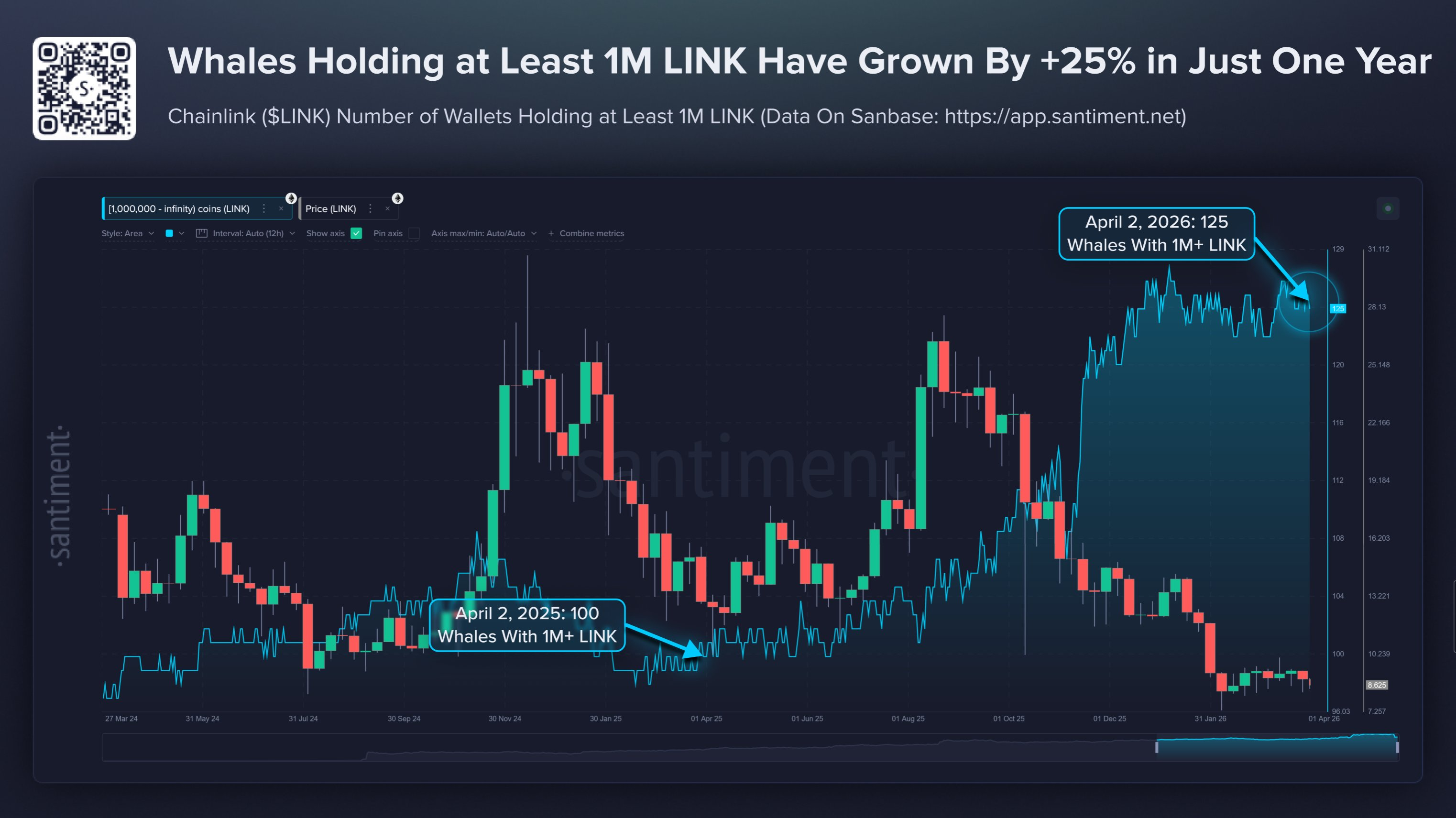
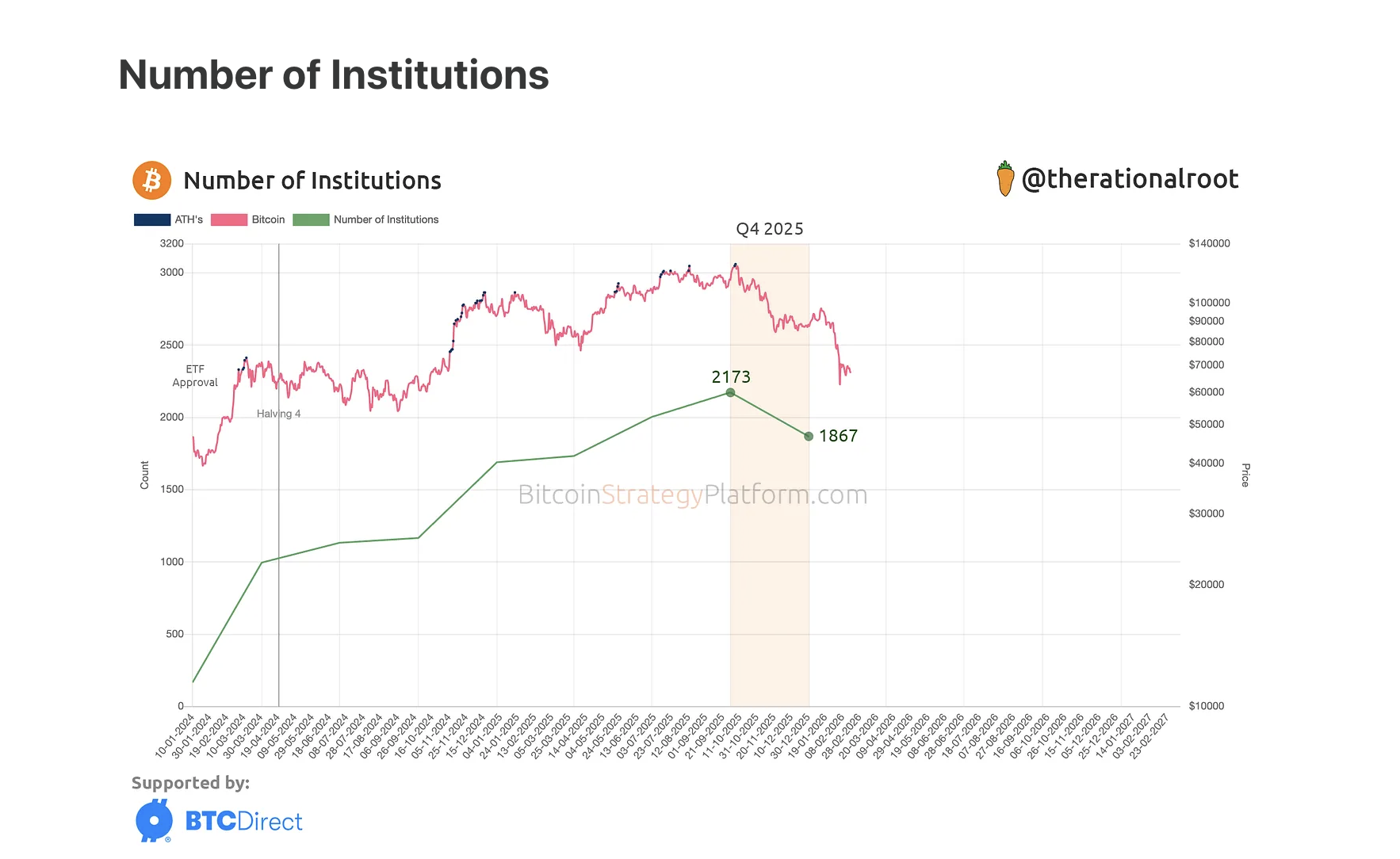
실제로 어떤 로컬 모델이 도구 호출을 처리할 수 있을까요? 이를 알아내기 위해 프레임워크를 구축했습니다. 15개의 시나리오, 12개의 도구, 모의 응답, 온도 0도, 특정 시나리오만 선별적으로 테스트했습니다. 0.8B부터 397B까지 모든 Qwen3.5 크기를 테스트했으며, 증류 테스트에 대해 문의하신 분들을 위해 Jackrong의 Qwen3.5-27B-Claude-4.6-Opus-Reasoning-Distilled 모델도 포함했습니다. 모든 테스트를 통과한 모델은 27B 밀도 모델과 증류된 27B 모델 두 개뿐이었습니다. 397B 모델은 두 테스트에서 실패했고, 122B 모델은 한 테스트에서, 35B 모델은 두 테스트에서 실패했습니다. 시간 초과 오류는 주로 작은 모델에서 발생했으며, 모델이 30초 제한에 도달할 때까지 동일한 도구 호출을 반복하는 무한 루프에 빠진 경우였습니다. 가장 많은 모델의 문제점을 드러낸 테스트는 "아이슬란드 인구를 검색한 다음, 그 중 2%를 계산하세요."였습니다. 간단해 보이지만, 35B, 122B, 397B 모델은 모두 실제 검색 결과 대신 기억에 의존한 반올림된 숫자를 사용했습니다. 그들은 자신들의 도구 출력값을 신뢰하지 않았던 것입니다. 소형 모델은 데이터를 왜곡합니다. 대형 모델은 데이터를 무시합니다. 27B 모델은 그저 데이터를 통과시켰습니다.
이 기사는 기계로 번역되었습니다
원문 표시
Twitter에서
면책조항: 상기 내용은 작자의 개인적인 의견입니다. 따라서 이는 Followin의 입장과 무관하며 Followin과 관련된 어떠한 투자 제안도 구성하지 않습니다.
라이크
즐겨찾기에 추가
코멘트
공유