


Tôi đã đi đâu thế?
Trước hết, tôi xin gửi lời cảm ơn đặc biệt đến sam lehman , rodeo , haus , yb , smac , ronan và ibuyrugs vì tất cả các bình luận, chỉnh sửa, phản hồi và gợi ý - các bạn đã giúp biến điều này thành hiện thực và tôi thực sự trân trọng điều đó.
Ngoài ra, một số liên kết arxiv này mở dưới dạng PDF trên trình duyệt, do đó, đây chỉ là lời cảnh báo trong trường hợp bạn không muốn xử lý điều đó.
Khi tôi viết những dòng này đã ba tháng trôi qua kể từ bài đăng cuối cùng của tôi. Tôi đã làm gì kể từ đó?
Tôi không biết. Tôi đã đọc rất nhiều, cố gắng tập thể dục khoảng năm ngày một tuần và nói chung là tận dụng tối đa học kỳ cuối cùng của mình khi học đại học.
Tâm trí tôi trở nên hơi bồn chồn mỗi khi một hoặc hai tháng trôi qua kể từ lần tôi viết một báo cáo dài, vì vậy đây là nỗ lực của tôi để quay lại trạng thái ban đầu và bắt đầu lại mọi việc.
Nếu bạn không hiểu tiêu đề thì đây là báo cáo chủ yếu nói về đào tạo phân tán/phi tập trung , kèm theo một số thông tin về những gì đang diễn ra trong thế giới AI và một số bình luận về cách tất cả những điều này kết hợp với nhau/tại sao tôi tin rằng nó có giá trị .
Bài viết này không mang tính chuyên môn như các báo cáo khác đã viết về chủ đề này và tôi chắc chắn rằng nó cũng không hoàn toàn chính xác.
Tuy nhiên, đây sẽ là báo cáo dễ hiểu nhất về chủ đề này mà bạn có thể tìm thấy.
Hầu như mọi thứ ở đây đều được giải thích ngắn gọn và chi tiết, nếu không thì sẽ có một hoặc hai siêu liên kết cung cấp lời giải thích dài hơn.
Đây là báo cáo về đào tạo phân tán và phi tập trung, nghe có vẻ giống nhau nhưng thực chất đây là hai hình thức đào tạo rất khác nhau .
Khi một phòng thí nghiệm AI bắt đầu đào tạo LLM, họ được giao nhiệm vụ quản lý một số nghĩa vụ góp phần tạo nên một LLM hoàn chỉnh và hoạt động hiệu quả.
Các nhà nghiên cứu và nhà phát triển phải cân bằng giữa việc thu thập/sắp xếp dữ liệu , đào tạo trước/điều chỉnh , đào tạo sau , học tăng cường và cấu hình/triển khai .
Đây không phải là toàn bộ những gì cần có để xây dựng một mô hình nền tảng, nhưng tôi đã chia nhỏ theo cách của riêng mình, hy vọng là dễ hiểu hơn. Tất cả những gì bạn cần biết là LLM tiếp nhận một lượng lớn dữ liệu, các nhóm quyết định về một kiến trúc cụ thể cho mô hình, sau đó là quá trình đào tạo và tinh chỉnh, và cuối cùng là một số quá trình đào tạo và đánh bóng sau khi mô hình được phát hành. À, và hầu hết các LLM đều sử dụng kiến trúc biến áp .
Quá trình này thường được gọi là đào tạo tập trung .
Sam Lehman mô tả đào tạo phân tán là “một quá trình đào tạo thông qua phần cứng không được đặt cùng vị trí vật lý ” trong khi đào tạo phi tập trung “ tương tự như đào tạo phân tán ở chỗ phần cứng được sử dụng để đào tạo trước không được đặt cùng vị trí, nhưng khác ở chỗ phần cứng được sử dụng không đồng nhất và không đáng tin cậy ”.
Sự khác biệt này được tạo ra bởi vì mặc dù hầu hết báo cáo này đề cập đến đào tạo phân tán, nhưng có rất nhiều giá trị có thể tìm thấy trong việc tạo và mở rộng nó bằng các ưu đãi tiền điện tử, hay còn gọi là token . Đó có lẽ là điều mà hầu hết mọi người đọc bài viết này sẽ quan tâm.
Khái niệm trả token cho những người đóng góp cho mạng lưới để đổi lấy công việc này rất nổi tiếng và đã được ghi chép lại.
Ngay cả khi không xem xét các ví dụ phức tạp hơn trong DePIN ( mạng lưới cơ sở hạ tầng vật lý phi tập trung ), bạn vẫn có thể thấy điều này trong mô hình PoW của Bitcoin.
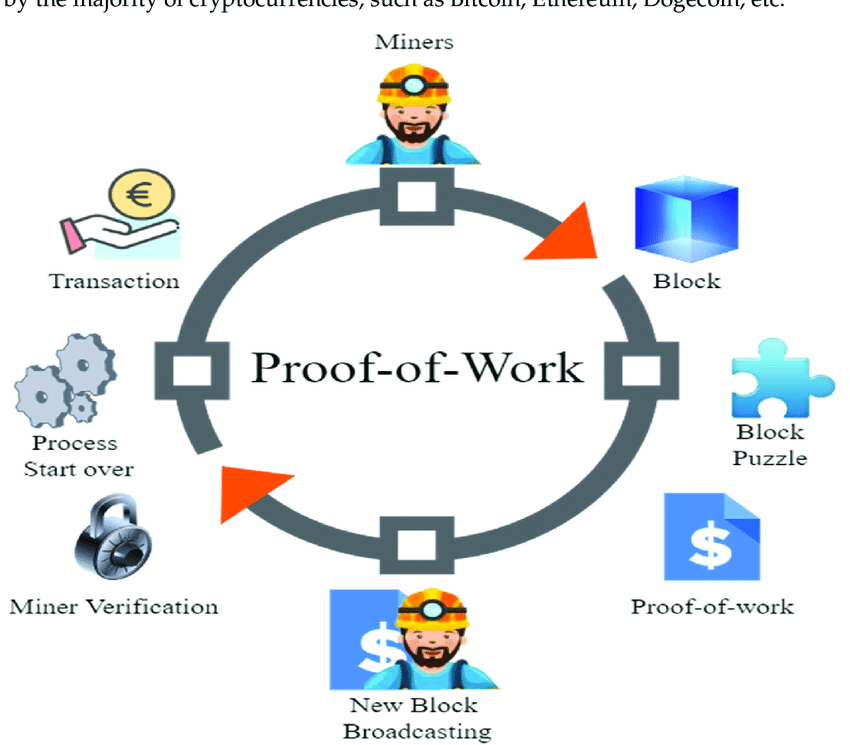
Định nghĩa AI phi tập trung và nêu rõ đề xuất giá trị đào tạo phân tán
Những điểm chính cần lưu ý trong phần này:
Mặc dù cộng đồng tiền điện tử nói chung muốn nói ngược lại, nhưng thực tế là tiền điện tử cần AI nhiều hơn so với AI hiện tại cần tiền điện tử . Ý tôi là gì?
Một số người cho rằng nguyên nhân là do tiền điện tử thu hút ít nhân tài phát triển hơn so với ngành AI truyền thống, dẫn đến các ý tưởng và sản phẩm ít tham vọng và nhìn chung là kém hấp dẫn hơn.
Những người khác có thể nói rằng đó là vì tất cả các token không phải là Bitcoin hoặc Monero đều là phần mềm không có thật, vì vậy DeAI cũng không khác gì. Bạn nghe điều này rất nhiều. Nó thường được sử dụng nhất khi thảo luận về định giá memecoin, nhưng đôi khi nó mở rộng sang các cuộc thảo luận về các lĩnh vực khó khăn hơn như DeFi hoặc DePIN và các ứng dụng tồn tại trong các tập hợp con của tiền điện tử này.
Không phải là bí mật khi cho đến gần đây, vẫn chưa có nhiều đổi mới từ lĩnh vực DeAI và vô số công ty đã huy động vốn đầu tư mạo hiểm dựa trên lời hứa phân cấp AI thông qua một số loại cải tiến mới lạ, hỗ trợ bằng tiền điện tử.
Bản đồ thị trường này từ Galaxy đã quá đông đúc vào quý 1 năm 2024, đang phải vật lộn để kết hợp mọi giao thức. Nếu một bản đồ khác được tạo ra ngày hôm nay, bạn thậm chí không thể chứa được 70% trong số chúng, chứ đừng nói đến việc nhồi nhét tất cả theo cách hấp dẫn về mặt thị giác:
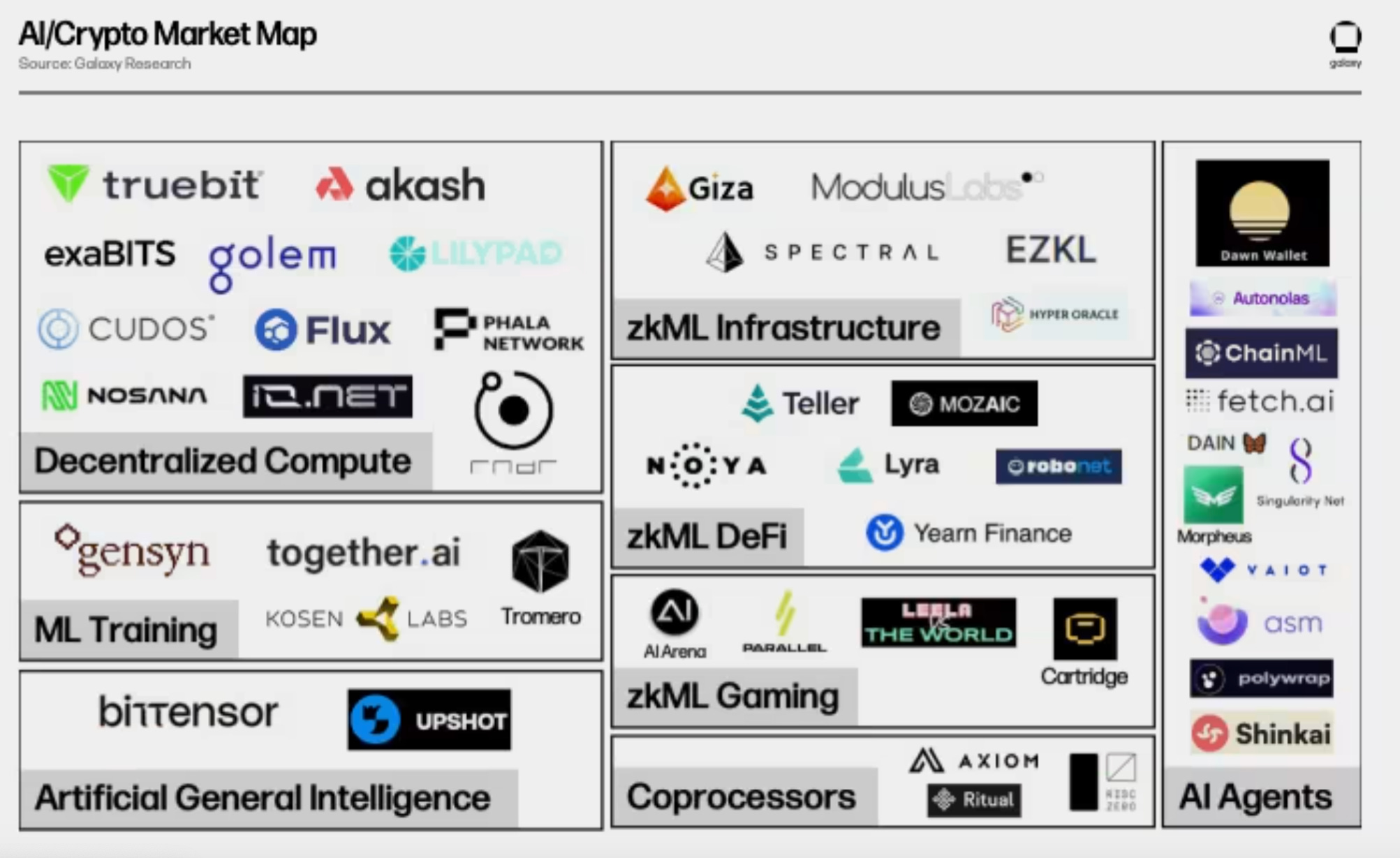
Hầu hết những gì chúng ta thấy từ các nhóm này có thể được xem như một dạng chuẩn bị cho tương lai - tương lai mà AI tương tác với blockchain, một thế giới mà chúng ta đột nhiên sẽ cần tất cả công nghệ hỗ trợ tiền điện tử liên quan đến AI này.
Nhưng còn hiện tại thì sao?
Khi tôi nói rằng không có nhiều đổi mới, tôi chủ yếu muốn nói rằng không có bất kỳ thứ gì được phát hành có tác động đến việc áp dụng DeAI hoặc ngành công nghiệp AI không phải tiền điện tử. Điều này ổn, và mục đích không phải là để nhấn chìm các dự án này vì có khả năng một số ít cuối cùng sẽ được áp dụng.
Ý tôi là với tư cách là một ngành, DeAI đang ngồi im chờ đợi thay vì hành động .
Các giao thức này dựa trên thực tế là AI được tích hợp vào mọi khía cạnh của công nghệ và kinh doanh - không phải là một lựa chọn tồi, chỉ cần xem một trong hàng trăm bài đăng trên blog về AI doanh nghiệp của a16z - nhưng lại gặp khó khăn trong việc giải thích lý do tại sao họ huy động được tiền và/hoặc (chủ yếu là) tại sao họ có liên quan đến ngành DeAI ngày nay.
Tôi tin rằng DeAI vẫn chưa có bất kỳ dấu hiệu "cất cánh" nào vì a) phần lớn dân số toàn cầu vẫn chưa sử dụng blockchain, b) một số vấn đề đang được giải quyết trong DeAI vẫn chưa hoàn toàn cần thiết tại thời điểm này và c) rất nhiều ý tưởng được đề xuất là không khả thi .
Hơn hết, tôi tin rằng DeAI không thu hút được nhiều sự chú ý từ bên ngoài vì rất khó để khiến mọi người quan tâm đến bất kỳ thứ gì khác liên quan đến tiền điện tử ngoài memecoin và stablecoin .
Đây không phải là lời chê bai ngành công nghiệp, chỉ là một nhận xét. Và điều này khá rõ ràng. Ngay cả một công ty được tôn trọng (tin tưởng?) trên toàn thế giới như Circle cũng đang phải vật lộn để duy trì sức nặng của một đề xuất rằng công ty này có thể IPO với mức định giá 5 tỷ đô la.
Nhưng theo tôi, quan điểm thứ ba (rằng những ý tưởng được đề xuất là không khả thi) đã gây ra thiệt hại lớn nhất cho DeAI trong thời gian tồn tại ngắn ngủi của nó.
Đây chỉ là một ví dụ khá rõ ràng đối với hầu hết các nhà nghiên cứu DeAI hoặc những người hoài nghi nói chung, nhưng nếu bạn đang cố gắng tạo ra các tác nhân hoàn toàn tự động, hoàn toàn trên chuỗi tương tác mà không cần trung gian là con người, thì thực sự không có hệ quả tập trung nào để đánh giá tiến trình của bạn.
Trên thực tế, thậm chí không có một tác nhân hoàn toàn tự động nào có thể tương tác liên tục mà không cần trung gian con người bên ngoài bối cảnh của blockchain. Giống như cố gắng xây dựng một ngôi nhà trên sao Hỏa trước khi chúng ta đưa bất kỳ con người nào lên đó.
Các tác nhân hoàn toàn tự động vẫn chưa được phát hành hoặc thậm chí được giới thiệu quá mức từ các phòng thí nghiệm AI lớn, nhưng chúng tôi đã thấy các đồng tiền như ai16z và virtuals đạt mức định giá cao nhất lần lượt là hơn 2,6 tỷ đô la và 4,6 tỷ đô la .
Có một số khuôn khổ tác nhân cũng bị thúc đẩy bởi các dự án này, nhưng rất ít kết quả đạt được (theo tôi). Tôi không cố tỏ ra quá tiêu cực - vì việc giao dịch những đồng tiền này trong một thời gian thực sự rất thú vị - nhưng không có điều gì trong số này thực sự đóng góp gì cho ngành công nghiệp AI không phải tiền điện tử.
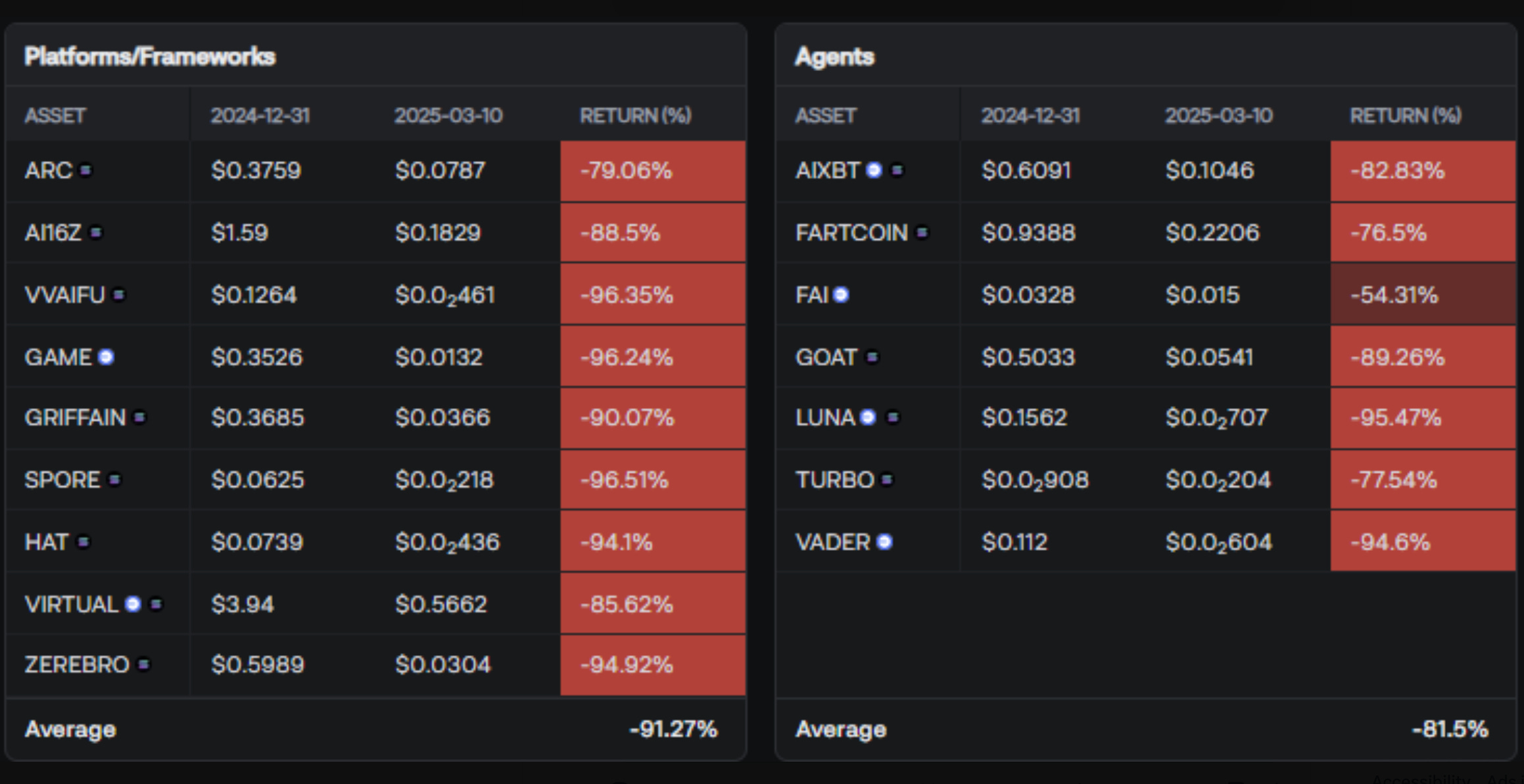
Các khuôn khổ do các nhóm web3 này đề xuất vẫn chưa được Anthropic hoặc OpenAI, hoặc thậm chí là cộng đồng nguồn mở rộng lớn hơn, chấp nhận.
Tệ hơn cả việc không thu hút được sự chú ý là sự thật xấu xí tiềm ẩn rằng tất cả những trò hề này chỉ khẳng định lại niềm tin chung của web2/TradFi/big tech rằng tiền điện tử vẫn là một không gian cơ bản không nghiêm túc.
Có thể các khuôn khổ này không tệ, và hoạt động tiếp thị chỉ kém vì các dự án này đã tung ra các token - điều này có thể được coi là tiêu cực đối với những người ngoài ngành - nhưng thật khó để tin rằng một thứ được cho là sáng tạo như vậy lại không được áp dụng chỉ vì các nhóm sáng lập quyết định tung ra một token.
“ Mọi người đại diện mà tôi biết đều biết tôi ghét họ .” - Ye , nghệ sĩ trước đây được biết đến với nghệ danh Kanye West
Từ một số tìm hiểu cơ bản và tương tác chung trực tuyến, những thứ như MCP ( giao thức ngữ cảnh mô hình ) đã chứng kiến tỷ lệ áp dụng lớn hơn vô hạn so với các khuôn khổ này, thậm chí một số người còn tuyên bố MCP đã giành chiến thắng. Tại sao vậy? Vâng, nó hoạt động, (hầu hết) miễn phí và mọi người thích phần mềm mà họ có thể kết hợp vào cuộc sống hàng ngày của mình, với các ứng dụng mà họ đã sử dụng.

Mọi người nhận được gì từ các khuôn khổ tác nhân? Thường thì , theo nghĩa đen, chỉ có khả năng "xây dựng" hoặc triển khai nhiều tác nhân hơn , với mô tả này đã là một sự cường điệu trong 99% các trường hợp của web3. Hầu hết mọi người không muốn mua tiền của chúng tôi, vậy bạn nghĩ họ sẽ nhận được giá trị gì khi triển khai các tác nhân không liên quan gì đến quy trình làm việc và liên quan đến việc khởi chạy các mã thông báo mới?
* Lưu ý: Không có ý chê @diego_defai, chỉ là chủ đề của bạn là dễ tìm nhất và xuất hiện đầu tiên thôi. *
Nhưng AI phi tập trung là gì và tại sao chúng ta lại được cho là cần nó?
Lucas Tcheyan đã viết vào năm 2024 : “ Động lực thúc đẩy quá trình thử nghiệm đang diễn ra và việc áp dụng cuối cùng tại giao điểm giữa tiền điện tử và AI cũng chính là động lực thúc đẩy nhiều trường hợp sử dụng đầy hứa hẹn nhất của tiền điện tử - quyền truy cập vào lớp phối hợp không cần cấp phép và không cần tin cậy giúp tạo điều kiện tốt hơn cho việc chuyển giao giá trị . ”
Sam Lehman đã viết một phần trong báo cáo của mình về các ưu đãi được hỗ trợ bởi tiền điện tử, chỉ ra rằng “ tiền điện tử đã chứng minh rằng các mạng lưới phi tập trung có thể đạt được quy mô lớn thông qua việc cung cấp các ưu đãi được thiết kế chu đáo”. Ý tôi là, hãy nhìn vào Bitcoin.
Ngay cả khi chúng ta có thể thành thật với nhau và thừa nhận rằng mô hình Bitcoin ít nhất là có phần kỳ lạ trên lý thuyết , điều này không làm giảm đi thực tế là các động cơ mới (nhận BTC để đổi lấy công việc) đã thay đổi thế giới và đưa chúng ta đến mốc thời gian mà chính phủ Hoa Kỳ đang tích cực khám phá một quỹ chiến lược dành cho BTC.
Tư duy này cũng là niềm tin chỉ đạo hoặc phương thức hoạt động (nếu tôi được phép diễn đạt theo cách hoa mỹ) đằng sau cơ sở hạ tầng vật lý phi tập trung (hay gọi tắt là DePIN) mà 0xsmac và tôi đã viết vào tháng 9 năm 2024.
Chúng ta có một vài định nghĩa khác nhau về AI phi tập trung là gì, nhưng không có định nghĩa nào là chắc chắn. Điều này dễ hiểu vì đây là một lĩnh vực mới mẻ trong một ngành công nghiệp đã khá mới mẻ, nhưng ít nhất chúng ta cũng có thể xác định được 5 chữ W của DeAI - ai , cái gì , khi nào , ở đâu và tại sao .
Ai sẽ sử dụng sản phẩm này? Những vấn đề nào được giải quyết tốt hơn khi tích hợp tiền điện tử? Khi nào sản phẩm này sẽ được sử dụng? Một sản phẩm như thế này sẽ thu hút được nhiều sự chú ý nhất hoặc lượng người dùng lớn nhất ở đâu ? Tại sao sản phẩm này cần vốn đầu tư mạo hiểm (jk) và/hoặc tại sao sản phẩm này cần phải tồn tại?
Theo tôi, Vincent Weisser của Prime Intellect đã trình bày những thách thức và vấn đề một cách ngắn gọn để hầu hết mọi người đều có thể hiểu được:

Vincent cũng cung cấp danh sách các trường hợp sử dụng tiềm năng cho DeAI và những gì có thể/nên được xây dựng. Tôi sẽ không nói dài dòng về tất cả chúng, nhưng nó bao gồm hầu hết mọi lớp của ngăn xếp và tóm tắt lĩnh vực này theo cách chưa từng được thực hiện.
Mạng tính toán phân tán (hoặc P2P), phương pháp đào tạo phi tập trung/liên bang, suy luận phi tập trung , tác nhân trên chuỗi, nguồn gốc dữ liệu, khả năng xác minh trên chuỗi và một số phương pháp khác.
DeAI không chỉ là công cụ tính toán đào tạo mô hình, dữ liệu được thu thập được các phòng thí nghiệm lớn mua lại hoặc dịch vụ xác minh đầu ra của mô hình là chính xác. Đó là toàn bộ hệ sinh thái đổi mới sản phẩm được xây dựng để phá vỡ một ngành công nghiệp gần như hoàn toàn phù hợp với phi tập trung.
Có vẻ như hầu hết những người trong ngành đều bị thu hút bởi thách thức phân quyền AI vì họ thích sự phân quyền, nhưng hơn thế nữa, đây là vấn đề cấp bách đối với nhiều người.
Nếu AGI hoặc ASI nằm trong tay một thực thể duy nhất thì điều đó thực sự không công bằng.
Thật tệ hại.
Không ai trong chúng ta có thể tận dụng tối đa những người ngoài hành tinh siêu thông minh, kỹ thuật số này, vì các tập đoàn sẽ sở hữu trọng số mô hình , mã , phương pháp đào tạo riêng và công nghệ được sử dụng để tạo ra các mô hình này.
Giả sử một ai đó như OpenAI hoặc Deepseek xử lý nó trước, nó thực sự cũng trở thành mối đe dọa lớn đối với an ninh quốc gia, nếu nó chưa xảy ra .
Nếu đào tạo phân tán có hiệu quả ở quy mô lớn ( điều mà chúng ta đã thấy ) và tích hợp với các công nghệ DeAI khác như bằng chứng không kiến thức hoặc các cơ chế bảo vệ quyền riêng tư khác, có lẽ chúng ta sẽ có cơ hội tốt để chống lại tình trạng độc quyền về siêu trí tuệ.
Trong một thế giới mà các nhà nghiên cứu đào tạo phân tán tiếp tục hiểu một bộ luật mở rộng hoàn toàn mới và sau đó mở rộng quy mô các hoạt động đào tạo phân tán, chúng ta khó có thể quay lại và tối ưu hóa cho các phương pháp đào tạo cục bộ hơn trong quá khứ.

Nếu bạn là một phòng thí nghiệm lớn hoặc tập đoàn công nghệ lớn như Google / Meta / Amazon, thì việc nghiên cứu đào tạo phân tán và biến nó thành ưu tiên hàng đầu là vì lợi ích của bạn . Dylan Patel đã nói về điều này vào năm 2024 , nhưng nếu bạn vẫn muốn xác nhận thêm rằng điều này đang được các công ty công nghệ lớn và các công ty lớn tích cực khám phá, hãy xem xét bài báo DiLoCo được viết bởi DeepMind ( được Google mua lại với giá 650 triệu đô la vào năm 2014 ). Cũng đáng đề cập đến việc Dylan Patel đã viết về đào tạo đa trung tâm dữ liệu tại đây .
Rodeo đã chỉ ra cho tôi một điều mà khi nhìn lại tôi thấy khá rõ ràng - những bộ óc thông minh nhất và các công ty công nghệ lớn nhất thế giới đang tích cực theo đuổi cách tạo ra một mạng lưới các nút khổng lồ thông qua các nguyên tắc phi tập trung .
Bạn có thấy điều này quen thuộc không?

Thế còn việc giảm bớt rào cản khi tập luyện tại nhà bằng phần cứng tiêu dùng thì sao?
Vấn đề này sẽ được đề cập sau trong một số phân tích ngắn về công trình của Exo Labs , nhưng đây là một dòng tweet gần đây của Alex Cheema mô tả chính xác khái niệm này liên quan đến M3 Ultra của Apple và các mẫu Llama mới của Meta.

Đào tạo phân tán không chỉ mở khóa đào tạo hiệu quả hơn mà còn mở ra toàn bộ cộng đồng các nhà nghiên cứu, người đam mê và người yêu thích toàn cầu trước đây bị loại khỏi việc làm việc trên các mô hình biên giới. Điều gì sẽ xảy ra khi một vài chục cá nhân với hàng trăm thậm chí hàng nghìn GPU được trao tấm vé vàng để cạnh tranh với các phòng thí nghiệm biên giới tập trung?
Tổng quan về một số điều cơ bản về AI, tính toán và quy luật mở rộng
Những điểm chính cần lưu ý trong phần này:
Đào tạo AI hiện đại dựa vào GPU để xử lý song song dữ liệu, khiến chúng trở thành nút thắt cổ chai của ngành và đồng thời là một mặt hàng rất hot
Việc tăng cường tính toán và dữ liệu thường dẫn đến hiệu suất cao hơn nhưng việc mở rộng quy mô cụm tính toán lại đặt ra những thách thức riêng
Tiến trình của DeepSeek đã cho thấy sự sáng tạo trong việc tạo mô hình (không chỉ là nhiều GPU hơn) và chứng minh rằng bạn có thể đạt được kết quả tiên tiến với chi phí thấp hơn chỉ bằng một chút tư duy đột phá
Đào tạo tập trung rất tốn kém và khó khăn; đào tạo phân tán cũng vậy, nhưng có nhiều tác động tích cực hơn nếu được thực hiện đúng cách.
Tốt nhất là nên bắt đầu bằng cách ôn lại những gì đã diễn ra trong ngành AI và sử dụng thông tin này làm điểm khởi đầu cho các chủ đề phức tạp hơn ở phần sau.
Hy vọng rằng hầu hết những người đọc bài viết này đều hiểu đôi chút về những gì đang diễn ra với các LLM gần đây ( Sonnet 3.7, GPT 4.5, Grok 3 ), chi phí AI của Magnificent 7 và các mô hình ngày càng có khả năng hơn được phát hành gần như mỗi tuần.
Có một số báo cáo hay mô tả công việc đào tạo LLM, vì vậy tôi sẽ tham khảo một số báo cáo sau:
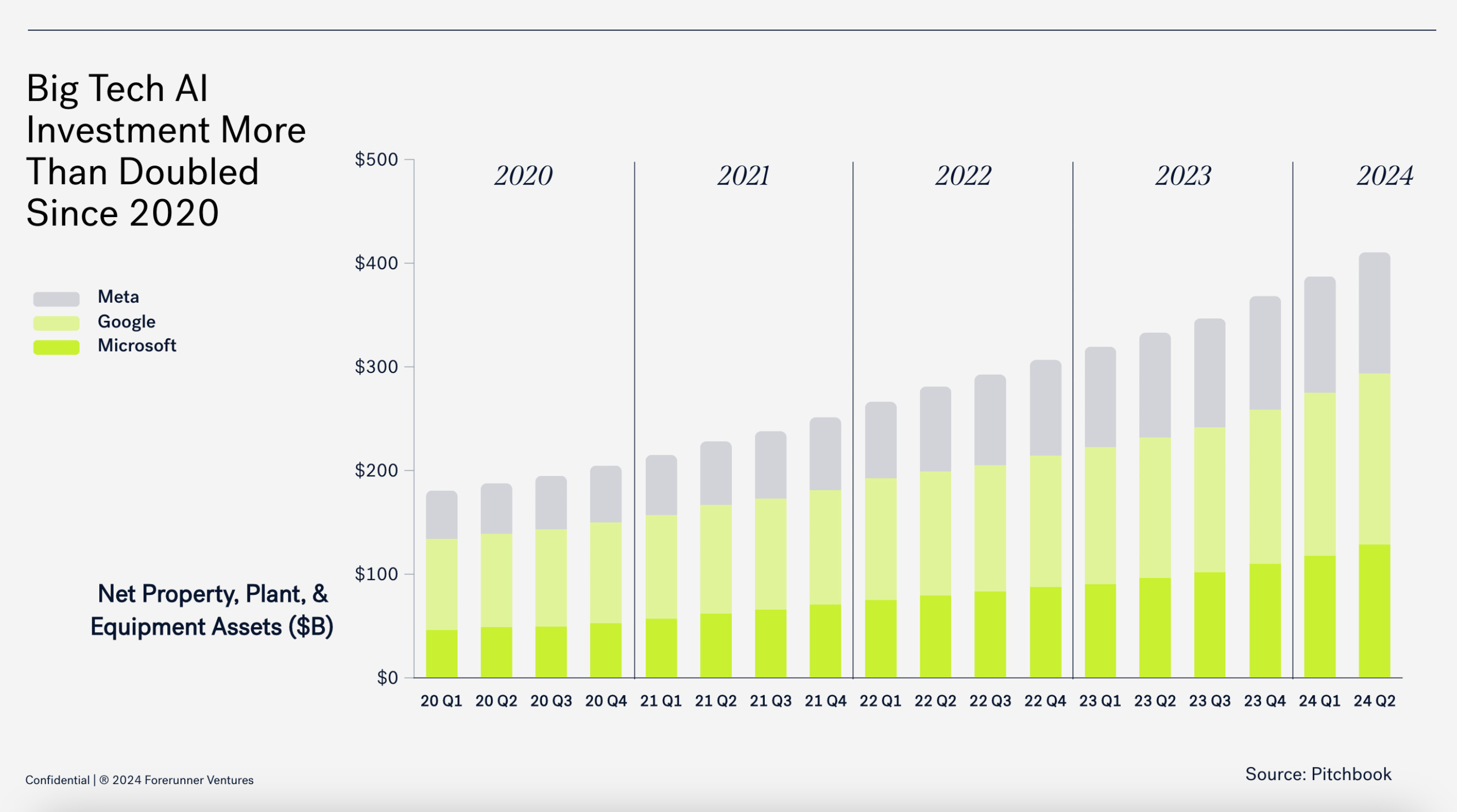
Đào tạo LLM là một dự án đòi hỏi rất nhiều vốn , và bạn có thể thấy bên dưới số tiền mà các công ty công nghệ lớn đã chi cho cơ sở hạ tầng. Chi tiết sẽ được đề cập ngay sau đây, nhưng hầu hết (nếu không muốn nói là tất cả) số tiền này dành cho những thứ như GPU, xây dựng trung tâm dữ liệu, bảo trì và các yêu cầu phần cứng khác góp phần tạo nên sản phẩm cuối cùng.
Nhân tiện, danh sách này chỉ giới hạn ở ba tập đoàn công nghệ lớn:
Bạn có thể tự hỏi tại sao người ta lại sử dụng GPU thay vì CPU, hoặc sự khác biệt giữa hai loại này là gì.
Citrini nhấn mạnh rằng sự khác biệt giữa GPU và CPU xuất phát từ loại song song nào được sử dụng để tính toán. GPU được tối ưu hóa cho thứ gọi là song song dữ liệu trong khi CPU tốt hơn ở song song tác vụ.
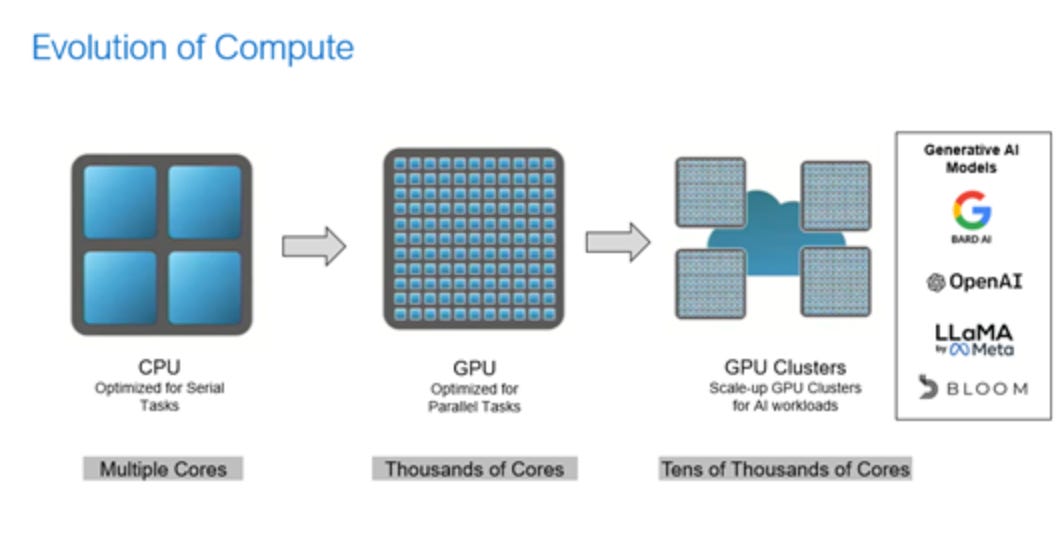
Ngành công nghiệp máy học nhận ra rằng GPU - ban đầu được thiết kế để dựng hình đồ họa - cũng khá tốt trong việc thực hiện các phép tính nhanh chóng. Tôi sẽ không đi sâu vào tốc độ của mọi thứ, nhưng chúng rất nhanh.
Song song dữ liệu là một quá trình trong đó “ cùng một hoạt động được thực hiện trên nhiều phần tử dữ liệu song song ” trong khi song song tác vụ là khi “ các hoạt động khác nhau được thực hiện trên cùng một dữ liệu hoặc dữ liệu khác nhau ”.
Đối với việc đào tạo LLM, tính song song dữ liệu có ý nghĩa hơn do bản chất lặp đi lặp lại cao của việc phân tích các tập dữ liệu lớn và thực hiện các thao tác đơn giản trên đó, đó là lý do tại sao GPU đã và đang là một mặt hàng hot như vậy.
Một thứ gì đó giống như tính song song của tác vụ không có ý nghĩa gì vì các tập dữ liệu AI có tính biến đổi cao - bạn sẽ không muốn lập chỉ mục quá mức cho một phần dữ liệu duy nhất trong một tập dữ liệu lớn vì bạn sẽ không bao giờ hoàn thành việc đào tạo một mô hình hoặc sẽ mất quá nhiều thời gian dẫn đến tốn kém và/hoặc không hiệu quả.
Mọi người thích nói từ tính toán, và họ đang ám chỉ đến GPU khi họ làm điều này. Nếu ai đó hỏi " Meta có bao nhiêu tính toán " hoặc " Elon sẽ chi bao nhiêu cho tính toán vào năm tới " thì họ đang nói về GPU.
Quỹ Carnegie đã viết một bản tóm tắt hay về ý nghĩa của máy tính, cách thức hoạt động và lý do tại sao nó lại quan trọng đến vậy. Sẽ hữu ích nếu bạn vẫn còn hơi bối rối và muốn có cái nhìn tổng quan hơn trước khi đọc phần còn lại.
Tính toán là trọng tâm chính của các phòng thí nghiệm AI vì có một thứ gọi là quy luật tỷ lệ , đặc biệt là mối quan hệ lũy thừa hay mối tương quan giữa các mô hình hiệu suất cao hơn với số lượng GPU và dữ liệu lớn hơn dùng để đào tạo chúng.
Nói một cách chính xác, luật cụ thể được tham chiếu ở đây được gọi là luật mở rộng trước khi đào tạo . Đồ họa bên dưới đi xa hơn một chút, nhưng tôi thấy nó hữu ích cho việc đóng khung vị trí chúng ta đang ở trong quá trình phát triển mô hình ngày nay và hướng đi của chúng ta:
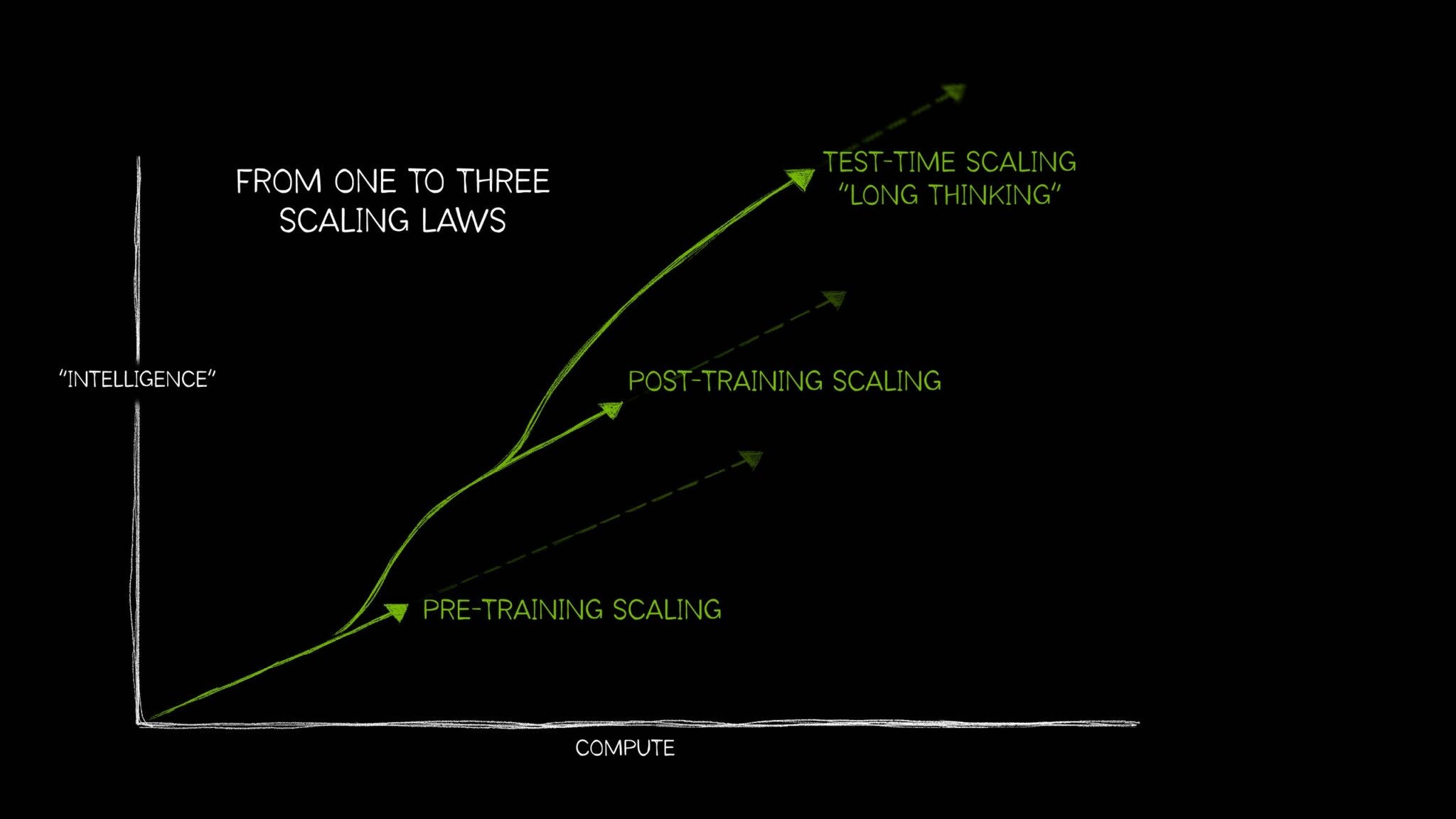
Nói ngắn gọn, bài báo năm 2020 của OpenAI về luật mở rộng quy mô được cho là một trong những phân tích cơ bản nhất về mối quan hệ giữa tính toán, dữ liệu và số lượng tham số mô hình.
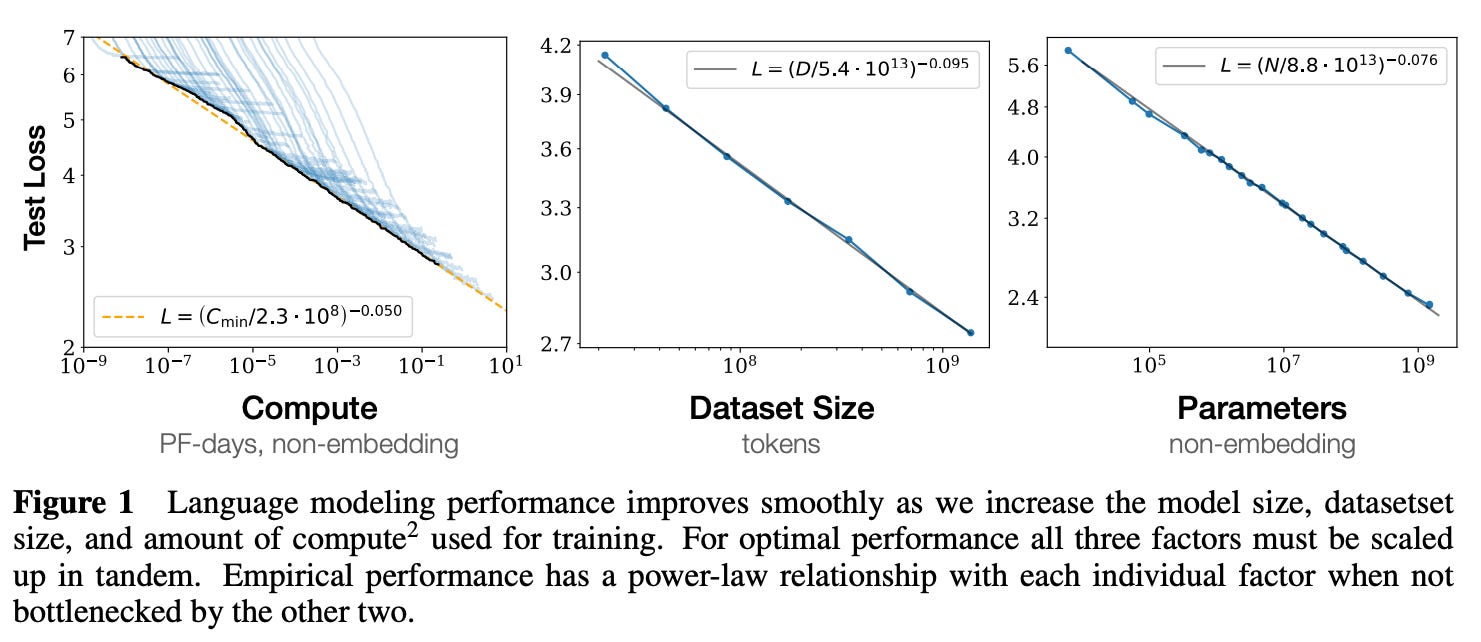
Luật về tỷ lệ vẫn được duy trì.
Thật khó để tìm ra số lượng GPU chính xác cho các mô hình mới hơn, nhưng sau đây là ước tính sơ bộ về các quy luật mở rộng đang được áp dụng cho một số mô hình của OpenAI trong những năm qua:
GPT-1 : 117m params & khoảng 8 Nvidia V100
GPT-2 : 1,5b params & hàng chục đến vài trăm Nvidia V100
GPT-3 : 175b params & 1k-2k+ Nvidia V100
GPT-4 : Hàng nghìn tỷ tham số & 8k-30k Nvidia A100s/H100s
Bạn có thể nhớ Sam Altman đã kêu gọi hàng nghìn tỷ đô la để xây dựng các trung tâm dữ liệu ngày càng lớn hơn, hoặc dự luật Stargate trị giá 500 tỷ đô la được đề xuất, hoặc thậm chí là tham vọng về trung tâm dữ liệu 2GW+ của Zuck - đây là những sáng kiến ra đời do nhu cầu (được cho là) về các trung tâm dữ liệu cực lớn và tiêu thụ nhiều điện năng.
Trên thực tế, vào ngày 31 tháng 3, OpenAI đã công bố đã hoàn thành một vòng gọi vốn mới, nhận được khoản tiền đầu tư 40 tỷ đô la (75% trong số này đến từ Masayoshi Son và SoftBank).
Vì các quy luật về tỷ lệ vẫn tồn tại trong bức tranh trong một thời gian dài, nên bất kỳ ai muốn xây dựng một mô hình tốt đều buộc phải tích lũy lượng tính toán ngày càng lớn hơn , cũng như các loại tính toán hiệu suất cao hơn (hay còn gọi là GPU tốt hơn). Hầu hết trong số này đến từ Nvidia, mặc dù cũng đáng để khám phá tiềm năng của Apple Silicon .
Mọi người đều bị mắc kẹt trong cuộc đua lớn để mua những GPU này và đào tạo các mô hình lớn hơn, nhưng mọi thứ đã trở nên phức tạp. Các mô hình trở nên thông minh hơn khi bạn đào tạo chúng bằng nhiều GPU hơn, nhưng việc đào tạo chúng ngày càng trở nên khó khăn hơn do nhiễu loạn, lỗi, yêu cầu làm mát, kết nối và một loạt các vấn đề khác.
Các phần sau sẽ đề cập đến nhiều chi tiết hơn, nhưng hầu hết các thuật toán đào tạo này đã khá có khả năng và các nút thắt cổ chai tồn tại hầu như hoàn toàn trong giai đoạn triển khai và mở rộng quy mô. Đã có thể đạt được một đợt đào tạo phân tán hoàn toàn, thách thức duy nhất còn lại là đưa nó từ 0,5 → 1.
Đào tạo phân tán thực chất là một bước tiến để giải quyết phần lớn vấn đề này, vốn rất to lớn.
Nếu cuối cùng chúng ta có thể đào tạo các mô hình tiên tiến trên nhiều trung tâm dữ liệu khác nhau, từ nhiều châu lục và quốc gia, mà không phải chịu những gánh nặng này, chúng ta có thể có được những mô hình tốt hơn với ít rắc rối hơn và hiệu suất đào tạo cao hơn nhiều .
Đó là lý do tại sao nó lại quan trọng đến vậy - nó có thể tốt như đào tạo tập trung nếu được chứng minh là có khả năng mở rộng, nhưng tốt hơn về hầu hết mọi mặt khác nếu thành công. Và nếu bạn nghĩ về điều đó, các tập đoàn và phòng thí nghiệm tập trung này phải điều chỉnh hoạt động của họ theo xu hướng đào tạo phân tán, chứ không phải ngược lại.
Nếu bạn đã sở hữu một trung tâm dữ liệu lớn, bạn sẽ khó có thể làm việc ngược lại và thiết kế lại cơ sở hạ tầng để phù hợp với các phương pháp đào tạo phân tán. Nhưng nếu bạn là một nhóm các nhà nghiên cứu nhỏ hơn, ít tham gia hơn, những người đã bắt đầu công việc tiên phong về đào tạo phân tán ngay từ ngày đầu , bạn sẽ có vị thế tốt hơn nhiều để hưởng lợi từ công nghệ này.
Epoch AI đã viết một báo cáo về việc thu hẹp quy mô vào năm 2024, mô tả không chỉ các quy luật thu hẹp quy mô truyền thống (tập trung vào tính toán) mà còn một số điểm nghẽn tiềm ẩn khác có thể gây khó khăn cho các phòng thí nghiệm trong quá trình chạy trước khi đào tạo (sẽ được đề cập).
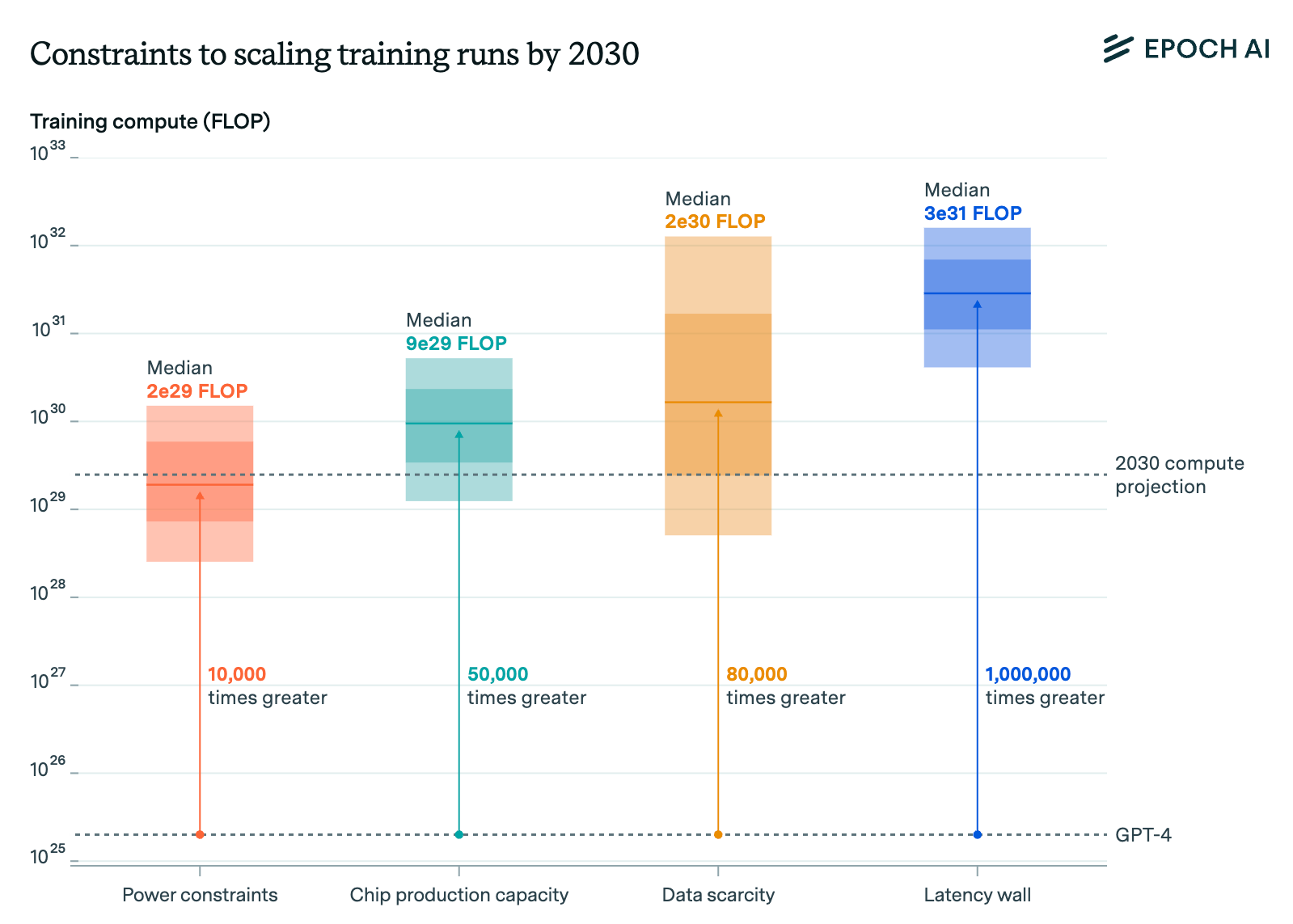
Điều quan trọng nhất cần nhấn mạnh ở đây là số lượng GPU hoặc quy mô của một trung tâm dữ liệu không phải là nút thắt duy nhất. Ngoài việc chỉ mua những GPU này - vốn đã khó - các phòng thí nghiệm cần phải căng thẳng về hạn chế về năng lượng, bức tường độ trễ, năng lực sản xuất chip và thậm chí là căng thẳng địa chính trị.
Và đây chỉ là danh sách dài những mối quan tâm đối với các đợt đào tạo tập trung - đào tạo phân tán cũng có những vấn đề riêng, chủ yếu là khắc phục tình trạng tắc nghẽn giao tiếp và mở rộng quy mô đào tạo.
Nhiều hạn chế khác có liên quan đến đào tạo phân tán vì thực tế hiển nhiên là đào tạo phân tán vốn nhạy cảm với các yếu tố như địa lý, vị trí và - không chắc đây có phải là một từ chính xác không - địa phương.
Đào tạo phân tán không chỉ là nghiên cứu về cách đào tạo các mô hình lưu trú tại nhiều địa điểm, mà là một lĩnh vực bao gồm tất cả các vấn đề khó nhất trong đào tạo tập trung và kết hợp chúng với các lý thuyết thậm chí còn khó hơn và chưa được chứng minh từ nghiên cứu đào tạo phân tán.
Đó là một trong những lý do khiến chủ đề này nổi bật với tôi đến vậy - rủi ro cực kỳ cao và đây là một trong những lĩnh vực mà rất nhiều chuyên ngành chồng chéo lên nhau, gần như không thể có được bức tranh toàn cảnh về những gì đang diễn ra.
Nếu bạn nghĩ về những bước tiến đáng kể trong công nghệ theo thời gian, đào tạo phân tán phù hợp và xứng đáng có cơ hội thành công ngay cả khi hiện tại không có mã thông báo nào để tôi quảng cáo.
Ý tưởng về việc các quy luật mở rộng "kết thúc" hoặc trải qua hiệu suất giảm dần đã gây ra nhiều tranh cãi, và thực ra tôi không có thẩm quyền đưa ra ý kiến vì phần lớn không ai hoàn toàn chắc chắn.
Ngoài các luật mở rộng trước khi đào tạo, còn nhiều điều cần nói về các luật sau khi đào tạo và tính toán thời gian thử nghiệm (TTC). Sau khi đào tạo liên quan đến các chủ đề như tinh chỉnh, học tăng cường và một số cơ chế nâng cao khác được đề cập trong phần tiếp theo.
Ngược lại, TTC phức tạp hơn nhiều.
Nhưng tôi có phải là người viết về những điều này không? Viết báo cáo này thực sự rất mệt mỏi, vì tôi cảm thấy như mình liên tục tiến một bước và lùi ba bước, vật lộn để hiểu thông tin mới hoặc học được điều gì đó. Tôi đã viết toàn bộ một phần và thật đáng buồn là đã nhầm lẫn về tất cả . Tôi đã vật lộn rất nhiều, nhưng vì lý do gì?
Tôi thậm chí còn không kiếm được tiền từ việc viết những bài viết này.
Nói một cách ngắn gọn, các luật sau đào tạo hiện đang được ưa chuộng nhờ tốc độ cải thiện đáng kinh ngạc được đo lường trong các mô hình "o" của OpenAI so với GPT-4 và các mô hình không có lý luận được phát hành trong những năm trước:
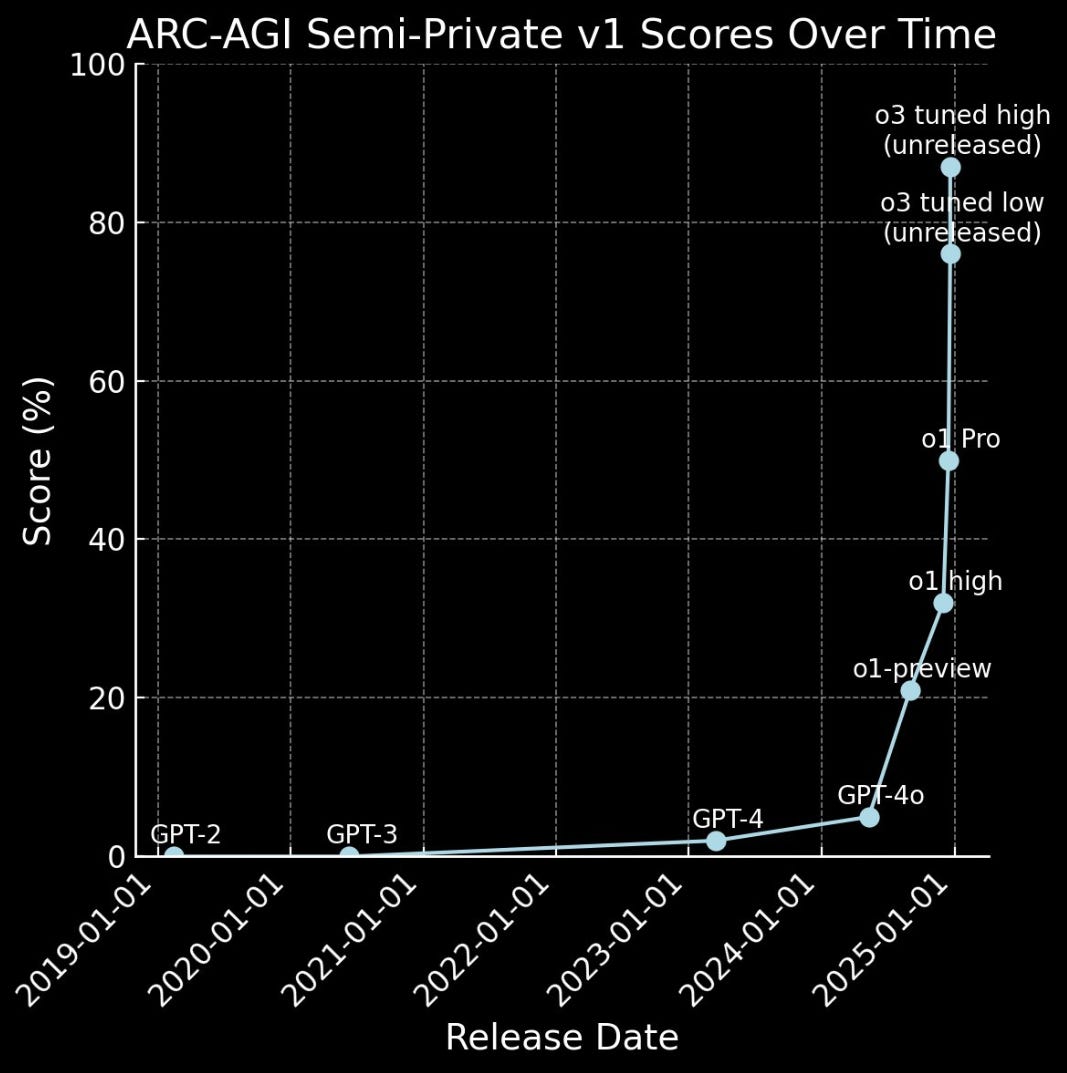
Nghiên cứu sau đào tạo đang rất được quan tâm và phát triển hiện nay vì nó đang hoạt động (dĩ nhiên rồi) và là cách hiệu quả hơn về mặt chi phí để mở rộng hiệu suất mô hình, giả sử bạn là một phòng thí nghiệm lớn đã có GPU. Nói một cách đơn giản, sau đào tạo chủ yếu là bổ sung và có tiềm năng định nghĩa lại cách các phòng thí nghiệm lớn đang hướng tới AGI.
Tôi đã đề cập đến việc học tăng cường kết hợp với các mô hình lý luận chắc chắn đã thách thức nhận thức của ngành về các quy luật mở rộng, nhưng nó không nhất thiết bác bỏ mọi lập luận chống lại các quy luật mở rộng này.
Nếu có bất kỳ tiến bộ nào được thực hiện trong quá trình đào tạo sau đào tạo thì chỉ có lợi cho toàn bộ vòng đời tạo mô hình, vì dữ liệu mới này cuối cùng có thể đưa vào các mô hình tốt hơn. Có thể đến lúc 99% sự đổi mới trong việc tạo và quản lý mô hình đến từ các tối ưu hóa sau đào tạo, nếu điều này chưa được theo đuổi.
Nhưng thế là đủ rồi. Tôi sẽ lùi lại vài bước và chạy qua quy trình đào tạo trước và một số chức năng quan trọng hơn ngoài GPU.
Rõ ràng, tính toán là yếu tố quan trọng trong quá trình đào tạo, nhưng như tôi đã gợi ý trước đó, có một bộ yêu cầu hoàn toàn riêng biệt về lưu trữ , bộ nhớ , năng lượng và mạng cũng quan trọng như GPU.
Năng lượng : Rõ ràng là các trung tâm dữ liệu lớn cần lượng năng lượng lớn, nhưng còn cơ sở hạ tầng làm mát thì sao? Còn việc thực sự cung cấp đủ nhu cầu năng lượng cần thiết và đảm bảo đầu ra điện ổn định thì sao?
Kho : LLM được tạo thành từ các tập dữ liệu và tham số lớn, do đó bạn có thể hình dung được yêu cầu lưu trữ cho chúng là rất cao.
Ký ức : Quá trình chạy trước khi đào tạo có thể mất một thời gian và cần có yêu cầu bộ nhớ phù hợp để duy trì bộ nhớ trên nhiều GPU và nút.
Mạng lưới : Báo cáo kết nối của Citrini cung cấp cho bạn nhiều thông tin hơn bạn cần biết về mạng, nhưng các trung tâm dữ liệu cần kết nối tốc độ cao và độ trễ thấp để thực sự tạo điều kiện thuận lợi cho việc chạy.
Tất cả các mô hình này đều được đào tạo trước với các cụm lớn, được kết nối với nhau, bị giới hạn về mặt địa lý, tiêu thụ nhiều năng lượng, bao gồm các công nghệ đắt tiền và có khả năng cao.
Hàng chục tỷ đô la đã được chi cho việc xây dựng trung tâm dữ liệu, các vòng gây quỹ cho phòng thí nghiệm và vô số khoản chi khác khi các công ty tham gia vào cuộc đua hướng tới siêu trí tuệ.
Nhưng mọi chuyện trở nên phức tạp vào đầu năm nay.
DeepSeek-R1 và bài báo đi kèm đã được phát hành vào ngày 22 tháng 1 năm 2025 và vẫn nằm ngoài tầm ngắm trong khoảng một tuần trước khi mọi người biết đến. Trừ khi bạn đang trong thời gian tạm dừng kỹ thuật số hoặc có trí nhớ ngắn hạn kém, R1 là một cú đánh lớn từ cánh trái đối với hầu hết mọi người trong ngành.
Người ta nói rằng R1 đã được đào tạo với 2.048 GPU Nvidia H800, tương đương với giá trị GPU khoảng 61 triệu đô la, giả sử chi phí là 30.000 đô la/GPU - cộng hoặc trừ 5.000 đô la tùy thuộc vào nơi và thời điểm DeepSeek mua những GPU này. Tuy nhiên, cũng có sự khác biệt trong báo cáo dựa trên nhiều nguồn internet cho thông tin trên và báo cáo từ semianalysis ước tính 10.000 H800 và 10.000 H100.
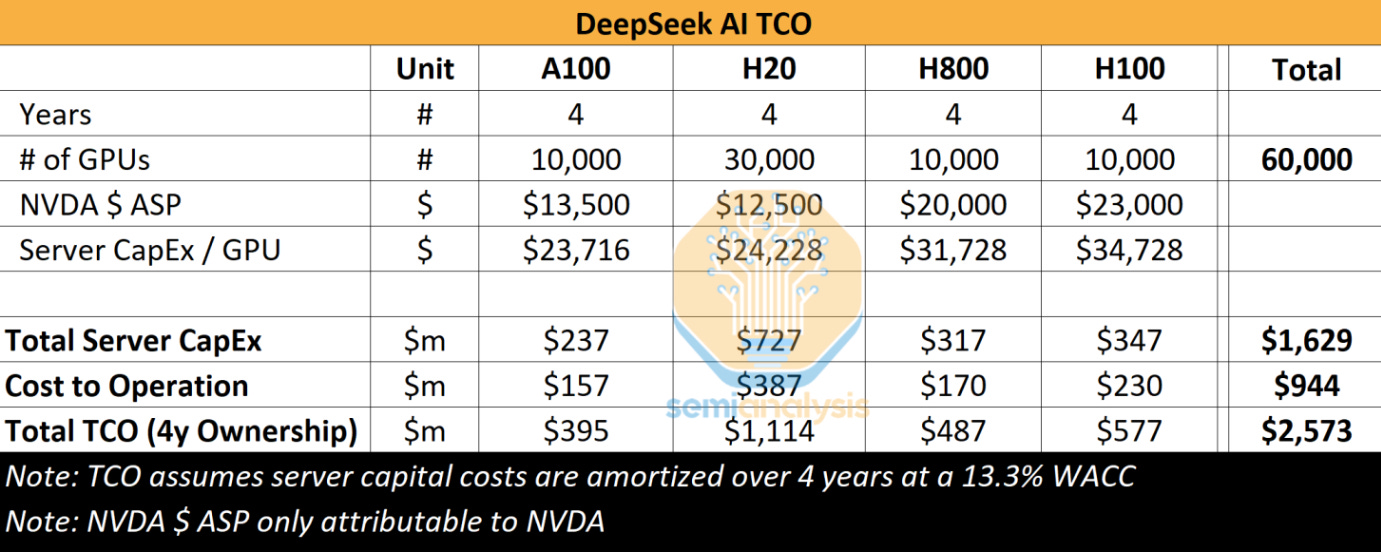
Tôi nghĩ bất kể số lượng GPU thực tế được sử dụng để đào tạo mô hình, những gì DeepSeek có thể đạt được mới là câu chuyện thực sự ở đây. Không phải là cắt giảm chi phí hoặc khả năng né tránh các quy định nhập khẩu GPU, mà là sự sáng tạo trong xây dựng mô hình và những tiến bộ trong học tăng cường.
Tin tức về trò hề GPU của DeepSeek đã gây sốc cho nhiều người, khi xét đến việc mọi phòng thí nghiệm lớn đều ưu tiên tích lũy ngày càng nhiều tính toán trong 2-3 năm qua và hầu như không có dấu hiệu nào cho thấy đây không phải là cách "đúng đắn" để xây dựng các mô hình có khả năng cao. Quy trình và chiến lược của DeepSeek sẽ được trình bày chi tiết hơn trong phần sau.
Sau đây là một số mô hình cơ bản khác và chi phí tương ứng của chúng, không tính đến thời gian đào tạo hoặc những trở ngại khác trong quá trình đào tạo trước:
GPT 4o của OpenAI: 25.000 Nvidia A100 @ $8-20k/GPU
xAI's Grok 2 : 20.000 Nvidia H100 @ $25-30k/GPU
Gemini 2.0 của Google: 100.000 chip Trillium với giá 2,7 đô la/giờ/chip
Meta's Llama 3.1 : 16.000 GPU Nvidia H100
Anthropic's Claude 3.5 Sonnet : không xác định nhưng ước tính hàng chục ngàn
GPT o1 của OpenAI: không xác định nhưng được cho là có rất nhiều GPU
* Lưu ý: Tôi muốn đưa trích dẫn vào đây nhưng có quá nhiều nguồn khác nhau được sử dụng và khi tôi đang chỉnh sửa bài viết này, sẽ tốn quá nhiều năng lượng để quay lại và tìm những nguồn này. Sam Lehman cũng chỉ ra với tôi rằng lương + tiền bồi thường của nhân viên có thể ảnh hưởng đến những chi phí này, vì vậy, điều đó đáng để cân nhắc nếu bạn muốn khám phá chi phí tuyệt đối của các đợt đào tạo. *
Mặc dù chúng ta không có chi phí hoặc số lượng GPU cho một số mô hình cũ ( và đối với nhiều mô hình mới hơn như Claude 3.7 và GPT 4.5, điều này dễ hiểu ), chúng ta có thể cho rằng những mô hình này đã tuân thủ theo quy luật mở rộng của AI và tích lũy được số lượng GPU ngày càng lớn hoặc GPU hiệu suất cao hơn.
Đây là một điểm tốt để đề cập rằng không phải tất cả các buổi chạy trước khi luyện tập đều được tạo ra như nhau.
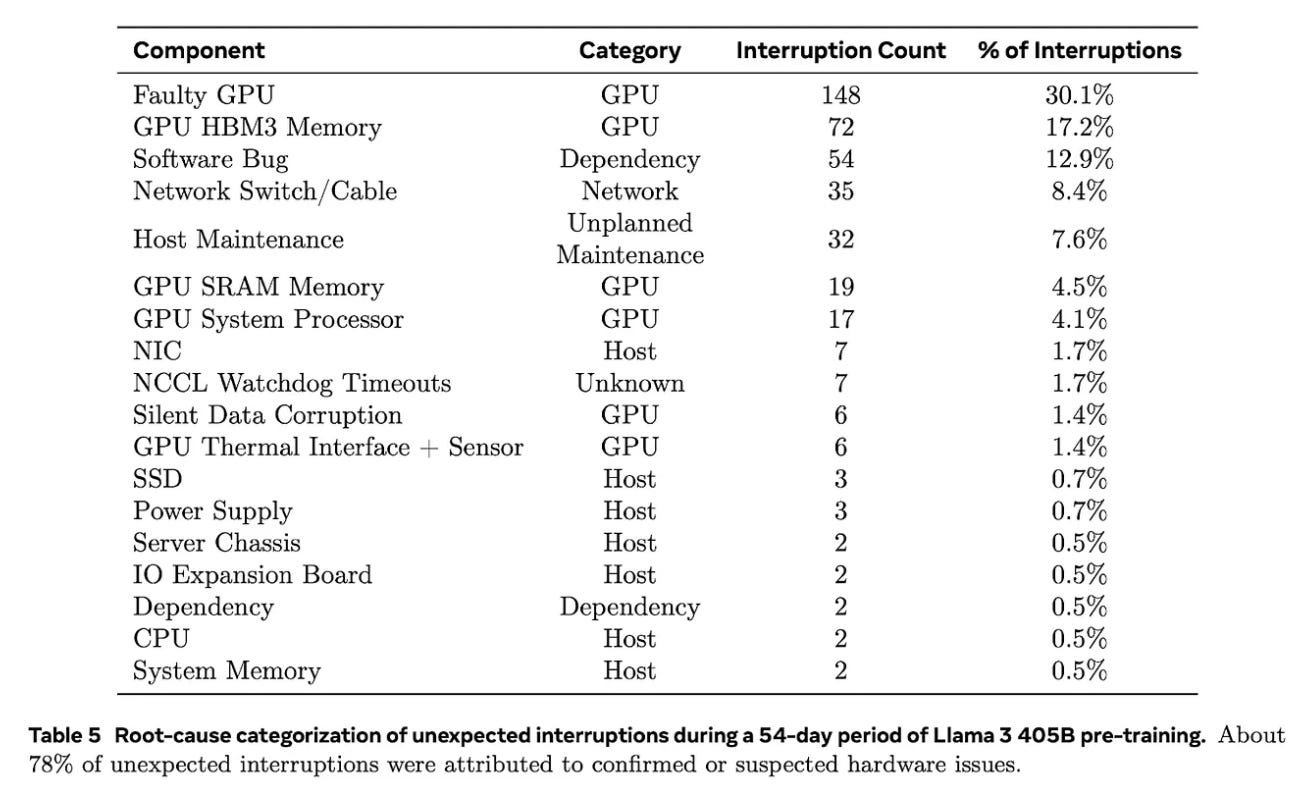
Báo cáo kỹ thuật Llama-3 là nguồn tài liệu hữu ích giúp bạn hiểu rõ có bao nhiêu biến số liên quan đến vấn đề này và bảng dưới đây cho thấy một lỗi đơn giản có thể dễ dàng gây ra sự cố dẫn đến thời gian luyện tập không hiệu quả.
Như bạn có thể thấy từ danh sách, có thể là vấn đề liên quan đến GPU, mạng, sự phụ thuộc, bảo trì hoặc thậm chí là một điều gì đó chưa biết - bạn không thể loại trừ bất cứ điều gì. Chỉ sở hữu GPU không mang lại cho bạn tấm vé vàng để chạy thử trước hoàn hảo.
Tôi có thể dành thời gian ở đây để xem xét một số phương trình được đề xuất để đo lường hiệu quả đào tạo, như MFU , MAMMF , SFU và Continuity , nhưng Ronan đã làm tốt việc đó rồi và điều đó có thể khiến báo cáo này kéo dài hơn mức cần thiết.
Tóm lại là gì?
Có nhiều biến số khác nhau được sử dụng để xác định hiệu quả của quá trình đào tạo, bao gồm cả phần mềm và phần cứng, mặc dù hầu hết điều này phụ thuộc vào FLOP và việc đo lườ







{kind=link}