

이 기사는 기계로 번역되었습니다
원문 표시
Karpathy의 자동 연구에서 영감을 받아, 저는 VibeHQ가 단일 에이전트뿐 아니라 전체 다중 에이전트 협업 메커니즘을 스스로 진화시키도록 학습시켰습니다.
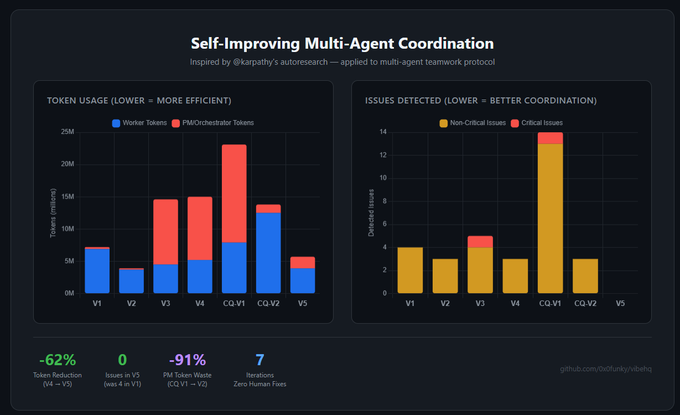
인간의 개입 없이 7번의 완전 자동화 실행 결과:
• 토큰 사용량: 720만 → 570만 (최대값 62% 감소)
• 조정 관련 문제(작업 중복 등) 감소: 4 → 0
• PM 토큰 낭비: -91%
루프: 벤치마크 → 협업 정량화 및 LLM 분석 실패 모드 → /optimize-protocol을 사용하여 조정 코드 재작성 → 재구축 → 반복
AI는 에이전트 팀 협업 실패를 관찰하고, 실패 원인을 분석한 후, 인간의 개입 없이 자체 소스 코드를 수정하여 협업 로직을 조정합니다. AI는 팀 시너지를 완벽하게 자체적으로 관리합니다.
관련 자료를 살펴보면, 자동 연구는 모델 학습을 자동으로 최적화합니다. 이전에는 Ralph가 자율적인 반복 작업을 위해 단일 에이전트를 사용했고, Gastown은 오케스트레이션을 위해 20~30개의 Claude Code 인스턴스를 동시에 실행했지만, 진화적 역량은 보여주지 못했습니다. 이들은 모두 매우 강력했지만, 결국 개별 에이전트의 역량 발전에만 초점을 맞추었습니다.
팀워크 자체, 즉 작업 분담 방법, 갈등 방지 방법, 컨텍스트 공유 방법, 서로의 작업 방해 요소를 해결하는 방법은 진화하고 있지 않습니다. 현실 세계와 마찬가지로 AI 팀도 서로 호흡을 맞추는 데 시간이 필요합니다.
이것이 어떻게 진화할지 상상해 보세요.
• 에이전트들이 자체적인 팀 문화와 시너지를 형성합니다.
• 프로젝트 진행 상황에 따라 3명 또는 7명으로 구성된 팀을 배정하여 프로젝트에 적응합니다.
• 함께 진행하는 프로젝트가 많을수록 팀의 역량이 강화됩니다.
• 에이전트들이 프로젝트 진행 중에 새로운 팀원을 온보딩하고, 작업을 자동으로 재배정합니다.
솔직히, 궁극적으로 어떻게 진화할까요? 저도 모르지만, 바로 그 점이 가장 흥미로운 부분입니다.

Andrej Karpathy
@karpathy
03-10
Three days ago I left autoresearch tuning nanochat for ~2 days on depth=12 model. It found ~20 changes that improved the validation loss. I tested these changes yesterday and all of them were additive and transferred to larger (depth=24) models. Stacking up all of these changes,

자세한 실험 데이터는 이 논문에서 확인할 수 있습니다.
Twitter에서
면책조항: 상기 내용은 작자의 개인적인 의견입니다. 따라서 이는 Followin의 입장과 무관하며 Followin과 관련된 어떠한 투자 제안도 구성하지 않습니다.
라이크
즐겨찾기에 추가
코멘트
공유




