

원제: ZPU: 영지식 처리 장치
원작자: 인곤야마
원본출처 : 미디엄
편집자: Kate, Marsbit
요약:
이 블로그에서는 영지식 처리에 대한 새로운 요구 사항을 해결하도록 설계된 범용 프로그래밍 가능 하드웨어 가속기 인 영지식 처리 장치(ZPU)를 제안합니다.
우리는 ZPU 아키텍처와 설계 고려 사항을 다룰 것입니다. ZPU 생태계의 다양한 부분(ISA, 데이터 흐름, 메모리 및 처리 요소(PE) 내부) 뒤에 있는 설계 선택을 설명합니다. 마지막으로 ZK와 FHE(완전 동형 암호화)를 최첨단 ASIC 아키텍처와 비교합니다.
소개하다
데이터 기반 애플리케이션의 급속한 성장과 개인 정보 보호에 대한 요구 증가로 인해 민감한 정보를 보호하는 암호화 프로토콜에 대한 관심이 급증했습니다. 이러한 프로토콜 중에서 영지식 증명(ZKP)은 계산 무결성과 개인 정보 보호를 보장하는 강력한 도구로 돋보입니다. ZKP를 사용하면 한 당사자는 추가 정보를 공개하지 않고도 다른 당사자에게 청구의 유효성을 증명할 수 있습니다. 이 기능으로 인해 블록체인 기술, 보안 클라우드 컴퓨팅 솔루션, 검증 가능한 아웃소싱 서비스 등 개인 정보 보호에 초점을 맞춘 다양한 애플리케이션에서 ZKP가 널리 채택되었습니다.
그러나 실제 애플리케이션에 ZKP를 채택하는 것은 증명 생성과 관련된 성능 오버헤드라는 중요한 과제에 직면합니다. ZKP 알고리즘에는 타원 곡선에 대한 대규모 다항식 계산 및 다중 스칼라 곱셈과 같이 매우 큰 정수에 대한 복잡한 수학적 연산이 포함되는 경우가 많습니다. 더욱이 암호화 알고리즘은 지속적으로 발전하고 있으며 새롭고 보다 효율적인 체계가 빠르게 개발되고 있습니다. 따라서 기존 하드웨어 가속기 다양한 암호화 기본 형식과 변화하는 암호화 알고리즘을 따라잡기가 어렵습니다.
이 블로그에서는 영지식 처리에 대한 새로운 요구 사항을 해결하도록 설계된 새로운 다목적 하드웨어 가속기 영지식 처리 장치(ZPU)를 제안합니다. ZPU는 ISA(명령 집합 아키텍처)를 기반으로 구축되었으며 프로그래밍 기능을 지원하므로 빠르게 발전하는 암호화 알고리즘에 적응할 수 있습니다. ZPU에는 대형 단어 모듈 알고리즘을 기본적으로 지원하는 처리 요소(PE)의 상호 연결 네트워크가 있습니다. PE의 핵심 구조는 디지털 신호 처리(DSP) 및 기타 컴퓨팅 시스템의 기본 처리 요소인 MAC(Multiply-Accumulate) 엔진에서 영감을 받았습니다. PE의 연산자는 NTT 나비 연산 및 다중 스칼라 곱셈을 위한 타원 곡선 점 추가와 같은 ZK 알고리즘의 일반적인 연산을 지원하도록 특별히 설계된 핵심 구성 요소와 함께 모듈 알고리즘을 사용합니다.
명령어 세트 아키텍처
ZPU 아키텍처는 아래 그림 1과 같이 ISA(명령어 세트 아키텍처)에 의해 정의된 처리 요소(PE)의 상호 연결 네트워크를 특징으로 합니다. 우리는 영지식 프로토콜의 변화하는 환경에 적응하기 위해 이 아키텍처를 선택했습니다.
ISA 접근 방식을 통해 ZPU는 유연성을 유지하고 ZK 알고리즘의 변경 사항에 적응하며 광범위한 암호화 기본 형식을 지원할 수 있습니다. 또한 고정 하드웨어 대신 ISA를 사용하면 제조 후 소프트웨어를 지속적으로 개선할 수 있으므로 현장에서 새로운 발전이 나타나더라도 ZPU의 관련성과 효율성을 유지할 수 있습니다.
ISA는 프로세서가 실행할 수 있는 명령어 세트입니다. 이는 하드웨어와 소프트웨어 간의 인터페이스 역할을 하며 소프트웨어가 하드웨어와 상호 작용하는 방식을 정의합니다. 맞춤형 ISA로 ZPU를 설계함으로써 대형 프레임 산술 연산, 타원 곡선 암호화 및 기타 복잡한 암호화 연산과 같은 ZK 처리 작업의 특정 요구 사항에 맞게 ZPU를 최적화할 수 있습니다.
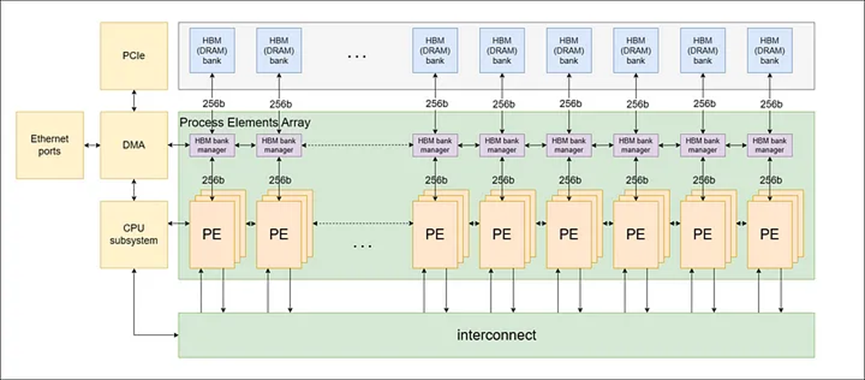
그림 1: PE 네트워크 구조
PE 핵심 부품
각 PE는 그림 2와 같이 모듈식 곱셈기, 가산기, 감산기를 포함하는 코어로 설계되었습니다. 이러한 핵심 구성 요소는 디지털 신호 처리(DSP) 및 기타 컴퓨팅 시스템의 기본 처리 요소인 MAC(곱셈 누적) 엔진에서 영감을 받았습니다. MAC 엔진은 두 숫자를 곱하고 그 결과를 누산기에 추가하는 곱셈 누산 작업을 효율적으로 수행합니다.
PE의 핵심 구조는 다중 스칼라 곱셈을 위한 타원 곡선 점 추가 및 숫자 이론 변환(NTT)을 위한 NTT 나비 연산과 같은 ZK에서 일반적인 연산에 맞게 조정되었습니다. 나비 연산에는 덧셈, 뺄셈, 곱셈이 포함되며 모두 모듈식 연산으로 수행됩니다. 이 작업은 전용 나비 명령을 통해 기본 나비 계산을 구현하므로 PE의 핵심 하드웨어 구성 요소에 잘 맞는 계산 흐름도의 나비 모양에서 이름을 따왔습니다.
또한 각 PE에는 다음을 포함한 여러 전용 메모리 장치가 포함되어 있습니다.
1. 도착 라운지: PE에 도착하는 데이터를 저장하는 데 사용되는 메모리입니다.
2. 출발 라운지: PE에서 출발하는 데이터를 저장하는 데 사용되는 메모리입니다.
3. 피연산자 A, B, C에 대한 임시 저장: 중간 결과를 저장하는 데 세 개의 개별 메모리가 사용됩니다.
4. 메모리 확장기: 다중 스칼라 곱셈(MSM)을 위한 버킷 집계와 같은 다양한 알고리즘의 요구 사항을 처리하는 데 사용되는 다목적 메모리입니다.
5. 프로그램 메모리: 명령 대기열을 저장하는 데 사용되는 메모리입니다.
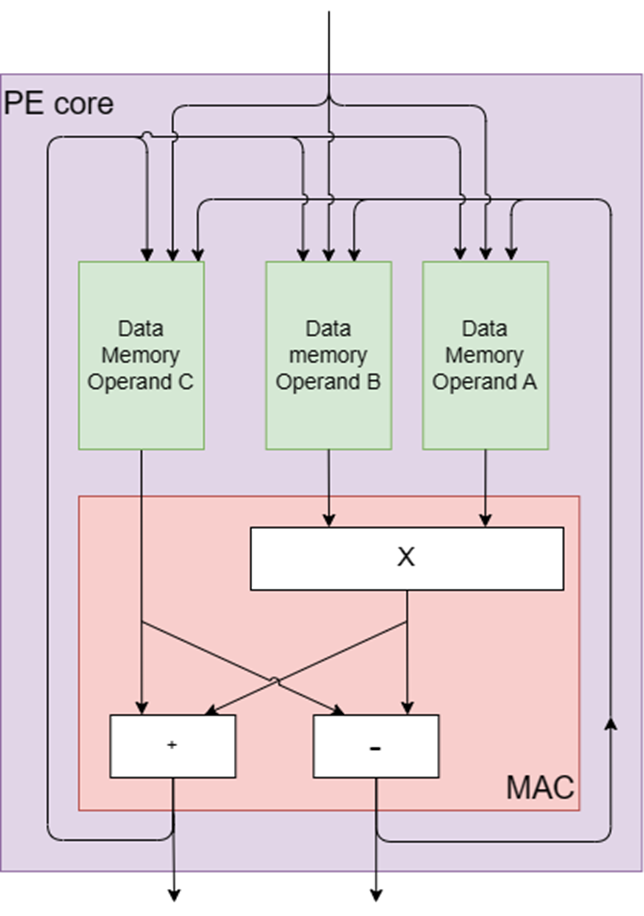
그림 2: PE 핵심 구성요소
PE 비트 폭
PE는 기본적으로 큰 단어 모듈 산술 연산(최대 256비트 단어)을 지원합니다. PE의 높은 비트폭 기본 지원과 낮은 비트폭 기본 지원 간의 균형은 다양한 피연산자 크기의 효율성 균형을 맞춰야 하는 필요성에서 발생합니다.
PE가 높은 비트폭 기본 지원을 제공하는 경우 PE는 더 작은 청크로 나눌 필요 없이 큰 피연산자 크기를 처리하는 데 최적화됩니다. 그러나 PE가 완전히 활용되지 않기 때문에 이 최적화 비용은 더 작은 비트폭 작업의 효율성을 감소시킵니다. 반면에 PE가 낮은 비트폭 기본 지원을 갖는 경우 작은 피연산자 크기를 보다 효율적으로 처리하도록 최적화됩니다. 그러나 PE가 더 큰 피연산자를 더 작은 청크로 나누고 이러한 청크를 순차적으로 처리해야 하기 때문에 이러한 최적화는 더 큰 비트 너비 작업을 처리할 때 비효율성을 초래합니다.
문제는 광범위한 피연산자 크기에 대한 효율적인 처리를 보장하기 위해 높은 비트폭과 낮은 비트폭 기본 지원 간의 올바른 균형을 찾는 것입니다. 이 균형은 대상 애플리케이션 도메인(즉, ZK 프로토콜)에서 널리 퍼져 있는 일반적인 비트 폭을 고려하고 각 설계 선택의 장단점을 평가해야 합니다. ZPU 아키텍처의 경우 256비트 워드 길이가 좋은 균형을 이루도록 선택되었습니다.
체육 연결
모든 PE는 링으로 연결되며, 각 PE는 인접한 두 PE와 직접 연결되어 링 네트워크를 형성합니다. 이 링 연결을 통해 제어 데이터가 서로 다른 PE 간에 효율적으로 전파될 수 있습니다. PE는 또한 시간이 지남에 따라 서로 다른 PE 간의 직접 연결을 가능하게 하는 배럴 시프터와 유사한 메커니즘인 상호 연결 어셈블리를 통해 연결됩니다. 이 설정을 통해 PE는 다른 모든 PE와 정보를 보내고 받을 수 있습니다.
주변 부품
또한 이 아키텍처는 오프칩 고대역폭 메모리(HBM)를 통합하여 높은 메모리 용량과 높은 메모리 대역폭을 지원합니다. 여러 개의 PE가 모여 PE 클러스터를 형성하고, 각 PE 클러스터는 HBM 뱅크나 채널에 연결됩니다. 또한 전체 시스템 작동을 관리하기 위해 ARM 기반 온칩 CPU 하위 시스템이 포함되어 있습니다.
등급
ZPU의 성능을 평가하기 위해 우리는 가속화하려는 알고리즘의 주요 작업을 고려합니다. 우리는 주로 NTT 나비 연산과 타원 곡선(EC) 점 추가 연산을 연구합니다. MSM 및 NTT 작업의 총 계산 시간을 평가하기 위해 필요한 총 계산 명령 수를 계산하고 이를 클럭 주파수와 PE 수로 나눴습니다.
NTT 버터플라이 연산은 매 클록 주기마다 수행됩니다. MSM(다중 스칼라 곱셈)의 핵심 요소인 타원 곡선 점 추가 작업의 경우 이를 단일 PE에서 실행할 수 있는 기본 기계 수준 명령으로 분해합니다. 그런 다음 이 작업을 완료하는 데 필요한 클록 사이클 수를 계산합니다. 분석을 통해 우리는 각 타원 곡선 점 추가 작업이 18클럭 사이클마다 한 번씩 수행될 수 있음을 확인했습니다.
이러한 가정은 성능 평가의 기초를 제공하며 다양한 알고리즘 요구 사항이나 하드웨어 기능을 반영하기 위해 필요에 따라 조정될 수 있습니다.
우리의 계산에 따르면 GPU의 1.305GHz 주파수에서 실행되는 72개의 PE 구성은 Zprize 의 MSM 작업에서 GPU 카테고리 우승자의 성능과 일치하기에 충분합니다. Yrrid Software와 Matter Labs는 모두 A40 NVIDIA GPU를 사용하여 4MSM 계산당 2.52초의 결과를 달성하여 이러한 성과를 달성했습니다. 비교는 BLS 12-377 스칼라 필드에서 무작위로 선택된 2²⁶ 스칼라, BLS 12-377 G1 곡선의 고정 타원 곡선 점 세트 및 무작위로 샘플링된 입력 벡터의 유한 세트를 포함하는 고정 기준점 MSM 계산을 기반으로 합니다. 스칼라 필드 요소.
PE 면적 추정에 따르면 A40 GPU에 사용된 것과 동일한 공정 기술인 8nm 공정을 사용하는 ASIC은 A40 GPU와 동일한 628mm2 면적에 약 925개의 PE를 수용할 수 있습니다. 이는 A40 GPU보다 약 13배 더 높은 효율성을 달성했음을 의미합니다.
PipeZK는 다중 스칼라 곱셈 및 대규모 다항식 계산 처리에 각각 최적화된 전용 MSM 및 NTT 코어를 사용하여 영지식 증명(ZKP) 생성 성능을 향상시키도록 설계된 효율적인 파이프 가속기 입니다.
PipeZK와 비교하여 300MHz의 PipeZK 주파수에서 작동하는 17개의 PE 구성만으로도 PipeZK의 MSM 작동 성능을 일치시키기에 충분하다는 것을 발견했습니다. PipeZK는 BN128 곡선에서 2²⁰ 길이의 MSM에 대해 300MHz에서 MSM 작업을 수행했으며 완료하는 데 0.061초가 걸렸습니다. 또한 300MHz에서 0.011초 내에 256비트 요소가 포함된 2²⁰ 요소 NTT를 실행하는 PipeZK의 NTT 작동 성능과 일치하려면 동일한 주파수에서 실행되는 약 4개의 PE가 필요합니다. 전체적으로 MSM과 NTT를 동시에 실행하는 PipeZK의 성능을 맞추려면 21개의 PE가 필요합니다.
우리의 면적 추정에 따르면 28nm 공정(PipeZK에서 사용된 것과 동일한 공정 기술)을 사용하는 ASIC은 PipeZK 칩과 동일한 50.75mm2 면적에 약 16개의 PE를 수용할 수 있습니다. 이는 PipeZK의 고정 아키텍처보다 효율성이 약간 떨어지지만(25% 효율성 낮음) 여전히 다양한 타원 곡선 및 ZK 프로토콜에 적응할 수 있는 유연성을 갖추고 있음을 의미합니다.
RPU( 링 처리 장치 )는 동형 암호화 및 양자 후 암호화와 같은 다양한 보안 및 개인 정보 보호 기술의 기초가 되는 RLWE(Ring-based Learning with Errors)의 계산을 가속화하기 위한 최근 노력입니다.
RPU와 비교하여 우리의 계산에 따르면 128비트 요소에 대해 64K NTT를 계산할 때 최적의 구성(128개 뱅크 및 HPLE)에서 RPU의 성능을 일치시키려면 RPU의 1.68GHz에서 약 23개의 PE가 필요합니다. 주파수가 계속 실행됩니다. 우리의 분석에 따르면 RPU와 동일한 12nm 공정 기술을 사용하는 ASIC은 RPU가 차지하는 20.5mm² 영역 내에서 약 19.65개의 PE를 수용할 수 있습니다. 이는 NTT 이외의 기본 요소와 호환되는 동시에 RPU보다 약간 덜 효율적(15% 덜 효율적)임을 의미합니다.
TREBUCHET는 RPU(링 처리 장치)를 온칩 블록으로 사용하는 FHE(완전 동형 암호화) 가속기 입니다. 또한 슬라이스는 컴퓨팅 요소에 가까운 데이터를 예약하여 메모리 관리를 용이하게 합니다. RPU는 장치 전반에 걸쳐 복제되므로 소프트웨어가 데이터 이동을 최소화하고 데이터 수준 병렬성을 활용할 수 있습니다.
TREBUCHET과 ZPU는 모두 모듈 알고리즘에서 매우 긴 단어(128비트 이상)를 지원하는 ISA 아키텍처와 대규모 산술 단어 엔진을 기반으로 합니다. 그러나 RPU 또는 TREBUCHET SoC에 비해 ZPU의 부가 가치는 아키텍처가 해결하도록 설계된 문제 집합을 확장한다는 것입니다. RPU와 TREBUCHET는 주로 NTT에 중점을 두는 반면, ZPU는 MSM(다중 스칼라 곱셈) 및 산술 지향 해시 함수와 같은 더 많은 기본 형식을 지원합니다.
요약하다
우리의 성능 평가는 ZPU가 기존 최첨단 ASIC 설계의 성능과 일치하거나 이를 능가하는 동시에 ZK 알고리즘 및 암호화 기본 요소의 변경에 더 큰 적응성을 제공할 수 있음을 보여줍니다. PE의 높은 비트폭 지원과 낮은 비트폭 지원 간의 균형과 같이 고려해야 할 장단점이 있지만 ZPU의 설계는 광범위한 피연산자 크기에 걸쳐 효율적인 처리를 보장하도록 신중하게 최적화되었습니다. ZPU에 대해 더 자세히 알아보거나 잠재적인 협력을 모색하는 데 관심이 있는 분들은 언제든지 저희에게 연락해 주세요. ZPU 프로젝트의 진행 상황과 향후 개발에 대한 추가 업데이트를 여러분과 공유할 수 있기를 기대합니다.
리뷰를 작성해주신 Weikeng Chen 에게 감사드립니다.



