

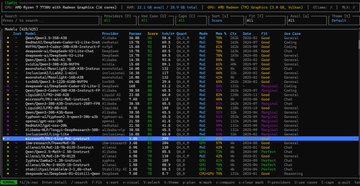
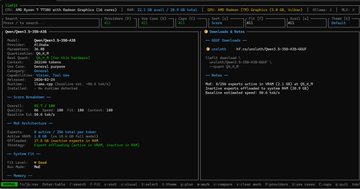
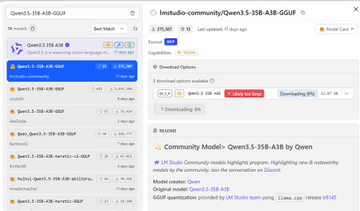
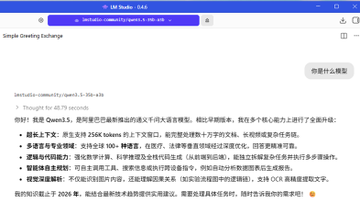
크레이피시 모델을 로컬에서 실행하는 가장 좋은 방법은 Ryzen 7 프로세서가 탑재된 Windows 미니 PC를 사용하는 것입니다. Qwen 3 모델도 로컬에서 실행할 수 있기 때문입니다! 환경: Windows 11 Pro, AMD Ryzen 7 7730U (Radeon 그래픽, 16코어), 32GB RAM 1) PowerShell 관리자 권한으로 scoop을 설치합니다. Set-ExecutionPolicy -ExecutionPolicy RemoteSigned -Scope CurrentUser Invoke-RestMethod -Uri get.scoop.sh | Invoke-Expression 2) scoop을 사용하여 llmfit을 설치합니다. scoop install llmfit 3) llmfit을 실행하고 이 컴퓨터에 가장 적합한 오픈 소스 로컬 대형 모델을 찾습니다. Qwen3.5-35B-A3B (MoE 아키텍처, 총 350억 개의 파라미터 중 30억 개만 활성화됨), 추론 효율이 매우 높으며 모든 가중치를 로드해야 합니다. Q3_K_M ≈ 16-17GB (16GB RAM) Q4_K_M ≈ 21-22GB (32GB RAM) 4) LM Studio(Windows 버전)를 설치합니다. lmstudio.ai 다운로드 후 더블 클릭하여 설치하세요. 5) lmstudio를 실행하고 Qwen3.5-35B-A3B를 검색합니다. Qwen3.5-35B-A3B-GGUF 버전을 선택합니다. Q3_K_M 및 Q4_K_M을 다운로드합니다. 6) 다운로드한 모델을 시작하려면 다음 매개변수를 선택하세요. 컨텍스트 길이: 16384 (안정적이라고 판단되면 32768로 조정) GPU 오프로드: 40으로 증가 (로딩 실패 시 35로 조정) CPU 스레드 풀 크기: 16으로 증가 평가 배치 크기: 512로 변경 최대 동시 예측: 4로 유지 통합 KV 캐시: 활성화 유지 KV 캐시를 GPU 메모리로 오프로드: 활성화 유지 전문가 수: 8로 유지 MoE 가중치를 CPU로 강제 적용할 레이어 수: MoE 레이어가 CPU로 돌아가지 않도록 하려면 0으로 변경 GPU 가속 완벽 지원 플래시 주의: 활성화됨 모델 메모리 유지: 활성화됨 mmap 시도: 활성화됨 RoPE 자동 실행 설정 저장: 다음 번 원클릭 로딩을 위해 체크하세요. 모델 로드 버튼을 클릭하세요. 첫 로딩은 1~3분 정도 소요됩니다(대용량 파일 이동이 필요하기 때문입니다). 잠시 기다려 주세요. 로딩이 완료되면 바로 채팅을 테스트할 수 있습니다. 팁: BIOS에서 iGPU 공유 메모리를 8GB로 설정하면 속도를 더욱 향상시킬 수 있습니다. 채팅을 시작하세요! 100% 현지화된 LLM, 안전하고 신뢰할 수 있습니다.
이 기사는 기계로 번역되었습니다
원문 표시

Kenny.eth
@_0xKenny
03-10
新购龙虾🦞小主机 - Windows Mini PC,甚至可以跑轻量级本地小模型。
放在家里平时帮我处理的大部分网站访问需求,定期缴纳各种费用、查询邮件等等,全部用OpenClaw自动化。
GMKtec M5 Ultra Gaming Mini PC Ryzen 7 7730U (Upgraded 7430U/ 5825U), 32GB RAM 512GB SSD Dual NIC LAN 2.5GbE Desktop




Twitter에서
면책조항: 상기 내용은 작자의 개인적인 의견입니다. 따라서 이는 Followin의 입장과 무관하며 Followin과 관련된 어떠한 투자 제안도 구성하지 않습니다.
라이크
즐겨찾기에 추가
코멘트
공유




