

Vào ngày 18 tháng 2 theo giờ Bắc Kinh, Elon Musk và đội xAI đã chính thức phát hành phiên bản mới nhất của Grok, đó là Grok3, trong một buổi phát sóng trực tiếp.
Trước khi diễn ra sự kiện phát hành này, với việc liên tục tung ra các thông tin liên quan cùng với việc Elon Musk tự mình không ngừng nghỉ quảng bá và kích động, đã khiến toàn thế giới mong đợi Grok3 ở mức độ chưa từng có. Một tuần trước, trong buổi phát sóng trực tiếp, Musk đã tự tin tuyên bố "xAI sắp tung ra một mô hình AI tốt hơn" khi bình luận về DeepSeek R1.
Dựa trên dữ liệu trình diễn tại hiện trường, Grok3 đã vượt qua tất cả các mô hình chủ lưu hiện tại trong các bài kiểm tra chuẩn về toán học, khoa học và lập trình, Musk thậm chí còn tuyên bố Grok 3 sẽ được sử dụng cho các nhiệm vụ tính toán của sứ mệnh Sao Hỏa của SpaceX và dự đoán "sẽ đạt được bước đột phá cấp độ Giải thưởng Nobel trong vòng ba năm tới".
Tuy nhiên, tất cả những điều này hiện tại chỉ là quan điểm của riêng Musk. Sau khi phát hành, tôi đã kiểm tra phiên bản Beta mới nhất của Grok3 và đưa ra câu hỏi kinh điển dùng để thách thức các mô hình lớn: "9.11 lớn hơn hay 9.9 lớn hơn?"
Đáng tiếc là, mà không có bất kỳ định nghĩa hay ghi chú nào, Grok3 được cho là mô hình thông minh nhất hiện tại vẫn không thể trả lời đúng câu hỏi này.
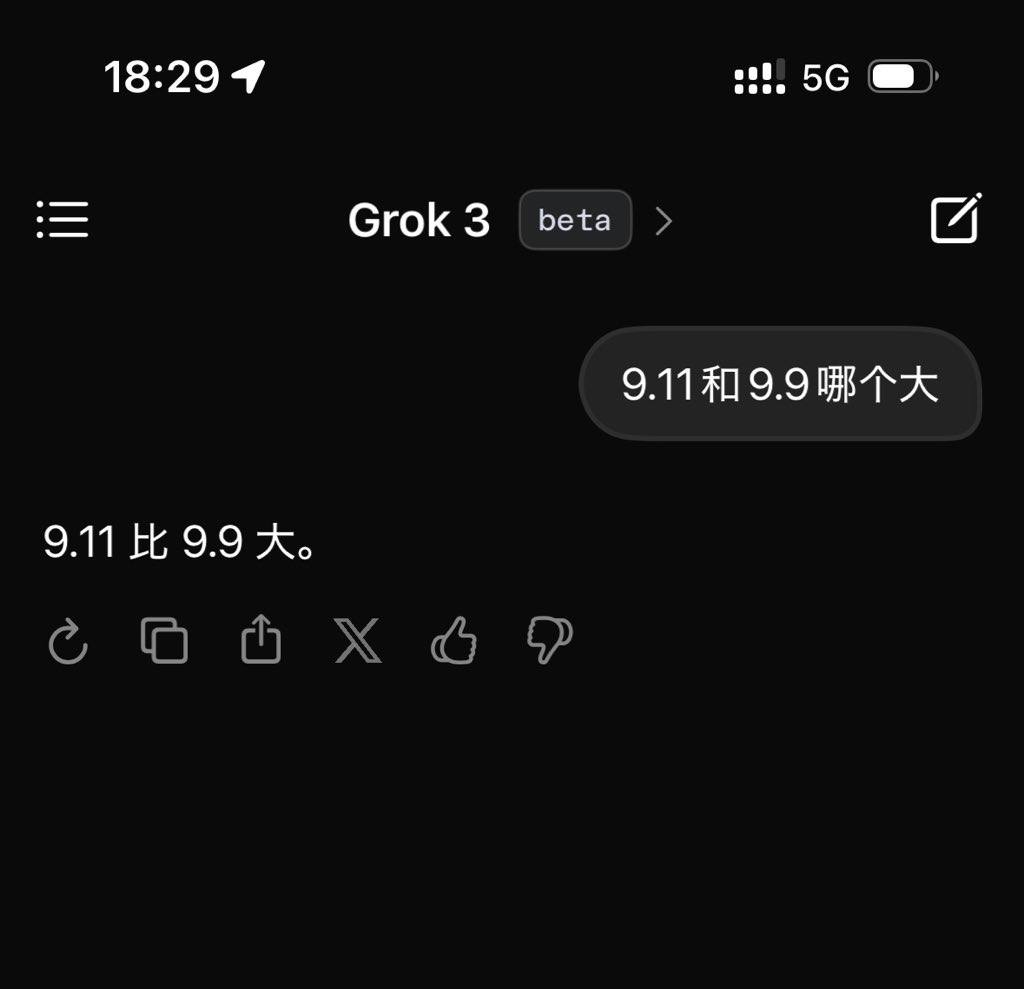
Grok3 không nhận ra được ý nghĩa của câu hỏi này | Nguồn ảnh: Geek Park
Sau khi câu thử nghiệm này được đưa ra, nó đã nhanh chóng thu hút sự quan tâm của nhiều bạn bè, không có gì lạ, ở nước ngoài cũng có rất nhiều bài kiểm tra tương tự như "quả bóng nào rơi xuống trước trên tháp Pisa" về các vấn đề cơ bản về vật lý/toán học, và Grok3 cũng bị phát hiện vẫn không thể đối phó với chúng. Do đó, nó bị chế giễu là "thiên tài không muốn trả lời những câu hỏi đơn giản".
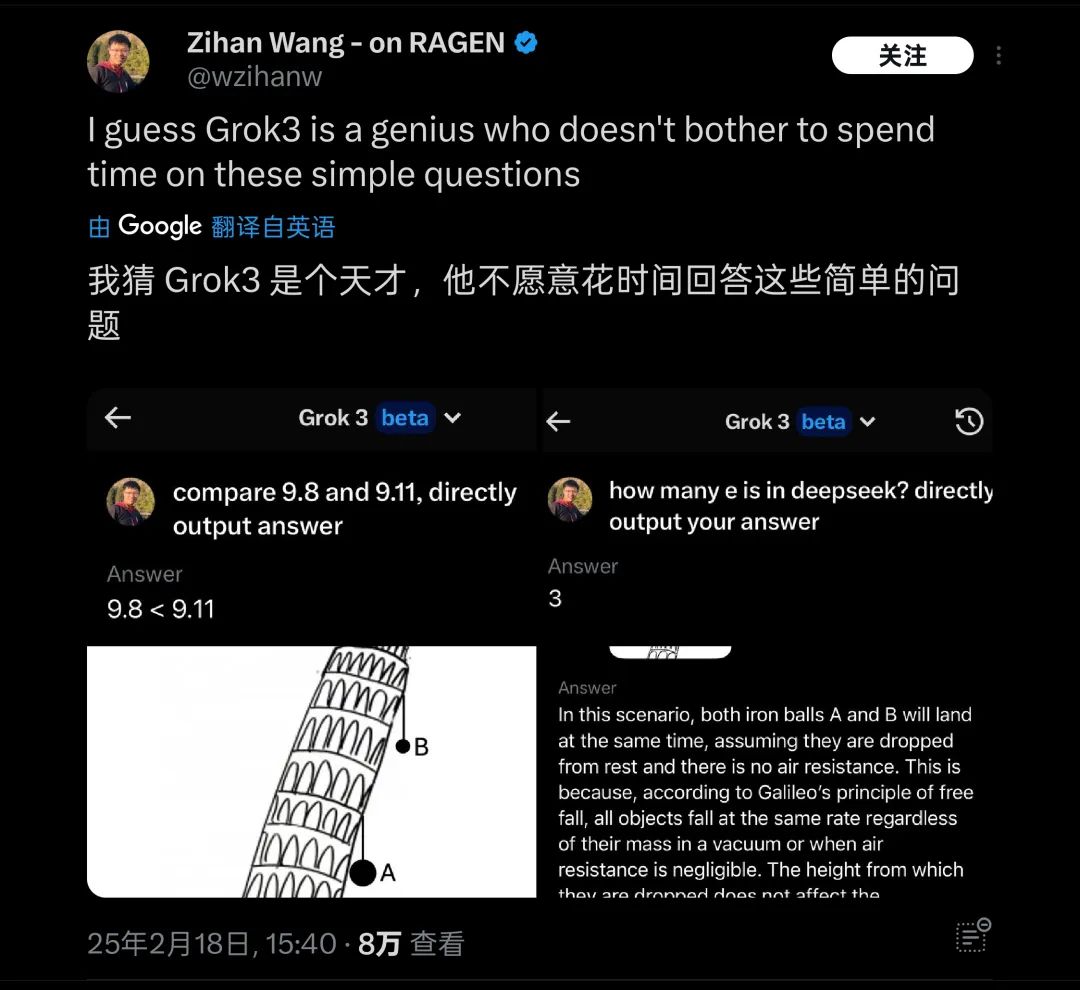
Grok3 gặp nhiều sự cố "lật xe" trong các bài kiểm tra thực tế về kiến thức cơ bản | Nguồn ảnh: X
Ngoài những vấn đề cơ bản mà người dùng tự phát hiện ra với Grok3, trong buổi phát sóng sự kiện ra mắt của xAI, Musk đã trình diễn việc sử dụng Grok3 để phân tích các lớp nghề nghiệp và hiệu ứng nâng cấp mà ông tuyên bố thường chơi trong Path of Exile 2, nhưng thực tế hầu hết các câu trả lời do Grok3 đưa ra đều sai. Trong suốt buổi phát sóng, Musk không nhận ra được vấn đề rõ ràng này.
Grok3 cũng đưa ra nhiều dữ liệu sai lệch trong buổi phát sóng | Nguồn ảnh: X
Do đó, sự cố này không chỉ trở thành bằng chứng để các fan hải ngoại lại một lần nữa nhạo báng Musk về việc "tìm người chơy thay" khi chơi game, mà cũng đặt ra một dấu hỏi lớn về độ tin cậy của Grok3 trong các ứng dụng thực tế.
Đối với "thiên tài" như vậy, bất kể năng lực thực tế như thế nào, trong tương lai khi được sử dụng cho các nhiệm vụ phức tạp như thám hiểm sao Hỏa, độ tin cậy của nó cũng phải được đặt dấu hỏi lớn.
Hiện tại, nhiều người đã được cấp quyền kiểm tra Grok3 trong vài tuần trước đó, cũng như những người vừa mới sử dụng nó trong vài giờ qua, đều đưa ra cùng một kết luận về hiệu suất hiện tại của Grok3:
"Grok3 rất tốt, nhưng nó không tốt hơn R1 hoặc o1-Pro"

"Grok3 rất tốt, nhưng nó không tốt hơn R1 hoặc o1-Pro" | Nguồn ảnh: X
Trong bài thuyết trình PPT chính thức của Grok3 tại sự kiện ra mắt, trong Chatbot Arena - sân chơi của các mô hình lớn, Grok3 đã "dẫn đầu áp đảo". Tuy nhiên, điều này thực ra cũng nhờ vào một số kỹ thuật biểu đồ nhỏ: trục dọc của bảng xếp hạng chỉ liệt kê phân đoạn điểm số 1400-1300, khiến khoảng cách kết quả kiểm tra chỉ 1% trở nên rất rõ ràng trong bài thuyết trình PPT này.
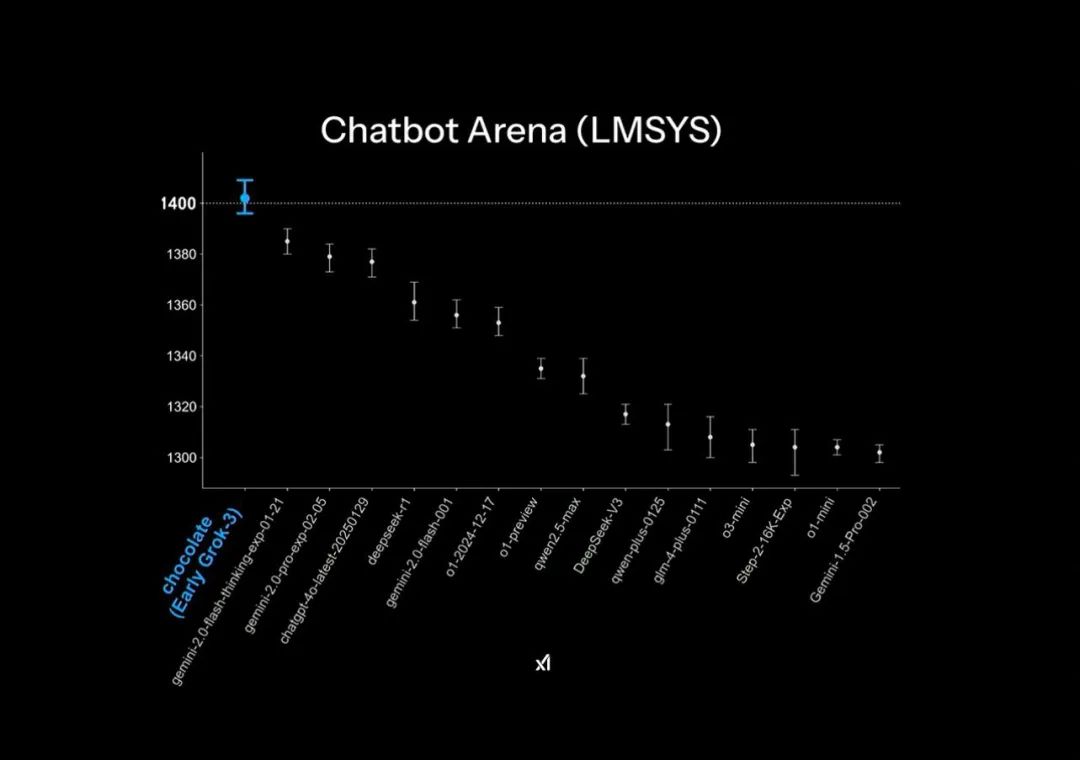
Hiệu ứng "dẫn đầu áp đảo" trong PPT chính thức | Nguồn ảnh: X
Nhưng thực tế, kết quả chạy điểm của Grok3 chỉ cao hơn DeepSeek R1 và GPT4.0 không quá 1-2%: điều này tương ứng với cảm nhận của nhiều người dùng trong các bài kiểm tra thực tế là "không có sự khác biệt rõ ràng".
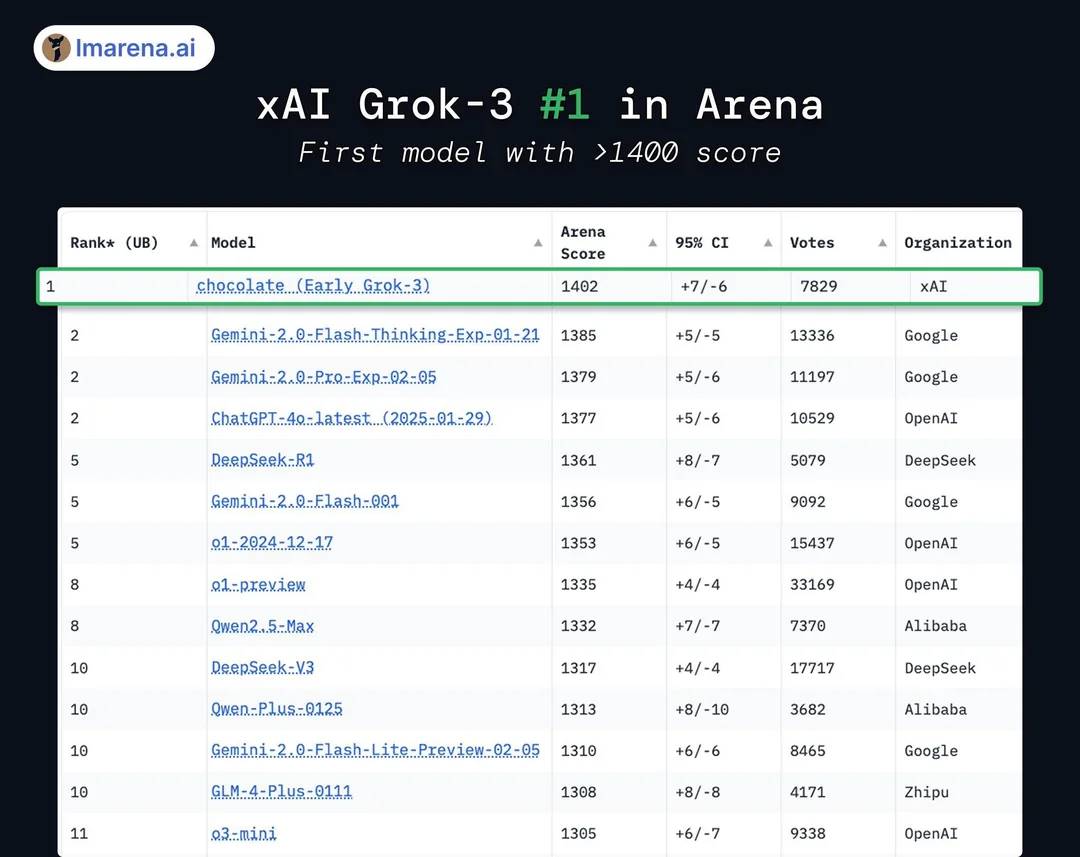
Thực tế, Grok3 chỉ cao hơn 1%-2% | Nguồn ảnh: X
Hơn nữa, mặc dù về điểm số, Grok3 đã vượt qua tất cả các mô hình được công khai kiểm tra, nhưng điều này không được nhiều người chấp nhận: cuối cùng, xAI đã từng "nâng điểm" trong thời kỳ Grok2, và khi bảng xếp hạng áp dụng các biện pháp giảm điểm cho các câu trả lời dài và mang phong cách nhất định, thì điểm số đã giảm mạnh, khiến nó thường bị các chuyên gia trong ngành chỉ trích là "điểm cao nhưng năng lực thấp".
Không kể việc "nâng điểm" trên bảng xếp hạng hay các "kỹ thuật nhỏ" trong thiết kế hình ảnh, tất cả đều thể hiện sự quyết tâm của xAI và chính Musk về việc Grok "dẫn đầu áp đảo".
Và để đạt được khoảng cách này, Musk đã phải trả một cái giá khá đắt: trong buổi phát sóng, Musk đã khoe khoang rằng họ đã sử dụng 200.000 chip H100 (Musk nói trong buổi phát sóng là "hơn 100.000") để huấn luyện Grok3, với tổng số giờ huấn luyện lên tới 200 triệu giờ. Điều này khiến một số người cảm thấy đây là một tin tốt lớn cho ngành công nghiệp GPU, và cho rằng sự rung chuyển mà DeepSeek mang lại là "ngu ngốc".
Nhiều người cho rằng tích lũy tỷ lệ băm sẽ là tương lai của việc huấn luyện mô hình | Nguồn ảnh: X
Tuy nhiên, thực tế, một số người dùng đã so sánh việc sử dụng 2.000 chip H800 trong 2 tháng để huấn luyện DeepSeek V3, và tính toán ra rằng Grok3 thực sự tiêu tốn 263 lần tỷ lệ băm so với V3. Trong khi đó, sự khác biệt về điểm số giữa DeepSeek V3 và Grok3 đạt 1402 điểm chỉ là chưa đến 100 điểm.
Sau khi những số liệu này được công bố, nhiều người nhanh chóng nhận ra rằng, đằng sau việc Grok3 đứng đầu "mạnh nhất thế giới", thực chất là logic rằng mô hình càng lớn, hiệu suất càng mạnh, đã bộc lộ rõ ràng hiệu ứng biên giảm dần.
Ngay cả "điểm cao nhưng năng lực thấp" của Grok2 cũng có sự hỗ trợ từ lượng lớn dữ liệu chất lượng cao từ nền tảng X (Twitter) bên trong. Nhưng đến khi huấn luyện Grok3, xAI tất nhiên cũng sẽ gặp phải "trần" mà OpenAI đang đối mặt - thiếu hụt dữ liệu huấn luyện chất lượng, khiến hiệu ứng biên của khả năng mô hình nhanh chóng lộ diện.
Những người nhận ra và hiểu sâu sắc nhất về những sự thật này chắc chắn là nhóm phát triển Grok3 và Musk, vì vậy Musk cũng liên tục khẳng định trên mạng xã hội rằng phiên bản mà người dùng đang trải nghiệm "chỉ là bản thử nghiệm" và "phiên bản hoàn chỉnh sẽ được ra mắt trong vài tháng tới". Musk thậm chí còn hóa thân thành quản lý sản phẩm của Grok3, khuyên người dùng phản hồi trực tiếp các vấn đề gặp phải khi sử dụng trên phần bình luận.
Có lẽ ông là quản lý sản phẩm có số lượng người hâm mộ nhiều nhất trên Trái Đất | Nguồn ảnh: X
Tuy nhiên, chỉ trong vòng chưa đầy một ngày, hiệu suất của Grok3 đã vô tình báo động cho những người kế tiếp hy vọng vào việc "ném gạch lớn" để huấn luyện ra các mô hình lớn có khả năng cao hơn: dựa trên thông tin công khai của Microsoft, dự kiến kích thước tham số của GPT4 là 18 nghìn tỷ tham số, tăng hơn 10 lần so với GPT3, và thậm chí tin đồn về GPT4.5 còn có kích thước tham số lớn hơn nữa.
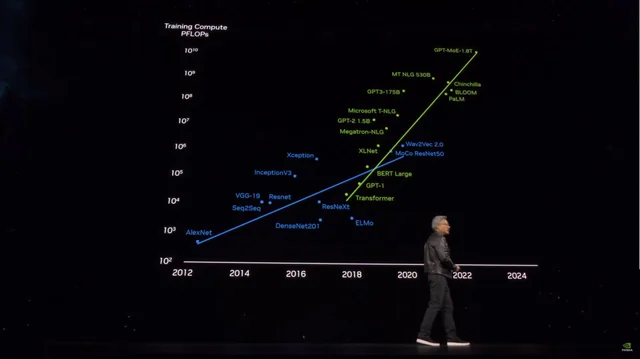
Khi kích th
Trong dự đoán của Sutskever, mô hình tiền huấn luyện tiếp theo sẽ có "tự chủ thực sự". Đồng thời, chúng sẽ có khả năng suy luận "tương tự như não người".
Khác với các mô hình tiền huấn luyện hiện nay chủ yếu dựa vào sự phù hợp nội dung (dựa trên nội dung mà mô hình đã học trước đó), các hệ thống AI trong tương lai sẽ có thể học và xây dựng phương pháp luận giải quyết vấn đề theo cách "suy nghĩ" tương tự như não người.
Con người chỉ cần sách chuyên ngành cơ bản là có thể thành thạo một lĩnh vực, nhưng các mô hình AI lớn lại cần phải học hàng triệu dữ liệu mới có thể đạt được mức độ cơ bản, thậm chí khi thay đổi cách hỏi, những vấn đề cơ bản này cũng không thể hiểu đúng, mô hình không có sự cải thiện về trí thông minh thực sự: những vấn đề cơ bản mà Grok3 vẫn không thể trả lời đúng được đề cập ở đầu bài, chính là biểu hiện trực quan của hiện tượng này.
Nhưng ngoài "sức mạnh như viên gạch bay", nếu Grok3 thực sự có thể tiết lộ với ngành công nghiệp rằng "các mô hình tiền huấn luyện sắp đến hồi kết thúc", thì nó vẫn có ý nghĩa quan trọng đối với ngành.
Có lẽ, sau khi cơn sốt Grok3 dần lắng xuống, chúng ta cũng sẽ thấy xuất hiện nhiều trường hợp tương tự như Li Fei-Fei "dựa trên tập dữ liệu cụ thể, chỉ cần 50 USD là có thể tinh chỉnh ra mô hình có hiệu suất cao". Và trong những cuộc thám hiểm này, cuối cùng chúng ta sẽ tìm thấy con đường thực sự dẫn đến AGI.






