tác giả:IOSG
TL/DR
Chúng tôi đã thảo luận về cách AI và Web3 có thể phát huy điểm mạnh của nhau và bổ sung cho nhau trong các ngành dọc khác nhau như mạng máy tính, nền tảng đại lý và ứng dụng tiêu dùng. Khi tập trung vào lĩnh vực tài nguyên dữ liệu theo chiều dọc, dự án đại diện Web3 cung cấp các khả năng mới để thu thập, chia sẻ và sử dụng dữ liệu.
• Các nhà cung cấp dữ liệu truyền thống khó có thể đáp ứng nhu cầu của AI và các ngành dựa trên dữ liệu khác để có dữ liệu có thể xác minh theo thời gian thực, chất lượng cao, đặc biệt là về tính minh bạch, kiểm soát người dùng và bảo vệ quyền riêng tư.
• Các giải pháp Web3 đang nỗ lực định hình lại hệ sinh thái dữ liệu. Các công nghệ như MPC, Bằng chứng không tri thức và TLS Notary đảm bảo tính xác thực và bảo vệ quyền riêng tư của dữ liệu khi dữ liệu được truyền giữa nhiều nguồn, trong khi lưu trữ phân tán và điện toán biên mang lại sự linh hoạt và hiệu quả cao hơn cho việc xử lý dữ liệu theo thời gian thực.
• Trong đó, cơ sở hạ tầng mới nổi của mạng dữ liệu phi tập trung đã tạo ra một số dự án tiêu biểu: OpenLayer (lớp dữ liệu thực mô-đun ), Grass (sử dụng băng thông nhàn rỗi của người dùng và mạng nút trình thu thập thông tin phi tập trung ) và Vana (lớp chủ quyền dữ liệu người dùng 1), sử dụng. những con đường kỹ thuật khác nhau để mở ra những triển vọng mới cho lĩnh vực đào tạo và ứng dụng AI.
• Thông qua khả năng huy động từ cộng đồng, các lớp trừu tượng không cần tin cậy và cơ chế khích lệ dựa trên mã thông token , cơ sở hạ tầng dữ liệu phi tập trung có thể cung cấp các giải pháp riêng tư, an toàn, hiệu quả và tiết kiệm hơn so với các nhà cung cấp dịch vụ siêu quy mô Web2, đồng thời trao quyền cho người dùng kiểm soát dữ liệu và các tài nguyên liên quan để xây dựng một môi trường rộng lớn hơn. hệ sinh thái kỹ thuật số mở, an toàn và có khả năng tương tác.
1. Làn sóng nhu cầu dữ liệu
Dữ liệu đã trở thành động lực chính cho sự đổi mới và ra quyết định trong các ngành công nghiệp. UBS dự đoán rằng khối lượng dữ liệu toàn cầu dự kiến sẽ tăng trưởng hơn 10 lần từ năm 2020 đến năm 2030, đạt 660 ZB. Đến năm 2025, mỗi người trên thế giới sẽ tạo ra 463 EB (Exabyte, 1 EB = 1 tỷ GB) dữ liệu mỗi ngày. Thị trường dữ liệu dưới dạng dịch vụ (DaaS) đang mở rộng nhanh chóng. Theo báo cáo của Grand View Research, thị trường DaaS toàn cầu sẽ có giá trị 14,36 tỷ USD vào năm 2023 và dự kiến tăng trưởng với tăng trưởng là 28,1% vào năm 2030, cuối cùng đạt 76,8 tỷ USD. Đằng sau những con số tăng trưởng cao này là nhu cầu về dữ liệu chất lượng cao, thời gian thực và đáng tin cậy trong nhiều lĩnh vực công nghiệp.
Việc đào tạo mô hình AI dựa vào lượng lớn dữ liệu đầu vào để xác định các mẫu và điều chỉnh các tham số. Sau khi đào tạo, dữ liệu cũng cần thiết để kiểm tra hiệu suất và khả năng khái quát hóa của mô hình. Ngoài ra, tác nhân AI, với tư cách là một dạng ứng dụng thông minh mới nổi có thể thấy trước trong tương lai, yêu cầu nguồn dữ liệu đáng tin cậy và thời gian thực để đảm bảo đưa ra quyết định và thực hiện nhiệm vụ chính xác. (Nguồn: Leewayhertz)
Việc đào tạo mô hình AI dựa vào lượng lớn dữ liệu đầu vào để xác định các mẫu và điều chỉnh các tham số. Sau khi đào tạo, dữ liệu cũng cần thiết để kiểm tra hiệu suất và khả năng khái quát hóa của mô hình. Ngoài ra, tác nhân AI, với tư cách là một dạng ứng dụng thông minh mới nổi có thể thấy trước trong tương lai, yêu cầu nguồn dữ liệu đáng tin cậy và thời gian thực để đảm bảo đưa ra quyết định và thực hiện nhiệm vụ chính xác. (Nguồn: Leewayhertz)
Nhu cầu phân tích kinh doanh cũng ngày càng đa dạng và phong phú, đồng thời trở thành công cụ cốt lõi thúc đẩy sự đổi mới của doanh nghiệp. Ví dụ: các nền tảng truyền thông xã hội và các công ty nghiên cứu thị trường cần dữ liệu hành vi người dùng đáng tin cậy để xây dựng chiến lược và hiểu rõ hơn về xu hướng, tích hợp dữ liệu đa dạng từ nhiều nền tảng xã hội và xây dựng hồ sơ người dùng toàn diện hơn.
Đối với hệ sinh thái Web3, dữ liệu thực và đáng tin cậy cũng cần thiết trên Chuỗi để hỗ trợ một số sản phẩm tài chính mới. Khi ngày càng có nhiều tài sản mới được mã hóa, cần có giao diện dữ liệu linh hoạt và đáng tin cậy để hỗ trợ phát triển các sản phẩm đổi mới và quản lý rủi ro, để các hợp đồng thông minh có thể được thực thi dựa trên dữ liệu thời gian thực có thể kiểm chứng được. Ngoài ra còn có các lĩnh vực như nghiên cứu khoa học và Internet of Things (IoT).
Các trường hợp sử dụng mới minh họa sự gia tăng nhu cầu về dữ liệu đa dạng, thời gian thực, theo thời gian thực trong các ngành và các hệ thống cũ có thể gặp khó khăn trong việc đối phó với khối lượng dữ liệu tăng trưởng nhanh và nhu cầu thay đổi.
2. Hạn chế và vấn đề của sinh thái dữ liệu truyền thống
Một hệ sinh thái dữ liệu điển hình bao gồm thu thập, lưu trữ, xử lý, phân tích và ứng dụng dữ liệu. Mô hình tập trung được đặc trưng bởi việc thu thập và lưu trữ dữ liệu tập trung, vận hành và bảo trì do đội ngũ CNTT cốt lõi của doanh nghiệp quản lý và kiểm soát truy cập nghiêm ngặt.
Ví dụ: hệ sinh thái dữ liệu của Google bao gồm nhiều nguồn dữ liệu từ các công cụ tìm kiếm, Gmail cho đến hệ điều hành Android. Dữ liệu người dùng được thu thập thông qua các nền tảng này, được lưu trữ trong các trung tâm dữ liệu được phân phối trên toàn cầu, sau đó được xử lý và phân tích bằng các thuật toán để hỗ trợ nhiều hoạt động Phát triển và tối ưu hóa khác nhau. sản phẩm và dịch vụ.
Trong thị trường tài chính, lấy LSEG (trước đây là Refinitiv) làm ví dụ, dữ liệu và cơ sở hạ tầng của nó lấy dữ liệu lịch sử và thời gian lịch sử từ sàn giao dịch toàn cầu, ngân hàng và các tổ chức tài chính lớn khác, đồng thời sử dụng mạng Reuters News của riêng mình để thu thập tin tức liên quan đến thị trường Các thuật toán và mô hình độc quyền được sử dụng để tạo ra dữ liệu phân tích và đánh giá rủi ro , có sẵn dưới dạng các sản phẩm bổ sung.
Kiến trúc dữ liệu truyền thống có hiệu quả trong các dịch vụ chuyên nghiệp, nhưng những hạn chế của mô hình tập trung ngày càng trở nên rõ ràng. Đặc biệt về phạm vi bao phủ, tính minh bạch và bảo vệ quyền riêng tư của người dùng đối với các nguồn dữ liệu mới nổi, hệ sinh thái dữ liệu truyền thống đang phải đối mặt với nhiều thách thức. Dưới đây là một vài ví dụ:
• Phạm vi bao phủ dữ liệu không đầy đủ: Các nhà cung cấp dữ liệu truyền thống gặp thách thức trong việc nhanh chóng nắm bắt và phân tích các nguồn dữ liệu mới nổi như tâm lý trên mạng xã hội, dữ liệu thiết bị IoT, v.v. Các hệ thống tập trung gặp khó khăn trong việc thu thập và tích hợp một cách hiệu quả dữ liệu“đuôi dài” từ nhiều nguồn quy mô nhỏ hoặc không chính thống.
Kiến trúc dữ liệu truyền thống có hiệu quả trong các dịch vụ chuyên nghiệp, nhưng những hạn chế của mô hình tập trung ngày càng trở nên rõ ràng. Đặc biệt về phạm vi bao phủ, tính minh bạch và bảo vệ quyền riêng tư của người dùng đối với các nguồn dữ liệu mới nổi, hệ sinh thái dữ liệu truyền thống đang phải đối mặt với nhiều thách thức. Dưới đây là một vài ví dụ:
• Phạm vi bao phủ dữ liệu không đầy đủ: Các nhà cung cấp dữ liệu truyền thống gặp thách thức trong việc nhanh chóng nắm bắt và phân tích các nguồn dữ liệu mới nổi như tâm lý trên mạng xã hội, dữ liệu thiết bị IoT, v.v. Các hệ thống tập trung gặp khó khăn trong việc thu thập và tích hợp một cách hiệu quả dữ liệu“đuôi dài” từ nhiều nguồn quy mô nhỏ hoặc không chính thống.
Ví dụ, sự cố GameStop năm 2021 cũng bộc lộ những hạn chế của các nhà cung cấp dữ liệu tài chính truyền thống trong việc phân tích tâm lý trên mạng xã hội. Tâm lý nhà đầu tư trên các nền tảng như Reddit nhanh chóng thay đổi xu hướng thị trường, nhưng các thiết bị đầu cuối dữ liệu như Bloomberg và Reuters không nắm bắt kịp thời những động lực này, khiến việc dự đoán thị trường trở nên khó khăn hơn.
• Khả năng tiếp cận dữ liệu hạn chế: Độc quyền hạn chế khả năng tiếp cận. Nhiều nhà cung cấp truyền thống mở một số dữ liệu thông qua dịch vụ API/đám mây, nhưng phí truy cập cao và quy trình ủy quyền phức tạp vẫn làm tăng khó khăn trong việc tích hợp dữ liệu.
Rất khó để các nhà phát triển trên Chuỗi truy cập nhanh chóng dữ liệu ngoài Chuỗi đáng tin cậy. Dữ liệu chất lượng cao bị một số gã khổng lồ độc quyền và chi phí truy cập cao.
• Các vấn đề về tính minh bạch và độ tin cậy dữ liệu: Nhiều nhà cung cấp dữ liệu tập trung thiếu tính minh bạch về phương pháp thu thập và xử lý dữ liệu của họ cũng như thiếu các cơ chế hiệu quả để xác minh tính xác thực và tính toàn vẹn của dữ liệu quy mô lớn. Việc xác minh dữ liệu thời gian thực quy mô lớn vẫn là một vấn đề phức tạp và tính chất tập trung cũng làm tăng rủi ro dữ liệu bị giả mạo hoặc thao túng.
• Bảo vệ quyền riêng tư và quyền sở hữu dữ liệu: Dữ liệu người dùng được sử dụng rộng rãi bởi các công ty công nghệ lớn và nền tảng thương mại quy mô lớn. Là người tạo ra dữ liệu riêng tư, người dùng khó có thể nhận được lợi nhuận có giá trị từ họ. Người dùng thường không hiểu cách thu thập, xử lý và sử dụng dữ liệu của họ và họ khó quyết định phạm vi và cách thức sử dụng dữ liệu. Việc thu thập và sử dụng dữ liệu quá mức sẽ dẫn đến rủi ro nghiêm trọng về quyền riêng tư.
Ví dụ: sự cố Cambridge Analytica của Facebook đã tiết lộ những lỗ hổng lớn trong cách các nhà cung cấp dữ liệu truyền thống không bảo vệ được tính minh bạch và quyền riêng tư khi sử dụng dữ liệu.
• Kho dữ liệu: Ngoài ra, dữ liệu phân tán từ các nguồn và định dạng khác nhau khó có thể tích hợp nhanh chóng, ảnh hưởng đến khả năng phân tích toàn diện. Nhiều dữ liệu thường bị khóa trong các tổ chức, hạn chế việc chia sẻ và đổi mới dữ liệu giữa các ngành và tổ chức. Hiệu ứng silo dữ liệu cản trở việc tích hợp và phân tích dữ liệu giữa các miền.
Ví dụ, trong ngành tiêu dùng, các thương hiệu cần tích hợp dữ liệu từ nền tảng thương mại điện tử, cửa hàng thực tế, mạng xã hội và nghiên cứu thị trường. Tuy nhiên, dữ liệu này có thể khó tích hợp do các hình thức nền tảng không nhất quán hoặc biệt lập. Một ví dụ khác, các công ty chia sẻ chuyến đi như Uber và Lyft thu thập lượng lớn dữ liệu thời gian thực từ người dùng về phương tiện đi lại, nhu cầu của hành khách và vị trí địa lý, nhưng do cạnh tranh nên dữ liệu này không thể được đề xuất và chia sẻ để tích hợp.
Ngoài ra, còn có các vấn đề như hiệu quả chi phí và tính linh hoạt. Các nhà cung cấp dữ liệu truyền thống đang tích cực ứng phó với những thách thức này, nhưng sự xuất hiện đột ngột của công nghệ Web3 mang lại những ý tưởng và khả năng mới để giải quyết những vấn đề này.
Ví dụ, trong ngành tiêu dùng, các thương hiệu cần tích hợp dữ liệu từ nền tảng thương mại điện tử, cửa hàng thực tế, mạng xã hội và nghiên cứu thị trường. Tuy nhiên, dữ liệu này có thể khó tích hợp do các hình thức nền tảng không nhất quán hoặc biệt lập. Một ví dụ khác, các công ty chia sẻ chuyến đi như Uber và Lyft thu thập lượng lớn dữ liệu thời gian thực từ người dùng về phương tiện đi lại, nhu cầu của hành khách và vị trí địa lý, nhưng do cạnh tranh nên dữ liệu này không thể được đề xuất và chia sẻ để tích hợp.
Ngoài ra, còn có các vấn đề như hiệu quả chi phí và tính linh hoạt. Các nhà cung cấp dữ liệu truyền thống đang tích cực ứng phó với những thách thức này, nhưng sự xuất hiện đột ngột của công nghệ Web3 mang lại những ý tưởng và khả năng mới để giải quyết những vấn đề này.
3. Sinh thái dữ liệu Web3
Kể từ khi phát hành các giải pháp lưu trữ phi tập trung như IPFS (Hệ thống tệp liên hành tinh) vào năm 2014, sê-ri dự án mới nổi đã xuất hiện trong ngành, nhằm giải quyết những hạn chế của hệ sinh thái dữ liệu truyền thống. Chúng tôi thấy phi tập trung các giải pháp dữ liệu phi tập trung đã hình thành một hệ sinh thái liên kết, nhiều lớp, bao gồm tất cả các giai đoạn của vòng đời dữ liệu dữ liệu , bao gồm tạo, lưu trữ, trao đổi, xử lý và phân tích, xác minh và bảo mật cũng như quyền riêng tư và quyền sở hữu.
• Lưu trữ dữ liệu: Sự phát triển nhanh chóng của Filecoin và Arweave chứng tỏ phi tập trung(DCS) đang trở thành một sự thay đổi mô hình trong lĩnh vực lưu trữ. Giải pháp DCS giảm rủi ro lỗi đơn lẻ thông qua kiến trúc phân tán đồng thời thu hút người tham gia với hiệu quả chi phí cạnh tranh hơn. Với sự xuất hiện của sê-ri trường hợp ứng dụng quy mô lớn, dung lượng lưu trữ của DCS đã có sự tăng trưởng bùng nổ (ví dụ: tổng dung lượng lưu trữ của mạng Filecoin đã đạt 22 exabyte vào năm 2024).
• Xử lý và phân tích: Các nền tảng điện toán dữ liệu phi tập trung như Fluence cải thiện thời gian thực và hiệu quả xử lý dữ liệu thông qua công nghệ điện toán biên, đặc biệt phù hợp với các ứng dụng có yêu cầu thời gian thực cao như Internet of Things (IoT) và lý luận AI . bối cảnh. Dự án Web3 sử dụng phương pháp học tập liên kết, quyền riêng tư khác biệt, hoàn cảnh thực thi đáng tin cậy, crypto đồng hình hoàn toàn và các công nghệ khác để cung cấp sự bảo vệ quyền riêng tư linh hoạt và sự cân bằng ở lớp điện toán.
• Nền tảng trao đổi/thị trường dữ liệu: Để thúc đẩy việc đánh giá lại và lưu thông dữ liệu, Ocean Protocol đã tạo ra các kênh trao đổi dữ liệu mở và hiệu quả thông qua cơ chế token hóa và DEX, chẳng hạn như hỗ trợ các công ty sản xuất truyền thống (Daimler, công ty mẹ của Mercedes-Benz) hợp tác phát triển dữ liệu Thị trường trao đổi để hỗ trợ chia sẻ dữ liệu trong quản lý Chuỗi cung ứng. Mặt khác, Streamr đã tạo ra một mạng truyền dữ liệu dựa trên đăng ký, không cần cấp phép, phù hợp với các kịch bản phân tích thời gian thực và IoT, cho thấy tiềm năng tuyệt vời trong các dự án vận tải và hậu cần (chẳng hạn như làm việc với dự án Thành phố thông minh của Phần Lan).
Với tần suất trao đổi và sử dụng dữ liệu ngày càng tăng, tính xác thực, độ tin cậy và bảo vệ quyền riêng tư dữ liệu đã trở thành những vấn đề then chốt không thể bỏ qua. Điều này thúc đẩy hệ sinh thái Web3 tiếp tục đổi mới và thử nghiệm trong các lĩnh vực xác minh dữ liệu và bảo vệ quyền riêng tư, tạo ra sê-ri giải pháp đột phá.
3.1 Đổi mới trong xác minh dữ liệu và bảo vệ quyền riêng tư
Nhiều công nghệ web3 và các dự án gốc đang nỗ lực giải quyết các vấn đề về xác thực dữ liệu và bảo vệ dữ liệu sở hữu tư nhân . Ngoài ZK, các phát triển công nghệ như MPC cũng được sử dụng rộng rãi. Trong đó, Công chứng giao thức bảo mật lớp vận chuyển (TLS Notary) đặc biệt đáng được chú ý như một phương pháp xác minh mới nổi. Giới thiệu công chứng TLS Bảo mật lớp vận chuyển (TLS) là một giao thức crypto được sử dụng rộng rãi cho truyền thông mạng nhằm đảm bảo tính bảo mật, tính toàn vẹn và bảo mật của việc truyền dữ liệu giữa máy trạm và máy chủ. Đây là một tiêu chuẩn crypto phổ biến trong truyền thông mạng hiện đại và được sử dụng trong nhiều tình huống như HTTPS, email và nhắn tin tức thời.
3.1 Đổi mới trong xác minh dữ liệu và bảo vệ quyền riêng tư
Nhiều công nghệ web3 và các dự án gốc đang nỗ lực giải quyết các vấn đề về xác thực dữ liệu và bảo vệ dữ liệu sở hữu tư nhân . Ngoài ZK, các phát triển công nghệ như MPC cũng được sử dụng rộng rãi. Trong đó, Công chứng giao thức bảo mật lớp vận chuyển (TLS Notary) đặc biệt đáng được chú ý như một phương pháp xác minh mới nổi. Giới thiệu công chứng TLS Bảo mật lớp vận chuyển (TLS) là một giao thức crypto được sử dụng rộng rãi cho truyền thông mạng nhằm đảm bảo tính bảo mật, tính toàn vẹn và bảo mật của việc truyền dữ liệu giữa máy trạm và máy chủ. Đây là một tiêu chuẩn crypto phổ biến trong truyền thông mạng hiện đại và được sử dụng trong nhiều tình huống như HTTPS, email và nhắn tin tức thời.
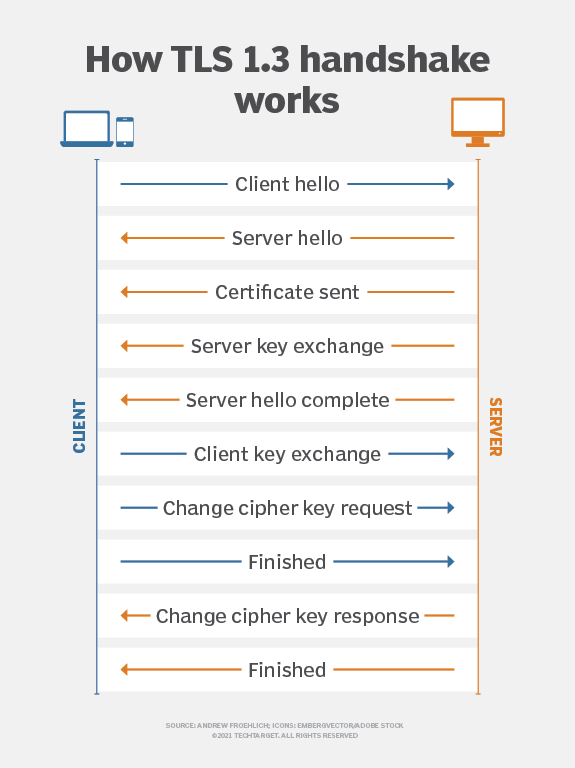
Khi ra đời cách đây mười năm, mục tiêu ban đầu của TLS Notary là xác minh tính xác thực của các phiên TLS bằng cách giới thiệu một “công chứng viên” bên thứ ba ngoài máy trạm(Prover) và máy chủ.
Bằng cách sử dụng tính năng phân tách khóa, khóa chính cho phiên TLS được chia thành hai phần, do máy trạm và công chứng viên nắm giữ. Thiết kế này cho phép công chứng viên tham gia vào quá trình xác minh với tư cách là bên thứ ba đáng tin cậy nhưng không có quyền truy cập vào nội dung liên lạc thực tế. Cơ chế công chứng này được thiết kế để phát hiện các cuộc tấn công trung gian, ngăn chặn chứng chỉ gian lận, đảm bảo dữ liệu liên lạc không bị giả mạo trong quá trình truyền và cho phép bên thứ ba đáng tin cậy xác nhận tính hợp pháp của liên lạc trong khi bảo vệ quyền riêng tư liên lạc.
Do đó, TLS Notary cung cấp khả năng xác minh dữ liệu an toàn và cân bằng hiệu quả các yêu cầu xác minh cũng như bảo vệ quyền riêng tư.
Vào năm 2022, dự án TLS Notary được xây dựng lại từ đầu bởi phòng thí nghiệm nghiên cứu Khám phá quy mở rộng và quyền riêng tư (PSE) của Ethereum Foundation. Phiên bản mới của giao thức TLS Notary được viết lại từ đầu bằng ngôn ngữ Rust và kết hợp các giao thức crypto nâng cao hơn (chẳng hạn như MPC). Các tính năng giao thức mới cho phép người dùng chứng minh cho bên thứ ba tính xác thực của dữ liệu họ nhận được từ máy chủ, trong khi không Nội dung cụ thể của dữ liệu bị rò rỉ. Trong khi vẫn duy trì các chức năng xác minh cốt lõi ban đầu của TLS Notary, khả năng bảo vệ quyền riêng tư đã được cải thiện rất nhiều, khiến nó phù hợp hơn với nhu cầu bảo mật dữ liệu hiện tại và tương lai.
3.2 Các biến thể và mở rộng của TLS Notary
Công nghệ TLS Notary đã tiếp tục phát triển trong những năm gần đây và đã phát triển nhiều biến thể để nâng cao hơn nữa chức năng xác minh và quyền riêng tư:
• zkTLS: Phiên bản TLS Notary nâng cao quyền riêng tư, kết hợp với công nghệ ZKP, cho phép người dùng tạo chứng chỉ crypto dữ liệu trang web mà không để lộ bất kỳ thông tin nhạy cảm nào. Nó phù hợp với các tình huống giao tiếp yêu cầu bảo vệ quyền riêng tư cực kỳ cao.
• 3P-TLS (TLS ba bên): Giới thiệu máy trạm, máy chủ và kiểm toán, cho phép kiểm toán xác minh tính bảo mật của giao tiếp mà không tiết lộ nội dung giao tiếp. Giao thức này hữu ích trong các trường hợp yêu cầu tính minh bạch nhưng cần bảo vệ quyền riêng tư, chẳng hạn như đánh giá tuân thủ hoặc kiểm toán các giao dịch tài chính.
Các dự án Web3 sử dụng các công nghệ crypto này để tăng cường xác minh dữ liệu và bảo vệ quyền riêng tư, phá vỡ các rào cản dữ liệu, giải quyết các vấn đề về lưu trữ dữ liệu và đường truyền đáng tin cậy, cho phép người dùng chứng minh quyền sở hữu tài khoản mạng xã hội và hồ sơ mua hàng cho vay mượn tài chính mà không bị rò rỉ quyền riêng tư, hồ sơ tín dụng ngân hàng. , bối cảnh chuyên môn và chứng chỉ học thuật cũng như các thông tin khác, chẳng hạn như:
• Reclaim Protocol sử dụng công nghệ zkTLS để tạo ra Bằng chứng không tri thức về lưu lượng HTTPS, cho phép người dùng nhập dữ liệu hoạt động, danh tiếng và danh tính từ các trang web bên ngoài một cách an toàn mà không để lộ thông tin nhạy cảm.
• zkPass kết hợp công nghệ 3P-TLS để cho phép người dùng xác minh dữ liệu sở hữu tư nhân trong thế giới thực mà không bị rò rỉ. Nó được sử dụng rộng rãi trong KYC, dịch vụ tín dụng và các tình huống khác và tương thích với mạng HTTPS.
• Opacity Network dựa trên zkTLS, cho phép người dùng chứng minh hoạt động của họ một cách an toàn trên nhiều nền tảng khác nhau (chẳng hạn như Uber, Spotify, Netflix, v.v.) mà không cần truy cập trực tiếp vào API của các nền tảng này để đạt được bằng chứng hoạt động đa nền tảng.
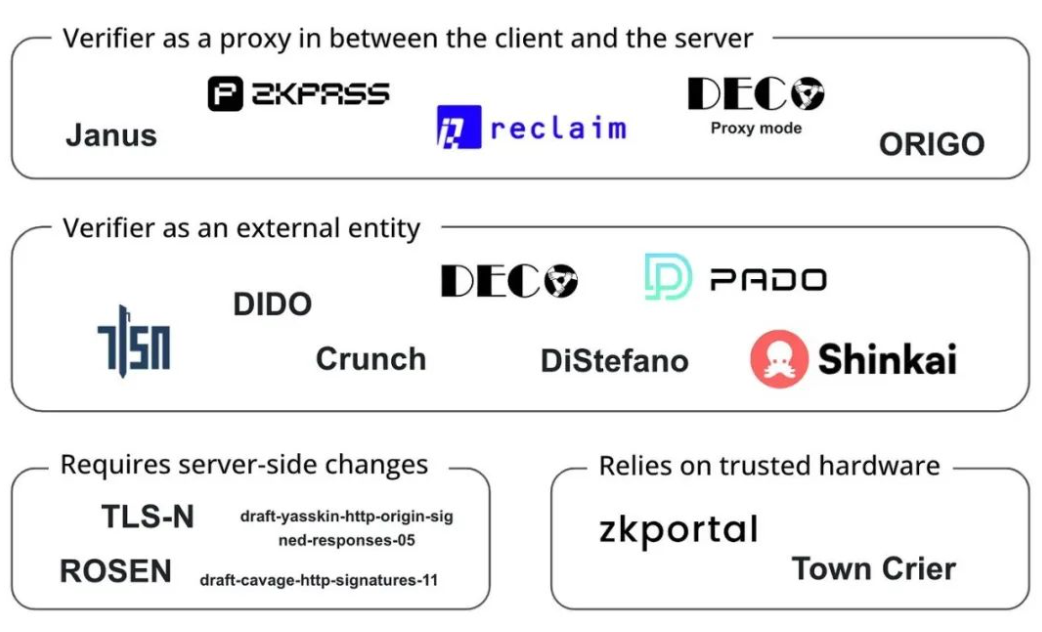
Là một liên kết quan trọng trong chuỗi sinh thái dữ liệu , xác minh dữ liệu Web3 có triển vọng ứng dụng rộng rãi và sự thịnh vượng về mặt sinh thái của nó đang dẫn đến một nền kinh tế kỹ thuật số cởi mở, năng động và lấy người dùng làm trung tâm hơn. Tuy nhiên, sự phát triển của công nghệ xác minh tính xác thực chỉ là bước khởi đầu cho việc xây dựng cơ sở hạ tầng dữ liệu thế hệ mới.
4. Mạng dữ liệu phi tập trung
Một số dự án kết hợp các công nghệ xác minh dữ liệu nêu trên để khám phá sâu hơn ở thượng nguồn của hệ sinh thái dữ liệu, tức là truy xuất nguồn gốc dữ liệu, thu thập phân tán và truyền dữ liệu đáng tin cậy. Phần sau đây tập trung vào một số dự án tiêu biểu: OpenLayer, Grass và Vana, cho thấy tiềm năng đặc biệt trong việc xây dựng cơ sở hạ tầng dữ liệu thế hệ mới.
4.1 Lớp mở
OpenLayer là một trong những dự án Accelerator khởi nghiệp crypto mùa xuân a16z crypto 2024. Là lớp dữ liệu thực mô-đun đầu tiên, nó cam kết cung cấp giải pháp mô-đun sáng tạo để điều phối việc thu thập, xác minh và chuyển đổi dữ liệu để đáp ứng cả nhu cầu của Web2 và Web3. các công ty. OpenLayer đã thu hút được sự hỗ trợ từ các quỹ có tiếng và các nhà đầu tư thiên thần bao gồm Geometry Ventures và LongHash Ventures .
Có nhiều thách thức trong lớp dữ liệu truyền thống: thiếu cơ chế xác minh đáng tin cậy, phụ thuộc vào kiến trúc tập trung dẫn đến khả năng truy cập hạn chế, thiếu khả năng tương tác và thanh khoản của dữ liệu giữa các hệ thống khác nhau và không có cơ chế phân phối giá trị dữ liệu hợp lý.
Một vấn đề cụ thể hơn là khi dữ liệu đào tạo AI ngày càng khan hiếm. Trên Internet công cộng, nhiều trang web đã bắt đầu áp dụng các hạn chế về trình thu thập thông tin để ngăn các công ty AI thu thập dữ liệu trên quy mô lớn.
Khi nói đến dữ liệu độc quyền riêng tư, tình hình phức tạp hơn. Nhiều dữ liệu có giá trị được lưu trữ theo cách bảo vệ quyền riêng tư do tính chất nhạy cảm, thiếu cơ chế khích lệ hiệu quả. Trong tình hình hiện tại, người dùng không thể nhận được lợi nhuận trực tiếp một cách an toàn từ việc cung cấp dữ liệu riêng tư và do đó không sẵn lòng chia sẻ dữ liệu nhạy cảm này.
Để giải quyết những vấn đề này, OpenLayer kết hợp công nghệ xác minh dữ liệu để xây dựng lớp dữ liệu xác thực mô-đun (Lớp dữ liệu xác thực mô-đun) và sử dụng khích lệ kinh tế phi tập trung để điều phối quá trình thu thập, xác minh và chuyển đổi dữ liệu, cung cấp cho các công ty Web2 và Web3 nhiều hơn nữa. Cơ sở hạ tầng dữ liệu an toàn, hiệu quả và linh hoạt.
Để giải quyết những vấn đề này, OpenLayer kết hợp công nghệ xác minh dữ liệu để xây dựng lớp dữ liệu xác thực mô-đun (Lớp dữ liệu xác thực mô-đun) và sử dụng khích lệ kinh tế phi tập trung để điều phối quá trình thu thập, xác minh và chuyển đổi dữ liệu, cung cấp cho các công ty Web2 và Web3 nhiều hơn nữa. Cơ sở hạ tầng dữ liệu an toàn, hiệu quả và linh hoạt.
4.1.1 Các thành phần cốt lõi của thiết kế mô-đun OpenLayer
OpenLayer cung cấp nền tảng mô-đun để đơn giản hóa quá trình thu thập dữ liệu , xác minh và chuyển đổi đáng tin cậy:
a) OpenNodes
OpenNodes là thành phần cốt lõi chịu trách nhiệm thu thập dữ liệu phi tập trung trong hệ sinh thái OpenLayer. Dữ liệu được thu thập thông qua các ứng dụng di động, mở rộng trình duyệt và các kênh khác của người dùng. Nút vận hành khác nhau có thể thực hiện nhiệm vụ phù hợp nhất theo thông số kỹ thuật phần cứng của họ để tối ưu hóa lợi nhuận.
OpenNodes hỗ trợ ba loại dữ liệu chính để đáp ứng nhu cầu của các loại nhiệm vụ khác nhau:
• Dữ liệu internet có sẵn công khai (chẳng hạn như dữ liệu tài chính, dữ liệu thời tiết, dữ liệu thể thao và luồng truyền thông xã hội)
• Dữ liệu riêng tư của người dùng (chẳng hạn như lịch sử xem Netflix, hồ sơ đặt hàng trên Amazon, v.v.)
• Dữ liệu tự báo cáo từ các nguồn an toàn (chẳng hạn như dữ liệu được ký bởi chủ sở hữu độc quyền hoặc được xác minh bởi phần cứng đáng tin cậy cụ thể)
Nhà phát triển có thể dễ dàng thêm các loại dữ liệu mới, chỉ định nguồn dữ liệu mới, yêu cầu và phương pháp truy xuất dữ liệu và người dùng có thể chọn cung cấp dữ liệu không xác định danh tính để đổi lấy phần thưởng. Thiết kế này cho phép hệ thống liên tục mở rộng để thích ứng với nhu cầu dữ liệu mới. Nguồn dữ liệu đa dạng cho phép OpenLayer cung cấp hỗ trợ dữ liệu toàn diện cho các tình huống ứng dụng khác nhau và cũng giảm ngưỡng cung cấp dữ liệu.
b) Trình xác thực mở
OpenValidators chịu trách nhiệm xác thực dữ liệu sau khi thu thập, cho phép người tiêu dùng dữ liệu xác nhận rằng dữ liệu do người dùng cung cấp khớp chính xác với nguồn dữ liệu. Tất cả phương pháp xác minh được cung cấp đều có thể được chứng minh crypto và kết quả xác minh có thể được xác minh sau đó. Có một số nhà cung cấp khác nhau của cùng một loại chứng nhận. Nhà phát triển có thể chọn nhà cung cấp xác minh phù hợp nhất dựa trên nhu cầu của họ.
Trong các trường hợp sử dụng ban đầu, đặc biệt đối với dữ liệu công khai hoặc sở hữu tư nhân từ API Internet, OpenLayer tận dụng TLS Notary làm giải pháp xác minh để xuất dữ liệu từ bất kỳ ứng dụng web nào và chứng minh tính xác thực của dữ liệu mà không ảnh hưởng đến quyền riêng tư.
Không giới hạn ở TLS Notary, nhờ thiết kế mô-đun, hệ thống xác minh có thể dễ dàng kết nối với phương pháp xác minh khác để thích ứng với các loại dữ liệu và nhu cầu xác minh khác nhau, bao gồm nhưng không giới hạn ở:
1. Các kết nối TLS đã được chứng thực: Sử dụng Hoàn cảnh thực thi đáng tin cậy (TEE) để thiết lập các kết nối TLS được chứng nhận nhằm đảm bảo tính toàn vẹn và tính xác thực của dữ liệu trong quá trình truyền.
2. Vùng bảo mật: Sử dụng hoàn cảnh cách ly bảo mật cấp phần cứng (chẳng hạn như Intel SGX) để xử lý và xác minh dữ liệu nhạy cảm, cung cấp mức độ bảo vệ dữ liệu cao hơn.
3. ZK Proof Generators: Tích hợp ZKP để cho phép xác minh thuộc tính dữ liệu hoặc kết quả tính toán mà không làm rò rỉ dữ liệu gốc.
c) Kết nối mở
OpenConnect là mô-đun lõi chịu trách nhiệm chuyển đổi dữ liệu và tính khả dụng trong hệ sinh thái OpenLayer. Nó xử lý dữ liệu từ nhiều nguồn khác nhau và đảm bảo khả năng tương tác của dữ liệu giữa các hệ thống khác nhau để đáp ứng nhu cầu của các ứng dụng khác nhau. Ví dụ:
• Chuyển đổi dữ liệu thành định dạng oracle oracle Chuỗi để các hợp đồng thông minh sử dụng trực tiếp.
• Chuyển đổi dữ liệu thô phi cấu trúc thành dữ liệu có cấu trúc để xử lý trước cho các mục đích như đào tạo AI.
Đối với dữ liệu từ tài khoản riêng tư của người dùng, OpenConnect cung cấp các chức năng giải mẫn cảm dữ liệu để bảo vệ quyền riêng tư, đồng thời cung cấp các thành phần để tăng cường bảo mật trong quá trình chia sẻ dữ liệu cũng như giảm rò rỉ và lạm dụng dữ liệu . Để đáp ứng nhu cầu dữ liệu theo thời gian thực của các ứng dụng như AI và blockchain , OpenConnect hỗ trợ chuyển đổi dữ liệu theo thời gian thực hiệu quả.
Hiện tại, thông qua tích hợp Eigenlayer, các nhà khai thác OpenLayer AVS giám sát nhiệm vụ yêu cầu dữ liệu , chịu trách nhiệm lấy dữ liệu và xác minh dữ liệu, sau đó báo cáo kết quả trở lại hệ thống, cầm cố hoặc thế chấp lại tài sản thông qua EigenLayer để đảm bảo kinh tế cho hành động của họ . Nếu chứng minh được hành vi ác ý, bạn sẽ có rủi ro bị tịch thu tài sản cầm cố. Là một trong những AVS (Dịch vụ xác minh hoạt động) sớm nhất trên mạng chính EigenLayer, OpenLayer đã thu hút hơn 50 nhà khai thác và 4 tỷ đô la tài sản reStake .
Nhìn chung, lớp dữ liệu phi tập trung do OpenLayer xây dựng mở rộng phạm vi và tính đa dạng của dữ liệu có sẵn mà không làm mất đi tính thực tế và hiệu quả, đồng thời đảm bảo tính xác thực và toàn vẹn của dữ liệu thông qua công nghệ crypto và khích lệ kinh tế. Công nghệ của nó có các ứng dụng thực tế rộng rãi cho các Dapp Web3 đang tìm cách đạt được sự tin cậy ngoài Chuỗi, các công ty cần đầu vào thực sự để đào tạo và suy đoán các mô hình AI cũng như các công ty muốn phân khúc và định giá người dùng dựa trên danh tính và danh tiếng của họ. Người dùng cũng có thể coi trọng dữ liệu sở hữu tư nhân của họ.
4.2.1 Các thành phần chính của cỏ
4.2 Cỏ
Grass là một dự án hàng đầu được Wynd Network phát triển nhằm tạo ra một nền tảng dữ liệu đào tạo AI và trình thu thập dữ liệu web phi tập trung . Vào cuối năm 2023, dự án Grass đã hoàn thành vòng tài trợ ban đầu trị giá 3,5 triệu đô la Mỹ do Polychain Capital và Tribe Capital dẫn đầu. Sau đó, vào tháng 9 năm 2024, dự án đã nhận được nguồn tài trợ Series A do HackVC dẫn đầu, với các tổ chức đầu tư có tiếng như Polychain, Delphi, Lattice và Brevan Howard cũng trong đó.
Chúng tôi đã đề cập rằng đào tạo AI yêu cầu đầu vào dữ liệu mới và một trong đó những giải pháp là sử dụng nhiều IP để vượt qua các quyền truy cập dữ liệu và cung cấp dữ liệu cho AI. Grass bắt đầu từ việc này và tạo ra một mạng nút trình thu thập thông tin phân tán, dành riêng cho phi tập trung cơ sở hạ tầng vật lý, sử dụng băng thông nhàn rỗi của người dùng để thu thập và cung cấp các bộ dữ liệu có thể xác minh được cho việc đào tạo AI. Nút định tuyến các yêu cầu web thông qua kết nối internet của người dùng, truy cập các trang web công cộng và biên dịch các tập dữ liệu có cấu trúc. Nó sử dụng công nghệ điện toán biên để làm sạch và định dạng dữ liệu sơ bộ nhằm cải thiện chất lượng dữ liệu .
Grass áp dụng kiến trúc Data Rollup Layer 2 Solana , được xây dựng trên Solana để cải thiện hiệu quả xử lý. Grass sử dụng trình xác thực để nhận, xác minh và xử lý các giao dịch web từ nút và tạo chứng chỉ ZK để đảm bảo tính xác thực dữ liệu. Dữ liệu đã xác minh được lưu trữ trong sổ cái dữ liệu(L2) và được liên kết với bằng chứng Chuỗi L1 tương ứng.
4.2.1 Các thành phần chính của cỏ
a) Nút cỏ
Tương tự như OpenNodes, người dùng C-side cài đặt các ứng dụng Grass hoặc mở rộng mở rộng trình duyệt và chạy chúng, sử dụng nút thông nhàn rỗi để thực hiện các hoạt động thu thập dữ liệu web thông qua kết nối Internet của người dùng, truy cập các trang web công cộng và biên dịch các bộ dữ liệu có cấu trúc, sử dụng tính toán biên. công nghệ làm sạch và định dạng dữ liệu sơ bộ. Người dùng được thưởng mã token GRASS dựa trên băng thông và khối lượng dữ liệu mà họ đóng góp.
b) Bộ định tuyến
Kết nối nút Grass và trình xác nhận, quản lý mạng nút và băng thông chuyển tiếp. Bộ định tuyến được khích lệ vận hành và nhận phần thưởng tỷ lệ thuận với tổng băng thông xác minh đi qua rơle trong đó .
c) Người xác nhận
Nhận, xác minh và xử lý các giao dịch web hàng loạt từ bộ định tuyến, tạo bằng chứng ZK, sử dụng bộ khóa duy nhất để thiết lập kết nối TLS, chọn bộ mật mã thích hợp để liên lạc với máy chủ web mục tiêu. Grass hiện đang sử dụng các trình xác nhận tập trung, với kế hoạch trong tương lai là chuyển sang một ủy ban xác thực.
d) Bộ xử lý ZK
Nhận bằng chứng về dữ liệu phiên trên mỗi nút được tạo từ trình xác thực, theo lô và gửi bằng chứng về tính hợp lệ cho tất cả các yêu cầu web tới Lớp 1 ( Solana).
e) Sổ cái dữ liệu Grass (Grass L2)
Bộ dữ liệu hoàn chỉnh được lưu trữ và liên kết với Chuỗi L1 tương ứng (Solana) để chứng minh.
f) Mô hình nhúng cạnh
Chịu trách nhiệm chuyển đổi dữ liệu web phi cấu trúc thành các mô hình có cấu trúc có thể sử dụng cho đào tạo AI.
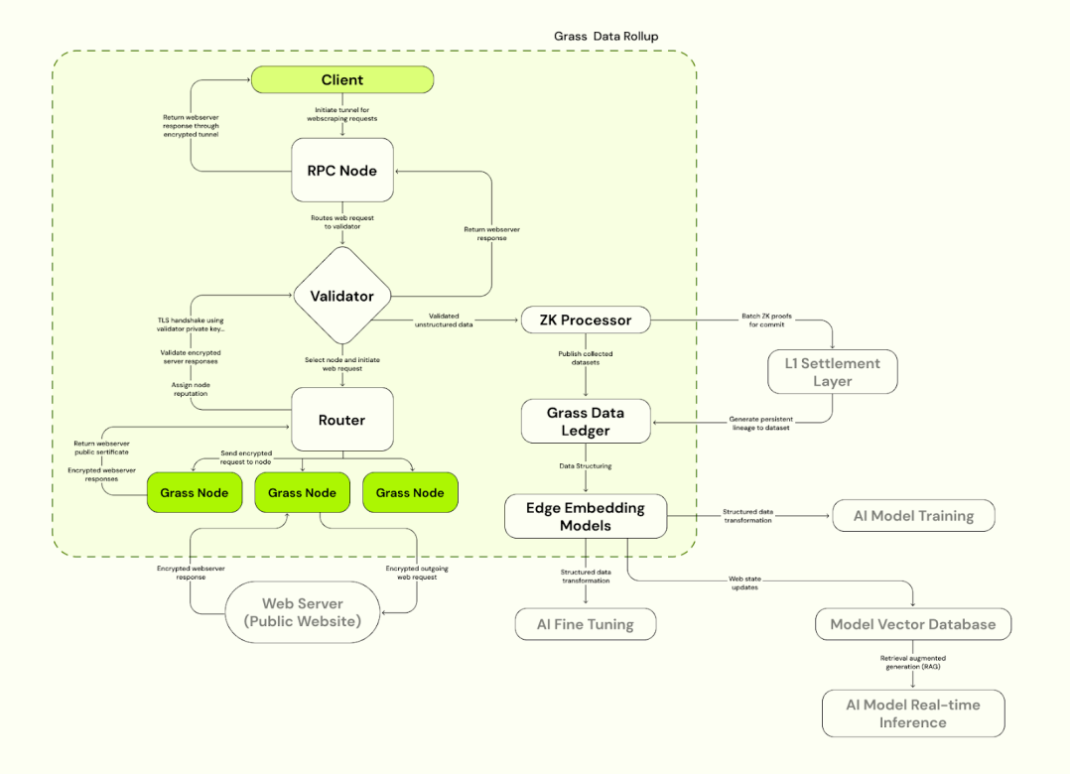
Phân tích và so sánh Grass và OpenLayer
Cả OpenLayer và Grass đều tận dụng mạng phân tán để cung cấp cho các công ty quyền truy cập vào dữ liệu Internet mở và thông tin đóng yêu cầu xác thực. Cơ chế khích lệ thúc đẩy chia sẻ dữ liệu và sản xuất dữ liệu chất lượng cao. Cả hai đều cam kết tạo ra một lớp dữ liệu phi tập trung (Lớp dữ liệu phi tập trung) để giải quyết các vấn đề về truy cập và xác minh dữ liệu , nhưng áp dụng các đường dẫn kỹ thuật và mô hình kinh doanh hơi khác nhau.
Sự khác biệt trong kiến trúc kỹ thuật
Grass sử dụng kiến trúc Data Rollup Layer 2 Solana và hiện đang sử dụng cơ chế xác minh tập trung bằng một trình xác thực duy nhất. Là đợt AVS đầu tiên, OpenLayer được xây dựng dựa trên EigenLayer và sử dụng các cơ chế khích lệ kinh tế và tịch thu để thực hiện cơ chế xác minh phi tập trung. Nó áp dụng thiết kế mô-đun và nhấn mạnh mở rộng và tính linh hoạt của các dịch vụ xác minh dữ liệu .
Sự khác biệt của sản phẩm
Cả hai đều cung cấp các sản phẩm tương tự C, cho phép người dùng kiếm tiền từ giá trị dữ liệu thông qua nút . Về phía To B, Grass cung cấp một mô hình thị trường dữ liệu thú vị và sử dụng L2 để xác minh và lưu trữ dữ liệu hoàn chỉnh, cung cấp các bộ đào tạo có cấu trúc, chất lượng cao, có thể kiểm chứng từ các công ty AI. OpenLayer hiện không có thành phần lưu trữ dữ liệu chuyên dụng, nhưng nó cung cấp nhiều dịch vụ xác minh luồng dữ liệu theo thời gian thực (Vaas) hơn, ngoài việc cung cấp dữ liệu cho AI, nó còn phù hợp cho các tình huống yêu cầu phản hồi nhanh. , chẳng hạn như Oracle cho các dự án thị trường dự đoán RWA/DeFi, cung cấp dữ liệu xã hội theo thời gian thực, v.v.
Do đó, đối tượng khách hàng mục tiêu hiện tại của Grass chủ yếu là các công ty AI và nhà khoa học dữ liệu, cung cấp các bộ dữ liệu đào tạo có cấu trúc và quy mô lớn, đồng thời phục vụ các tổ chức nghiên cứu và doanh nghiệp yêu cầu lượng lớn dữ liệu mạng trong khi OpenLayer tạm thời hướng đến những đối tượng đó; những người cần nguồn dữ liệu Chuỗi , các nhà phát triển trên Chuỗi, các công ty AI yêu cầu luồng dữ liệu có thể kiểm chứng theo thời gian thực và các công ty Web2 hỗ trợ các chiến lược thu hút người dùng sáng tạo như xác minh lịch sử sử dụng sản phẩm.
Khả năng cạnh tranh trong tương lai
Tuy nhiên, dựa trên xu hướng của ngành, thực sự có khả năng chức năng của hai dự án sẽ hội tụ trong tương lai. Grass cũng có thể sớm cung cấp dữ liệu có cấu trúc theo thời gian thực. Là một nền tảng mô-đun, OpenLayer cũng có thể mở rộng sang quản lý tập dữ liệu và có sổ cái dữ liệu riêng trong tương lai, do đó, các lĩnh vực cạnh tranh giữa hai nền tảng này có thể dần dần chồng chéo lên nhau.
Hơn nữa, cả hai dự án có thể xem xét bổ sung thêm liên kết chính của việc ghi nhãn dữ liệu. Grass có thể đang di chuyển nhanh hơn trên mặt trận này vì chúng có mạng nút khổng lồ - được báo cáo là hơn 2,2 triệu nút đang hoạt động. Lợi thế này mang lại cho Grass tiềm năng cung cấp dịch vụ học tập tăng cường dựa trên phản hồi của con người (RLHF), tận dụng lượng lớn dữ liệu chú thích để tối ưu hóa các mô hình AI.
Tuy nhiên, việc OpenLayer tập trung vào dữ liệu riêng tư, với chuyên môn về xác minh dữ liệu và xử lý thời gian thực, có thể duy trì lợi thế về chất lượng và độ tin cậy dữ liệu. Ngoài ra, OpenLayer, với tư cách là một trong những AVS của EigenLayer, có thể có sự phát triển hơn nữa trong cơ chế xác minh phi tập trung.
Mặc dù hai dự án có thể cạnh tranh trong một số lĩnh vực, nhưng thế mạnh độc đáo và lộ trình kỹ thuật tương ứng của chúng cũng có thể khiến chúng chiếm giữ những vị trí khác nhau trong hệ sinh thái dữ liệu.

4.3 VAVA
Là mạng nhóm dữ liệu lấy người dùng làm trung tâm, Vana cũng cam kết cung cấp dữ liệu chất lượng cao cho AI và các ứng dụng liên quan. So với OpenLayer và Grass, Vana áp dụng con đường kỹ thuật và mô hình kinh doanh khác biệt hơn. Vana đã hoàn thành khoản tài trợ trị giá 5 triệu đô la Mỹ vào tháng 9 năm 2024, do Coinbase Ventures dẫn đầu. Trước đó, họ đã nhận được 18 triệu đô la Mỹ trong vòng tài trợ Series A do Paradigm dẫn đầu. Các nhà đầu tư có tiếng khác bao gồm Polychain, Casey Caruso, v.v.
Ban đầu được ra mắt như một dự án nghiên cứu của MIT vào năm 2018, Vana đặt mục tiêu trở thành một blockchain Lớp 1 được thiết kế dành riêng cho dữ liệu riêng tư của người dùng. Những đổi mới của nó về quyền sở hữu dữ liệu và phân phối giá trị cho phép người dùng kiếm lợi nhuận từ các mô hình AI được đào tạo trên dữ liệu của họ. Cốt lõi của Vana là hiện thực hóa sự lưu thông và giá trị của dữ liệu riêng tư thông qua dữ liệu thanh khoản dữ liệu không đáng tin cậy, riêng tư và hiển thị cũng như cơ chế Bằng chứng Đóng góp cải tiến:
dữ liệu thanh khoản dữ liệu
Vana giới thiệu khái niệm nhóm thanh khoản dữ liệu (DLP) duy nhất: là thành phần cốt lõi của mạng Vana, mỗi DLP là một mạng ngang hàng độc lập được sử dụng để tổng hợp các loại tài sản dữ liệu cụ thể. Người dùng có thể tải dữ liệu riêng tư của họ (chẳng hạn như hồ sơ mua sắm, thói quen duyệt web, hoạt động trên mạng xã hội, v.v.) lên một DLP cụ thể và linh hoạt lựa chọn có cho phép sử dụng dữ liệu này cho các bên thứ ba cụ thể hay không. Dữ liệu được tích hợp và quản lý thông qua các nhóm thanh khoản này và dữ liệu được hủy nhận dạng, đảm bảo quyền riêng tư của người dùng đồng thời cho phép dữ liệu tham gia vào các ứng dụng thương mại, chẳng hạn như đào tạo mô hình AI hoặc nghiên cứu thị trường.
Người dùng gửi dữ liệu tới DLP và nhận token DLP tương ứng (mỗi DLP có token cụ thể) làm phần thưởng. Token này không chỉ thể hiện tổng đóng góp của dữ liệu người dùng mà còn cung cấp cho người dùng quyền quản trị và quyền phân phối lợi nhuận trong tương lai đối với DLP. Người dùng không chỉ có thể chia sẻ dữ liệu mà còn có thể nhận được lợi nhuận liên tục từ các lệnh gọi dữ liệu tiếp theo (và cung cấp tính năng theo dõi trực quan). Không giống như việc bán dữ liệu một lần truyền thống, Vana cho phép dữ liệu liên tục tham gia vào chu kỳ kinh tế.
4.3.2 Cơ chế bằng chứng đóng góp
Một trong những cải tiến cốt lõi khác của Vana là cơ chế Bằng chứng Đóng góp. Đây là cơ chế chính của Vana để đảm bảo chất lượng dữ liệu, cho phép mỗi DLP kiểm soát chức năng chứng nhận đóng góp duy nhất theo đặc điểm của nó để xác minh tính xác thực và tính toàn vẹn của dữ liệu, đồng thời đánh giá sự đóng góp của dữ liệu vào việc cải thiện hiệu suất mô hình AI. Cơ chế này đảm bảo rằng dữ liệu đóng góp của người dùng được định lượng và ghi lại, từ đó mang lại phần thưởng cho người dùng.
Tương tự như " Bằng chứng công việc of Work" trong crypto , Proof of Contribution phân bổ lợi nhuận cho người dùng dựa trên chất lượng, số lượng và tần suất sử dụng dữ liệu mà họ đóng góp. Việc thực hiện tự động thông qua hợp đồng thông minh đảm bảo rằng những người đóng góp nhận được phần thưởng phù hợp với đóng góp của họ.
Kiến trúc kỹ thuật của Vana
1. Lớp thanh khoản dữ liệu
Đây là lớp cốt lõi của Vana, chịu trách nhiệm đóng góp, xác minh và ghi dữ liệu vào DLP, đưa dữ liệu lên Chuỗi dưới dạng tài sản kỹ thuật số có thể chuyển nhượng. DLP tạo và triển khai các hợp đồng thông minh DLP, đồng thời đặt mục đích đóng góp dữ liệu, phương pháp xác minh và các tham số đóng góp. Người đóng góp và người giám sát dữ liệu gửi dữ liệu để xác minh và mô-đun đun Bằng chứng đóng góp (PoC) thực hiện xác minh dữ liệu và đánh giá giá trị, cấp quyền quản trị và phần thưởng dựa trên các tham số.
2. Lớp di chuyển dữ liệu
Đây là một nền tảng dữ liệu mở dành cho những người đóng góp và phát triển dữ liệu cũng như lớp ứng dụng của Vana. Lớp di chuyển dữ liệu cung cấp không gian cộng tác cho những người đóng góp và nhà phát triển dữ liệu để xây dựng các ứng dụng bằng cách sử dụng thanh khoản dữ liệu được tích lũy trong DLP. Cung cấp cơ sở hạ tầng để đào tạo phân tán các mô hình do người dùng sở hữu và phát triển AI Dapps.
3. Kết nối phổ quát
Sổ cái phi tập trung cũng là biểu đồ luồng dữ liệu theo thời gian thực trong toàn bộ hệ sinh thái Vana, sử dụng sự đồng thuận Bằng chứng cổ phần of Stake để ghi lại các giao dịch dữ liệu theo thời gian thực trong hệ sinh thái Vana. Đảm bảo chuyển token DLP hiệu quả và cung cấp quyền truy cập dữ liệu DLP chéo vào các ứng dụng. Tương thích với EVM, cho phép khả năng tương tác với các mạng, giao thức và ứng dụng DeFi khác.
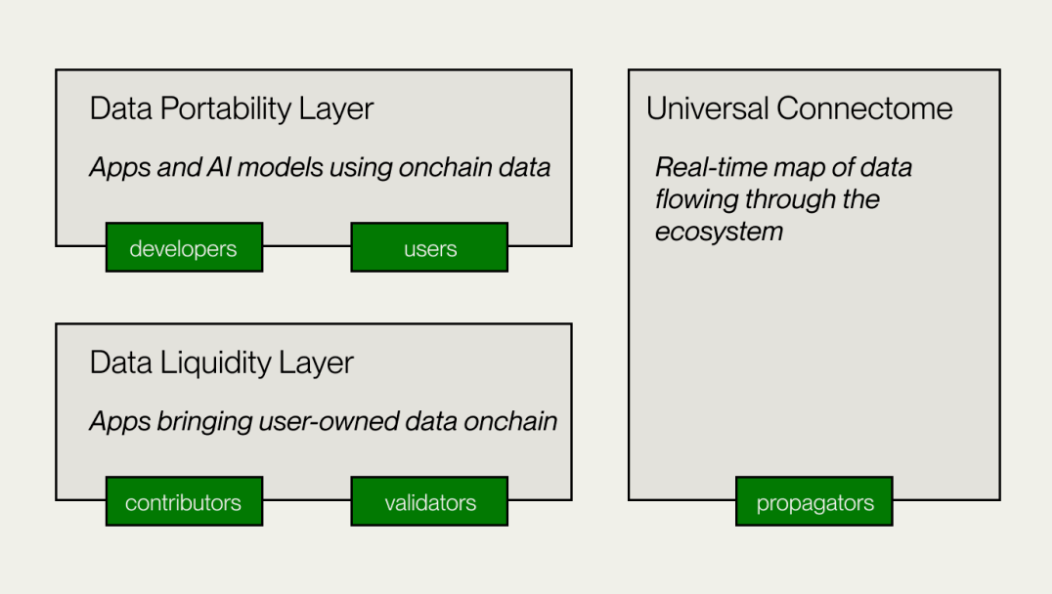
Vana cung cấp một con đường khác, tập trung vào thanh khoản và trao quyền giá trị cho dữ liệu người dùng. Mô hình trao đổi dữ liệu phi tập trung này không chỉ phù hợp với các tình huống như thị trường dữ liệu và đào tạo AI mà còn cung cấp nền tảng cho dữ liệu người dùng trong hệ sinh thái Web3. -khả năng tương tác và ủy quyền của nền tảng cung cấp một giải pháp mới, cuối cùng tạo ra một hệ sinh thái Internet mở cho phép người dùng sở hữu và quản lý dữ liệu của riêng họ cũng như các sản phẩm thông minh được tạo từ dữ liệu này.
5. Đề xuất giá trị của mạng dữ liệu phi tập trung
Nhà khoa học dữ liệu Clive Humby cho biết vào năm 2006 dữ liệu là dầu của thời đại mới. Trong 20 năm qua, chúng ta đã chứng kiến sự phát triển nhanh chóng của công nghệ “tinh chế”. Các công nghệ như phân tích dữ liệu lớn và học máy đã giải phóng giá trị của dữ liệu hơn bao giờ hết. Theo dự báo của IDC, vòng tròn dữ liệu toàn cầu sẽ tăng trưởng lên 163 ZB vào năm 2025, hầu hết trong đó sẽ đến từ người dùng cá nhân Với sự phổ biến của các công nghệ mới nổi như IoT, thiết bị đeo, AI và các dịch vụ được cá nhân hóa, lượng lớn dữ liệu sẽ xuất hiện. Dữ liệu sẽ và sẽ được lấy từ các cá nhân.
Điểm yếu của các giải pháp truyền thống: Khai phá sự đổi mới của Web3
Giải pháp dữ liệu Web3 vượt qua những hạn chế của cơ sở vật chất truyền thống thông qua mạng nút phân tán, đạt được khả năng thu thập dữ liệu rộng hơn và hiệu quả hơn, đồng thời cải thiện hiệu quả thu thập theo thời gian thực và độ tin cậy xác minh của dữ liệu cụ thể. Trong quá trình này, công nghệ Web3 đảm bảo tính xác thực và toàn vẹn của dữ liệu, đồng thời bảo vệ quyền riêng tư của người dùng một cách hiệu quả, từ đó đạt được mô hình sử dụng dữ liệu công bằng hơn. Kiến trúc dữ liệu phi tập trung này thúc đẩy quá trình dân chủ hóa việc thu thập dữ liệu.
Cho dù đó là mô hình nút người dùng của OpenLayer và Grass hay kiếm tiền từ dữ liệu riêng tư của người dùng của Vana, ngoài việc cải thiện hiệu quả của việc thu thập dữ liệu cụ thể, nó còn cho phép người dùng thông thường chia sẻ cổ tức của nền kinh tế dữ liệu, tạo ra đôi bên cùng có lợi mô hình dành cho người dùng và nhà phát triển, cho phép Người dùng thực sự kiểm soát và hưởng lợi từ dữ liệu cũng như các tài nguyên liên quan của họ.
Thông qua khích lệ kinh tế token , giải pháp dữ liệu Web3 thiết kế lại mô hình khích lệ và tạo ra cơ chế phân phối giá trị dữ liệu công bằng hơn. Nó thu hút lượng lớn người dùng, tài nguyên phần cứng và vốn, từ đó cùng nhau điều chỉnh và tối ưu hóa hoạt động của toàn bộ mạng dữ liệu.
So với các giải pháp dữ liệu truyền thống, chúng cũng có mô-đun và mở rộng: Ví dụ, thiết kế mô-đun của OpenLayer mang lại sự linh hoạt cho việc lặp lại công nghệ trong tương lai và mở rộng sinh thái. Nhờ các tính năng kỹ thuật, phương pháp thu thập dữ liệu để đào tạo mô hình AI được tối ưu hóa để cung cấp bộ dữ liệu phong phú và đa dạng hơn.
Từ việc tạo, lưu trữ, xác minh đến trao đổi và phân tích dữ liệu, các giải pháp dựa trên Web3 giải quyết nhiều thiếu sót của cơ sở truyền thống thông qua các ưu điểm kỹ thuật độc đáo, đồng thời mang đến cho người dùng khả năng kiếm tiền từ dữ liệu cá nhân, tạo ra sự thay đổi cơ bản trong mô hình kinh tế dữ liệu . Với sự phát triển và tiến bộ hơn nữa của công nghệ cũng như việc mở rộng các kịch bản ứng dụng, lớp dữ liệu phi tập trung dự kiến sẽ trở thành thế hệ cơ sở hạ tầng quan trọng tiếp theo cùng với các giải pháp dữ liệu Web3 khác để cung cấp hỗ trợ cho nhiều ngành công nghiệp dựa trên dữ liệu.
Từ việc tạo, lưu trữ, xác minh đến trao đổi và phân tích dữ liệu, các giải pháp dựa trên Web3 giải quyết nhiều thiếu sót của cơ sở truyền thống thông qua các ưu điểm kỹ thuật độc đáo, đồng thời mang đến cho người dùng khả năng kiếm tiền từ dữ liệu cá nhân, tạo ra sự thay đổi cơ bản trong mô hình kinh tế dữ liệu . Với sự phát triển và tiến bộ hơn nữa của công nghệ cũng như việc mở rộng các kịch bản ứng dụng, lớp dữ liệu phi tập trung dự kiến sẽ trở thành thế hệ cơ sở hạ tầng quan trọng tiếp theo cùng với các giải pháp dữ liệu Web3 khác để cung cấp hỗ trợ cho nhiều ngành công nghiệp dựa trên dữ liệu.