

Trí tuệ nhân tạo (AI) vừa trải qua "Thời khắc Sputnik" của riêng mình.
Tuần trước, công ty khởi nghiệp mô hình ngôn ngữ lớn (LLM) lớn của Trung Quốc, DeepSeek, chính thức ra mắt sau khi hoạt động thầm lặng, khiến thị trường Mỹ bất ngờ.
DeepSeek nhanh hơn, thông minh hơn và sử dụng ít tài nguyên hơn so với các LLM khác như ChatGPT. Tốc độ của nó vượt xa các mô hình tiền nhiệm, không chỉ trong việc tạo nội dung mà còn trong các truy vấn cơ bản. Quan trọng hơn, mô hình này có khả năng "tự suy nghĩ", do đó được cho là có chi phí đào tạo thấp hơn các mô hình trước đây.
Nghe có vẻ tuyệt vời, phải không? Nhưng nếu bạn là một công ty công nghệ đang đặt cược vào ngành công nghiệp AI của Mỹ, thì không hẳn là như vậy. Thị trường đã có phản ứng mạnh mẽ vào thứ Hai về diễn biến này. Các cổ phiếu công nghệ sụt giảm mạnh, xóa sổ hơn 1 nghìn tỷ USD giá trị vốn hóa thị trường - tương đương với một nửa giá trị thị trường của Bitcoin. Trong đó, cổ phiếu Nvidia giảm 17% trong một ngày, mất 589 tỷ USD giá trị vốn hóa, lập kỷ lục về mức giảm giá trị vốn hóa lớn nhất trong một ngày trên thị trường chứng khoán Mỹ. Sự sụt giảm của Nvidia và các cổ phiếu công nghệ khác đã kéo chỉ số Nasdaq giảm 3,1% trong ngày.
Và đợt bán tháo không chỉ giới hạn ở các cổ phiếu công nghệ. Các cổ phiếu năng lượng cũng chịu thiệt hại nặng nề, với các công ty khí đốt tự nhiên, năng lượng hạt nhân và năng lượng tái tạo như Vistacorp (có hoạt động quy mô lớn ở Texas) giảm khoảng 30%, trong khi Constellation Energy, công ty đang khởi động lại nhà máy điện hạt nhân Three Mile Island để cung cấp điện cho các trung tâm dữ liệu của Microsoft, cũng giảm hơn 20%.
Mối lo ngại của thị trường về DeepSeek rất đơn giản: Tốc độ cải thiện hiệu quả tính toán của LLM vượt xa dự kiến, dẫn trực tiếp đến giảm nhu cầu về GPU, trung tâm dữ liệu và năng lượng. Và trùng hợp thay, thời điểm mô hình này nổi lên lại gần với việc cựu Tổng thống Trump công bố "Dự án Stargate" trị giá 500 tỷ USD, nhằm tăng tốc xây dựng cơ sở hạ tầng AI của Mỹ.
Về tác động của DeepSeek, các chuyên gia có những quan điểm khác nhau. Một số người cho rằng đây có thể là tin tốt lành, chứ không phải thảm họa, cho ngành công nghiệp AI - giống như việc cải thiện hiệu quả của động cơ đốt trong không làm giảm nhu cầu ô tô mà thúc đẩy sự tăng trưởng của ngành.
Tuy nhiên, dữ liệu về chi phí đào tạo DeepSeek đang lưu hành trên mạng xã hội có thể gây hiểu lầm. Mặc dù mô hình mới thực sự giảm chi phí, nhưng vẫn không quá kích động như những tin đồn.
Tìm hiểu về DeepSeek
DeepSeek được thành lập bởi kỹ sư người Trung Quốc Liang Wenfeng vào tháng 5 năm 2023, và nhận được đầu tư từ quỹ phòng hộ High-Flyer, công ty mà Liang Wenfeng thành lập vào năm 2016. DeepSeek đã mở mã nguồn mở mô hình đầu tiên của mình, DeepSeek-R1, vào ngày 20 tháng 1 và nhanh chóng trở nên nổi tiếng trên mạng vào cuối tuần trước.
DeepSeek-R1 có nhiều tính năng độc đáo, khiến nó khác biệt so với các mô hình khác, bao gồm:
- Hiểu nghĩa: DeepSeek có khả năng "đọc hiểu ẩn ý". Nó sử dụng công nghệ "nhúng ngữ nghĩa" (semantic embeddings) để suy luận về ý định và ngữ cảnh sâu hơn đằng sau các truy vấn, từ đó cung cấp câu trả lời chi tiết hơn.
- Tìm kiếm đa phương thức: Nó có thể phân tích và kết hợp các loại nội dung phương tiện khác nhau, có nghĩa là có thể xử lý đồng thời văn bản, hình ảnh, video và âm thanh.
- Tự động thích ứng: DeepSeek có khả năng liên tục học hỏi và tự đào tạo - càng nhận nhiều dữ liệu đầu vào, khả năng thích ứng của nó càng mạnh. Điều này có thể giúp nó duy trì độ tin cậy mà không cần đào tạo lại thường xuyên. Nói cách khác, chúng ta có thể không cần cung cấp dữ liệu mới định kỳ như trước, vì mô hình có thể tự học và điều chỉnh trong quá trình hoạt động.
- Xử lý dữ liệu quy mô lớn: DeepSeek được cho là có thể xử lý dữ liệu ở quy mô Petabyte, cho phép nó đối phó với các tập dữ liệu khổng lồ mà các LLM khác có thể gặp khó khăn.
- Ít tham số hơn: DeepSeek-R1 có tổng số 67,1 tỷ tham số, nhưng chỉ cần 37 tỷ tham số mỗi lần suy luận, trong khi ước tính ChatGPT cần từ 500 tỷ đến 1 nghìn tỷ tham số mỗi lần suy luận (OpenAI không công bố con số cụ thể). Tham số là các đầu vào và thành phần được sử dụng để hướng dẫn và tối ưu hóa quá trình học tập của mô hình.
Ngoài các đặc điểm trên, điểm hấp dẫn nhất của DeepSeek là khả năng tự điều chỉnh và tự học. Đây không chỉ tiết kiệm thời gian và tài nguyên, mà còn tạo nền tảng cho sự phát triển của các AI Agent, có thể được áp dụng vào các hệ thống AI tự trị trong lĩnh vực robot, tự lái xe, logistics, v.v.
Trong bài viết "Lý do để short cổ phiếu Nvidia", Jeffrey Emmanuel, Giám đốc điều hành của Pastel, đã tóm tắt xuất sắc về bước đột phá này:
"Với R1, DeepSeek đã cơ bản giải quyết 'Thánh Graal' của lĩnh vực AI: cho phép mô hình dần dần suy luận mà không cần bộ dữ liệu giám sát quy mô lớn. Thử nghiệm DeepSeek-R1-Zero của họ đã thể hiện một thành tựu đáng kinh ngạc: thông qua học tăng cường thuần túy và một hàm thưởng thức được thiết kế cẩn thận, họ đã thành công trong việc phát triển khả năng suy luận phức tạp một cách tự nhiên. Đây không chỉ là giải quyết vấn đề - mô hình có thể tự động tạo ra các quy trình suy luận dài, tự kiểm tra công việc của mình và phân bổ thêm tài nguyên tính toán khi đối phó với các vấn đề khó hơn."
Lý do thực sự khiến Wall Street hoảng sợ về DeepSeek
DeepSeek quả thực là một phiên bản nâng cấp của ChatGPT, nhưng đây không phải là lý do chính khiến giới tài chính bị sốc tuần trước - lý do thực sự khiến các nhà đầu tư hoảng sợ là chi phí đào tạo của mô hình này.
Đội ngũ DeepSeek tuyên bố rằng chi phí đào tạo mô hình này chỉ 5,6 triệu USD, nhưng độ tin cậy của con số này đang bị nghi ngờ.
Tính theo số giờ GPU (tức là chi phí tính toán mỗi giờ cho mỗi GPU), đội ngũ DeepSeek cho biết họ đã sử dụng 2.048 GPU NVIDIA H800, tổng cộng 27,88 triệu giờ GPU, để hoàn thành việc tiền xử lý, mở rộng ngữ cảnh và đào tạo sau, với chi phí khoảng 2 USD/giờ GPU.
Ngược lại, Giám đốc điều hành của OpenAI, Sam Altman, cho biết chi phí đào tạo GPT-4 vượt quá 100 triệu USD. Quá trình đào tạo GPT-4 kéo dài từ 90 đến 100 ngày, sử dụng 25.000 GPU NVIDIA A100, tổng cộng từ 54 đến 60 triệu giờ GPU, với chi phí khoảng 2,50 đến 3,50 USD/giờ GPU.
Do đó, "mức giá" chi phí đào tạo của DeepSeek so với OpenAI đã trực tiếp gây ra đợt bán tháo hoảng loạn trên thị trường. Các nhà đầu tư tự hỏi: Nếu DeepSeek có thể xây dựng một LLM mạnh hơn với chỉ một phần nhỏ chi phí của OpenAI, thì tại sao chúng ta vẫn cần đầu tư hàng tỷ USD vào cơ sở hạ tầng tính toán AI ở Mỹ? Những khoản đầu tư "cần thiết" vào năng lực tính toán này có thực sự có ý nghĩa không? Lợi tức đầu tư (ROI) và mô hình kinh doanh của các trung tâm dữ liệu AI/HPC sẽ đi về đâu?
Biểu đồ dưới đây trực quan hóa doanh thu mỗi GW của trung tâm dữ liệu khi đào tạo DeepSeek và ChatGPT, càng làm nổi bật vấn đề này.
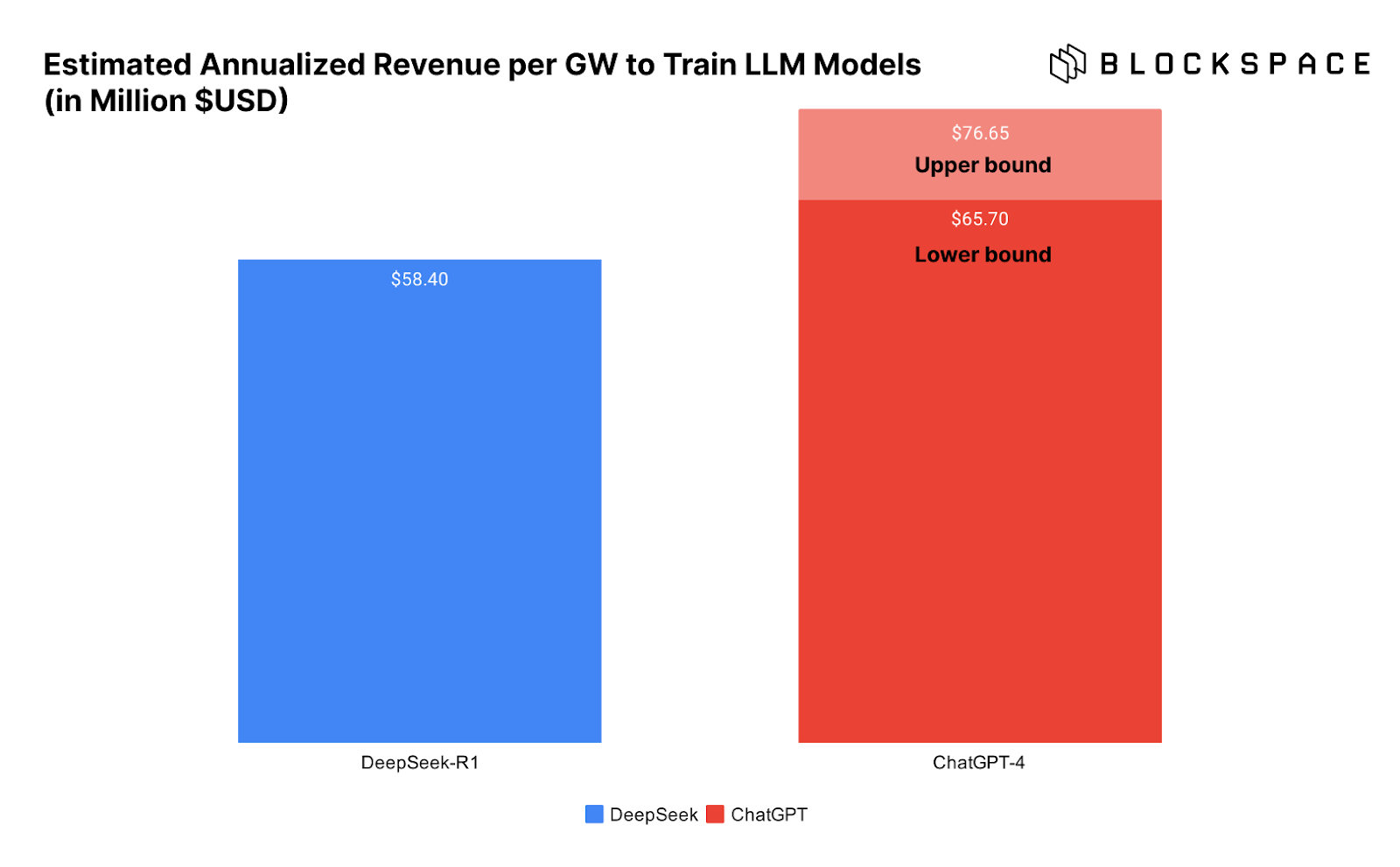
Vấn đề là, chúng ta không thể chắc chắn rằng DeepSeek thực sự đã hoàn thành việc đào tạo mô hình với chi phí thấp như vậy.
Liệu chi phí đào tạo DeepSeek thực sự thấp như vậy?
Tuy nhiên, DeepSeek có thực sự chỉ tốn 5,6 triệu USD để đào tạo mô hình không? Nhiều người trong ngành nghi ngờ điều này, và họ có lý do chính đáng.
Trước hết, trong bản Sách trắng kỹ thuật của DeepSeek, nhóm đã rõ ràng nêu rằng
"Nói cách khác, nếu một phòng thí nghiệm đã đầu tư hàng trăm triệu đô la vào nghiên cứu ban đầu và có một cụm máy tính quy mô lớn hơn, thì họ có thể hoàn thành việc đào tạo cuối cùng chỉ với 5,6 triệu đô la. Tuy nhiên, DeepSeek rõ ràng không chỉ sử dụng 2.048 GPU H800 - họ đã đề cập đến một cụm 10.000 GPU A100 trong một bài báo sớm. Do đó, một nhóm tuyệt vời như vậy nếu muốn bắt đầu từ đầu, chỉ với 2.000 GPU, sẽ không thể chỉ tốn 5,6 triệu đô la để đào tạo ra một mô hình tương tự như R1."
Ngoài ra, Baker chỉ ra rằng, DeepSeek đã sử dụng một phương pháp được gọi là "chưng cất kiến thức" (distillation) để học hỏi từ ChatGPT và đào tạo mô hình của riêng họ.
"Rất có thể DeepSeek không thể hoàn thành việc đào tạo mà không có quyền truy cập hoàn toàn vào GPT-4o và GPT-4o1."
DeepSeek, tiêu thụ năng lượng và Nghịch lý Jevons
Mặc dù khả năng tuyên bố chi phí đào tạo của DeepSeek chỉ 5,6 triệu đô la đang bị hoài nghi, nhưng Gavin Baker chỉ ra rằng, những đột phá của mô hình này - như khả năng tự học, ít tham số hơn, v.v. - thực sự đã làm cho việc đào tạo và suy luận (hay còn gọi là "suy luận" trong ngành, là chi phí chạy AI) trở nên rẻ hơn.
Baker tuyên bố rằng chi phí sử dụng DeepSeek-R1 thấp hơn 93% so với phiên bản o1 của ChatGPT, và chi phí mỗi lần gọi API giảm đáng kể. Mặc dù con số cụ thể 93% có thể vẫn còn tranh cãi, nhưng điểm then chốt là chi phí suy luận của DeepSeek thấp hơn, thậm chí có thể chạy trên phần cứng cục bộ như Mac Studio Pro.
Đây mới là bước đột phá thực sự của DeepSeek - AI trở nên kinh tế hơn. Như một nhận xét ẩn danh đã nói, điều này cảm thấy như Microsoft đã mở mã nguồn trình duyệt web, hoàn toàn phá hủy mô hình truy cập trả phí của Netscape.
DeepSeek đã hoàn toàn mở ra một mô hình mới cho AI, đưa sự phát triển AI vào một giai đoạn cạnh tranh hoàn toàn mới - "Bây giờ, trọng tâm cạnh tranh đã chuyển từ đào tạo AI sang suy luận AI", như Chamath Palihapitiya đã nói.
Trung tâm dữ liệu và ngành công nghiệp điện lực được thúc đẩy bởi AI sẽ đi về đâu?
Như chúng ta đã đề cập ở phần trước, liệu việc động cơ hiệu quả hơn có làm giảm nhu cầu về xăng dầu, hay lại gây tác động tiêu cực đến các ngành công nghiệp phụ thuộc vào ô tô?
Nghịch lý Jevons cho rằng, khi tiến bộ công nghệ cải thiện hiệu quả sử dụng tài nguyên, nhu cầu về chính tài nguyên đó lại tăng lên, vì chi phí thấp hơn sẽ thúc đẩy ứng dụng rộng rãi hơn. Những người đào Bitcoin đã trải nghiệm điều này - mặc dù hiệu suất của các máy đào ASIC liên tục cải thiện, nhưng tổng công suất tính toán của mạng Bitcoin vẫn tiếp tục tăng.
Nhìn chung, thị trường đã chào đón một đối thủ mạnh mẽ hơn, nhưng các quy tắc của trò chơi vẫn chưa thay đổi. Nếu chi phí suy luận và đào tạo AI giảm (đây cũng là xu hướng tất yếu), thì nó sẽ mở khóa nhiều ứng dụng hơn và tiếp tục thúc đẩy nhu cầu ngành công nghiệp AI.






