

Tác giả: Vương Lộ, Dingjiaoone (định tiêu điểm một) bản gốc
DeepSeek đã khiến toàn thế giới không thể ngồi yên.
Hôm qua, Elon Musk đã xuất hiện trong một buổi phát sóng trực tiếp với "trí tuệ nhân tạo thông minh nhất trên Trái đất" - Gork 3, tự nhận là "khả năng suy luận vượt trội so với tất cả các mô hình đã biết", và cũng vượt trội hơn DeepSeek R1, OpenAI o1 về điểm số trong thời gian suy luận - kiểm tra. Gần đây, ứng dụng cấp quốc gia WeChat đã thông báo sẽ tích hợp DeepSeek R1, đang trong quá trình thử nghiệm xám, và được coi là sự kết hợp "bom tấn" sẽ làm thay đổi lĩnh vực tìm kiếm AI.
Hiện nay, nhiều công ty công nghệ lớn toàn cầu như Microsoft, Nvidia, Huawei Cloud, Tencent Cloud đã tích hợp DeepSeek. Người dùng mạng cũng đã phát triển các ứng dụng mới lạ như xem bói, dự đoán xổ số, và sức nóng của chúng đã trực tiếp chuyển thành tiền thật, thúc đẩy giá trị định giá của DeepSeek tăng lên, cao nhất đã đạt 100 tỷ USD.
Ngoài việc miễn phí và dễ sử dụng, lý do DeepSeek có thể vươn ra ngoài vòng là vì với chi phí GPU chỉ 5,576 nghìn USD, họ đã huấn luyện ra DeepSeek R1 có khả năng không kém OpenAI o1. Cuối cùng, trong "cuộc chiến của hàng trăm mô hình" trong những năm qua, các công ty AI lớn trong và ngoài nước đều đã đổ hàng chục tỷ thậm chí hàng trăm tỷ USD. Gork 3 trở thành "trí tuệ nhân tạo thông minh nhất toàn cầu" cũng với một mức chi phí đắt đỏ, Elon Musk cho biết Gork 3 đã tiêu tốn tích lũy 200.000 card GPU Nvidia (khoảng 3 nghìn USD/card), trong khi các chuyên gia trong ngành ước tính DeepSeek chỉ tốn hơn 10.000 card.
Tuy nhiên, cũng có người "cuộn" DeepSeek về chi phí. Gần đây, nhóm của Lý Phi Phi tuyên bố rằng chỉ với chi phí cloud computing dưới 50 USD, họ đã huấn luyện ra một mô hình suy luận S1, có khả năng toán học và lập trình tương đương với o1 của OpenAI và R1 của DeepSeek. Tuy nhiên, cần lưu ý rằng S1 là một mô hình cỡ trung, vẫn có khoảng cách về quy mô tham số so với cấp tỷ tham số của DeepSeek R1.
Mặc dù vậy, sự chênh lệch chi phí huấn luyện khổng lồ từ 50 USD đến hàng trăm tỷ USD vẫn khiến mọi người tò mò, một mặt muốn biết khả năng của DeepSeek mạnh đến mức nào, vì sao mọi công ty đều đang cố gắng theo kịp hoặc vượt qua nó, mặt khác, huấn luyện một mô hình lớn thực sự tốn bao nhiêu tiền? Nó liên quan đến những giai đoạn nào? Trong tương lai, liệu có thể tiếp tục giảm chi phí huấn luyện?
DeepSeek bị "tổng quát hóa một phần"
Theo những người trong nghề, trước khi trả lời những câu hỏi này, cần phải làm rõ một số khái niệm.
Trước tiên là sự hiểu lầm "tổng quát hóa một phần" về DeepSeek. Mọi người kinh ngạc về một trong những mô hình lớn của nó - mô hình suy luận lớn DeepSeek-R1, nhưng nó vẫn có các mô hình lớn khác, và các sản phẩm mô hình lớn khác nhau có chức năng khác nhau. Và 5,576 nghìn USD là chi phí GPU trong quá trình huấn luyện mô hình tổng quát lớn DeepSeek-V3, có thể được hiểu là chi phí tính toán thuần túy.
So sánh đơn giản:
Mô hình tổng quát lớn:
Nhận lệnh cụ thể, phân tích các bước, người dùng cần mô tả nhiệm vụ rõ ràng, bao gồm cả thứ tự trả lời, ví dụ như người dùng cần nhắc nhở là trước tiên làm tóm tắt rồi mới đưa ra tiêu đề, hay ngược lại.
Tốc độ phản hồi nhanh, dựa trên dự đoán xác suất (phản ứng nhanh), dự đoán câu trả lời thông qua dữ liệu lớn.
Mô hình suy luận lớn:
Nhận nhiệm vụ đơn giản, rõ ràng, tập trung vào mục tiêu, người dùng chỉ cần nói ra yêu cầu, nó có thể tự lên kế hoạch.
Tốc độ phản hồi chậm, dựa trên suy luận chuỗi (suy nghĩ chậm), suy luận các bước của vấn đề để đưa ra câu trả lời.
Sự khác biệt chính về kỹ thuật giữa hai loại này là ở dữ liệu huấn luyện, mô hình tổng quát lớn là câu hỏi + câu trả lời, mô hình suy luận lớn là câu hỏi + quá trình suy nghĩ + câu trả lời.
Thứ hai, do mô hình suy luận lớn DeepSeek-R1 của Deepseek nhận được nhiều sự chú ý hơn, nhiều người sai lầm khi cho rằng mô hình suy luận lớn nhất định phải cao cấp hơn mô hình tổng quát lớn.
Cần khẳng định rằng, mô hình suy luận lớn là một loại mô hình tiên phong, là một mô hình tiền huấn luyện mới mà OpenAI đưa ra, tăng cường tính toán ở giai đoạn suy luận. So với mô hình tổng quát lớn, mô hình suy luận lớn tốn kém hơn, thời gian huấn luyện cũng lâu hơn.
Nhưng điều này không có nghĩa là mô hình suy luận lớn nhất định tốt hơn mô hình tổng quát lớn, thậm chí đối với một số loại vấn đề, mô hình suy luận lớn lại trở nên vô dụng.
Chuyên gia lĩnh vực mô hình lớn nổi tiếng Lưu Thông giải thích cho "Dingjiaoone" rằng, ví dụ như hỏi về thủ đô của một quốc gia/thành phố của một tỉnh, mô hình suy luận lớn sẽ không hiệu quả bằng mô hình tổng quát lớn.

Suy nghĩ quá mức của DeepSeek-R1 khi đối mặt với vấn đề đơn giản
Ông nói rằng, đối với những loại câu hỏi tương đối đơn giản như vậy, không chỉ hiệu suất trả lời của mô hình suy luận lớn thấp hơn mô hình tổng quát lớn, mà chi phí tính toán tiêu tốn cũng đáng kể, thậm chí có thể dẫn đến suy nghĩ quá mức và cuối cùng trả lời sai.
Ông khuyên nên sử dụng mô hình suy luận cho các nhiệm vụ toán học khó, lập trình thách thức, còn các nhiệm vụ đơn giản như tóm tắt, dịch thuật, trả lời cơ bản thì mô hình tổng quát sẽ hiệu quả hơn.
Thứ ba là thực lực thực sự của DeepSeek như thế nào.
Tổng hợp các bảng xếp hạng uy tín và quan điểm của những người trong nghề, "Dingjiaoone" xếp DeepSeek ở vị trí nhất định trong lĩnh vực mô hình suy luận lớn và mô hình tổng quát lớn.
Nhóm mô hình suy luận lớn hàng đầu chủ yếu có bốn công ty: OpenAI o-series (như o3-mini) ở nước ngoài, Gemini 2.0 của Google; DeepSeek-R1 và QwQ của Alibaba ở trong nước.
Không chỉ một người trong nghề cho rằng, mặc dù giới bên ngoài đều đang thảo luận về DeepSeek-R1 như một mô hình hàng đầu trong nước, có thể vượt qua OpenAI, nhưng về mặt kỹ thuật, so với o3 mới nhất của OpenAI, vẫn còn một khoảng cách nhất định.
Ý nghĩa quan trọng hơn của nó là đã thu hẹp đáng kể khoảng cách giữa trình độ hàng đầu trong và ngoài nước. "Nếu như trước đây khoảng cách là 2-3 thế hệ, thì sau khi xuất hiện DeepSeek-R1, nó đã thu hẹp chỉ còn 0,5 thế hệ", chuyên gia lâu năm trong ngành AI Giang Thụ nói.
Ông chia sẻ kinh nghiệm sử dụng cá nhân, giới thiệu ưu nhược điểm của bốn công ty:
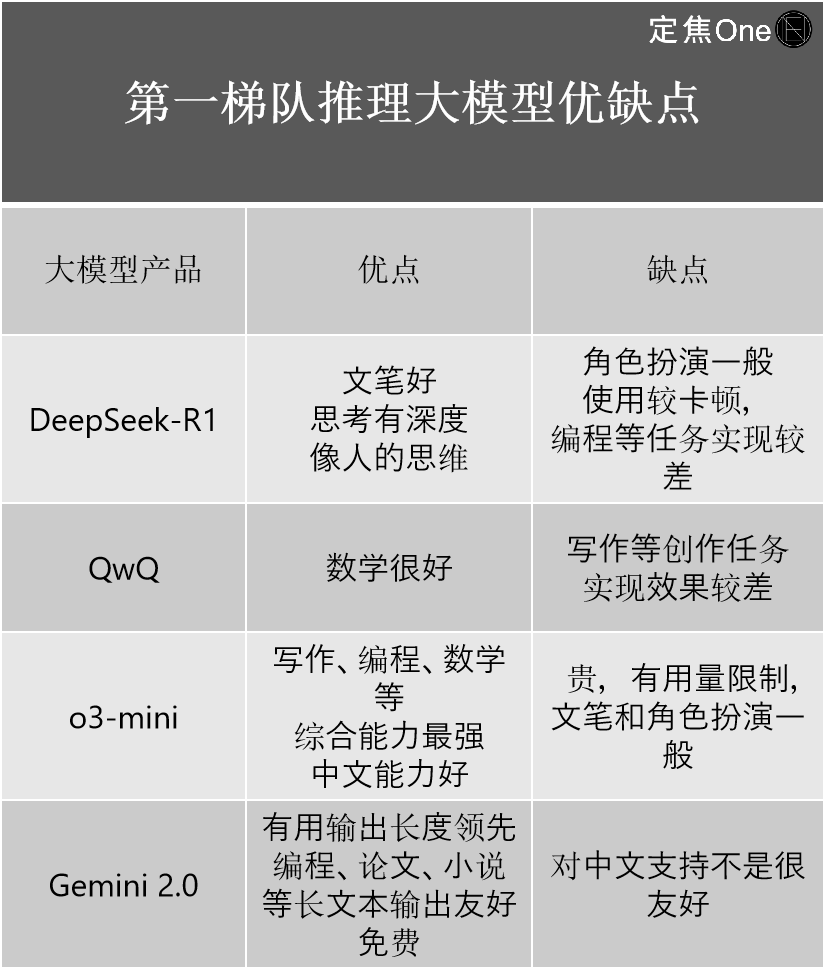
Trong lĩnh vực mô hình tổng quát lớn, dựa trên bảng xếp hạng LM Arena (nền tảng mã nguồn mở dùng để đánh giá và so sánh hiệu suất của các mô hình ngôn ngữ lớn (LLM)), nhóm hàng đầu có năm công ty: Gemini (đóng nguồn) của Google ở nước ngoài, ChatGPT của OpenAI, Claude của Anthropic; DeepSeek và Qwen của Alibaba trong nước.
Giang Thụ cũng liệt kê trải nghiệm sử dụng của họ.
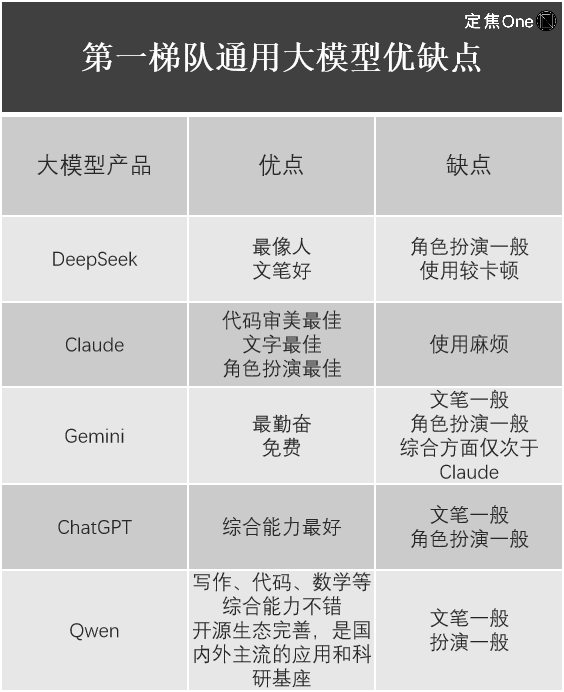
Dễ thấy rằng, mặc dù DeepSeek-R1 đã gây chấn động toàn ngành công nghệ, giá trị của nó là không thể phủ nhận, nhưng mỗi sản phẩm mô hình lớn đều có ưu nhược điểm riêng, DeepSeek cũng không phải là hoàn hảo ở mọi mặt. Ví dụ, Lưu Thông phát hiện rằng mô hình đa phương tiện lớn mới nhất của DeepSeek, Janus-Pro, chuyên về hiểu và tạo tác vụ hình ảnh, lại có hiệu quả sử dụng không tốt.
Huấn luyện mô hình lớn tốn bao nhiêu tiền?
Quay lại vấn đề chi phí huấn luyện mô hình lớn, một
Dưới đây là bản dịch tiếng Việt của văn bản trên:Ông Lưu Thông đưa ra các ví dụ, chẳng hạn như việc mua hay thuê phần cứng, giá cả giữa hai lựa chọn này có sự chênh lệch rất lớn. Nếu mua, khoản đầu tư một lần ban đầu sẽ rất lớn, nhưng sau đó sẽ giảm đáng kể, chỉ cần trả tiền điện. Nếu thuê, khoản đầu tư ban đầu có thể không lớn, nhưng khoản chi phí này sẽ không thể tiết kiệm được. Đối với dữ liệu đào tạo được sử dụng, việc mua dữ liệu sẵn có hay tự mình thu thập cũng có sự khác biệt rất lớn. Chi phí đào tạo mỗi lần cũng không giống nhau, như lần đầu tiên cần phải viết trình thu thập dữ liệu, lọc dữ liệu, nhưng ở phiên bản tiếp theo do có thể sử dụng lại các thao tác trước đó nên chi phí sẽ giảm. Và trước khi trình bày mô hình cuối cùng, số lượng phiên bản lặp lại cũng quyết định mức độ cao thấp của chi phí, nhưng các công ty mô hình lớn thì rất kín tiếng về vấn đề này.
Tóm lại, mỗi giai đoạn đều liên quan đến rất nhiều khoản chi phí ẩn cao.
Trước đây, giới ngoài đã ước tính dựa trên GPU rằng, trong các mô hình hàng đầu, chi phí đào tạo của GPT-4 khoảng 78 triệu USD, Llama3.1 hơn 60 triệu USD, Claude3.5 khoảng 100 triệu USD. Nhưng do những mô hình lớn hàng đầu này đều là mã nguồn đóng, và liệu các công ty có tình trạng lãng phí tài nguyên tính toán hay không, nên giới ngoài rất khó biết được. Cho đến khi DeepSeek xuất hiện với chi phí 5,576 nghìn USD.

Nguồn ảnh / Unsplash
Cần lưu ý rằng, 5,576 nghìn USD là chi phí đào tạo của mô hình nền DeepSeek-V3 được đề cập trong báo cáo kỹ thuật. "Chỉ có thể đại diện cho chi phí đào tạo của lần cuối cùng thành công, các chi phí nghiên cứu, kiến trúc và thử nghiệm thuật toán trước đó không được bao gồm; còn chi phí đào tạo cụ thể của phiên bản R1 thì báo cáo không đề cập đến." Ông Lưu Thông nói.
Công ty phân tích và dự báo thị trường bán dẫn SemiAnalysis chỉ ra rằng, xét đến các yếu tố như chi phí vốn máy chủ, chi phí vận hành, tổng chi phí của DeepSeek có thể đạt 2,573 tỷ USD trong vòng 4 năm.
Những người trong nghề cho rằng, so với khoản đầu tư hàng tỷ USD của các công ty mô hình lớn khác, thì ngay cả khi tính theo 2,573 tỷ USD, chi phí của DeepSeek vẫn là thấp.
Hơn nữa, quá trình đào tạo DeepSeek-V3 chỉ cần 2.048 GPU của Nvidia, số GPU-giờ chỉ là 2,788 nghìn, trong khi đó OpenAI đã tiêu tốn hàng vạn GPU, Meta đào tạo mô hình Llama-3.1-405B sử dụng 30,84 triệu GPU-giờ.
DeepSeek không chỉ hiệu quả hơn ở giai đoạn đào tạo mô hình, mà còn hiệu quả và chi phí thấp hơn ở giai đoạn gọi suy luận.
Từ mức định giá API của các mô hình lớn mà DeepSeek cung cấp (nhà phát triển có thể gọi API của các mô hình lớn để thực hiện chức năng như tạo văn bản, tương tác hội thoại, tạo mã...), có thể thấy chi phí của DeepSeek thấp hơn "những người như OpenAI". Thông thường, API có chi phí phát triển cao thường cần định giá cao để thu hồi chi phí.
Định giá API của DeepSeek-R1 là: 1 đồng mỗi 1 triệu token đầu vào (trúng bộ nhớ cache), 16 đồng mỗi 1 triệu token đầu ra, trong khi đó OpenAI o3-mini, định giá mỗi 1 triệu token đầu vào (trúng bộ nhớ cache) là 0,55 USD (4 đồng), đầu ra là 4,4 USD (31 đồng).
Trúng bộ nhớ cache, tức là lấy dữ liệu từ bộ nhớ cache thay vì tính toán lại hoặc gọi mô hình để tạo kết quả, có thể giảm thời gian xử lý dữ liệu và chi phí. Ngành công nghiệp phân biệt trúng và không trúng bộ nhớ cache để tăng tính cạnh tranh của định giá API, giá thấp cũng giúp các doanh nghiệp vừa và nhỏ dễ tiếp cận hơn.
Gần đây, DeepSeek-V3 đã kết thúc giai đoạn ưu đãi, mặc dù đã tăng từ 0,1 đồng lên 0,5 đồng mỗi 1 triệu token đầu vào (trúng bộ nhớ cache), và từ 2 đồng lên 8 đồng mỗi 1 triệu token đầu ra, nhưng vẫn thấp hơn các mô hình chủ lưu khác.
Mặc dù rất khó ước tính tổng chi phí đào tạo mô hình lớn, nhưng những người trong nghề đều tin rằng, DeepSeek có thể đại diện cho mức chi phí thấp nhất của mô hình lớn hàng đầu hiện nay, và trong tương lai, các công ty khác sẽ tham khảo DeepSeek để giảm chi phí.
Bài học về giảm chi phí của DeepSeek
DeepSeek tiết kiệm được ở đâu? Tổng hợp từ những người trong nghề, từ cấu trúc mô hình - tiền đào tạo - đào tạo sau, họ đều đã thực hiện tối ưu hóa ở mỗi khía cạnh.
Ví dụ, để đảm bảo tính chuyên nghiệp của câu trả lời, nhiều công ty mô hình lớn sử dụng mô hình MoE (Mixture of Experts - Hỗn hợp các chuyên gia), nghĩa là khi gặp một vấn đề phức tạp, mô hình lớn sẽ chia nhỏ thành nhiều nhiệm vụ phụ, sau đó giao cho các chuyên gia khác nhau giải quyết. Mặc dù nhiều công ty mô hình lớn đã từng đề cập đến mô hình này, nhưng DeepSeek đã đạt đến mức độ chuyên môn hóa tối đa của các chuyên gia.
Bí quyết là sử dụng phân chia chuyên gia chi tiết (chia nhỏ các chuyên gia trong cùng một lĩnh vực thành các nhiệm vụ phụ) và cách ly chuyên gia chia sẻ (cách ly một số chuyên gia để giảm sự trùng lặp kiến thức), điều này giúp tăng hiệu quả tham số MoE và hiệu suất, đạt được câu trả lời nhanh hơn và chính xác hơn.
Một người trong nghề ước tính rằng, MoE của DeepSeek chỉ sử dụng khoảng 40% lượng tính toán so với LLaMA2-7B nhưng đạt hiệu quả tương đương.
Xử lý dữ liệu cũng là một thách thức lớn trong việc đào tạo mô hình lớn, mọi người đều tìm cách tăng hiệu quả tính toán, đồng thời giảm nhu cầu về bộ nhớ và băng thông. DeepSeek đã tìm ra phương pháp là sử dụng đào tạo độ chính xác thấp FP8 (để tăng tốc độ đào tạo học sâu), "điều này dẫn đầu so với các mô hình nguồn mở hiện có, vì hầu hết các mô hình lớn đều sử dụng đào tạo độ chính xác hỗn hợp FP16 hoặc BF16, tốc độ đào tạo FP8 nhanh hơn nhiều so với chúng." Ông Lưu Thông nói.
Trong việc tăng cường học tập ở giai đoạn đào tạo sau, tối ưu hóa chiến lược là một thách thức lớn, có thể hiểu là giúp mô hình lớn ra quyết định tốt hơn, ví dụ như AlphaGo đã học cách chọn nước đi tối ưu nhất trong cờ vây thông qua tối ưu hóa chiến lược.
DeepSeek chọn sử dụng thuật toán GRPO (Grouped Relative Policy Optimization - Tối ưu hóa chính sách tương đối theo nhóm) thay vì PPO (Proximal Policy Optimization - Tối ưu hóa chính sách gần), sự khác biệt chính là trong quá trình tối ưu hóa thuật toán, GRPO ước tính hàm ưu thế thông qua phần thưởng tương đối trong nhóm, còn PPO sử dụng mô hình giá trị riêng biệt. Ít một mô hình như vậy, yêu cầu về sức tính toán tự nhiên sẽ thấp hơn, cũng sẽ tiết kiệm chi phí.
Và ở mức độ suy luận, sử dụng cơ chế chú ý tiềm ẩn đa đầu (MLA - Multi-Head Latent Attention) thay vì chú ý đa đầu truyền thống (MHA - Multi-Head Attention), giảm đáng kể lượng bộ nhớ và độ phức tạp tính toán, lợi ích trực tiếp là chi phí giao diện API giảm.
Tuy nhiên, điều lớn nhất mà DeepSeek mang lại cho ông Lưu Thông là, có thể từ nhiều góc độ khác nhau để nâng cao khả năng suy luận của mô hình lớn, tinh chỉnh mô hình thuần túy (SFT) và học tăng cường thuần túy (RLHF) đều có thể tạo ra mô hình suy luận lớn tốt.
Nguồn ảnh / Pexels
Nghĩa là, hiện nay để tạo mô hình suy luận, có thể có 4 cách:
Thứ nhất: Học tăng cường thuần túy (DeepSeek-R1-zero)
Thứ hai: SFT + Học tăng cường (DeepSeek-R1)
Thứ ba: SFT thuần túy (mô hình chưng cất của DeepSeek)
Thứ tư: Chỉ sử dụng lời nhắc (mô hình nhỏ chi phí thấp)
"Trước đây trong ngành, mọi người chỉ biết SFT + Học tăng cường, không ai nghĩ rằng, hóa ra làm SFT thuần túy và Học tăng cường thuần túy cũng có thể đạt được hiệu quả rất tốt." Ông Lưu Thông nói.
Việc giảm chi phí của DeepSe






