聪明的AI"——Gork 3在直播中亮相,自称其"推理能力超越目前所有已知模型",在推理-测试时间得分上,也好于DeepSeek R1、OpenAI o1。不久前,国民级应用微信宣布接入DeepSeek R1,正在灰度测试中,这一王炸组合被外界认为AI搜索领域要变天。
如今,微软、英伟达、华为云、腾讯云等全球多家科技大厂都已接入DeepSeek。网友也开发出了算命、预测彩票等新奇玩法,其热度直接转化成了真金白银,助推DeepSeek估值一路上涨,最高已经达到了千亿美金。
DeepSeek能出圈,除了免费和好用之外,还因为其仅以557.6万美元的GPU成本,就训练出了与OpenAI o1能力不相上下的DeepSeek R1模型。毕竟,在过去几年的"百模大战"中,国内外AI大模型公司都砸了几十亿甚至上百亿美元。Gork 3成为"全球最聪明AI"的代价也是高昂的,马斯克称Gork 3训练累计消耗20万块英伟达GPU(单块成本大约在3万美元),而业内人士估计DeepSeek仅在1万多张。
但也有人在成本上卷DeepSeek。近日李飞飞团队称,仅花费不到50美元的云计算费用,就训练出了一款推理模型S1,其在数学和编码能力测试中的表现媲美OpenAI的o1和DeepSeek的R1。但需要注意的是,S1是中型模型,与DeepSeek R1的上千亿参数级别存在差距。
即便如此,从50美元到上百亿美元的巨大训练成本差异,还是让大家好奇,一方面想知道DeepSeek的能力有多强,为什么各家都在试图赶上甚至超过它,另一方面,训练一个大模型究竟需要多少钱?它涉及哪些环节?未来,是否还有可能进一步降低训练成本?
被"以偏概全"的DeepSeek
在从业者看来,在解答这些问题前,得先捋清几个概念。
首先是对DeepSeek的理解"以偏概全"。大家惊叹的是它众多大模型之中的一个——推理大模型DeepSeek-R1,但它还有其他的大模型,不同大模型产品之间的功能不一样。而557.6万美元,是其通用大模型DeepSeek-V3训练过程中的GPU花费,可以理解为净算力成本。
简单对比下:
通用大模型:
接收明确指令,拆解步骤,用户要把任务描述清楚,包括回答顺序,比如用户需要提示是先做总结再给出标题,还是相反。
回复速度较快,基于概率预测(快速反应),通过大量数据预测答案。
推理大模型:
接收简单明了、聚焦目标的任务,用户要什么直接说,它可以自己做规划。
回复速度较慢,基于链式思维(慢速思考),推理问题步骤得到答案。
两者主要的技术差别在于训练数据,通用大模型是问题+答案,推理大模型是问题+思考过程+答案。
第二,由于Deepseek的推理大模型DeepSeek-R1关注度更高,很多人错误地认为推理大模型一定比通用大模型高级。
需要肯定的是,推理大模型属于前沿模型类型,是大模型预训练范式撞墙后,OpenAI推出的在推理阶段增加算力的新范式。相比通用大模型,推理大模型更烧钱,训练时间也更长。
但并不意味着,推理大模型一定比通用大模型好用,甚至对于某类问题,推理大模型反而显得鸡肋。
大模型领域知名专家刘聪对「定焦One」解释,比如问某个国家的首都/某个地方的省会城市,推理大模型就不如通用大模型好用。

DeepSeek-R1面对简单问题时的过度思考
他表示,面对这类比较简单的问题,推理大模型不仅回答效率低于通用大模型,消耗的算力成本也比较昂贵,甚至会出现过度思考等情况,最后可能给出错误答案。
他建议,完成数学难题、挑战性编码等复杂任务时使用推理模型,总结、翻译、基础问答等简单任务,通用模型使用效果更佳。
第三是DeepSeek的真正实力到底如何。
综合权威榜单和从业者的说法,「定焦One」分别在推理大模型和通用大模型领域,给DeepSeek排了个位。
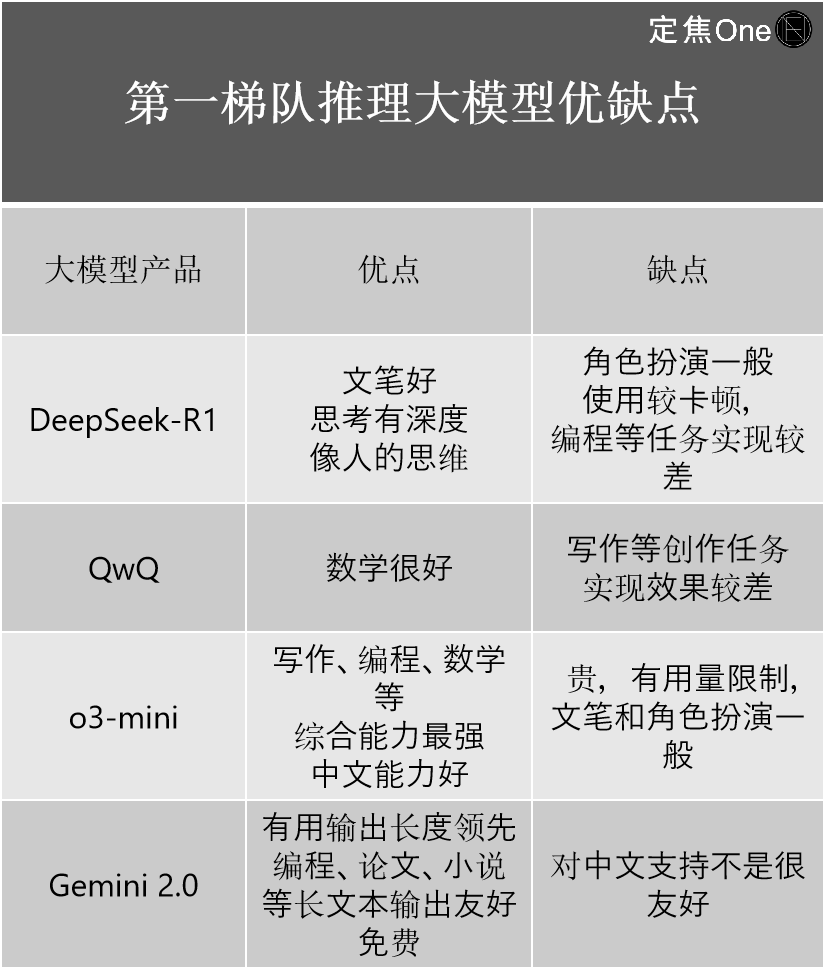
推理大模型第一梯队主要有四家:国外OpenAI的o系列模型(如o3-mini)、Google的Gemini 2.0;国内的DeepSeek-R1、阿里的QwQ。
不止一位从业者认为,虽然外界都在讨论DeepSeek-R1作为国内顶尖的模型,能力赶超OpenAI,但从技术角度看,相比OpenAI最新的o3,还有一定的差距。
它更重要的意义是,大大缩小了国内外顶尖水平之间的差距。"如果说之前的差距是2-3代,DeepSeek-R1出现后已经缩小到了0.5代。"AI行业资深从业者江树表示。
他结合自身使用经验,介绍了四家的优缺点:
在通用大模型领域,根据LM Arena(用于评估和比较大型语言模型(LLM)性能的开源平台)榜单,排在第一梯队的有五家:国外Google的Gemini(闭源)、OpenAI的ChatGPT、Anthropic的Claude;国内的DeepSeek、阿里的Qwen。
江树也列举出了使用它们的体验。
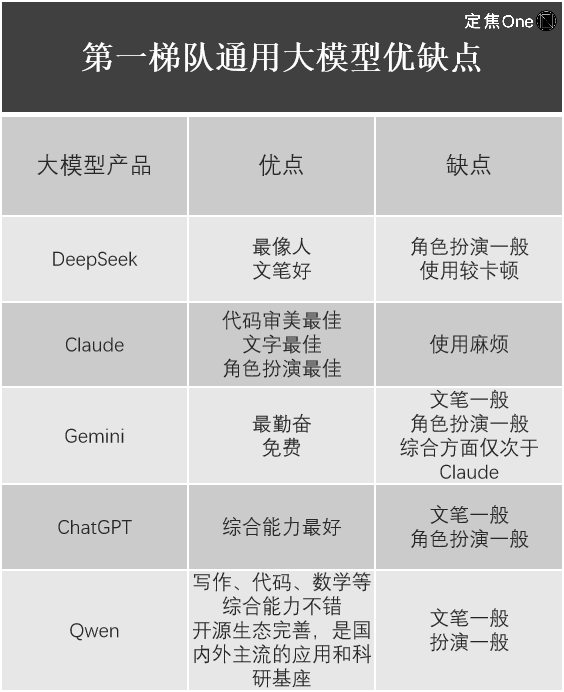
不难发现,尽管DeepSeek-R1震惊了全球科技圈,其价值毋庸置疑,但每家大模型产品都有自身的优劣势,DeepSeek也不是所有大模型都完美无缺。比如刘聪就发现,DeepSeek最新发布的专注于图像理解和生成任务的多模态大模型Janus-Pro,使用效果一般。
训练大模型,要花多少钱?
回到训练大模型的成本问题,一个大模型究竟是如何诞生的?
刘聪表示,大模型诞生主要分为预训练-后训练两个阶段,如果把大模型比作小孩,预训练和后训练要做的是,让小孩从出生时的只会哭,到懂得大人讲的内容,再到主动和大人讲话。
预训练主要指训练语料。比如将大量的文本语料投给模型,让小孩完成知识摄取,但此刻他只是学了知识还不会用。
后训练则要告诉小孩,如何去用学了的知识,包含两种方法,模型微调(SFT)和强化学习(RLHF)。
刘聪表示,无论是通用大模型还是推理大模型、国内还是国外,大家遵循的都是这一流程。江树也告诉「定焦One」,各家都用的是Transformer模型,因此在最底层的模型构成和训练步骤上,无本质区别。
多位从业者表示,各家大模型的训练成本差别很大,主要集中在硬件、数据、人工三大部分,每一部分也可能采取不同的方式,对应的成本也不同。
후오비 토큰(HT), 옵티미즘(OP), 이더리움 네임서비스(ENS), 알위브(AR), 플레이댑(PLA), Ronin(RON), 온톨로지가스(ONG), 테크플로우(TechFlow), 제미니(Gemini), 트론(TRON), 렌(Ren), 초당 거래 수(TPS), 유동성 공급자(LP), 캐시우드 (Cathie Wood), 해시레이트, 대량, 대면.