
이 기사는 기계로 번역되었습니다
원문 표시
바이트댄스는 텍스트를 (스크립트 기반) 비디오로 변환하는 모델을 선보였습니다. 이 모델은 문맥 인식이 가능하고, 고화질이며, 스크립트 기반 기능을 풍부하게 갖추고 있습니다. 서구의 모델은 물리 시뮬레이터에 불과하지만, 이 모델은 진정한 AI 감독 도구입니다.
컴퓨팅 제약 조건으로 인해 최적화가 필수적입니다. 서구는 칩을, 동양은 투지(그리고 데이터)를 가지고 있습니다.
텍스트에서 생성되는 영상이 참조 이미지 컴파운드(COMP) 이나 다른 모델에서 생성되는 영상보다 더 나은 이유는 아마도 바이트댄스가 언어와 동작 간의 의미론적 링크(Chainlink) 누구보다 잘 이해하기 때문일 것입니다 (틱톡과 더우인을 모두 소유한 회사니까요).
바이트댄스는 토큰 효율성 측면에서 중국어와 영어 교육을 모두 활용하는 유일한 기업이 될 가능성이 매우 높으므로, 전 세계에서 가해지는 압력 속에서 번창하는 중국 최고 기술 기업들에 대해 낙관적으로 전망합니다.
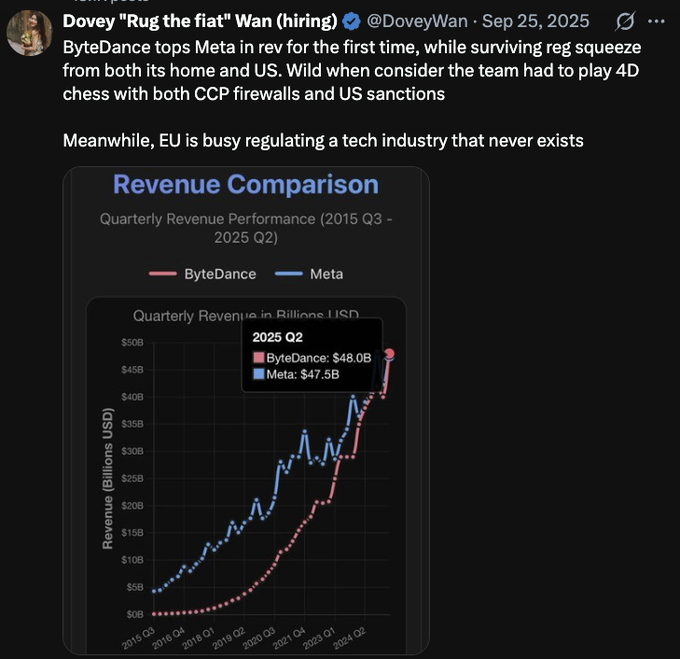
더 많은 UGC 영상, 정말 놀라운 수준의 영화 제작 및 워크플로 최적화
Dorksense
@Dork_sense
Seedance 2.0 from China will be the SOTA
This is AI
We are cooked.
• Native multi-shot storytelling from a single prompt (no more stitching scenes)
• Phoneme-level lip-sync in 8+ languages
• 30% faster generation than v1 via RayFlow optimization • 1080p cinematic quality,
Twitter에서
면책조항: 상기 내용은 작자의 개인적인 의견입니다. 따라서 이는 Followin의 입장과 무관하며 Followin과 관련된 어떠한 투자 제안도 구성하지 않습니다.
라이크
즐겨찾기에 추가
코멘트
공유




