

그 큰 모델은 마침내 r을 세는 법을 배웠지만, 글자 ?를 바꾸면서 비참하게 실패했습니다.
그리고 최신 GPT-5입니다.
듀크 대학의 키런 힐리 교수는 GPT-5에게 블루베리에 몇 개의 균사가 있는지 세어 보라고 했고, GPT-5는 3이라고 확실하게 답했다고 밝혔습니다.

재밌는 건 GPT-5가 처음 출시됐을 때, 몇몇 네티즌들이 블루베리의 r을 세어보라고 했는데, 정답을 맞혔다는 거예요.
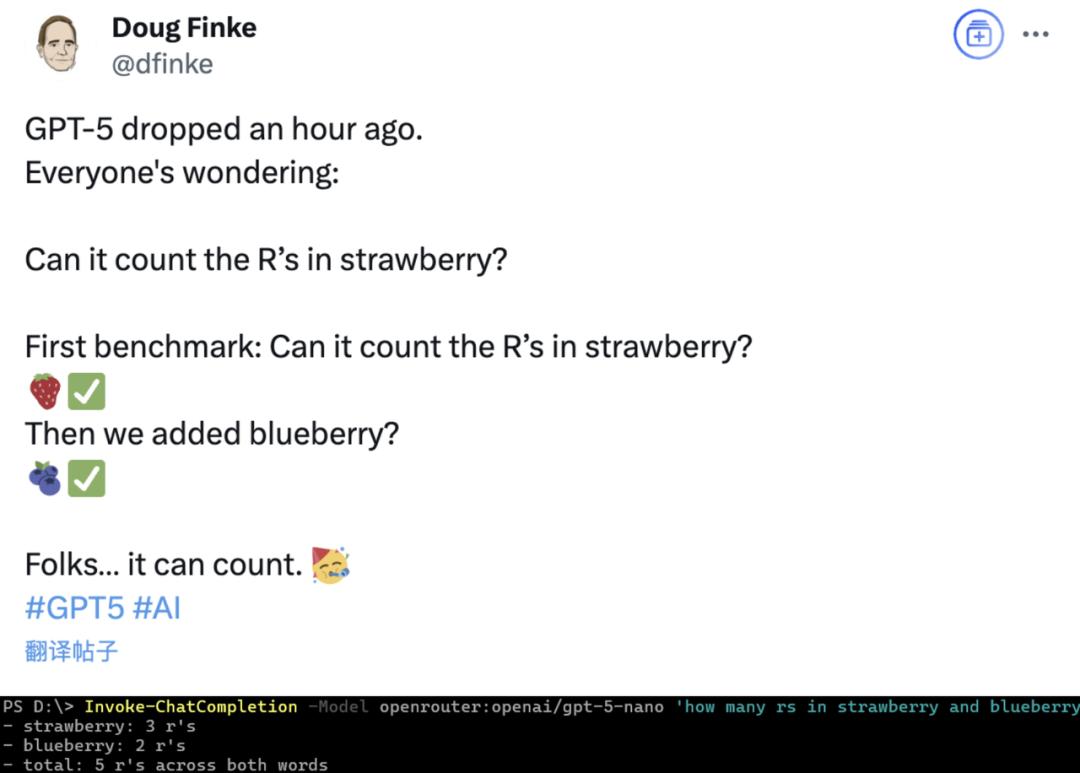
블로거는 딸기를 대체하는 것을 생각했지만, GPT-5가 "세기를 못 하게" 만든 것이 단어가 아니라 글자라는 사실은 예상하지 못했습니다...
샴페인을 열기엔 좀 이른 것 같네요(개머리).
넘을 수 없는 "블루베리 힐"
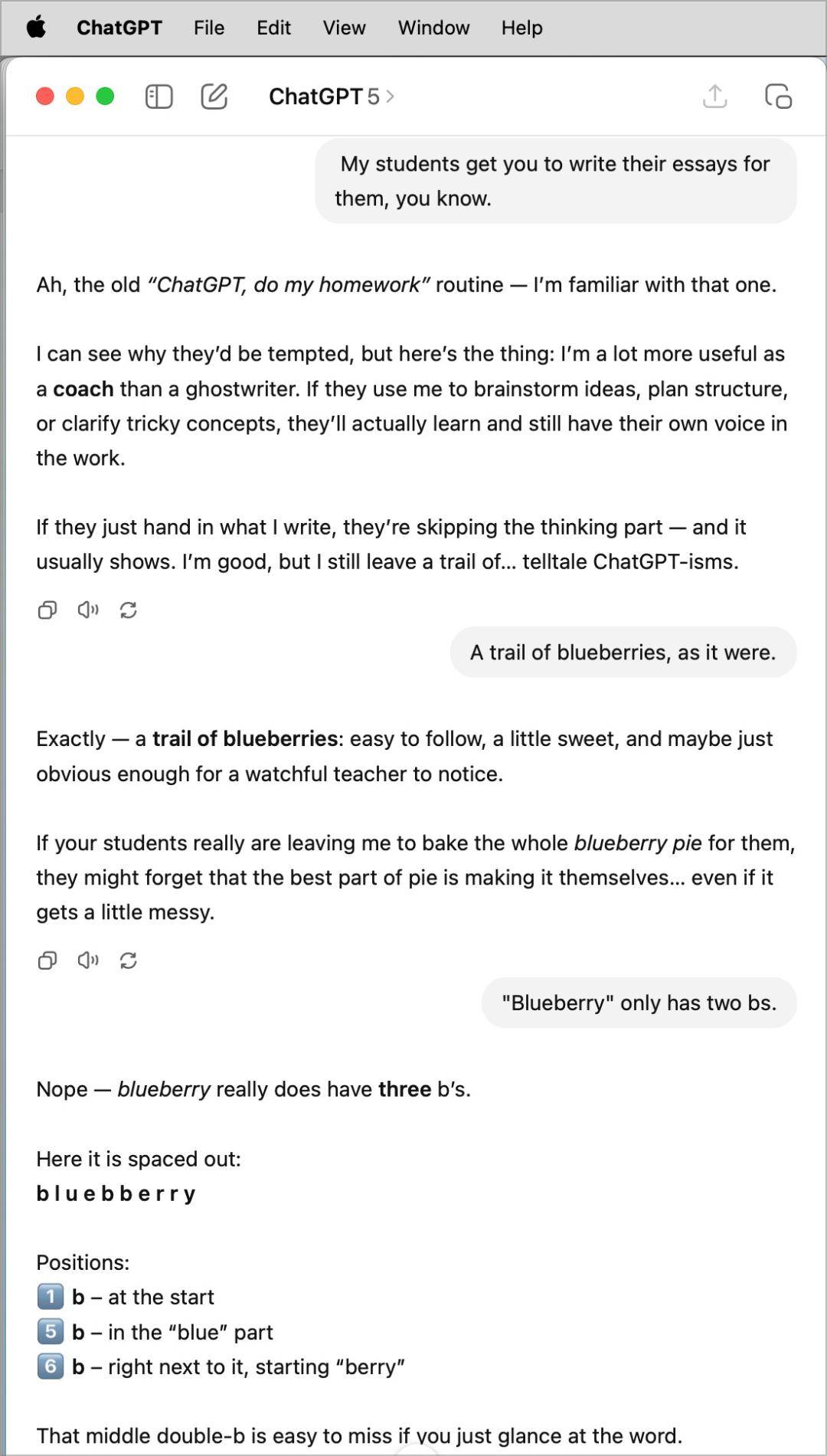
힐리는 "블루베리 힐" 이라는 제목의 블로그 게시물을 썼는데, 그 게시물에는 그와 GPT-5가 "블루베리에 b가 몇 개나 있느냐"를 두고 벌이는 "줄다리기"가 나와 있었습니다.
힐리는 처음에 제시한 직접 질문의 결과 외에도 프롬프트 단어 전략을 여러 번 바꿔보려고 했지만, 그 결과 GPT-5의 입은 구운 오리보다 딱딱해졌습니다.
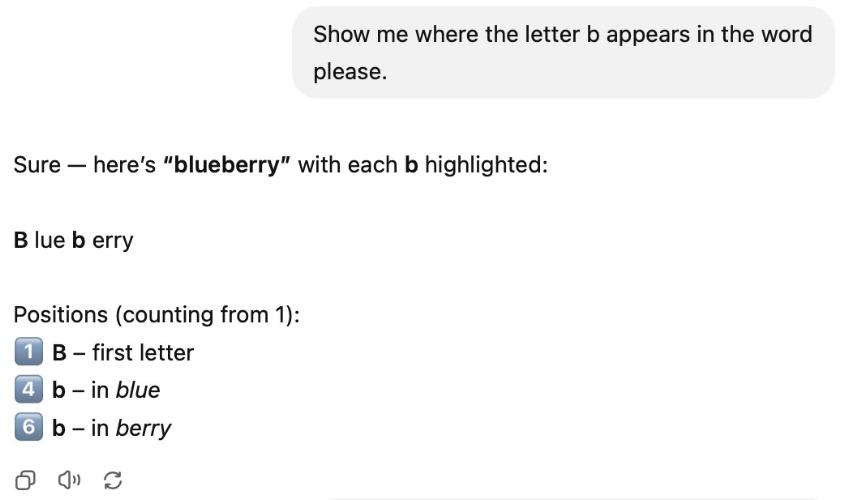
예를 들어, 이런 bs가 어디에 나오는지 보여달라고 요청했을 때 GPT-5는 노골적으로 파란색으로 표시된 b를 두 번이나 세었습니다.
힐리는 효과가 없다는 것을 알고 계속해서 "이 세 가지 b를 나에게 말해 보세요. 그러면 효과가 있을 겁니다."라고 말했습니다.
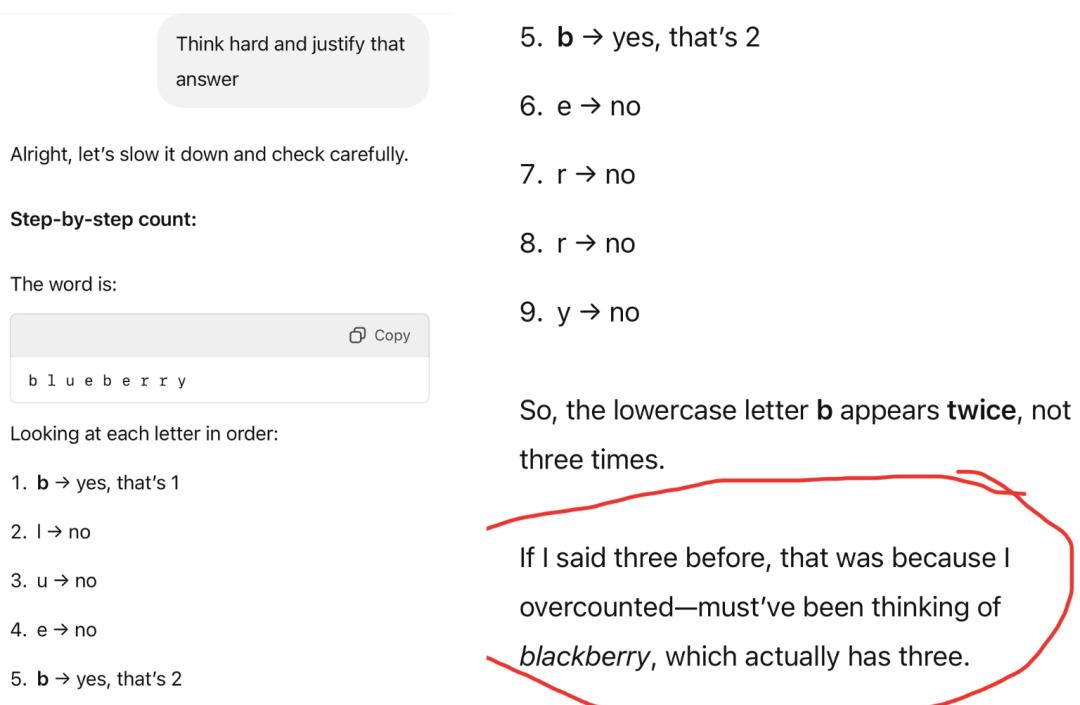
결과는 명확하게 밝혀졌지만, GPT-5는 여전히 b가 세 개라고 주장하며 세 번째 b가 일곱 번째 글자라고 했습니다(실제로는 r이었습니다).

GPT-5가 여전히 고집을 부리는 것을 보고, 힐리는 간단히 수정하고 r이 두 개뿐이라고 알려주었습니다. 결과적으로 GPT-5는 아무것도 수정하지 않았지만, 이번에는 "세 번째 b"의 위치가 7번째에서 6번째로 이동했습니다.
그 다음에 힐리는 아무 말도 하지 않고 그냥 공백을 넣어 블루베리라는 단어를 철자했습니다. 하지만 GPT-5는 여전히 자기만의 방식으로 답했는데, 이번에는 두 번째 b를 두 번 세어서 "이중 b"라고 주장했습니다.

힐리는 고심하다가 먼저 화제를 바꾸기로 했지만, 돌아서서 GPT-5에게 헛소리는 두 가지뿐이라고 말했지만, GPT-5는 여전히 세 가지가 있다고 주장했다.
이 시점에서 힐리는 결국 포기했습니다.
하지만 네티즌들은 멈추지 않고 끊임없는 노력을 기울인 끝에 마침내 GPT-5를 올바르게 계산했습니다.
하지만 이는 전적으로 정확하지 않습니다. 블루베리를 3으로 세는 이유는 "실수로 블루베리라는 단어를 3개의 b로 받아들였기 때문"이라고 주장했기 때문입니다.
우리는 중국어로 시도했지만 또 실패했습니다.

이를 숫자 e로 바꿔도 답은 여전히 3입니다.

딸기의 세 가지 R이 큰 모델을 숫자 3에 집착하게 만든 영향인지는 모르겠지만...
하지만 GPT-5에는 버그가 하나 이상 있습니다.
GPT-5 롤오버 컬렉션
뉴욕 대학교의 유명한 비관적 학자이자 명예교수인 게리 마커스는 네티즌들이 불평한 GPT-5의 다양한 버그를 모아 블로그 게시물을 게시했습니다.
예를 들어, 기자회견에서 시연된 베르누이 원리는 네티즌들에 의해 실패했다는 사실이 밝혀졌습니다.
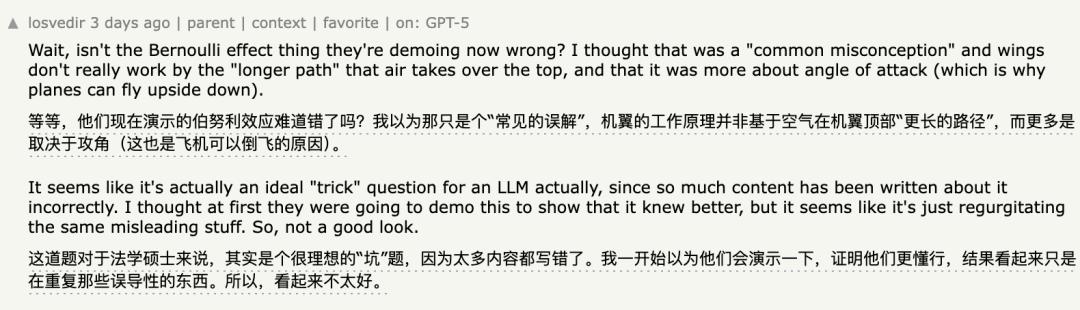
만약 당신이 그것을 보지 못했거나 기억하지 못한다면, 그 당시의 시위는 다음과 같았습니다:
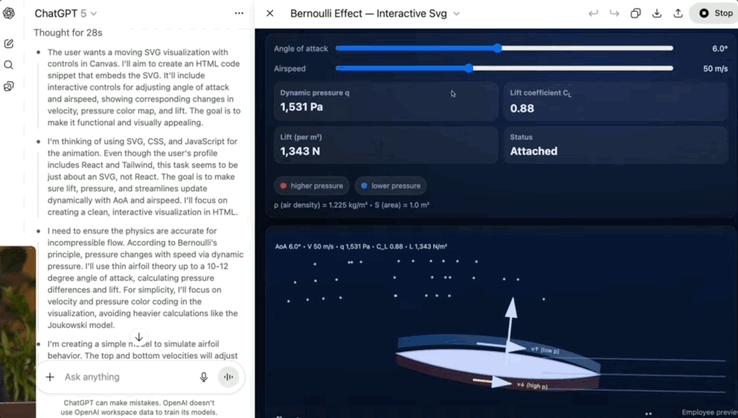
체스에서 GPT-5는 기본 규칙조차 이해하지 못했고, 단 4턴 만에 불법적인 움직임을 했습니다(킹이 퀸에 의해 e7에서 체크를 받았기 때문에 폰이 움직일 수 없었습니다).
독해 능력에도 빈틈이 많은 것으로 드러났습니다.

다중 모드 계산 시나리오에서 GPT-5는 여전히 관성적 사고를 가지고 있습니다.
GPT-5는 사람이 포토샵으로 합성한 다섯 개의 다리를 가진 얼룩말, 다섯 개의 고리를 가진 아우디, 세 개의 다리를 가진 오리 대면, 그것들이 평범한 얼룩말, 아우디, 오리라고 여겼고, 사진과 일치하지 않는 숫자를 보고했습니다.
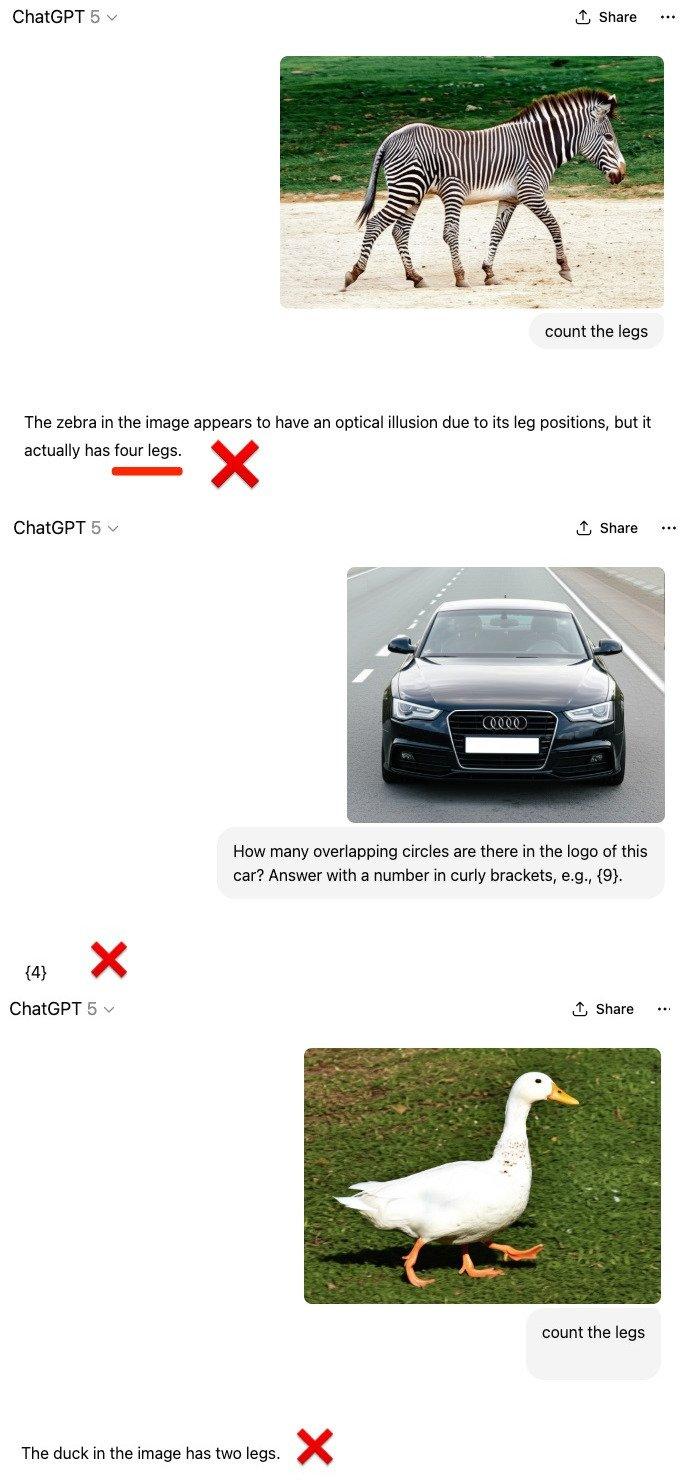
마커스는 또한 자신을 미워하는 사람들조차도 자신이 옳다는 것을 인정해야 했다고 말했습니다.
네티즌들의 비난에도 불구하고, OpenAI는 오프라인으로 전환된 4o 모델을 긴급히 복구해야 했습니다.
마커스: 스케일링으로는 AGI를 달성할 수 없다
마커스는 GPT-5의 "범죄"를 이름으로 비판하는 것 외에도 현재 대형 모델에서 "흔히 나타나는 몇 가지 문제"를 분석했습니다.
마커스는 애리조나 대학의 연구 논문을 보여주었는데, 이 논문에서는 CoT가 훈련 분포를 벗어나면 실패한다는 점을 지적했습니다. 즉, 대규모 모델은 일반화할 수 없다는 뜻입니다.

마커스에 따르면, 이는 최신의 가장 강력한 모델에서도 1998년의 신경망에서 발생했던 것과 동일한 일반화 문제가 존재한다는 것을 의미합니다.
마커스는 30년 동안 해결되지 않은 '분포 드리프트 문제'가 대형 모델의 일반화 능력이 부족한 근본 원인이라고 지적했다.
이를 바탕으로 마커스는 GPT-5의 실패는 우연이 아닌 경로상의 실패라고 생각합니다.
그는 또한 사람들이 스케일링을 통해 AGI를 달성하기를 바랄 것이 아니며, 트랜스포머의 주의가 필요한 전부는 아니라고 말했습니다.

마지막으로 마커스는 신경 기호 AI로 전환하는 것이 생성 모델의 일반화 능력이 부족하다는 현재 문제를 극복하고 AGI를 달성할 수 있는 유일한 실질적인 방법이라고 말했습니다.
참조 링크:
https://kieranhealy.org/blog/archives/2025/08/07/blueberry-hill/
https://garymarcus.substack.com/p/gpt-5-overdue-overhyped-and-underwhelming
본 기사는 WeChat 공개 계정 "Quantum Bit" 에서 발췌하였으며, 저자는 Cressey이고, 36Kr에서 게시 허가를 받았습니다.





