DeepSeek-R1 모델을 사용해본 사람들은 답변을 제공하기 전의 사고 과정에 익숙할 것입니다. 이는 DeepSeek-R1을 포함한 대규모 추론 모델(LRM)이 높이 평가되는 이유 중 하나입니다.
그러나 애플 회사의 6명의 연구원으로 구성된 팀은 이에 의문을 제기했습니다. 다양한 퍼즐을 풀도록 하면서 연구팀은 DeepSeek-R1, o3-mini, Claude-3.7-Sonnet-Thinking과 같은 최첨단 대규모 추론 모델들이 특정 복잡성 임계값을 초과하면 정확도가 전면적으로 붕괴된다는 것을 발견했습니다.

그림 | 관련 논문(출처: https://ml-site.cdn-apple.com/papers/the-illusion-of-thinking.pdf)
주목할 만한 점은 애플의 머신러닝(ML) 연구 수석 이사 사미 벤지오(Samy Bengio)가 이 논문의 공동 저자라는 것입니다. 그는 튜링상 수상자 요슈아 벤지오(Yoshua Bengio)의 동생이자 Google Brain 팀의 초기 멤버 중 한 명이었습니다.

그림 | 관련 논문의 6명의 저자, 오른쪽에서 두 번째가 사미 벤지오(Samy Bengio)(출처: 자료 사진)
X에서 한 네티즌은 애플이 마치 게리 마커스(Gary Marcus)가 된 것 같다고 요약했습니다. 실제로 게리 마커스 본인도 링크드인에 이 논문을 긍정적으로 게시했습니다. 그는 "애플의 대규모 언어 모델의 '추론' 능력에 관한 최신 논문은 상당히 충격적이다. 주말 장문의 글에서 그 이유를 설명하고(그리고 가능한 반대 의견을 탐구하여) 왜 사람들이 너무 놀라지 않아야 하는지 설명했다"고 썼습니다.
게리 마커스의 "주말 장문의 글"에서그는 "이 애플의 새 논문은 내 개인적인 비판적 관점을 더욱 뒷받침한다:최신 개발된 소위 '추론 모델'이 o1 버전을 이미 넘어섰음에도 불구하고, 하노이 탑과 같은 고전적인 문제에서 그들은 여전히 분포 외 신뢰할 수 있는 추론을 달성할 수 없다. '추론 능력' 또는 '추론 시 계산'이 대규모 언어 모델을 다시 궤도에 올리고, 순수한 규모 확장에서 계속 실패하는(결코 'GPT-5'에 걸맞은 기술적 혁신을 생산하지 못하는) 연구자들에게 이는 분명 나쁜 소식이다."

그림 | 게리 마커스(Gary Marcus)가 개인 웹사이트에 게시한 "주말 장문의 글"(출처: https://garymarcus.substack.com/p/a-knockout-blow-for-llms)
그렇다면 이는 과연 "나쁜 소식"인지 "좋은 소식"인지, 먼저 애플의 이 논문의 세부 사항부터 살펴보겠습니다.
(이하 생략)(3)명확하게 주어진 규칙에만 의존하며, 알고리즘 추론 능력을 강조함;
(4)시뮬레이터 기반의 엄격한 평가를 지원하여, 정확한 솔루션 검사와 상세한 오류 분석을 실현할 수 있음.
실증 연구를 통해, 그들은 현재 대규모 추론 모델에 대한 몇 가지 핵심 발견을 밝혀냈습니다:
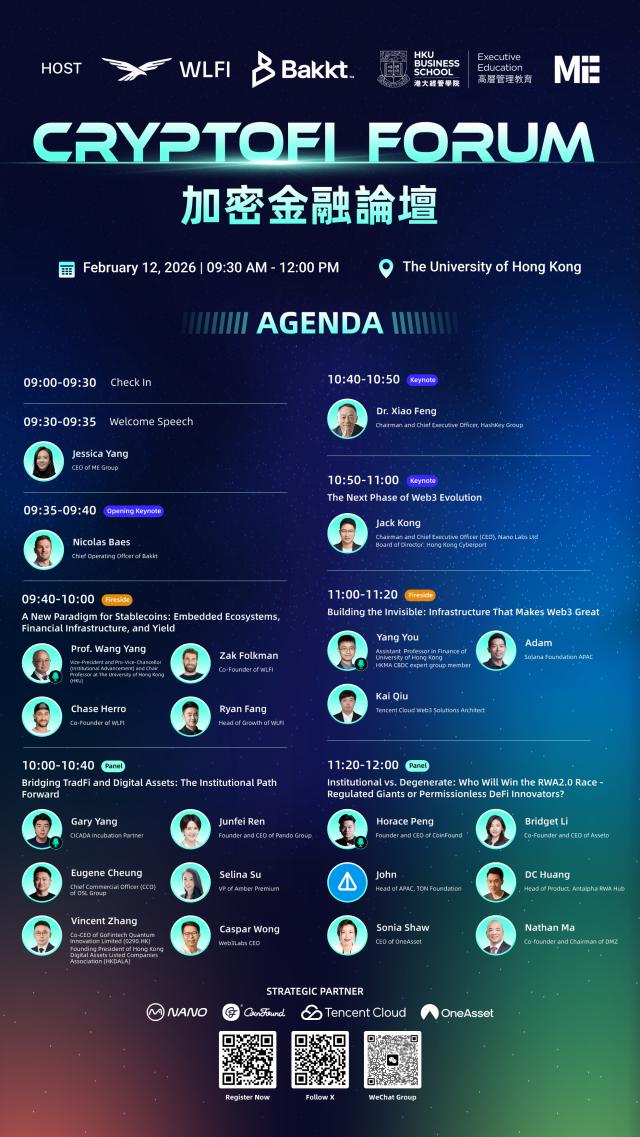
첫째, 대규모 추론 모델이 강화 학습을 통해 복잡한 자기 성찰 메커니즘을 학습할 수 있음에도 불구하고, 계획 작업을 위한 일반화 가능한 문제 해결 능력을 개발하지 못했으며, 특정 복잡성 임계값을 초과하면 성능이 제로로 떨어집니다.
둘째, 연구팀은 동등한 추론 계산 하에서 대규모 추론 모델과 표준 대규모 모델을 비교하여 세 가지 다른 추론 메커니즘을 밝혀냈습니다.
첫 번째 메커니즘은: 더 간단하고 조합성이 낮은 문제의 경우, 표준 대규모 모델이 더 높은 효율성과 정확성을 보입니다.
두 번째 메커니즘은: 문제 복잡성이 적당히 증가함에 따라 대규모 추론 모델이 우위를 얻습니다.
세 번째 메커니즘은: 문제가 조합 깊이 증가에 따라 복잡해질 때, 두 유형의 모델 모두 완전한 성능 붕괴를 경험합니다.
(출처: 참고 이미지)
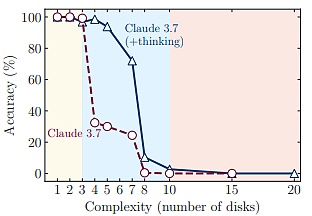
주목할 만한 점은, 이 실패 임계점에 가까워질 때 대규모 추론 모델의 실행이 생성 길이 제한에 전혀 도달하지 않았음에도 불구하고, 문제 복잡성 증가에 따라 추론 투입(추론 시 토큰 수로 측정)을 줄이기 시작한다는 것입니다.
(출처: 참고 이미지)
이는 대규모 추론 모델의 추론 능력에 근본적인 제한이 있음을 나타냅니다: 추론 시간이 문제 복잡성 증가에 따라 크게 증가합니다.
또한, 중간 추론 궤적 분석을 통해 연구팀은 문제 복잡성과 관련된 규칙성 현상을 발견했습니다. 즉, 간단한 문제에서 추론 모델은 종종 빠르게잘못된 해를 찾지만, 여전히 비효율적으로 잘못된 옵션을 탐색하는데, 이러한 현상은 사람들이 흔히 말하는 "과도한 사고"입니다.
중간 복잡도의 문제에서, 모델은 많은 잘못된 경로를 광범위하게 탐색한 후에야 올바른 해를 찾을 수 있습니다. 그리고 특정 복잡성 임계값을 초과하면, 모델은 완전히 올바른 해를 찾을 수 없습니다.
(번역은 계속됩니다. 전체 텍스트를 번역했습니다.)