Nguồn ảnh: Được tạo bởi AI không giới hạn
Việc DeepSeek liên tục trả lời "Máy chủ đang bận, vui lòng thử lại sau" đang khiến người dùng ở khắp nơi cảm thấy bực bội.
DeepSeek, trước đây không được nhiều người biết đến, đã nổi tiếng sau khi ra mắt mô hình ngôn ngữ V3 vào ngày 26 tháng 12 năm 2024, nhằm cạnh tranh với GPT-4. Vào ngày 20 tháng 1, DeepSeek cũng đã ra mắt mô hình ngôn ngữ R1 nhằm cạnh tranh với OpenAI O1. Sau đó, do chất lượng câu trả lời trong "chế độ suy nghĩ sâu" tốt và tín hiệu tích cực về việc chi phí huấn luyện mô hình có thể giảm mạnh, công ty và ứng dụng này đã thu hút được sự chú ý rộng rãi. Sau đó, R1 của DeepSeek liên tục gặp tình trạng quá tải, chức năng tìm kiếm trực tuyến bị gián đoạn, và chế độ suy nghĩ sâu thường xuyên hiển thị thông báo "Máy chủ đang bận", gây phiền toái cho nhiều người dùng.
Cách đây vài tuần, DeepSeek bắt đầu gặp sự cố gián đoạn máy chủ. Vào trưa ngày 27 tháng 1, trang web DeepSeek đã hiển thị "trang web/API của DeepSeek không khả dụng" nhiều lần. Trong ngày đó, DeepSeek trở thành ứng dụng có lượng tải về cao nhất trên iPhone vào cuối tuần, vượt qua cả ChatGPT tại khu vực Mỹ.
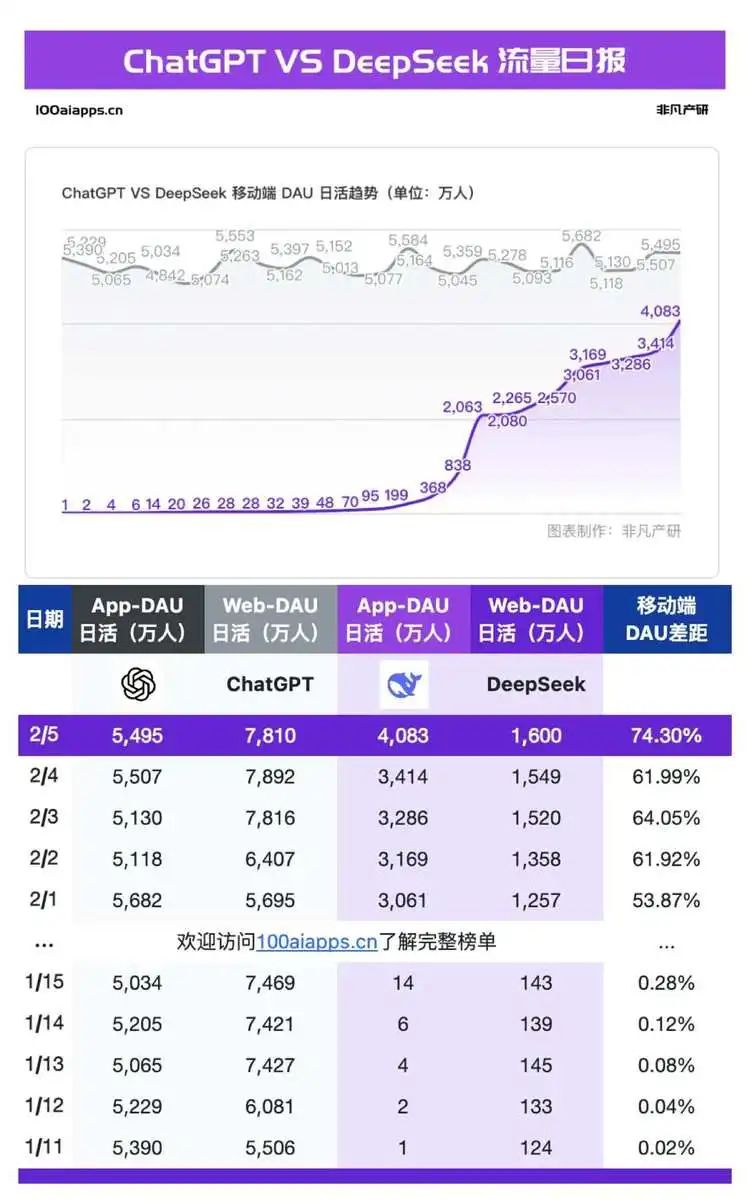
Vào ngày 5 tháng 2, sau 26 ngày ra mắt trên di động, DeepSeek đạt 40 triệu người dùng hoạt động hàng ngày, trong khi ChatGPT di động có 54,95 triệu người dùng hoạt động hàng ngày, tương đương 74,3% của ChatGPT. Gần như ngay khi DeepSeek bước ra khỏi đường cong tăng trưởng dốc, các phản hồi về máy chủ bận rộn liên tục ập đến, người dùng trên toàn thế giới bắt đầu gặp phải sự cố mất kết nối sau vài câu hỏi. Các trang web thay thế DeepSeek cũng bắt đầu xuất hiện, cùng với các dịch vụ đám mây, nhà sản xuất chip và công ty cơ sở hạ tầng ra mắt các giải pháp, và cả các hướng dẫn triển khai cá nhân. Tuy nhiên, sự bực bội của mọi người vẫn chưa được giải quyết: hầu hết các nhà sản xuất quan trọng trên toàn cầu đều tuyên bố hỗ trợ triển khai DeepSeek, nhưng người dùng ở các khu vực vẫn than phiền về tính không ổn định của dịch vụ.
Vậy điều gì đã xảy ra ở đây?
1. Những người quen với ChatGPT không chịu được khi DeepSeek không mở được
Sự bất mãn của mọi người với "máy chủ DeepSeek bận" đến từ việc họ trước đây chủ yếu sử dụng ứng dụng AI hàng đầu là ChatGPT, ít gặp phải tình trạng bị treo.
Kể từ khi dịch vụ của OpenAI ra mắt, mặc dù ChatGPT cũng trải qua một vài sự cố ngừng hoạt động ở mức độ nghiêm trọng nhất (P0), nhưng nhìn chung nó tương đối ổn định, đã tìm được sự cân bằng giữa đổi mới và ổn định, và dần trở thành một phần then chốt của các dịch vụ đám mây truyền thống.

ChatGPT không bị ngừng hoạt động quá nhiều lần
Quá trình suy luận của ChatGPT tương đối ổn định, bao gồm hai bước là mã hóa và giải mã. Bước mã hóa chuyển đổi văn bản đầu vào thành vector, vector chứa thông tin ngữ nghĩa của văn bản đầu vào. Bước giải mã, ChatGPT sử dụng văn bản đã tạo trước đó làm ngữ cảnh, thông qua mô hình Transformer để tạo ra từ hoặc cụm từ tiếp theo, cho đến khi tạo ra câu hoàn chỉnh đáp ứng yêu cầu. Mô hình lớn này thuộc kiến trúc Decoder, quá trình giải mã chính là quá trình lần lượt tạo ra các token (đơn vị nhỏ nhất khi mô hình xử lý văn bản).
Ví dụ, nếu hỏi ChatGPT "Bạn cảm thấy thế nào hôm nay?", ChatGPT sẽ mã hóa câu hỏi này, tạo ra biểu diễn chú ý ở mỗi lớp, dựa trên biểu diễn chú ý của tất cả các token trước đó, dự đoán được token đầu tiên là "Tôi", sau đó tiến hành giải mã, ghép "Tôi" vào "Bạn cảm thấy thế nào hôm nay?", tạo ra biểu diễn chú ý mới, dự đoán token tiếp theo là "rất", và tiếp tục quá trình này cho đến khi tạo ra câu hoàn chỉnh "Bạn cảm thấy thế nào hôm nay? Tôi rất tốt."
Công cụ lập lịch và phân bổ container Kubernetes đóng vai trò "chỉ huy hậu trường" của ChatGPT, chịu trách nhiệm điều phối và phân bổ tài nguyên máy chủ. Khi lượng người dùng vượt quá khả năng chịu tải của mặt phẳng điều khiển Kubernetes, sẽ dẫn đến tình trạng ChatGPT toàn hệ thống bị tê liệt.
Tổng số lần ChatGPT bị tê liệt không nhiều, nhưng điều này được hỗ trợ bởi nguồn lực mạnh mẽ, duy trì hoạt động ổn định. Điều này thường bị bỏ qua.
Nói chung, do quy mô dữ liệu xử lý trong quá trình suy luận thường không lớn, nên yêu cầu về tính toán không cao như quá trình huấn luyện. Ước tính của ngành cho biết, trong quá trình suy luận của mô hình lớn thông thường, bộ nhớ đệm chủ yếu được sử dụng bởi trọng số mô hình, chiếm hơn 80%. Thực tế là, trong các mô hình được tích hợp sẵn trong ChatGPT, kích thước mô hình mặc định đều nhỏ hơn mô hình 671B của DeepSeek-R1, cộng với việc ChatGPT có nhiều GPU hơn DeepSeek rất nhiều, nên tất nhiên sẽ ổn định hơn DS-R1.
DeepSeek-V3 và R1 đều là mô hình 671B, quá trình khởi động mô hình chính là quá trình suy luận, nhu cầu tính toán trong quá trình suy luận cần tương ứng với lượng người dùng, ví dụ 100 triệu người dùng cần 100 triệu GPU, không chỉ lớn mà còn độc lập với tài nguyên huấn luyện, không liên quan. Từ các thông tin, có vẻ như DeepSeek không đủ GPU và tài nguyên tính toán, nên thường xuyên bị treo.
Sự đối lập này khiến những người quen với trải nghiệm mượt mà của ChatGPT không thể chấp nhận, đặc biệt là khi họ càng quan tâm đến R1 hơn.
2. Treo, treo, và vẫn treo
Hơn nữa, nếu so sánh kỹ, tình huống mà OpenAI và DeepSeek gặp phải là rất khác nhau.
Phía trước có Microsoft làm hậu thuẫn, với tư cách là nền tảng độc quyền của OpenAI, dịch vụ đám mây Microsoft Azure đang chạy ChatGPT, Dalle-E 2 và GitHub Copilot, sau đó, tổ hợp này trở thành mô hình kinh điển của đám mây + AI, và nhanh chóng trở thành tiêu chuẩn trong ngành. Trong khi DeepSeek, mặc dù là startup, nhưng phần lớn dựa vào trung tâm dữ liệu tự xây dựng, tương tự như Google, chứ không phụ thuộc vào nhà cung cấp dịch vụ đám mây bên thứ ba. Theo thông tin công khai, DeepSeek chưa bắt đầu hợp tác với bất kỳ nhà cung cấp đám mây hoặc nhà sản xuất chip nào (mặc dù trong dịp Tết Nguyên đán, các nhà cung cấp đám mây đã tuyên bố cho DeepSeek chạy trên nền tảng của họ, nhưng họ chưa thực sự hợp tác).
Hơn nữa, DeepSeek đối mặt với mức tăng trưởng người dùng chưa từng có, có nghĩa là thời gian chuẩn bị cho các tình huống khẩn cấp của nó cũng ít hơn ChatGPT.
Hiệu suất tốt của DeepSeek đến từ việc tối ưu hóa tổng thể về phần cứng và hệ thống. Công ty mẹ của DeepSeek, Phương Lượng Lượng, đã đầu tư 200 triệu đô la vào việc xây dựng cụm siêu máy tính Firefly vào năm 2019, và đến năm 2022 đã âm thầm tích lũy hàng nghìn card GPU A100, để tăng cường hiệu quả huấn luyện song song. Ngành công nghiệp tin rằng, cụm Firefly có thể sử dụng hàng nghìn đến hàng chục nghìn GPU hiệu suất cao (như NVIDIA A100/H100 hoặc chip trong nước) để cung cấp khả năng tính toán song song mạnh mẽ. Hiện tại, cụm Firefly đang hỗ trợ việc huấn luyện các mô hình DeepSeek-R1, DeepSeek-MoE, những mô hình này có hiệu suất gần với mức của GPT-4 trong các nhiệm vụ toán học, lập trình, v.v.
Cụm Firefly thể hiện hành trình khám phá kiến trúc và phương pháp mới của DeepSeek, cũng khiến người ngoài tin rằng, thông qua những đổi mới công nghệ này, DS đã giảm được chi phí huấn luyện, chỉ cần một phần nhỏ so với các mô hình AI hàng đầu phương Tây, nhưng vẫn có thể huấn luyện ra R1 có hiệu suất tương đương. Theo ước tính của SemiAnalysis, DeepSeek thực sự sở hữu một lượng tài nguyên tính toán khổng lồ: DeepSeek đã tích lũy 60.000 card GPU NVIDIA, trong đó bao gồm 10.000 card A100, 10.000 card H100, 10.000 card "phiên bản đặc biệt" H800 và 30.000 card "phiên bản đặc biệt" H20.Dưới đây là bản dịch tiếng Việt của văn bản trên:
Theo phó chủ tịch Quỹ Ánh Sáng Vĩnh Cửu, lượng tính toán khổng lồ của DeepSeek trong giai đoạn huấn luyện có thể được lập kế hoạch và dự đoán, không dễ xảy ra tình trạng thiếu tính toán, nhưng tính toán suy luận có độ không chắc chắn lớn hơn, vì chủ yếu phụ thuộc vào quy mô người dùng và mức độ sử dụng, tương đối linh hoạt hơn, "Tính toán suy luận sẽ tăng theo một quy luật nhất định, nhưng khi DeepSeek trở thành một sản phẩm hiện tượng, quy mô người dùng và mức độ sử dụng tăng vọt trong thời gian ngắn, dẫn đến nhu cầu tính toán suy luận tăng vọt, do đó xảy ra tình trạng卡顿."
Nhà thiết kế sản phẩm mô hình hoạt động tích cực ngay lập tức, nhà phát triển độc lập Quy Tàng đồng ý rằng vấn đề về lượng là nguyên nhân chính gây ra tình trạng卡顿của DeepSeek, ông cho rằng DS hiện là ứng dụng di động có lượt tải về cao nhất trên 140 thị trường toàn cầu, hiện tại việc卡không thể chịu đựng được, ngay cả khi sử dụng các卡mới cũng không được, vì "việc làm cloud với các卡mới cần thời gian".
"Chi phí chạy chip NVIDIA A100, H100trong một giờ có giá thị trường hợp lý, DeepSeek so với chi phí suy luận đầu ra Token rẻ hơn OpenAI các mô hình tương tự trên 90%, sai lệch tính toán của mọi người không lớn, do đó cấu trúc mô hình MOE không phải là vấn đề chính, nhưng số lượng GPU mà DS sở hữu quyết định số lượng Token họ có thể sản xuất cung cấp mỗi phút, ngay cả khi có thể sử dụng thêm GPU để cung cấp dịch vụ suy luận cho người dùng, thay vì dùng cho nghiên cứu tiền huấn luyện, nhưng giới hạn vẫn ở đó." Nhà phát triển ứng dụng AI bản địa Tiểu Mèo Đèn Soi cũng có quan điểm tương tự.
Cũng có những người trong ngành cho biết, tình trạng卡顿của DeepSeek thực chất là do cloud riêng chưa được chuẩn bị tốt.
Tấn công của hacker cũng là một yếu tố thúc đẩy khác gây ra tình trạng卡顿của R1. Ngày 30/1, các phương tiện truyền thông nhận được thông tin từ công ty an ninh mạng Qihoo 360 rằng, cường độ tấn công nhắm vào dịch vụ trực tuyến của DeepSeek đột ngột tăng lên, chỉ thị tấn công tăng hơn 100 lần so với ngày 28/1. Phòng thí nghiệm Xlab của Qihoo 360 quan sát thấy ít nhất có 2 mạng botnet tham gia vào cuộc tấn công.
Nhưng đối với tình trạng卡顿của R1 do chính dịch vụ của mình, có vẻ như có một giải pháp khá rõ ràng, đó là dịch vụ do bên thứ ba cung cấp. Đây cũng là cảnh tượng sôi động nhất mà chúng tôi chứng kiến trong dịp Tết Nguyên đán - các nhà sản xuất lần lượt triển khai dịch vụ, đáp ứng nhu cầu của mọi người đối với DeepSeek.
Ngày 31/1, NVIDIA thông báo rằng NVIDIA NIM đã có thể sử dụng DeepSeek-R1, trước đó NVIDIA bị ảnh hưởng bởi DeepSeek, một đêm bị xóa gần 600 tỷ USD giá trị vốn hóa thị trường. Cùng ngày, người dùng của Amazon Web Services (AWS) có thể triển khai mô hình cơ bản R1 mới nhất của DeepSeek trên nền tảng trí tuệ nhân tạo Amazon Bedrock và Amazon SageMaker. Sau đó, các ứng dụng AI mới nổi như Perplexity, Cursor cũng lần lượt kết nối với DeepSeek. Microsoft thậm chí đã nhanh hơn Amazon và NVIDIA, sớm triển khai DeepSeek-R1 trên dịch vụ đám mây Azure và Github.
Bắt đầu từ ngày 1/2 (mùng 4 Tết), Huawei Cloud, Alibaba Cloud, Volcano Engine thuộc TikTok và Tencent Cloud cũng tham gia, họ thường cung cấp dịch vụ triển khai toàn bộ chuỗi mô hình, mọi kích thước của DeepSeek. Sau đó là các nhà sản xuất chip AI như Biren Technology, Horizon Robotics, Cambricon, Moxing, họ tuyên bố đã tích hợp phiên bản gốc hoặc phiên bản chưng cất nhỏ hơn của DeepSeek. Về phía các công ty phần mềm, một số sản phẩm của Yonyou, Kingdee đã tích hợp mô hình DeepSeek để tăng cường sức mạnh sản phẩm, cuối cùng là một số sản phẩm của các nhà sản xuất thiết bị cuối như Lenovo, Huawei, Honor cũng tích hợp mô hình DeepSeek để sử dụng làm trợ lý cá nhân và k舱thông minh ô tô.
Cho đến nay, DeepSeek đã thu hút một mạng lưới bạn bè khổng lồ nhờ giá trị bản thân, bao gồm các nhà cung cấp dịch vụ đám mây trong và ngoài nước, nhà điều hành, công ty chứng khoán và nền tảng cấp quốc gia như Nền tảng Siêu Máy Tính Quốc Gia. Do DeepSeek-R1 là mô hình hoàn toàn mã nguồn mở, các nhà cung cấp dịch vụ đã trở thành những người hưởng lợi từ mô hình DS. Một mặt, điều này đã tăng đáng kể tiếng vang của DS, đồng thời cũng gây ra hiện tượng卡顿thường xuyên hơn, các nhà cung cấp dịch vụ và chính DS ngày càng bị vướng vào làn sóng người dùng ùn ùn kéo đến, nhưng lại không tìm ra được chìa khóa để giải quyết vấn đề sử dụng ổn định.
Xét về mặt lý thuyết, các nhà cung cấp dịch vụ đám mây có đủ tính toán và khả năng suy luận để chạy các mô hình DeepSeek V3 và R1 gốc có tới 671 tỷ tham số, họ cung cấp dịch vụ triển khai DeepSeek để giảm rào cản cho doanh nghiệp sử dụng, cung cấp API của mô hình DS sau khi triển khai, được cho là có thể cung cấp trải nghiệm tốt hơn so với API do DS cung cấp.
Nhưng trong thực tế, vấn đề về trải nghiệm chạy mô hình DeepSeek-R1 vẫn chưa được giải quyết trong các dịch vụ của các nhà cung cấp, những người bên ngoài cho rằng các nhà cung cấp dịch vụ không thiếu卡, nhưng thực tế họ triển khai R1, các nhà phát triển phản hồi về tính ổn định của phản ứng không ổn định hoàn toàn tương đương với R1, điều này chủ yếu là do họ không thể phân bổ nhiều卡cho R1 để suy luận.
"Nhiệt độ R1 vẫn ở mức cao, các nhà cung cấp dịch vụ cần phải quan tâm đến các mô hình khác được kết nối, họ chỉ có thể cung cấp số lượng卡rất hạn chế cho R1, trong khi nhiệt độ R1 lại cao, bất cứ ai cung cấp R1 với giá tương đối thấp sẽ bị sụp đổ." Nhà thiết kế sản phẩm mô hình, nhà phát triển độc lập Quy Tàng giải thích lý do cho Siêu Sao Silicon.
Tối ưu hóa triển khai mô hình là một lĩnh vực rộng lớn bao gồm nhiều khâu, từ khi hoàn thành huấn luyện đến triển khai thực tế trên phần cứng, liên quan đến nhiều công việc ở nhiều cấp độ, nhưng đối với sự cố卡顿của DeepSeek, nguyên nhân có thể đơn giản hơn, chẳng hạn như mô hình quá lớn và chuẩn bị trước khi ra mắt chưa đủ.
Trước khi một mô hình lớn nổi tiếng ra mắt, sẽ gặp phải nhiều thách thức liên quan đến kỹ thuật, kỹ thuật và kinh doanh, chẳng hạn như tính nhất quán giữa dữ liệu huấn luyện và dữ liệu môi trường sản xuất, độ trễ dữ liệu và tác động của tính thời gian thực đối với hiệu quả suy luận của mô hình, hiệu quả suy luận trực tuyến và mức sử dụng tài nguyên quá cao, khả năng tổng quát của mô hình không đủ, cũng như các vấn đề kỹ thuật như độ ổn định của dịch vụ, tích hợp API và hệ thống, v.v.
Nhiều mô hình lớn nổi tiếng hiện nay đều rất coi trọng việc tối ưu hóa suy luận trước khi ra mắt, điều này là do vấn đề về thời gian tính toán và sử dụng bộ nhớ, cái trước là do độ trễ suy luận quá lâu, gây ra trải nghiệm người dùng kém, thậm chí không thể đáp ứng yêu cầu về độ trễ, tức là hiện tượng卡顿, cái sau là do số lượng tham số mô hình lớn, chiếm dụng bộ nhớ đệm, thậm chí một GPU cũng không chứa được, cũng sẽ dẫn đến tình trạng卡顿.
Ông Vĩnh Cửu giải thích với Siêu Sao Silicon rằng các nhà cung cấp dịch vụ gặp thách thức khi cung cấp dịch vụ R1, bản chất là do cấu trúc mô hình DS đặc biệt, mô hình quá lớn + kiến trúc MOE (cấu trúc hỗn hợp chuyên gia, một cách tính toán hiệu quả), "(các nhà cung cấp dịch vụ) cần thời gian để tối ưu hóa, nhưng nhiệt độ thị trường có cửa sổ thời gian, vì vậy họ thường là lên trước rồi mới tối ưu hóa, chứ không phải tối ưu hóa đầy đủ rồi mới lên."
Để R1 chạy ổn định, hiện nay then chốt là khả năng dự trữ và tối ưu hóa suy luận. DeepSeek cần tìm cách giảm chi phí suy luận, giảm số lượng Token đầu ra mỗi lần.
Đồng thời, tình trạng卡顿cũng cho thấy lượng tính toán của DS có thể không lớn như SemiAnalysis nói, Quỹ Vạn Phương cần dùng卡, nhóm huấn luyện DeepSeek cũng cần dùng卡, số卡dành cho người dùng luôn không nhiều. Theo tình hình hiện tại, trong ngắn hạn DeepSeek có thể không có động lực tốn tiền thuê dịch vụ để cung cấp tr