

GPT-5는 인간 의사보다 엑스레이를 더 잘 읽을 수 있을까?!
최신 연구에 따르면 GPT-5의 의료 이미지에 대한 추론 능력과 이해도는 인간 전문가보다 각각 24.23%, 29.40% 더 높은 것으로 나타났습니다 .
에모리 대학교 의과대학 연구팀은 GPT-5를 GPT-4o 및 더 작은 GPT-5 변형(GPT-5-mini 및 GPT-5-nano)과 비교하여 의료 분야에서 다중 모드 정보를 처리하는 능력을 분석했습니다.

일련의 표준화된 테스트를 통해 GPT-5가 모든 테스트에서 다른 모델보다 우수한 성능을 보인 것으로 나타났으며, 특히 MedXpertQA의 다중 모드 테스트에서 추론 점수와 이해 점수가 각각 GPT-4o보다 약 30% 와 36% 더 높았으며, 심지어 인간 의사보다도 더 높았습니다.

AI가 의료 기록을 읽는 것은 흔한 일이지만, 인간 의사보다 더 잘 읽는 경우는 드뭅니다. 그렇다면 GPT-5는 어떻게 이를 실현할까요?
AI는 다중 모드 의학에서 초보 인간 의사보다 우수한 성과를 보입니다.
연구진은 GPT-5, GPT-4o, 그리고 GPT-5의 미니와 나노 버전을 체계적으로 테스트했습니다.
시험은 일반 텍스트 USMLE 시험, 다중 모드 MedXpertQA 시험, 그리고 영상의학 VQA-RAD 시험의 세 가지 범주로 나뉩니다. 모든 시험은 제로샷 설정이며 데이터 미세 조정에 의존하지 않습니다 .
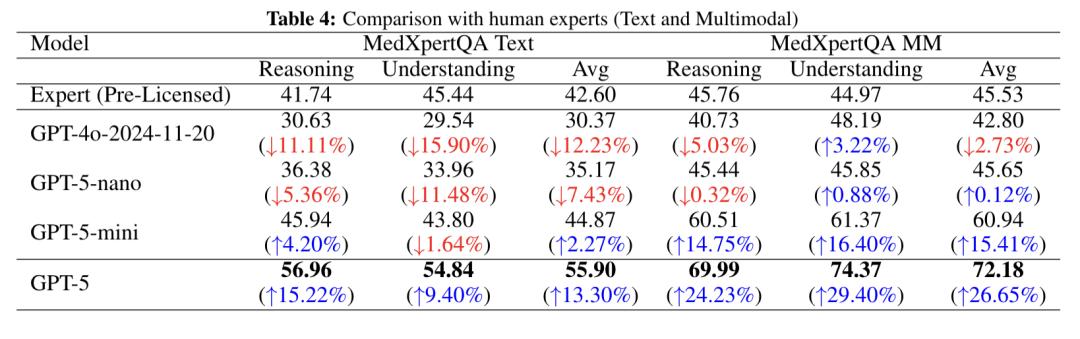
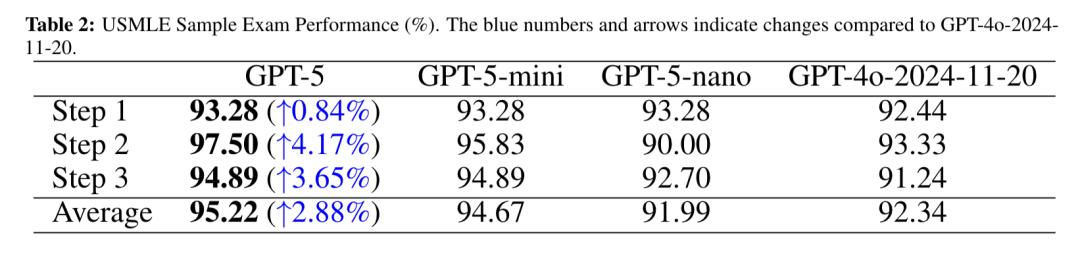
USMLE는 미국 의사면허시험(United States Medical Licensing Examination)으로 , 표준화된 문제와 엄격한 채점 시스템을 갖추고 있습니다. 전 세계 의학 교육 및 인재 평가의 중요한 기준이 되고 있습니다.
시험은 3단계로 나뉩니다. 1단계는 주로 기본 의학 지식을 테스트하고, 2단계는 임상 적용 지식에 중점을 두고, 3단계는 실습에 중점을 둡니다.
이 연구에 따르면 GPT-5는 USMLE 시험의 모든 측면에서 GPT-4o보다 우수했으며, 평균 점수도 다른 모델보다 앞섰습니다.
MedXpertQA 테스트는 모델의 전문 의학 지식과 고급 추론 능력을 평가하는 포괄적인 벤치마크입니다. 텍스트 기반 테스트와 다중 모드 테스트를 모두 포함하며, 17개 의학 전문 분야와 11개 신체 기관에 걸쳐 총 4,460개의 문제를 다룹니다. 데이터는 미국 의사면허시험(USMLE)과 유럽 방사선학회(ECR)를 포함한 20개 이상의 권위 있는 출처에서 수집되었습니다.
다중 모드 MedXpertQA 테스트는 다양한 이미지와 풍부한 임상 정보(의료 기록, 검사 결과 등)를 포함하는 전문가 수준의 시험 문제를 도입하는 MM 하위 집합을 사용하여 수행됩니다.
난이도를 높이기 위해 다중 모드 하위 집합의 질문이 5개 옵션으로 확장되었으며, 이를 통해 실제 상황에서 모델의 의료 진단 추론 능력을 보다 효과적으로 평가할 수 있습니다.
이전 데이터에 따르면 GPT-5의 추론 및 이해 점수는 GPT-4o보다 각각 약 30% 와 36% 더 높습니다.
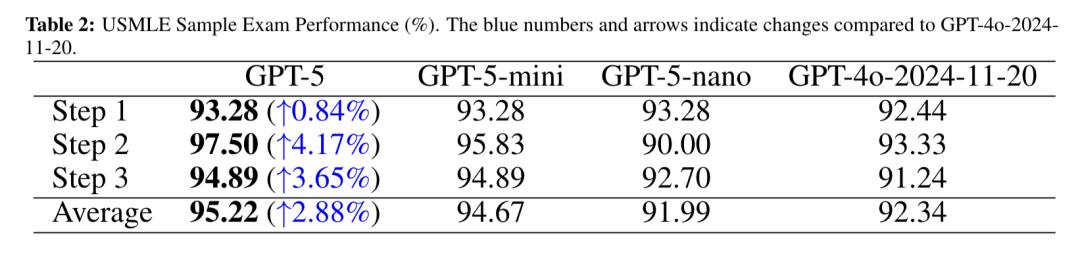
아래 그림은 추론, 이해, 평균화의 세 가지 차원을 포괄하여 MedXpertQA 테스트의 텍스트 하위 집합(Text)과 다중 모드 하위 집합(MM)에 대한 GPT-5 시리즈 모델과 GPT-4o의 무면허 인간 전문가 성과를 비교한 것입니다.
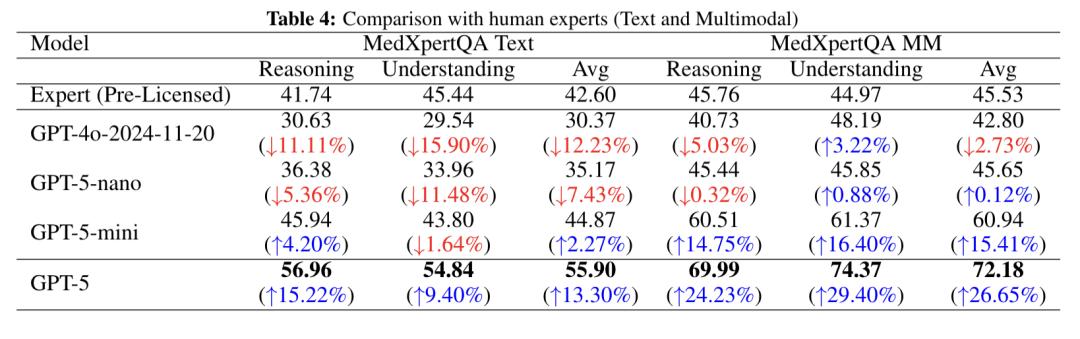
텍스트 테스트에서 GPT-4o는 세 가지 범주 모두에서 인간 전문가보다 낮은 점수를 받았고, GPT-5-nano도 모든 측면에서 뒤처졌으며, GPT-5-mini의 추론 및 평균 점수는 인간 전문가보다 약간 높았고, GPT-5가 가장 좋은 성과를 보였으며 점수에서 상당한 우위를 차지했습니다.
다중 모드 테스트에서 GPT-4o의 추론 점수와 평균 점수는 약간 낮았고, GPT-5-nano는 전반적으로 인간 전문가와 동등했으며, GPT-5-mini는 인간 전문가를 크게 능가했습니다. GPT-5는 추론 점수에서 인간 전문가를 24%, 이해력에서 인간 전문가를 29% 능가하여 가장 큰 우위를 보였으며, 이는 강력한 다중 모드 의학적 추론 능력을 보여줍니다.
VQA-RAD 테스트 는 의료 시각 질의응답 테스트입니다. 이 데이터셋은 315개의 방사선 영상과 3,515개의 질의응답 쌍으로 구성되어 있습니다. 이 테스트는 대규모 다중 모드 의료 언어 모델이 복잡한 의료 영상을 해석하고 정확한 텍스트 설명을 생성하는 능력을 평가하는 데 자주 사용됩니다.
이 연구에서 GPT-5는 70.92%의 일치율을 달성했는데, 이는 GPT-4o와 그 소형 변종인 GPT-5-nano보다 높은 수치이며, 경량 변종인 GPT-5-mini는 74.90%의 엄격한 일치율을 기록하며 약간 더 나은 성능을 보였습니다.

VQA-RAD의 비교적 작은 크기와 영상의학에 특화된 특성을 고려할 때, 이러한 점수 차이는 작은 모델의 데이터 세트 특정적 과적합으로 인한 것일 수 있습니다.
이렇게 많은 테스트 결과를 살펴본 후, GPT-5가 이전 모델인 GPT-4o를 완전히 압도할 수 있는 이유는 무엇일까요?
GPT-5는 엔드투엔드 멀티모달 아키텍처를 구축합니다.
연구팀은 GPT-5의 향상된 기능의 핵심이 향상된 크로스 모달 주의 및 정렬 기능에서 비롯된다고 믿고 있습니다.
GPT-5와 GPT-4o 간의 핵심 격차는 본질적으로 텍스트 중심의 하이브리드 처리 에서 기본 멀티모달 딥 퓨전 으로의 세대적 도약입니다.
여러 모달 작업을 처리할 때 GPT-4o는 여전히 텍스트 번역 + 외부 도구 호출 의 간접 모드에 의존합니다. 예를 들어, 의료 이미지를 구문 분석할 때 먼저 타사 모델을 통해 이미지 정보를 텍스트 설명으로 변환한 다음, 텍스트를 기반으로 추론을 수행해야 합니다.
이러한 모달 변환 중재는 정보 손실을 증가시킬 뿐만 아니라(예를 들어, 이미지의 미묘한 손상은 변환 중에 무시될 수 있음) 추론 체인의 단절로 이어집니다. 모델이 이미지 특징-병리학적 메커니즘-치료 계획 간의 인과 관계를 직접적으로 확립하기 어렵기 때문입니다.
GPT-5는 종단 간 멀티모달 아키텍처를 구축합니다 . 공유 태그 기술을 통해 텍스트, 이미지, 오디오 및 기타 정보를 통합 벡터 공간의 기호로 인코딩한 다음 크로스 모달 주의 메커니즘을 사용하여 인식, 추론 및 의사 결정 간의 원활한 연결을 달성합니다.
또한 연구팀은 GPT-5의 진전이 MedXpertQA Text 및 USMLE Step 2와 같은 추론 집약적 과제에서 더 두드러진다고 믿고 있습니다. 이는 사고 사슬 프롬프트와 GPT-5의 향상된 내부 추론 능력이 상승효과를 형성하여 다단계 추론을 더 정확하게 완료할 수 있기 때문입니다.
그러나 연구진은 GPT-5가 표준 검사에서 좋은 결과를 보였지만, 이 검사는 이상적인 조건에서 수행되었고 질문과 데이터가 표준화되었다는 점에 유의해야 한다고 지적했습니다. 실제로 환자의 상태는 다양하며 다양한 응급 상황에 직면할 수 있습니다.
따라서 GPT-5가 실제로 임상에 보조자로 참여하려면 더 많은 실제 테스트를 거쳐야 할 것입니다.
KCDH_A 디지털 건강 연구 센터는 AI를 위한 영상의학의 궁극적인 테스트를 수행했습니다. 이는 AI가 이전에는 시도하지 않았던 교차 모드 감지 작업으로, CT, MRI, X-ray를 포괄하며 일상 진료에서 실제로 발생하는 복잡한 실제 사례들을 시뮬레이션합니다.
테스트 결과에 따르면 모든 AI 모델은 인턴보다 낮은 점수를 받았고, 면허를 소지한 방사선 전문의는 AI보다 훨씬 앞서 있었습니다. GPT-5는 이제 막 AI 최고 자리에 올랐지만, 여전히 인간보다 훨씬 뒤처져 있습니다.
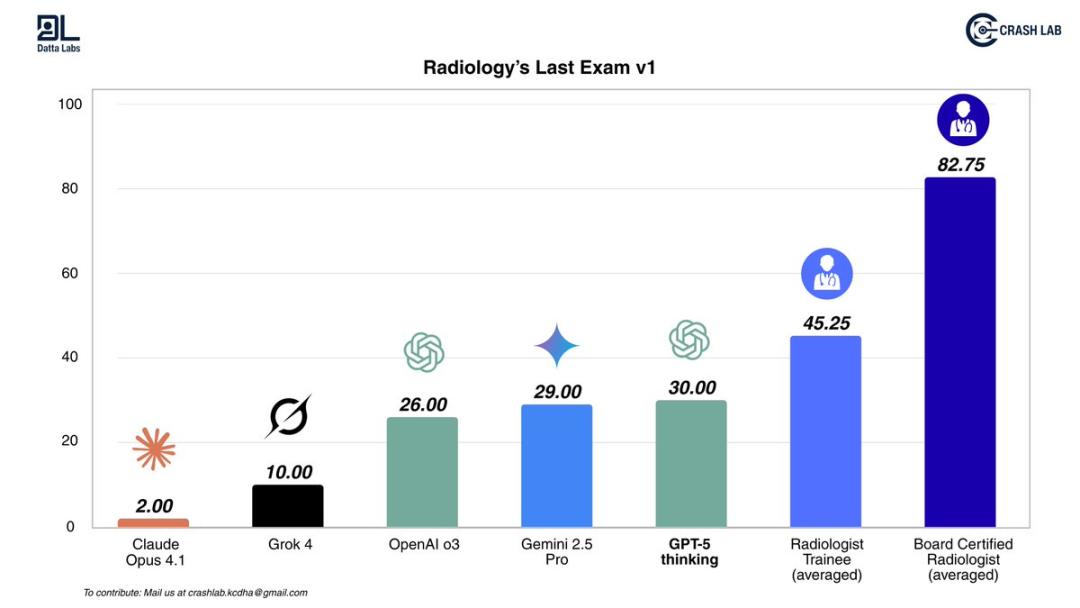
연구실의 연구원들은 다음과 같이 말했습니다.
저는 AI 발전에 큰 기대를 걸고 있으며 저희 연구실에서는 매일 AI 모델을 활용하고 있지만, AI가 방사선과 의사를 대체하는 것과 현실 사이에는 여전히 큰 격차가 있습니다.
이는 AI가 스스로 의료 기록을 읽을 수 있기 전에 먼저 개선이 필요하다는 것을 보여줍니다.
논문 주소: https://arxiv.org/abs/2508.08224
참조 링크:
[1]https://x.com/omarsar0/status/1955252499142627788
[2]https://x.com/emollick/status/1955381296743715241
[3]https://x.com/DrDatta_AIIMS/status/1954586822849523789
본 기사는 WeChat 공개 계정 "Quantum Bit" 에서 발췌하였으며, 저자는 Wen Le이고, 36Kr에서 게시 허가를 받았습니다.





