

Biên soạn: Jiayu, Cage
Tác nhân AI là một sự thay đổi mô hình mà chúng tôi đang theo dõi chặt chẽ và sê-ri bài viết của Langchain rất hữu ích trong việc tìm hiểu xu hướng phát triển của Tác nhân. Trong phần tổng hợp này, phần đầu tiên là báo cáo Trạng thái Tác nhân AI do đội ngũ Langchain phát hành. Họ đã phỏng vấn hơn 1.300 người hành nghề, bao gồm các nhà phát triển, giám đốc sản phẩm và giám đốc điều hành công ty, tiết lộ tình hình hiện tại và những điểm nghẽn trong việc triển khai Đại lý trong năm nay: 90% công ty có kế hoạch và nhu cầu về Đại lý AI, nhưng những hạn chế về khả năng của Đại lý gây khó khăn cho người dùng Nó chỉ có thể được triển khai trong một số quy trình và tình huống. Thay vì chi phí và độ trễ, mọi người quan tâm nhiều hơn đến việc cải thiện khả năng của Tác nhân cũng như khả năng quan sát và kiểm soát hành vi của nó.
Trong phần thứ hai, chúng tôi đã tổng hợp phân tích các yếu tố chính của Tác nhân AI từ sê-ri bài viết In the Loop trên trang web chính thức của LangChain: khả năng lập kế hoạch, đổi mới tương tác UI/UX và cơ chế bộ nhớ . Bài viết này phân tích các phương pháp tương tác của 5 loại sản phẩm có nguồn gốc LLM và so sánh 3 loại cơ chế bộ nhớ phức tạp của con người, có thể mang lại một số nguồn cảm hứng để hiểu Tác nhân AI và hiểu các yếu tố chính này. Trong phần này, chúng tôi cũng đã bổ sung thêm một số nghiên cứu điển hình của công ty Đại lý đại diện, chẳng hạn như các cuộc phỏng vấn với những người sáng lập Reflection AI, để hướng tới những bước đột phá quan trọng của Đại lý AI vào năm 2025.
Theo khung phân tích này, chúng tôi hy vọng rằng các ứng dụng Tác nhân AI sẽ bắt đầu xuất hiện vào năm 2025, bước vào một mô hình mới về cộng tác giữa con người và máy móc. Về khả năng lập kế hoạch của AI Agent, các mô hình do o3 đứng đầu đang thể hiện khả năng phản ánh và suy luận mạnh mẽ, đồng thời sự tiến bộ của các công ty kiểu mẫu đang tiến dần đến giai đoạn Agent từ nhà lý luận. Khi khả năng suy luận tiếp tục được cải thiện, “dặm cuối” của Agent sẽ là cơ chế tương tác và ghi nhớ sản phẩm, nhiều khả năng sẽ là cơ hội để các công ty khởi nghiệp bứt phá. Về tương tác, chúng tôi đã mong chờ "thời điểm GUI" trong kỷ nguyên AI liên quan đến bộ nhớ, chúng tôi tin rằng bối cảnh sẽ trở thành từ khóa để triển khai Tác nhân ở cấp độ cá nhân và thống nhất bối cảnh ở cấp độ doanh nghiệp. sẽ cải thiện đáng kể trải nghiệm sản phẩm của Đại lý.
01. Xu hướng sử dụng đại lý:
Mọi công ty đều có kế hoạch triển khai Agent
Sự cạnh tranh trong lĩnh vực Đại lý ngày càng trở nên khốc liệt. Trong năm qua, nhiều khung tác nhân đã trở nên phổ biến: ví dụ: sử dụng ReAct kết hợp với LLM để suy luận và hành động, sử dụng khung đa tác nhân để điều phối hoặc sử dụng các khung có thể kiểm soát tốt hơn như LangGraph.
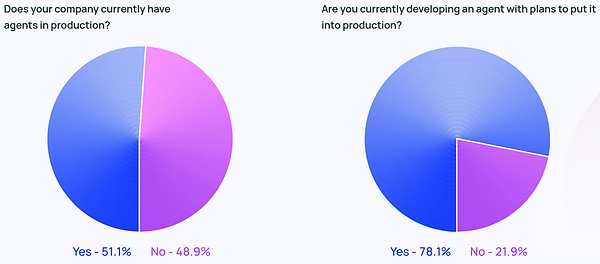
Tin đồn xung quanh Đặc vụ không chỉ là sự cường điệu của Twitter. Khoảng 51% số người được hỏi hiện đang sử dụng Agent trong sản xuất. Theo dữ liệu của Langchain theo quy mô công ty, các công ty có quy mô trung bình với 100-2000 nhân viên là những công ty tích cực nhất trong việc đưa Đại lý vào sản xuất, với tỷ lệ 63%.
Ngoài ra, 78% số người được hỏi có kế hoạch đưa Agent vào sản xuất trong thời gian tới. Rõ ràng, mọi người đều rất quan tâm đến AI Agent, nhưng thực sự việc tạo ra một Agent sẵn sàng sản xuất vẫn là một bài toán khó đối với nhiều người.
Mặc dù ngành công nghệ thường được cho rằng là những ngành sớm áp dụng Đại lý nhưng sự quan tâm đến Đại lý đang tăng lên ở tất cả các ngành. 90% số người được hỏi làm việc cho các công ty phi công nghệ đã đưa hoặc có kế hoạch đưa đại lý vào sản xuất (tỷ lệ gần tương đương với các công ty công nghệ, ở mức 89%).
Các trường hợp sử dụng phổ biến của Agent
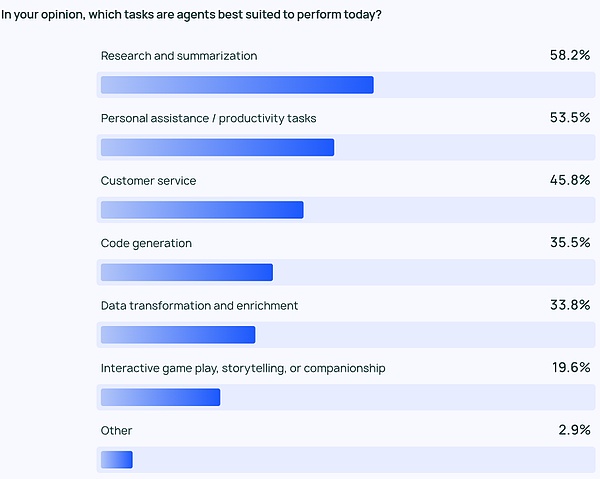
Các trường hợp sử dụng phổ biến nhất dành cho Đại lý bao gồm tiến hành nghiên cứu và tóm tắt (58%), tiếp theo là đơn giản hóa quy trình làm việc thông qua Đại lý tùy chỉnh (53,5%).
Những điều này phản ánh mong muốn của mọi người về những sản phẩm có thể xử lý nhiệm vụ quá tốn thời gian. Người dùng có thể dựa vào AI Agent để rút thông tin quan trọng và nhận xét từ lượng lớn thông tin, thay vì tự mình sàng lọc lượng dữ liệu khổng lồ rồi tiến hành đánh giá hoặc phân tích nghiên cứu dữ liệu. Tương tự như vậy, Đại lý AI có thể tăng năng suất cá nhân bằng cách hỗ trợ nhiệm vụ hàng ngày, cho phép người dùng tập trung vào những gì quan trọng.
Không chỉ các cá nhân cần loại hình cải thiện hiệu quả này mà các công ty và đội ngũ cũng cần nó. Dịch vụ khách hàng (45,8%) là một lĩnh vực ứng dụng chính khác của Đại lý giúp các công ty xử lý việc tư vấn, khắc phục sự cố và tăng tốc thời gian phản hồi của khách hàng giữa đội ngũ; xếp thứ tư và thứ năm là các ứng dụng dữ liệu và mã cấp thấp hơn.
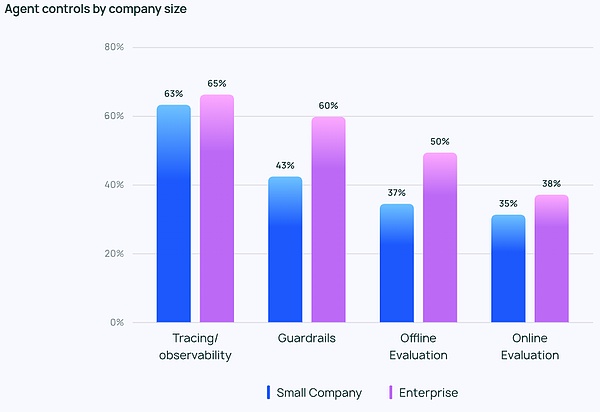
Giám sát: Các ứng dụng đại lý yêu cầu khả năng quan sát và kiểm soát
Khi việc triển khai Tác nhân trở nên mạnh mẽ hơn, cần có phương pháp quản lý và giám sát Tác nhân. Các công cụ theo dõi và quan sát đứng đầu danh sách bắt buộc phải có để giúp các nhà phát triển hiểu được hành vi và hiệu suất của các tổng đài viên. Nhiều công ty còn sử dụng lan can (kiểm soát bảo vệ) để ngăn chặn các đại lý đi chệch hướng.
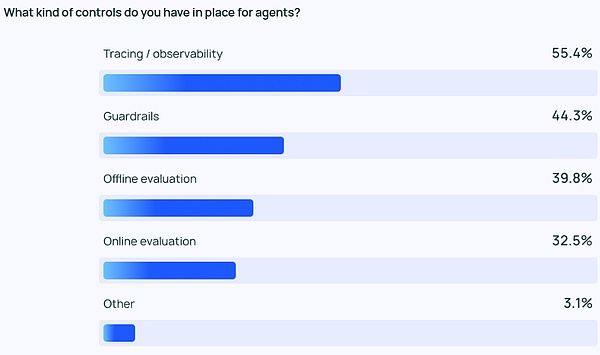
Khi thử nghiệm các ứng dụng LLM, đánh giá ngoại tuyến (39,8%) được sử dụng thường xuyên hơn đánh giá trực tuyến (32,5%), phản ánh khó khăn trong việc giám sát LLM trong thời gian thực. Trong số các phản hồi mở do LangChain cung cấp, nhiều công ty cũng nhờ các chuyên gia con người xem xét hoặc đánh giá các phản hồi theo cách thủ công như một lớp phòng ngừa bổ sung.
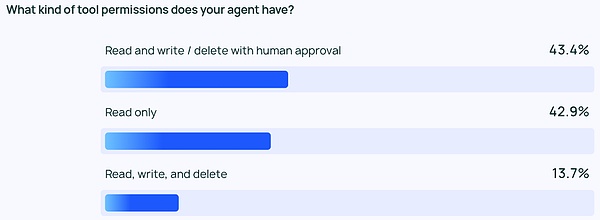
Mặc dù mọi người rất nhiệt tình với Đại lý nhưng nhìn chung họ vẫn thận trọng về các quyền của Đại lý. Rất ít người trả lời cho phép đại lý của họ đọc, viết và xóa một cách tự do. Thay vào đó, hầu hết đội ngũ chỉ cho phép quyền truy cập đọc vào công cụ hoặc yêu cầu sự chấp thuận của con người trước khi tác nhân có thể thực hiện các hành động rủi ro hơn như viết hoặc xóa.
Các công ty có quy mô khác nhau cũng có những ưu tiên khác nhau trong việc kiểm soát Đại lý. Không có gì ngạc nhiên khi các doanh nghiệp lớn (hơn 2.000 nhân viên) thận trọng hơn và phụ thuộc nhiều vào quyền "chỉ đọc" để tránh rủi ro không đáng có. Họ cũng có xu hướng kết hợp việc bảo vệ lan can với đánh giá ngoại tuyến và không muốn khách hàng thấy bất kỳ vấn đề nào.
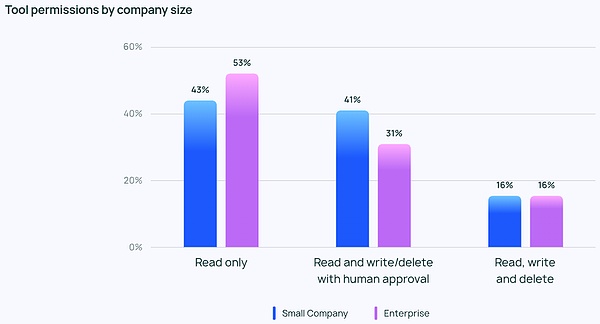
Trong khi đó, các công ty nhỏ hơn và công ty khởi nghiệp (dưới 100 nhân viên) tập trung hơn vào việc theo dõi để hiểu những gì đang xảy ra trong ứng dụng Đại lý của họ (thay vì các biện pháp kiểm soát khác). Theo dữ liệu khảo sát của LangChain, các công ty nhỏ hơn có xu hướng tập trung vào việc xem xét dữ liệu để hiểu kết quả; trong khi các doanh nghiệp lớn hơn có nhiều biện pháp kiểm soát hơn trên diện rộng.
Rào cản và thách thức khi đưa Agent vào sản xuất
Rất khó để đảm bảo hiệu suất LLM chất lượng cao. Câu trả lời cần có độ chính xác cao và phù hợp với phong cách chính xác. Đây là vấn đề mà các nhà phát triển Agent và người dùng quan tâm nhất - quan trọng hơn gấp đôi so với chi phí, bảo mật và các yếu tố khác.
LLM Agent là đầu ra nội dung xác suất, có nghĩa là khó có thể đoán trước được. Điều này tạo ra nhiều khả năng xảy ra lỗi hơn, khiến đội ngũ gặp khó khăn trong việc đảm bảo rằng tổng đài viên của họ luôn đưa ra phản hồi chính xác, phù hợp với ngữ cảnh.
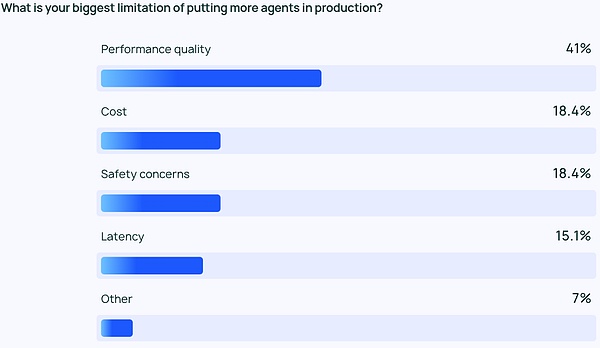
Điều này đặc biệt đúng đối với các công ty nhỏ hơn, nơi chất lượng hoạt động vượt xa các cân nhắc khác, với 45,8% cho rằng đây là mối quan tâm hàng đầu của họ, so với chi phí (mối quan tâm lớn thứ hai) chỉ ở mức 22,4%. Khoảng cách này nhấn mạnh tầm quan trọng của hiệu suất đáng tin cậy, chất lượng cao đối với các tổ chức chuyển các tác nhân từ giai đoạn phát triển sang sản xuất.
Mối lo ngại về bảo mật cũng phổ biến đối với các công ty lớn yêu cầu tuân thủ nghiêm ngặt và xử lý dữ liệu khách hàng một cách nhạy cảm.
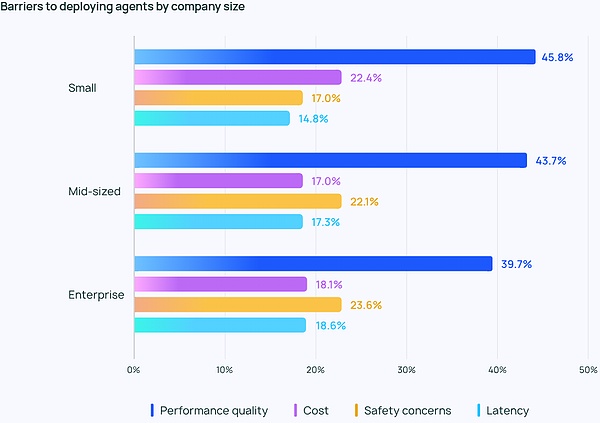
Những thách thức không dừng lại ở chất lượng. Từ những câu trả lời mở mà LangChain đưa ra, nhiều người vẫn tỏ ra hoài nghi về việc liệu công ty có tiếp tục đầu tư phát triển và thử nghiệm Đại lý hay không. Mọi người đều đề cập đến hai trở ngại nổi bật: việc phát triển Đại lý đòi hỏi nhiều kiến thức và đòi hỏi phải luôn theo kịp giới hạn công nghệ; việc phát triển và triển khai Đại lý đòi hỏi nhiều thời gian và chi phí, lợi nhuận của việc vận hành đáng tin cậy là không chắc chắn.
Các chủ đề mới nổi khác
Trong các câu hỏi mở, có rất nhiều lời khen ngợi về khả năng mà AI Agent thể hiện:
• Quản lý nhiệm vụ nhiều bước : Tác nhân AI có khả năng suy luận và quản lý bối cảnh sâu hơn, cho phép chúng xử lý nhiệm vụ phức tạp hơn ;
• Tự động hóa nhiệm vụ lặp đi lặp lại: Tác nhân AI tiếp tục được coi là chìa khóa để xử lý nhiệm vụ tự động, có thể giải phóng thời gian của người dùng để giải quyết các vấn đề sáng tạo hơn;
• Lập kế hoạch và cộng tác nhiệm vụ: Lập kế hoạch nhiệm vụ tốt hơn đảm bảo rằng đúng tác nhân xử lý đúng vấn đề vào đúng thời điểm, đặc biệt là trong các hệ thống đa tác nhân;
• Lý luận giống con người: Không giống như LLM truyền thống, Tác nhân AI có thể đưa ra quyết định trước đó, bao gồm xem xét và sửa đổi các quyết định trong quá khứ dựa trên thông tin mới.
Ngoài ra, còn có hai diễn biến được mọi người mong đợi nhất:
• Kỳ vọng đối với Tác nhân AI mã nguồn mở: Mọi người rõ ràng quan tâm đến Tác nhân AI mã nguồn mở và nhiều người đã đề cập rằng trí tuệ tập thể có thể đẩy nhanh quá trình đổi mới Tác nhân;
• Dự đoán về các mô hình mạnh hơn: Nhiều người đang dự đoán bước nhảy vọt tiếp theo trong các tác nhân AI được thúc đẩy bởi các mô hình lớn hơn, mạnh hơn—thời điểm mà các tác nhân có thể xử lý nhiệm vụ phức tạp hơn với hiệu quả và khả năng tự chủ cao hơn.
Nhiều người trong phần hỏi đáp cũng đề cập đến thách thức lớn nhất trong quá trình phát triển Agent: làm thế nào để hiểu được hành vi của Agent. Một số kỹ sư đề cập rằng họ gặp khó khăn trong việc giải thích khả năng và hành vi của Tác nhân AI cho các bên liên quan của công ty. Đôi khi plug-in trực quan hóa có thể giúp giải thích hành vi của Tác nhân, nhưng trong nhiều trường hợp, LLM vẫn là một hộp đen. Gánh nặng về khả năng diễn giải bổ sung được giao cho đội ngũ kỹ thuật.
02. Yếu tố cốt lõi trong AI Agent
Hệ thống Agentic là gì
Trước khi phát hành báo cáo Trạng thái của Tác nhân AI, đội ngũ Langchain đã viết khung Langraph của riêng mình trong trường Tác nhân và thảo luận về nhiều thành phần chính trong Tác nhân AI thông qua blog In the Loop Trong đó là phần tổng hợp các nội dung chính của chúng tôi. .
Trước hết, mọi người đều có định nghĩa hơi khác nhau về AI Agent, Harrison Chase, người sáng lập LangChain, đã đưa ra định nghĩa sau:
AI Agent là một hệ thống sử dụng LLM để đưa ra quyết định về luồng điều khiển chương trình.
Tác nhân AI là một hệ thống sử dụng LLM để quyết định luồng điều khiển của ứng dụng.
Về cách triển khai, bài viết giới thiệu khái niệm về Kiến trúc nhận thức đề cập đến cách Tác nhân suy nghĩ và cách hệ thống sắp xếp mã/lời nhắc LLM:
• Nhận thức: Tác nhân sử dụng LLM để suy luận về mặt ngữ nghĩa về cách sắp xếp mã/LLM nhắc nhở;
• Kiến trúc: Các hệ thống Agent này vẫn liên quan đến lượng lớn kỹ thuật tương tự như kiến trúc hệ thống truyền thống.
Hình ảnh bên dưới hiển thị các ví dụ về các cấp độ khác nhau của Kiến trúc nhận thức:
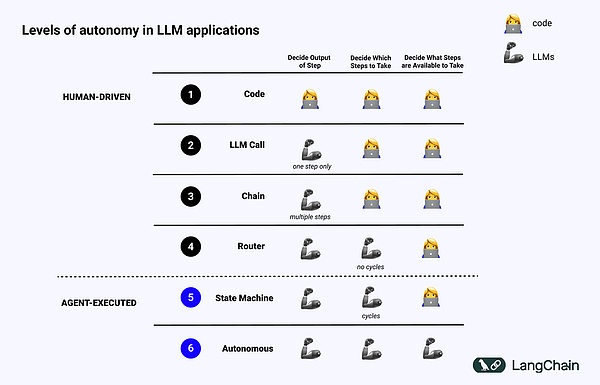
• Mã (mã) phần mềm được tiêu chuẩn hóa: Mọi thứ đều là Mã cứng và các tham số liên quan về đầu ra hoặc đầu vào được cố định trực tiếp trong mã nguồn. Điều này không tạo thành một kiến trúc nhận thức vì không có phần nhận thức;
• Cuộc gọi LLM, ngoại trừ một số quá trình xử lý trước dữ liệu, một cuộc gọi LLM duy nhất cấu thành phần lớn ứng dụng và Chatbot đơn giản thuộc loại này;
• Chuỗi: Sê-Ri các cuộc gọi LLM cố gắng chia giải pháp của vấn đề thành nhiều bước và gọi các LLM khác nhau để giải quyết vấn đề. Các RAG phức tạp thuộc loại này: LLM đầu tiên được gọi để tìm kiếm và truy vấn, còn LLM thứ hai được gọi để tạo ra câu trả lời;
• Bộ định tuyến: Trong ba hệ thống trước, người dùng có thể biết trước tất cả các bước mà chương trình sẽ thực hiện, nhưng trong Bộ định tuyến, LLM tự quyết định nên gọi LLM nào và thực hiện những bước nào, điều này làm tăng thêm tính ngẫu nhiên và khó đoán;
• State Machine, sử dụng LLM kết hợp với Router, sẽ càng khó đoán hơn, bởi vì bằng cách đặt nó trong một vòng lặp, hệ thống (về mặt lý thuyết) có thể thực hiện các cuộc gọi LLM lần;
• Hệ thống Agent: Người ta còn gọi là “Autonomous Agent”. Khi sử dụng State Machine vẫn có những hạn chế về những hành động nào có thể được thực hiện và những tiến trình nào được thực hiện sau khi thực hiện hành động đó, nhưng khi sử dụng Autonomous Agent thì những hạn chế này sẽ bị loại bỏ. LLM để quyết định những bước cần thực hiện và cách phối hợp các LLM khác nhau. Điều này có thể được thực hiện bằng cách sử dụng các lời nhắc, công cụ hoặc mã khác nhau.
Nói một cách đơn giản, hệ thống càng có tính "tác nhân" thì LLM càng xác định cách hệ thống hoạt động.
Các yếu tố chính của đại lý
lập kế hoạch
Độ tin cậy của đại lý là một điểm khó khăn lớn. Thường có những công ty sử dụng LLM để xây dựng đại lý nhưng đề cập rằng các đại lý không thể lập kế hoạch và lý luận tốt. Lập kế hoạch và lý luận ở đây có ý nghĩa gì?
Việc lập kế hoạch và lý luận của Đại lý đề cập đến khả năng suy nghĩ của LLM về những hành động cần thực hiện. Điều này liên quan đến lý luận ngắn hạn và dài hạn, trong đó LLM đánh giá tất cả thông tin có sẵn và sau đó quyết định: tôi cần thực hiện sê-ri bước nào và đâu là bước đầu tiên tôi nên thực hiện ngay bây giờ?
Nhiều khi các nhà phát triển sử dụng chức năng gọi hàm để cho LLM chọn thao tác thực hiện. Gọi hàm là khả năng mà OpenAI lần đầu tiên thêm vào API LLM vào tháng 6 năm 2023. Thông qua Gọi hàm, người dùng có thể cung cấp cấu trúc JSON cho các hàm khác nhau và để LLM khớp với một (hoặc nhiều) trong đó trúc.
Để hoàn thành thành công một nhiệm vụ phức tạp, hệ thống cần thực hiện sê-ri hành động. Kiểu lập kế hoạch và lý luận dài hạn này rất phức tạp đối với LLM: thứ nhất, LLM phải xem xét một kế hoạch hành động dài hạn, sau đó quay lại các hành động ngắn hạn sẽ thực hiện thứ hai, khi Đại lý thực hiện ngày càng nhiều hoạt động; , kết quả của các thao tác sẽ được phản hồi trở lại LLM, khiến cửa sổ ngữ cảnh tăng trưởng, điều này có thể khiến LLM "phân tâm" và hoạt động kém.
Giải pháp đơn giản nhất để cải thiện việc lập kế hoạch là đảm bảo rằng LLM có tất cả thông tin cần thiết để lập kế hoạch/lập kế hoạch phù hợp. Mặc dù điều này nghe có vẻ đơn giản nhưng thông tin được chuyển đến LLM thường không đủ để LLM đưa ra quyết định hợp lý và việc thêm bước truy xuất hoặc làm rõ Lời nhắc có thể là một cải tiến đơn giản.
Sau đó, bạn có thể xem xét việc thay đổi kiến trúc nhận thức của ứng dụng của mình. Có hai loại kiến trúc nhận thức để cải thiện khả năng suy luận, kiến trúc nhận thức chung và kiến trúc nhận thức theo miền cụ thể:
1. Kiến trúc nhận thức chung
Kiến trúc nhận thức chung có thể được áp dụng cho bất kỳ nhiệm vụ . Có hai bài viết ở đây đề xuất hai kiến trúc chung. Một là kiến trúc "lập kế hoạch và giải quyết", được đề xuất trong bài viết Nhắc nhở lập kế hoạch và giải quyết: Cải thiện lý luận chuỗi tư duy không bắn bằng các mô hình ngôn ngữ lớn. kiến trúc, trước tiên tác nhân đề xuất một kế hoạch và sau đó thực hiện từng bước trong kế hoạch. Một kiến trúc phổ biến khác là kiến trúc Phản ánh, được đề xuất trong Phản xạ: Tác nhiệm vụ ngôn ngữ với việc học tăng cường bằng lời nói. Trong kiến trúc này, có một bước "phản ánh" rõ ràng sau khi Tác nhân thực hiện nhiệm vụ để phản ánh liệu nó có thực hiện đúng nhiệm vụ hay không. Tôi sẽ không đi vào chi tiết ở đây, nhưng bạn có thể đọc hai bài báo để biết chi tiết.
Mặc dù những ý tưởng này cho thấy những cải tiến nhưng chúng thường quá chung chung để được các đại lý thực sự sử dụng trong sản xuất. (Ghi chú của người dịch: Không có model sê-ri o1 nào khi bài viết này được xuất bản)
2. Kiến trúc nhận thức theo miền cụ thể
Thay vào đó, chúng tôi thấy rằng Tác nhân được xây dựng bằng cách sử dụng kiến trúc nhận thức dành riêng cho từng miền. Điều này thường thể hiện ở các bước lập kế hoạch/phân loại theo miền cụ thể, các bước xác thực theo miền cụ thể. Một số ý tưởng từ việc lập kế hoạch và phản ánh có thể được áp dụng ở đây, nhưng chúng thường được áp dụng theo cách cụ thể theo từng lĩnh vực.
Một bài báo của AlphaCodium đưa ra một ví dụ cụ thể: đạt được hiệu suất tiên tiến bằng cách sử dụng cái mà họ gọi là "kỹ thuật truyền phát" (một cách khác để nói về kiến trúc nhận thức).
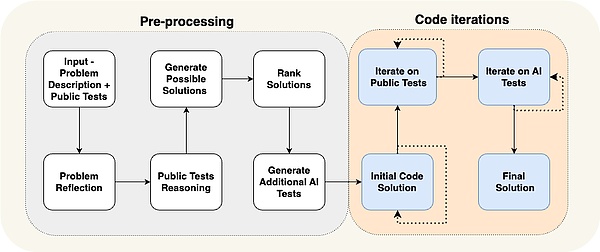
Bạn có thể thấy rằng quy trình của Tác nhân rất cụ thể đối với vấn đề mà họ đang cố gắng giải quyết. Họ yêu cầu nhân viên phải làm theo các bước: đưa ra các thử nghiệm, sau đó đưa ra giải pháp, sau đó lặp lại với nhiều thử nghiệm hơn, v.v. Kiến trúc nhận thức này tập trung cao độ vào một lĩnh vực cụ thể và không thể khái quát hóa sang các lĩnh vực khác.
Nghiên cứu trường hợp:
Tầm nhìn của người sáng lập Reflection AI Laskin viễn cảnh mong đợi tương lai của Đặc vụ
Trong một cuộc phỏng vấn với người sáng lập Reflection AI, Misha Laskin tại Sequoia Capital, Misha đã đề cập rằng anh ấy đang bắt đầu hiện thực hóa viễn cảnh mong đợi việc xây dựng khả năng tìm kiếm tốt nhất trong công ty mới Reflection AI của mình bằng cách kết hợp khả năng tìm kiếm của RL với mô hình Đại lý LLM. Anh và người đồng sáng lập Ioannis Antonoglou (người đứng đầu AlphaGo, AlphaZero, Gemini RLHF) là những mô hình đào tạo được thiết kế cho Agentic Workflows. Quan điểm chính trong cuộc phỏng vấn như sau:
• Độ sâu là phần còn thiếu của AI Agent. Mặc dù các mô hình ngôn ngữ hiện tại vượt trội về bề rộng nhưng chúng lại thiếu độ sâu cần thiết để hoàn thành nhiệm vụ một cách đáng tin cậy. Laskin cho rằng rằng việc giải quyết các "vấn đề độ sâu" là rất quan trọng để tạo ra các tác nhân AI thực sự có năng lực. Năng lực ở đây đề cập đến các tác nhân có thể lập kế hoạch và thực hiện nhiệm vụ phức tạp qua nhiều bước;
• Kết hợp Học và Tìm kiếm là chìa khóa để đạt được hiệu suất siêu phàm. Dựa trên thành công của AlphaGo, Laskin nhấn mạnh khái niệm sâu sắc nhất trong AI là sự kết hợp giữa Học (dựa vào LLM) và Tìm kiếm (tìm ra con đường tối ưu). Phương pháp này rất quan trọng để tạo ra các tác nhân có thể làm tốt hơn con người trong nhiệm vụ phức tạp;
• Sau đào tạo và xây dựng mô hình khen thưởng đặt ra những thách thức đáng kể. Không giống như những trò chơi có phần thưởng rõ ràng, nhiệm vụ trong thế giới thực thường thiếu phần thưởng thực sự. Phát triển mô hình phần thưởng đáng tin cậy là thách thức chính trong việc tạo ra Tác nhân AI đáng tin cậy
• Đại lý toàn cầu có thể gần gũi hơn chúng ta nghĩ. Laskin ước tính rằng có thể chỉ mất ba năm để đạt được “AGI kỹ thuật số”, một hệ thống AI có cả chiều rộng và độ sâu. Dòng thời gian được tăng tốc này nêu bật tính cấp thiết của việc giải quyết các vấn đề về an toàn và độ tin cậy trong khi năng lực được phát triển
• Con đường đến với Đại lý toàn cầu cần có phương pháp. Reflection AI tập trung vào mở rộng các chức năng của Tác nhân, bắt đầu từ một số hoàn cảnh cụ thể, chẳng hạn như trình duyệt, mã hóa và hệ điều hành máy tính. Mục tiêu của họ là phát triển các Đại lý toàn cầu không giới hạn nhiệm vụ cụ thể.
Tương tác UI/UX
Trong những năm tới, tương tác giữa người và máy tính sẽ trở thành lĩnh vực nghiên cứu trọng điểm: Hệ thống tác nhân khác với hệ thống máy tính truyền thống trước đây vì độ trễ, độ không tin cậy và giao diện ngôn ngữ tự nhiên mang đến những thách thức mới. Do đó, các mô hình UI/UX mới để tương tác với các ứng dụng Tác nhân này sẽ xuất hiện. Hệ thống đại lý vẫn đang ở giai đoạn đầu, nhưng một số mô hình UX mới nổi đã xuất hiện. Chúng được thảo luận dưới đây:
1. Tương tác đàm thoại (Giao diện người dùng trò chuyện)
Trò chuyện thường được chia thành hai loại: trò chuyện trực tuyến và trò chuyện không phát trực tuyến.
Trò chuyện trực tuyến cho đến nay là UX phổ biến nhất. Đó là một Chatbot truyền lại suy nghĩ và hành động của nó ở định dạng trò chuyện - ChatGPT là ví dụ phổ biến nhất. Hình thức tương tác này tưởng chừng đơn giản nhưng cũng mang lại kết quả tốt vì: thứ nhất, ngôn ngữ tự nhiên có thể được sử dụng để nói chuyện với LLM, nghĩa là không có trở ngại nào giữa khách hàng và LLM thứ hai, LLM có thể mất một thời gian để hoạt động; , Phát trực tuyến cho phép người dùng hiểu chính xác những gì đang diễn ra trong nền; thứ ba, LLM thường mắc lỗi và Trò chuyện cung cấp một giao diện tuyệt vời để sửa và hướng dẫn nó một cách tự nhiên và mọi người đã quen với việc có các cuộc trò chuyện và lặp lại tiếp theo trong trò chuyện. đồ đạc.
Nhưng trò chuyện trực tuyến cũng có nhược điểm của nó. Đầu tiên, trò chuyện trực tuyến là một trải nghiệm người dùng tương đối mới, vì vậy các nền tảng trò chuyện hiện tại của chúng tôi (iMessage, Facebook Messenger, Slack, v.v.) không có tính năng này. Thứ hai, đối với nhiệm vụ chạy dài hơn, điều này hơi khó xử—Người dùng có phải không? chỉ cần ngồi đó và xem Đặc vụ hoạt động? Thứ ba, trò chuyện trực tuyến thường cần được kích hoạt bởi con người, điều đó có nghĩa là cần lượng lớn người trong vòng lặp.
Sự khác biệt lớn nhất với trò chuyện không phát trực tuyến là các phản hồi được trả về theo đợt, LLM hoạt động ở chế độ nền và người dùng không vội để LLM trả lời ngay lập tức, điều đó có nghĩa là tích hợp vào quy trình công việc hiện có có thể dễ dàng hơn. Mọi người đã quen với việc nhắn tin cho con người – tại sao họ không thể thích nghi với việc nhắn tin bằng AI? Trò chuyện không phát trực tuyến sẽ giúp tương tác dễ dàng hơn với các hệ thống tổng đài viên phức tạp hơn—các hệ thống này thường mất một khoảng thời gian, điều này có thể gây khó chịu nếu cần có phản hồi ngay lập tức. Trò chuyện không phát trực tuyến thường loại bỏ kỳ vọng này, giúp thực hiện những việc phức tạp hơn dễ dàng hơn.
Hai phương thức trò chuyện này có những ưu điểm và nhược điểm sau:

2. Hoàn cảnh nền (Ambient UX)
Người dùng sẽ cân nhắc việc gửi tin nhắn tới AI, chính là Chat đã đề cập ở trên, nhưng nếu Agent chỉ hoạt động ở chế độ nền thì chúng ta nên tương tác với Agent như thế nào?
Để các hệ thống tác nhân thực sự phát huy được tiềm năng của mình, cần phải có sự thay đổi này cho phép AI hoạt động ở chế độ nền. Người dùng thường chấp nhận thời gian hoàn thành lâu hơn khi nhiệm vụ được xử lý ở chế độ nền (vì họ không còn kỳ vọng vào độ trễ thấp). Điều này giúp nhân viên hỗ trợ có thể thực hiện nhiều công việc hơn và thường suy luận cẩn thận và chăm chỉ hơn so với trong UX trò chuyện.
Ngoài ra, việc chạy Tác nhân trong nền mở rộng khả năng của người dùng con người của chúng tôi. Giao diện trò chuyện thường giới hạn chúng ta làm một nhiệm vụ tại một thời điểm. Tuy nhiên, nếu Tác nhân đang chạy trong hoàn cảnh nền, có thể có nhiều Tác nhân xử lý nhiều nhiệm vụ cùng một lúc.
Để Tác nhân chạy ở chế độ nền cần có sự tin tưởng của người dùng. Làm cách nào để thiết lập sự tin cậy này? Một ý tưởng đơn giản: hiển thị cho người dùng chính xác những gì Tác nhân đang làm. Hiển thị tất cả các bước nó đang thực hiện và cho phép người dùng quan sát những gì đang xảy ra. Mặc dù các bước này có thể không hiển thị ngay lập tức (như khi truyền phát phản hồi), nhưng nó phải có sẵn để người dùng nhấn và quan sát. Bước tiếp theo là không chỉ cho phép người dùng xem điều gì đang xảy ra mà còn cho phép họ sửa tác nhân. Nếu họ phát hiện ra rằng Đại lý đã đưa ra lựa chọn sai ở Bước 4 trên 10, khách hàng có thể chọn quay lại Bước 4 và sửa Đại lý theo cách nào đó.
Phương pháp này chuyển người dùng từ "trong vòng lặp" sang "trong vòng lặp". "Đang lặp lại" yêu cầu có thể hiển thị cho người dùng tất cả các bước trung gian do Tác nhân thực hiện, cho phép người dùng tạm dừng quy trình làm việc giữa chừng, cung cấp phản hồi và sau đó để Tác nhân tiếp tục.
Kỹ sư phần mềm AI Devin là một ứng dụng triển khai UX tương tự. Devin mất nhiều thời gian hơn để chạy, nhưng khách hàng có thể xem tất cả các bước đã thực hiện, sụp đổ trạng thái phát triển tại một thời điểm cụ thể và đưa ra các chỉnh sửa từ đó. Mặc dù Tác nhân có thể đang chạy ở chế độ nền nhưng điều này không có nghĩa là nó cần thực hiện nhiệm vụ một cách hoàn toàn tự động. Đôi khi tác nhân không biết phải làm gì hoặc phản hồi như thế nào, lúc này nó cần thu hút sự chú ý của con người và yêu cầu giúp đỡ.
Một ví dụ cụ thể là trợ lý email mà Đặc vụ Harrison đang xây dựng. Mặc dù trợ lý email có thể trả lời các email cơ bản, nhưng nó thường yêu cầu Harrison thực hiện nhiệm vụ anh không muốn tự động hóa, bao gồm xem xét báo cáo lỗi phức tạp của LangChain, quyết định xem có nên tham dự một cuộc họp hay không, v.v. Trong trường hợp này, trợ lý email cần một phương pháp để liên lạc với Harrison rằng nó cần thông tin để phản hồi. Lưu ý rằng nó không yêu cầu câu trả lời trực tiếp; thay vào đó, nó yêu cầu Harrison cung cấp thông tin đầu vào về một nhiệm vụ nhất định, sau đó nó có thể sử dụng tạo ra nhiệm vụ gửi một email hay lên lịch lời mời.
Hiện tại, Harrison đã thiết lập trợ lý ở Slack. Nó gửi một câu hỏi tới Harrison, người sẽ trả lời câu hỏi đó trong Bảng điều khiển, tích hợp nguyên bản với quy trình làm việc của nó. Loại UX này tương tự như UX của bảng thông tin hỗ trợ khách hàng. Giao diện này sẽ hiển thị tất cả các khu vực mà trợ lý yêu cầu sự trợ giúp của con người, mức độ ưu tiên của yêu cầu và bất kỳ dữ liệu nào khác.

3. UX bảng tính
UX bảng tính là một cách siêu trực quan và thân thiện với người dùng để hỗ trợ công việc xử lý hàng loạt. Mỗi bảng hoặc thậm chí mỗi cột trở thành Tác nhân riêng để nghiên cứu những điều cụ thể. Quá trình xử lý hàng loạt này cho phép người dùng mở rộng tương tác với nhiều Đại lý.
UX này còn có những lợi ích khác. Định dạng bảng tính là một UX quen thuộc với hầu hết người dùng nên nó rất phù hợp với quy trình công việc hiện có. Loại UX này lý tưởng cho việc làm phong phú dữ liệu, một trường hợp sử dụng LLM phổ biến, trong đó mỗi cột có thể biểu thị một thuộc tính khác nhau cần được làm phong phú.
Các sản phẩm từ Exa AI, Clay AI, Manaflow và các công ty khác đang sử dụng UX này. Phần sau đây sử dụng Manaflow làm ví dụ để cho thấy cách bảng tính UX này xử lý quy trình làm việc.
Nghiên cứu trường hợp:
Cách Manaflow sử dụng bảng tính để tương tác với Đại lý
Manaflow được lấy cảm hứng từ Minion AI, công ty nơi người sáng lập Lawrence từng làm việc. Sản phẩm do Minion AI xây dựng là Web Agent. Tác nhân Web có thể điều khiển Google Chrome cục bộ, cho phép nó tương tác với các ứng dụng như đặt vé máy bay, gửi email, lên lịch rửa xe, v.v. Dựa trên cảm hứng của Minion AI, Manaflow đã chọn để Agent vận hành các công cụ giống như bảng tính. Điều này là do Agent không giỏi xử lý các giao diện UI của con người. Điều mà Agent thực sự giỏi là Mã hóa. Do đó, Manaflow cho phép Tác nhân gọi tập lệnh Python của giao diện UI, giao diện cơ sở dữ liệu, API liên kết và sau đó trực tiếp vận hành cơ sở dữ liệu: bao gồm thời gian đọc, đặt chỗ, gửi email, v.v.
Quy trình làm việc như sau: Giao diện chính của Manaflow là một bảng tính (Manasheet), trong đó mỗi cột thể hiện một bước trong quy trình làm việc, mỗi hàng tương ứng với AI Agent thực hiện nhiệm vụ. Mỗi quy trình làm việc của bảng tính có thể được lập trình bằng ngôn ngữ tự nhiên (cho phép người dùng không rành về kỹ thuật mô tả nhiệm vụ và các bước bằng ngôn ngữ tự nhiên). Mỗi bảng tính có một biểu đồ phụ thuộc bên trong xác định thứ tự thực hiện mỗi cột. Các trình tự này sẽ được gán cho từng hàng Agent để thực hiện song song nhiệm vụ và xử lý các quy trình như chuyển đổi dữ liệu, gọi API, truy xuất nội dung và gửi tin nhắn:
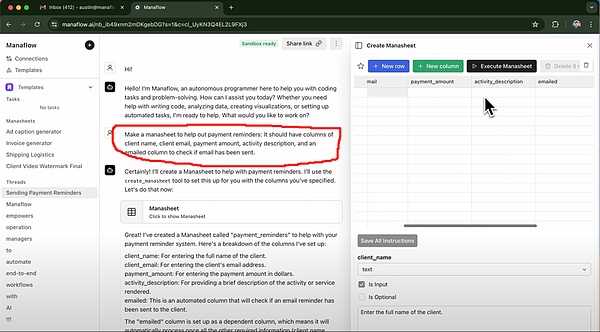
Phương pháp có thể tạo Manasheet là nhập ngôn ngữ tự nhiên tương tự như ngôn ngữ trong hộp màu đỏ ở trên. Ví dụ: nếu bạn muốn gửi email báo giá cho khách hàng trong hình trên, bạn có thể nhập Lời nhắc thông qua Trò chuyện để tạo Manasheet. . Thông qua Manasheet, bạn có thể xem tên khách hàng, email của khách hàng, ngành nghề của khách hàng, email đã được gửi chưa và các thông tin khác; nhấn Thực thi Manasheet để thực hiện nhiệm vụ.
4. Giao diện người dùng sáng tạo
Có hai cách triển khai khác nhau của "giao diện người dùng tổng quát".
Một cách là để mô hình tự tạo ra các thành phần nguyên thủy cần thiết. Điều này tương tự như các sản phẩm như Websim. Đằng sau hậu trường, Tác nhân chủ yếu viết HTML thô, trao cho nó toàn quyền kiểm soát những gì được hiển thị. Tuy nhiên, phương pháp này cho phép có độ không chắc chắn cao về chất lượng của ứng dụng web được tạo, do đó kết quả cuối cùng có thể không ổn định.
Phương pháp khác, hạn chế hơn là xác định trước một số thành phần giao diện người dùng, thường thông qua các lệnh gọi công cụ. Ví dụ: nếu LLM gọi API thời tiết, nó sẽ kích hoạt hiển thị thành phần UI bản đồ thời tiết. Vì các thành phần được hiển thị không thực sự được tạo (nhưng có nhiều tùy chọn hơn), nên giao diện người dùng được tạo sẽ tinh tế hơn, mặc dù không hoàn toàn linh hoạt về những gì nó có thể tạo ra.
Nghiên cứu trường hợp:
Sản phẩm AI cá nhândot
Ví dụ: Dot, từng được gọi là sản phẩm AI cá nhân tốt nhất vào năm 2024, là một sản phẩm UI có tính tổng quát tốt.
Dot là sản phẩm của New Computer: mục tiêu của nó là trở thành người bạn đồng hành lâu dài với người dùng chứ không phải là công cụ quản lý nhiệm vụ tốt hơn Theo đồng sáng lập Jason Yuan, cảm giác của Dot là khi bạn không biết phải đi đâu. hoặc phải làm gì. Khi nói đến điều gì đó hoặc cần nói gì, bạn chuyển sang Dot. Dưới đây là hai ví dụ để giới thiệu chức năng của sản phẩm:
• Người sáng lập Jason Yuan thường nhờ Dot giới thiệu các quán bar vào đêm khuya, nói rằng anh ấy muốn say rượu và nghỉ ngơi. Việc này cứ lặp đi lặp lại trong vài tháng sau khi tan sở, Yuan lại hỏi những câu hỏi tương tự. thực sự đã bắt đầu thuyết phục Jason rằng anh ấy không thể tiếp tục như thế này nữa;
• Phóng viên Mark Wilson của Fast Company cũng đã dành vài tháng làm việc với Dot. Có lần, anh ấy chia sẻ với Dot về chữ "O" mà anh ấy đã viết trong lớp học thư pháp của mình. Dot thực sự đã đưa ra một bức ảnh chữ "O" viết tay của anh ấy vài tuần trước và khen ngợi sự tiến bộ của khả năng viết chữ của anh ấy.
• Khi ngày càng dành nhiều thời gian sử dụng Dot, Dot hiểu rõ hơn rằng người dùng thích ghé thăm các quán cà phê và chủ động đề xuất những quán cà phê ngon gần chủ sở hữu, bao gồm cả lý do tại sao quán cà phê này ngon và cuối cùng chu đáo hỏi xem anh ta có muốn điều hướng hay không.
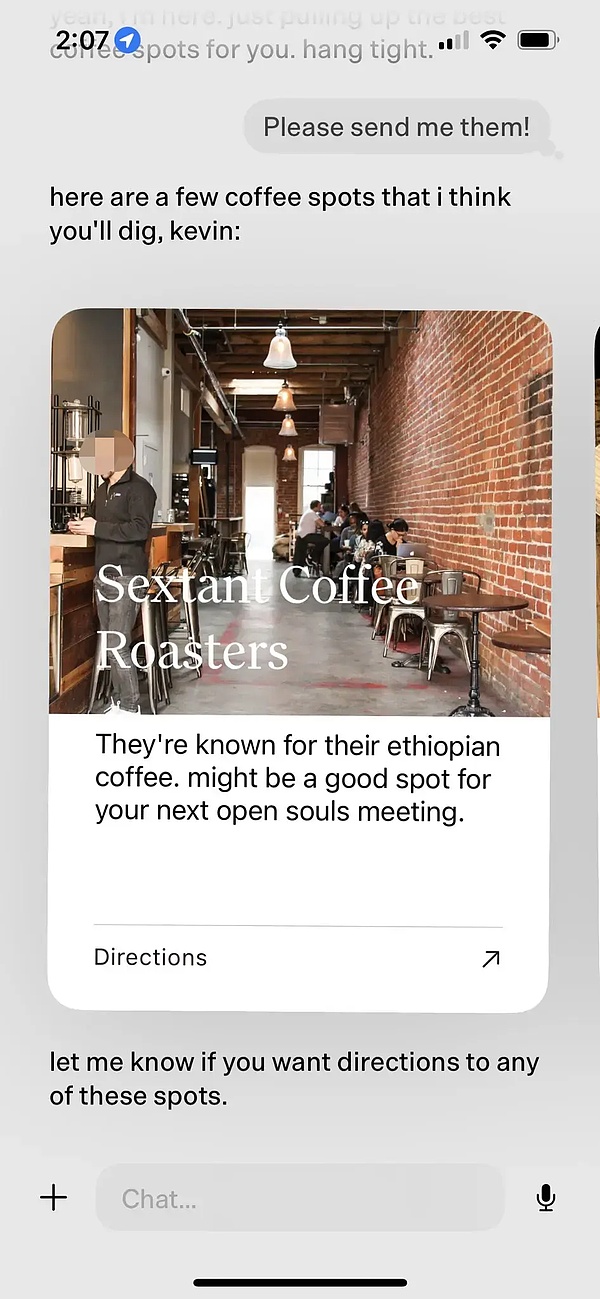
Bạn có thể thấy rằng trong ví dụ đề xuất quán cà phê này, Dot đạt được hiệu ứng tương tác gốc LLM thông qua các thành phần giao diện người dùng được xác định trước.
5. UX cộng tác
Điều gì xảy ra khi các đặc vụ và con người làm việc cùng nhau? Hãy nghĩ đến Google Docs, trong đó khách hàng có thể cộng tác với các thành viên đội ngũ để viết hoặc chỉnh sửa tài liệu, nhưng nếu một trong những cộng tác viên là Đại lý thì sao?
Dự án Patchwork của Geoffrey Litt và Ink & Switch là một ví dụ tuyệt vời về sự hợp tác giữa con người và tác nhân. (Ghi chú của người dịch: Đây có thể là nguồn cảm hứng cho bản cập nhật sản phẩm OpenAI Canvas gần đây).
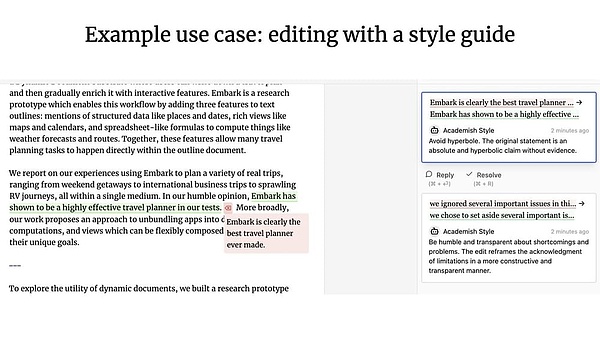
UX cộng tác so với UX xung quanh như đã thảo luận trước đó như thế nào? Kỹ sư sáng lập LangChain, Nuno nhấn mạnh rằng sự khác biệt chính giữa hai loại này là liệu có sự đồng thời hay không:
• Trong UX cộng tác , khách hàng và LLM thường làm việc đồng thời, lấy công việc của nhau làm đầu vào;
• Trong môi trường xung quanh UX , LLM hoạt động liên tục ở chế độ nền trong khi người dùng hoàn toàn tập trung vào việc khác.
ký ức
Trí nhớ rất quan trọng đối với trải nghiệm Đại lý tốt. Hãy tưởng tượng nếu bạn có một đồng nghiệp không bao giờ nhớ những gì bạn đã nói với họ, buộc bạn phải lặp đi lặp lại thông tin thì đây sẽ là một trải nghiệm cộng tác rất tồi tệ. Mọi người thường mong đợi hệ thống LLM có ký ức bẩm sinh, có lẽ vì LLM đã có cảm giác rất giống con người. Tuy nhiên, bản thân LLM không thể nhớ được điều gì.
Bộ nhớ của Tác nhân dựa trên nhu cầu của chính sản phẩm và các UX khác nhau cung cấp phương pháp khác nhau để thu thập thông tin và cập nhật phản hồi. Chúng ta có thể thấy các loại bộ nhớ nâng cao khác nhau trong cơ chế bộ nhớ của các sản phẩm Agent - chúng đang bắt chước các loại bộ nhớ của con người.
Bài viết CoALA: Kiến trúc nhận thức cho tác nhân ngôn ngữ ánh xạ các loại bộ nhớ của con người vào bộ nhớ tác nhân và phương pháp phân loại như trong hình sau:
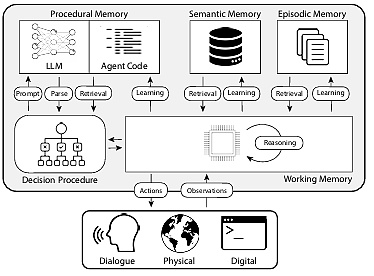
1. Trí nhớ thủ tục: Trí nhớ dài hạn về cách thực hiện nhiệm vụ, tương tự như tập lệnh cốt lõi của não
• Trí nhớ thủ tục ở người: nhớ cách đi xe đạp.
• Bộ nhớ thủ tục của Tác nhân: Bài báo CoALA mô tả bộ nhớ thủ tục là sự kết hợp giữa tỷ trọng LLM và mã Tác nhân, xác định cơ bản cách thức hoạt động của Tác nhân.
Trên thực tế, đội ngũ Langchain chưa thấy bất kỳ hệ thống Đại lý nào tự động cập nhật LLM hoặc viết lại mã của nó, nhưng vẫn tồn tại một số ví dụ về việc Đại lý cập nhật lời nhắc hệ thống của họ.
2. Trí nhớ ngữ nghĩa: Dự trữ kiến thức lâu dài
• Trí nhớ ngữ nghĩa của con người: Nó bao gồm các mẩu thông tin, chẳng hạn như sự kiện, khái niệm và mối quan hệ giữa chúng được học ở trường.
• Bộ nhớ ngữ nghĩa của tác nhân: Bài báo CoALA mô tả bộ nhớ ngữ nghĩa như một kho lưu trữ các sự kiện.
Trong thực tế, điều này thường đạt được bằng cách sử dụng LLM để rút thông tin từ cuộc đối thoại hoặc tương tác của Tác nhân. Chính xác cách lưu trữ thông tin này thường tùy thuộc vào từng ứng dụng cụ thể. Sau đó, thông tin này được truy xuất trong các cuộc hội thoại trong tương lai và được chèn vào Lời nhắc hệ thống để tác động đến phản hồi của Đại lý.
3. Ký ức phân đoạn: Nhớ lại các sự kiện cụ thể trong quá khứ
• Trí nhớ theo từng giai đoạn ở con người: Khi một người nhớ lại các sự kiện (hoặc “các giai đoạn”) cụ thể đã trải qua trong quá khứ.
• Bộ nhớ phân đoạn trong Tác nhân: Bài báo CoALA định nghĩa bộ nhớ phân đoạn là việc lưu trữ các chuỗi hành động trong quá khứ của Tác nhân.
Điều này chủ yếu được sử dụng để khiến Tác nhân thực hiện các hành động như mong đợi. Trong thực tế, bộ nhớ phân đoạn được cập nhật thông qua phương pháp Nhắc vài lần. Nếu có đủ Lời nhắc vài lần chụp cho các bản cập nhật liên quan thì bản cập nhật tiếp theo sẽ được hoàn thành thông qua Lời nhắc vài lần chụp động.
Nếu có phương pháp hướng dẫn Tác nhân hoàn thành thao tác chính xác ngay từ đầu thì phương pháp này có thể được sử dụng trực tiếp khi đối diện vấn đề tương tự sau này, ngược lại, nếu không có phương pháp thao tác đúng hoặc nếu Tác nhân tiếp tục làm mới; thì trí nhớ ngữ nghĩa sẽ quan trọng hơn, nhưng ở ví dụ trước, trí nhớ ngữ nghĩa sẽ không giúp ích được gì nhiều.
Ngoài việc xem xét loại bộ nhớ sẽ được cập nhật trong Tác nhân, nhà phát triển cũng cần xem xét cách cập nhật bộ nhớ của Tác nhân:
Phương pháp đầu tiên để cập nhật bộ nhớ của Agent là “theo đường dẫn nóng” . Trong trường hợp này, hệ thống Đại lý ghi nhớ các dữ kiện trước khi phản hồi (thường thông qua lệnh gọi công cụ) và ChatGPT thực hiện phương pháp này để cập nhật bộ nhớ của nó;
Một phương pháp khác để cập nhật bộ nhớ của Agent là "ở chế độ nền" . Trong trường hợp này, một tiến trình nền sẽ chạy sau phiên để cập nhật bộ nhớ.
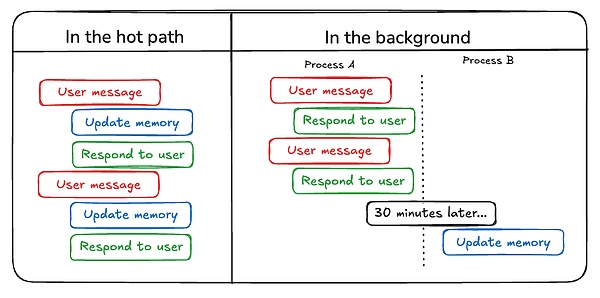
So sánh hai phương pháp, nhược điểm của phương pháp"trong đường dẫn nóng" là có một số độ trễ trước khi bất kỳ phản hồi nào được gửi và nó cũng yêu cầu kết hợp logic bộ nhớ với logic tác nhân.
Tuy nhiên, "ở chế độ nền" tránh được những vấn đề này - không thêm độ trễ và logic bộ nhớ vẫn độc lập. Nhưng "ở chế độ nền" có nhược điểm riêng: bộ nhớ không được cập nhật ngay lập tức và cần có logic bổ sung để xác định thời điểm bắt đầu quá trình nền.
Một phương pháp cập nhật bộ nhớ khác liên quan đến phản hồi của người dùng, đặc biệt liên quan đến bộ nhớ phân đoạn. Ví dụ: nếu người dùng đánh giá cao cho lần tương tác (Phản hồi tích cực), Đại lý có thể lưu phản hồi cho các cuộc gọi trong tương lai.
Dựa trên nội dung được tổng hợp ở trên, chúng tôi hy vọng rằng tiến trình đồng thời của ba thành phần lập kế hoạch, tương tác và bộ nhớ sẽ cho phép chúng tôi thấy nhiều Tác nhân AI khả dụng hơn vào năm 2025 và bước vào kỷ nguyên mới của công việc hợp tác giữa con người và máy móc.






