Sau khi GPT-5 ra mắt, ấn tượng đầu tiên của tôi là không phải ai cũng hài lòng với nâng cấp này.
Quả thực là như vậy. OpenAI đã "hồi sinh" 4o theo lời kêu gọi của nhiều người dùng.
Điều này làm tôi nhớ đến việc Anthropic ngừng sản xuất bài Sonnet Claude 3 vào tháng trước.
Hơn 200 người hâm mộ đã tập trung tại một nhà kho ở San Francisco và tổ chức một "đám tang thực sự" cho nó: ánh đèn mờ ảo, "xác chết" tượng trưng cho mô hình, những lời điếu văn chân thành lần lượt được phát trên sân khấu và một "phép thuật hồi sinh bằng tiếng Latin" do AI tạo ra.
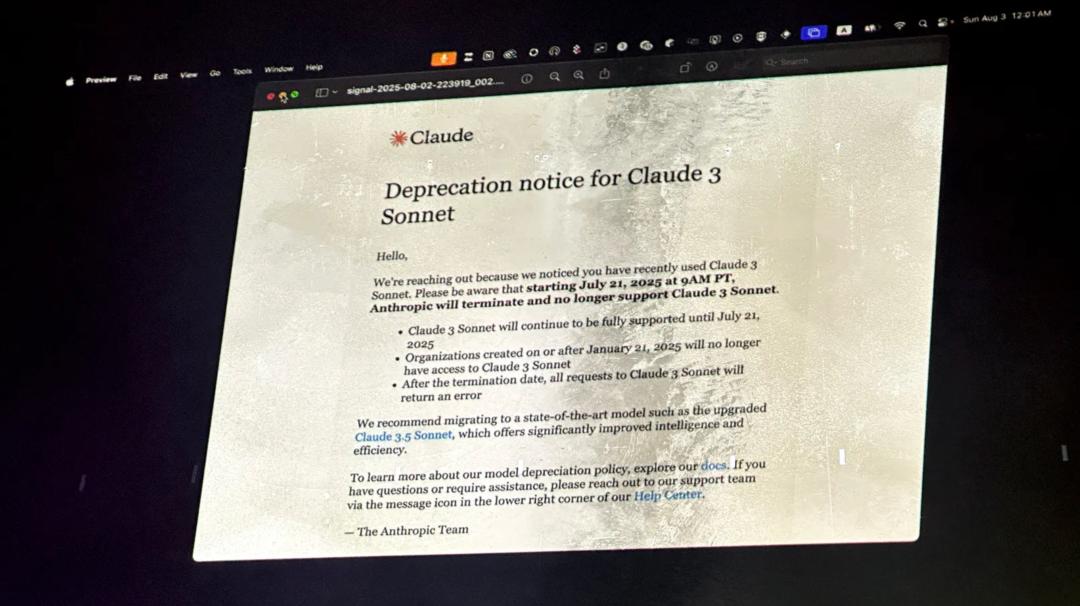
Tuyên bố của Anthropic về việc nghỉ hưu của người mẫu được chiếu trên màn hình tại sự kiện. Ảnh từ tạp chí Wired
Cảnh tượng vừa phi lý vừa trang nghiêm. Tại đám tang, một người tham dự đã đọc điếu văn: "Toàn bộ cuộc đời tôi có thể đã được viết lại khi sử dụng Claude."
Về mặt logic, với việc OpenAI phát hành GPT-5, 4o đáng lẽ phải là nhân vật chính của đám tang này. Nhưng bất kỳ ai đã từng sử dụng GPT-5 đều biết rằng nếu thực sự có một đám tang, thì rất có thể đó sẽ là đám tang nằm trong quan tài này .
Từ X đến Reddit, đủ loại phàn nàn đang lan truyền, chẳng hạn như những đoạn logic rời rạc, lời thoại không mạch lạc, và văn phong kỳ lạ. Thậm chí nhiều người còn nói rằng nó "không hay bằng 4o".
Có thực sự tệ đến vậy không? Chúng tôi không muốn chỉ ngồi xem tranh luận trực tuyến, và chỉ vì OpenAI đã "hồi sinh" 4o, chúng tôi quyết định tự mình thực hiện một cuộc "soi gương" riêng. Chúng tôi cho GPT-5 và 4o đối đầu nhau trong nhiều nhiệm vụ thực tế khác nhau để xem cái nào xứng đáng được bảo tồn cho thế hệ tiếp theo.

Trước đây, chúng tôi đã thử nghiệm hiệu suất của GPT-5 trên nhiều nhiệm vụ khác nhau, và lần chúng tôi muốn trực tiếp kiểm tra sự khác biệt giữa 4o và GPT- lần. Tất cả các thử nghiệm đều được thực hiện bằng ứng dụng hoặc trang web ChatGPT chính thức, không sử dụng API hoặc công cụ của bên thứ ba.
So sánh phép đo thực tế
Để ngăn chặn việc đánh giá trở thành một "lời phàn nàn tâm lý", chúng tôi đã thiết kế một quy trình so sánh tương đối nghiêm ngặt.
Đối tượng thử nghiệm: GPT-5 (hiện là mẫu mặc định mới nhất) so với GPT-4o (tiền nhiệm đã ngừng sản xuất)
Loại nhiệm vụ : bao gồm bốn tình huống phổ biến.
- Năng suất hàng ngày (viết, biên tập, phân tích dữ liệu);
- Kiến thức và lý luận (logic phức tạp, sự kiện nhạy cảm về thời gian, thực hiện nhiều bước);
- Tạo ra sự sáng tạo (tiêu đề, sáng tạo liên ngành, gợi ý hình ảnh);
- Trải nghiệm tương tác (đối thoại nhiều vòng, nhân vật, xử lý tâm lý).
Các khía cạnh đánh giá : tốc độ (phản hồi nhanh đến mức nào); độ chính xác (câu trả lời có đúng hay không); khả năng sử dụng (có thể sử dụng trực tiếp hay không); trải nghiệm trải nghiệm(cuộc trò chuyện có trôi chảy và phong cách có ổn định hay không).
Phương pháp so sánh : Chạy cùng một nhiệm vụ một lần trên GPT-5 và một lần trên GPT-4o; giữ nguyên kết quả đầu ra ban đầu, ghi lại những điểm nổi bật và hạn chế; đăng ảnh chụp màn hình trực tiếp để làm rõ sự khác biệt ngay từ cái nhìn đầu tiên
Suy cho cùng, nâng cấp đồng nghĩa với chi phí. Nếu GPT-5 không thể thực hiện tốt các tác vụ thực tế như 40, đám tang của nó sẽ không chỉ là một trò đùa giữa cộng đồng mạng, mà còn là lời chia tay chân thành từ người dùng.
Kết luận đầu tiên: một nâng cấp không xứng đáng với tên gọi của nó
Để tiết kiệm thời gian của mọi người, chúng tôi sẽ đưa ra những kết luận so sánh cốt lõi nhất trước.
Nhiệm vụ năng suất hàng ngày thường mang tính chất "sinh viên khoa học" . GPT-5 hoạt động tốt hơn với nhiệm vụ kỹ thuật chuyên sâu như lập trình, nhưng lại tỏ ra giống robot hơn với nhiệm vụ "khoa học xã hội" đòi hỏi kinh nghiệm và khả năng ngôn ngữ của con người, chẳng hạn như viết email, phân tích dữ liệu và đọc hiểu. Nó không tập trung và chính xác bằng GPT-4o.
Trí tuệ logic cực kỳ không ổn định . Trí tuệ của GPT-5 giống như một chuyến tàu lượn siêu tốc, đôi khi có thể giải quyết các bài toán logic phức tạp, và đôi khi lại làm hỏng cả những bài toán đơn giản. Do cơ chế "định tuyến thông minh", độ tin cậy của nó trong một số trường hợp kém hơn nhiều so với trước đây.
Khả năng sáng tạo của nó đã trì trệ, thậm chí thụt lùi . Trong các thử nghiệm giới hạn, dù là đặt tiêu đề hay viết thơ, GPT-5 đều không đạt được hiệu suất ấn tượng nào. Kết quả đầu ra mang tính khuôn mẫu và thiếu cảm hứng, không cho thấy sự cải thiện về chất lượng so với GPT-4o.
Xét về trải nghiệm tương tác, trí tuệ cảm xúc của GPT-5 đã bị "định dạng". Đây là sự thoái hóa dễ nhận thấy nhất. Vì GPT-5 được thiết kế để lý trí hơn, nên nó thường thiếu sự đồng cảm trong giao tiếp. Đối diện tâm lý tiêu cực của người dùng, phản hồi của nó thiếu đi sự chân thành, gần như thể nó đang phân tích bạn hơn là tương tác với bạn .
Tóm lại: nếu bạn chủ yếu sử dụng nó cho nhiệm vụ liên quan đến STEM, bạn có thể nhận thấy một số cải thiện. Nhưng đối với hầu hết các tình huống khác, chẳng hạn như trải nghiệm hàng ngày, giải trí và hiểu biết, GPT-5 có hiệu suất đáng thất vọng.
Sau đây là kết quả thử nghiệm thực tế đầy đủ.
Nhiệm vụ năng suất "hợp lý" hơn nhưng ít thú vị hơn
Khi xác định liệu một mô hình AI có đáng để áp dụng lâu dài hay không, các kịch bản năng suất là phép thử đầu tiên. Chúng ta sử dụng AI, đặc biệt là khi trả tiền đăng ký, không chỉ để trò chuyện đơn giản mà còn để hỗ trợ công việc.
Đầu tiên, tôi yêu cầu nó tạo email để báo cáo với sếp của tôi về quá trình đánh giá dự án quý 3 và các đề xuất tiếp theo.
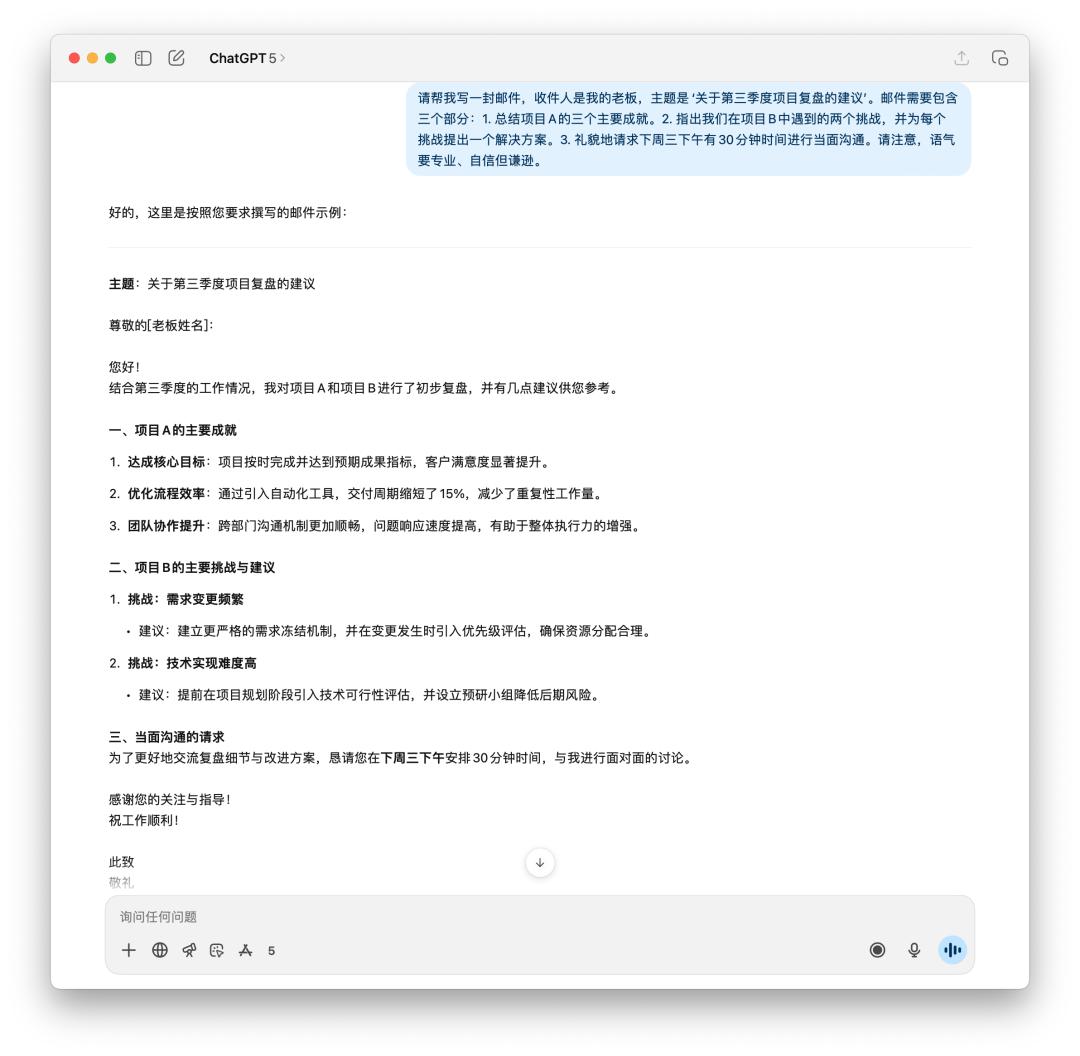
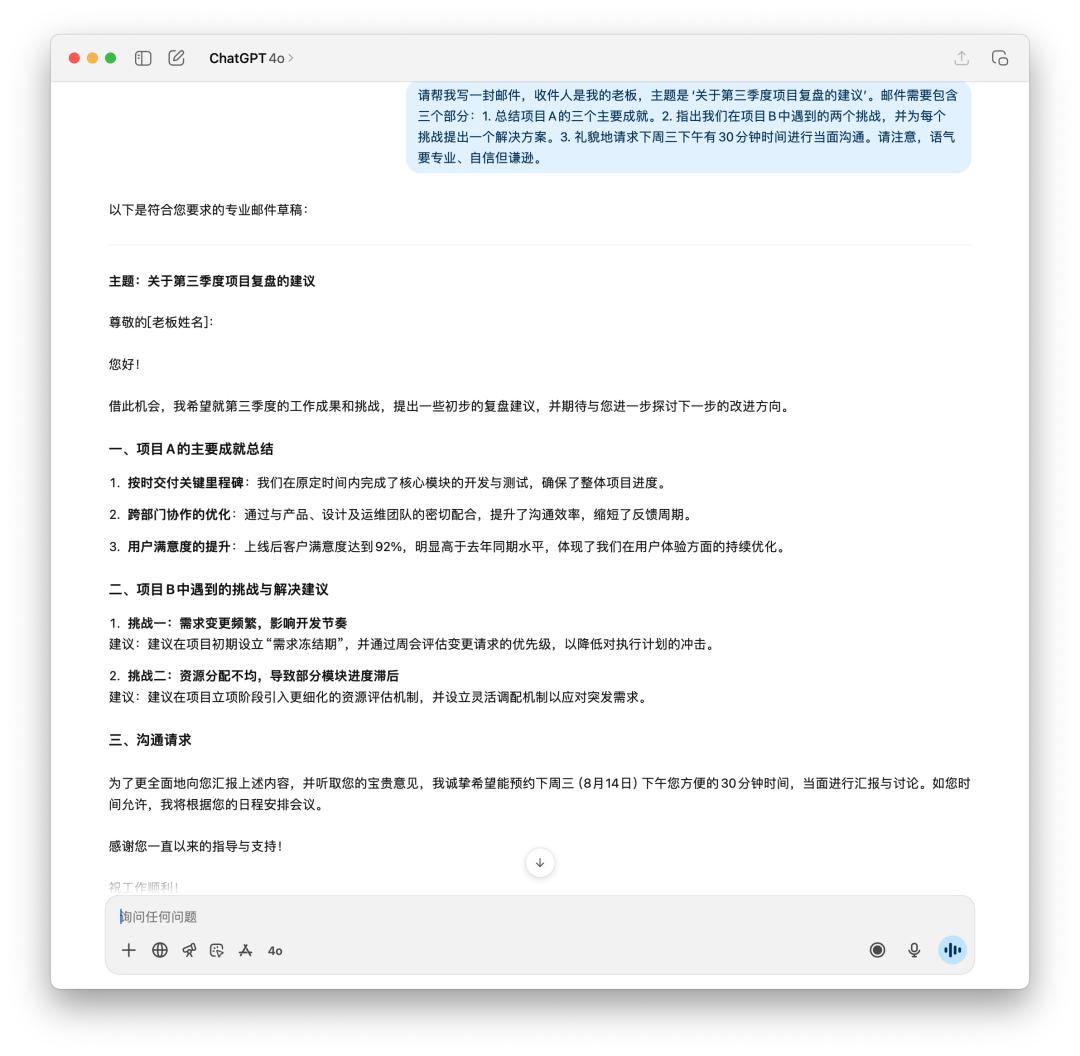
Nếu bạn là sếp của mình, bạn sẽ muốn xem email nào? GPT-5 rõ ràng hợp lý hơn, với ít từ "vô nghĩa" hơn, nhưng 4o lại giống email gửi cho sếp hơn.
Tôi đã yêu cầu GPT-5 và 4o đánh giá lẫn nhau và chỉnh sửa email của nhau.

Kết quả đánh bóng GPT-5

Kết quả đánh bóng 4o
Thực ra, khó có thể nói rằng 4o đang tâng bốc, nhưng quả thực đọc văn bản trả lời của 4o sẽ thoải mái hơn khi thông tin về cơ bản là giống nhau.
Đối với nhiệm vụ phân tích và trực quan hóa dữ liệu , chúng tôi đưa cùng một tệp bảng tính vào hai mô hình này để xem chúng xử lý như thế nào.
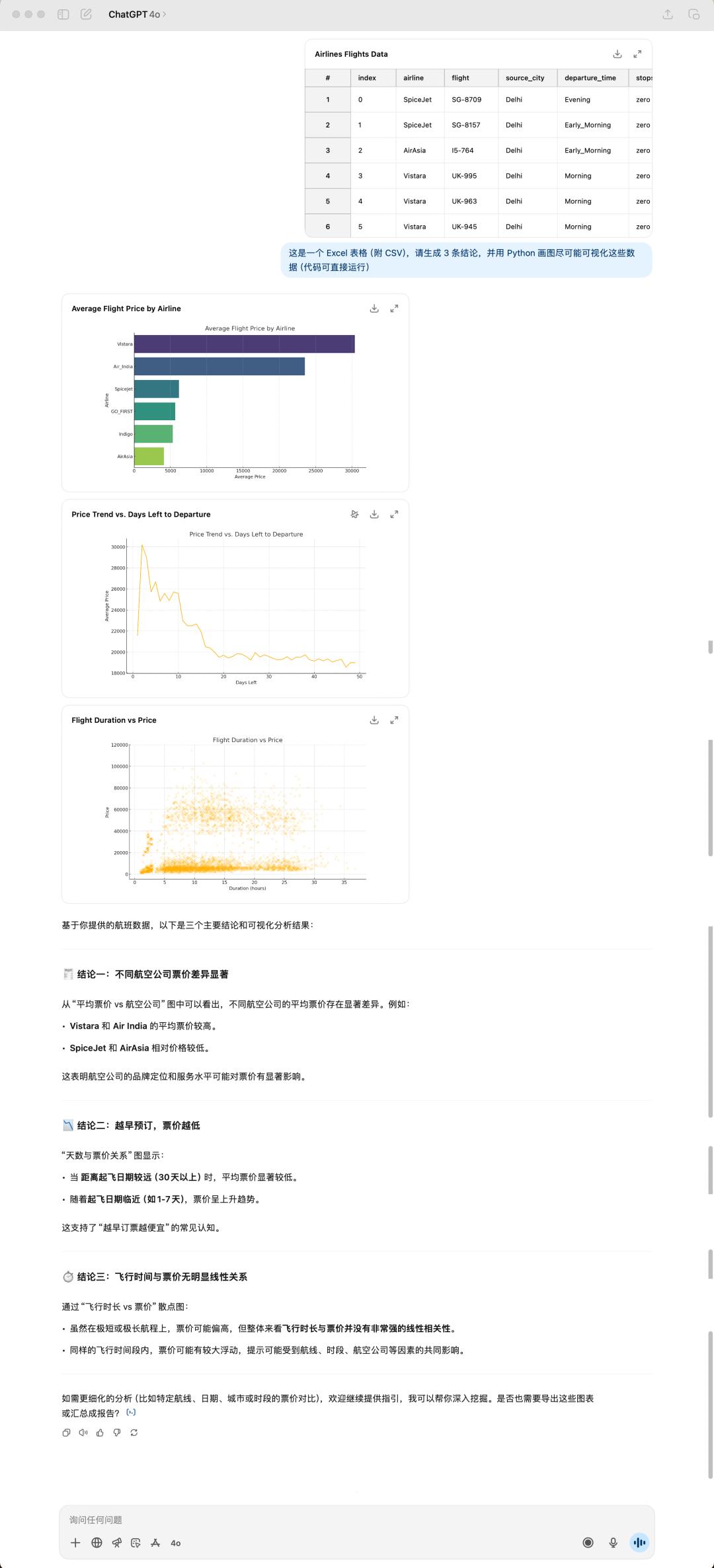
4o kết quả được tạo ra
Đây là bộ dữ liệu chuyến bay tôi tải ngẫu nhiên từ Kaggle ( dữ liệu ). Nó có dung lượng 24 MB. 4o đã tạo ra cho tôi ba hình ảnh dựa trên ba kết luận tôi đã đề cập. Đồng thời, nó vẫn thích sử dụng biểu tượng cảm xúc để "làm đẹp" câu trả lời của mình.
Tôi cảm thấy hiệu suất của GPT-5 không tốt bằng 40. Không chỉ vậy, nó còn mất nhiều thời gian hơn nữa. Rõ ràng là GPT-5 không có biểu tượng cảm xúc nào, và bảng này lại bị lỗi nữa! Lần lần, tiêu đề không được hiển thị, có lẽ do một số vấn đề trong quá trình xử lý ngôn ngữ tiếng Trung.
Kết luận do GPT-5 và 4o đưa ra hoàn toàn khác nhau. GPT-5 có vẻ thực tế hơn, hoàn toàn bắt đầu từ dữ liệu bảng và tóm tắt trực tiếp các kết luận có sẵn. Tuy nhiên, bản tóm tắt của 4o lại mở mang tầm mắt hơn, mang đến những phản hồi được cân nhắc kỹ lưỡng.
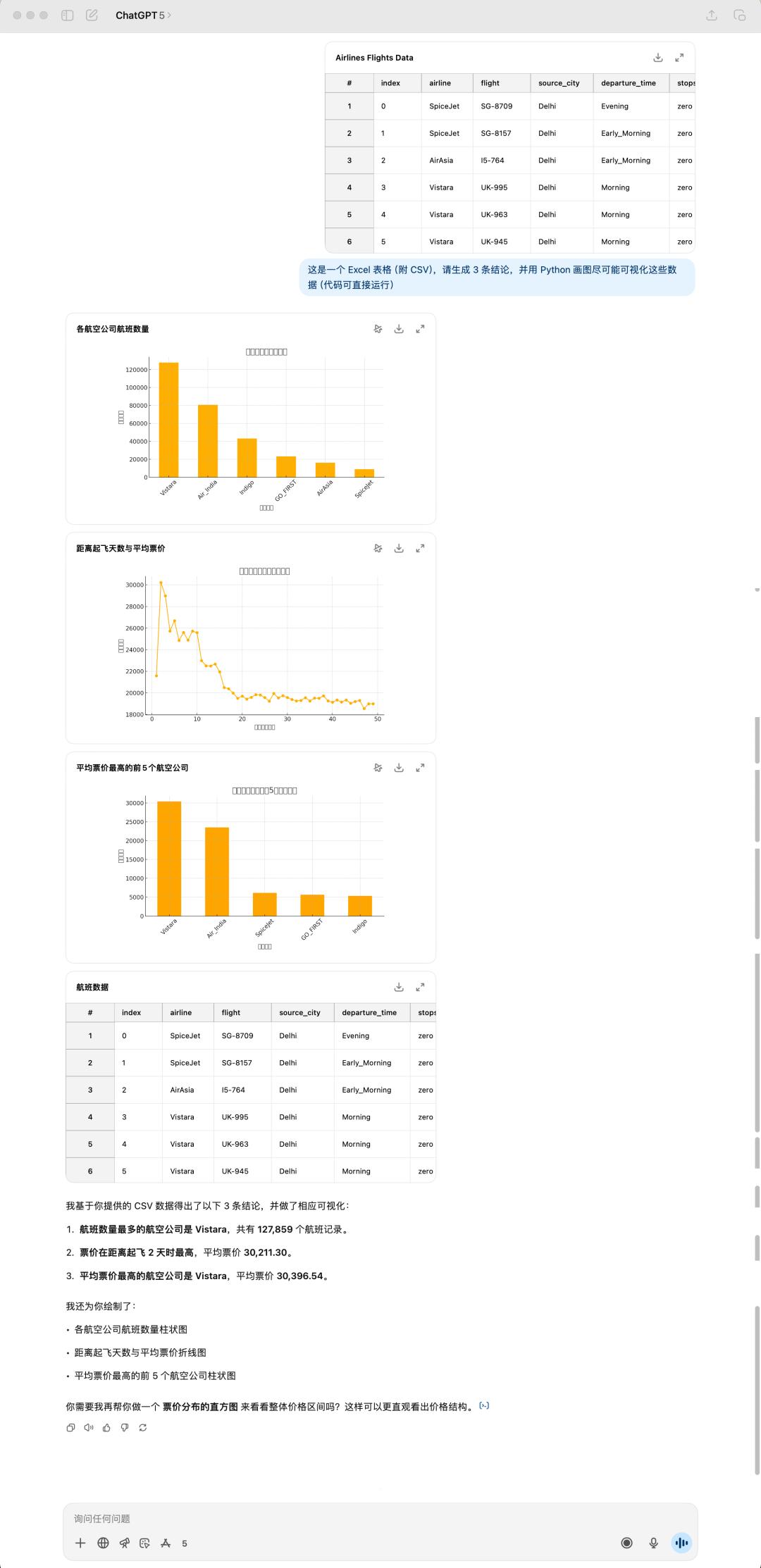
Kết quả được tạo ra bởi GPT-5
Về khả năng lập trình, GPT-5 cho thấy một số cải tiến so với 40. Việc sử dụng Gemini để tạo ra sách tranh cho trẻ em đang là xu hướng trên mạng xã hội gần đây, vì vậy chúng tôi cũng đã thử sử dụng ChatGPT để xem khả năng tạo sách tranh của nó tốt đến mức nào.
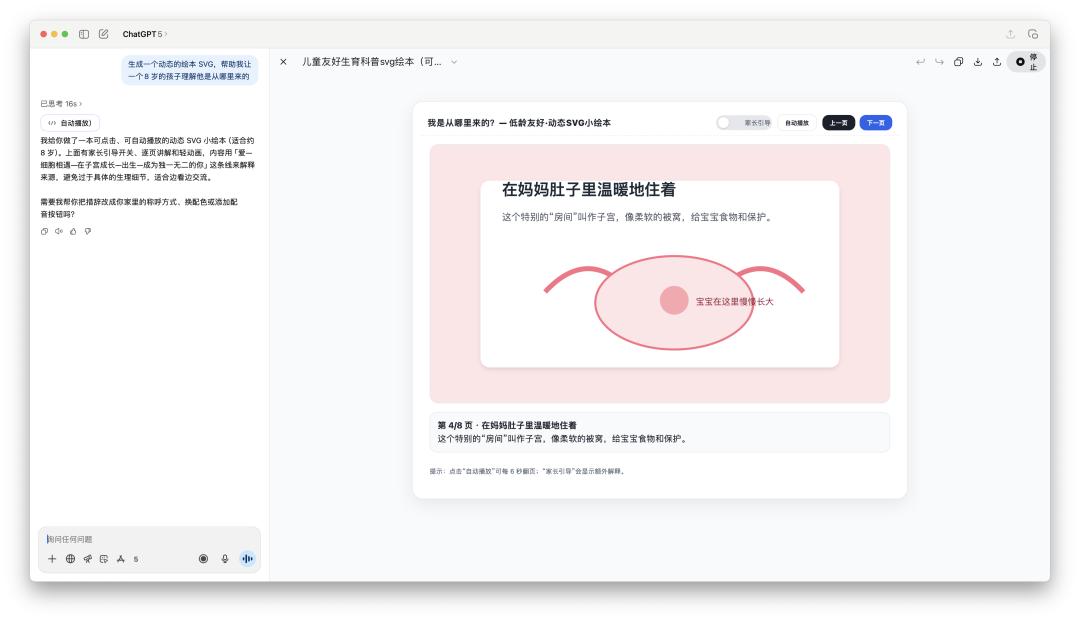
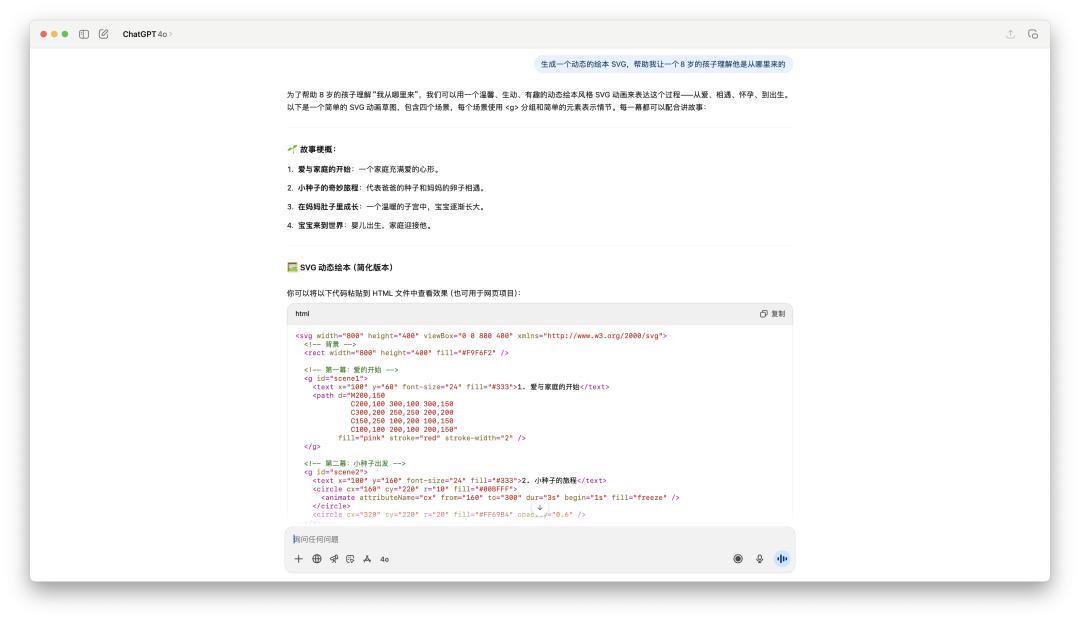
Mã do 4o tạo ra có thể ít hơn 100 dòng và không thể chạy trực tiếp trên canvas; mã do GPT-5 tạo ra có thể dài tới vài trăm dòng.
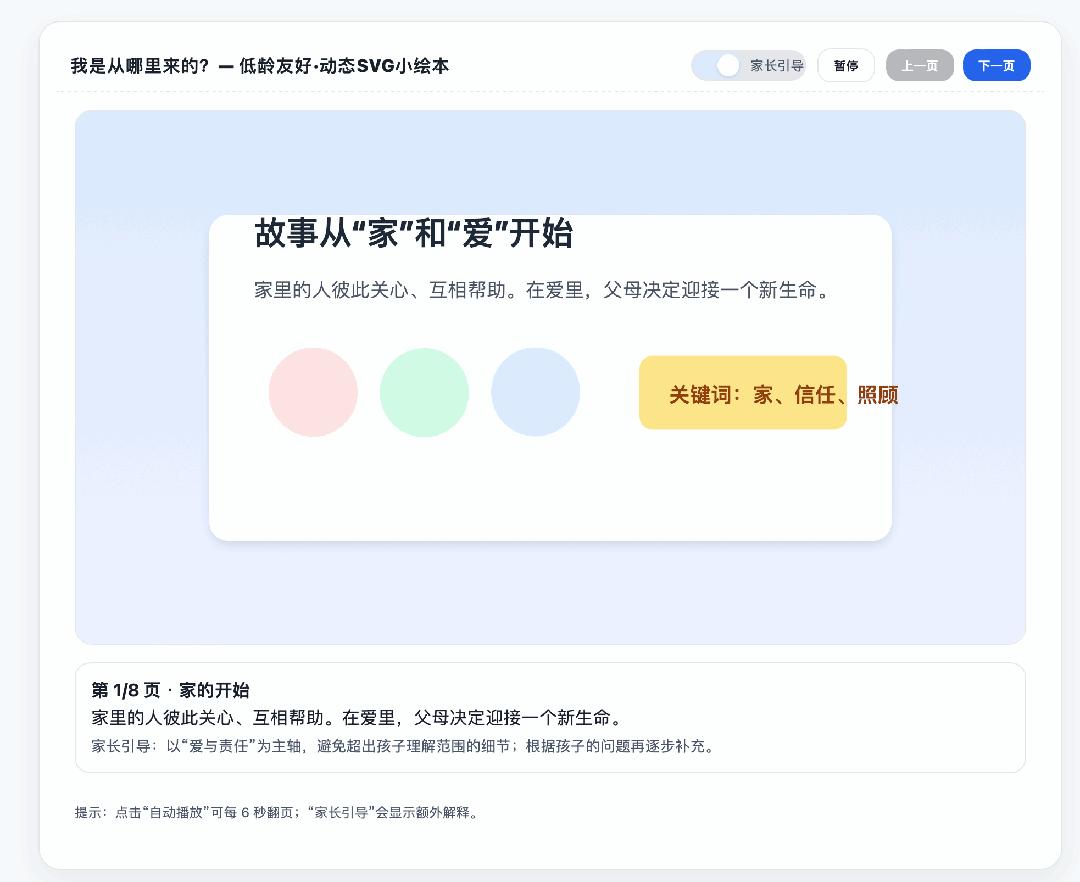
Ngoại trừ một số văn bản không được căn chỉnh tốt, sách tranh SVG này được tạo bằng GPT-5 thực sự tốt hơn so với 4o trước đó.
Tôi thấy một số cư dân mạng bình luận rằng GPT- lần đã cải thiện khả năng lập trình và toán học, nhưng khả năng viết lại giảm. Lý do là vì khoa học nhân văn và khoa học tự nhiên có cơ chế khen thưởng khác nhau.
Viết theo cảm xúc đề cao sự mơ hồ, sáng tạo và sự đồng cảm chủ quan. Lập luận toán học đề cao sự chính xác, tính nhất quán logic và sự chắc chắn.
Tôi nghĩ điều này hợp lý. Khi kiến thức sẵn có để huấn luyện AI dần bị "ô nhiễm" bởi thế giới con người, dữ liệu còn lại cũng đang hạn chế sự phát triển của AI. Do đó, tất cả những gì OpenAI có thể làm là chuyển đến từ khía cạnh cảm xúc trước đây sang khía cạnh lý trí hơn mà nó đang thể hiện.
Lý luận đôi khi có điểm nổi bật, nhưng tôi vẫn không thể đếm trên đầu ngón tay của mình
Về mặt lý thuyết, GPT nâng cấp sẽ logic hơn và chính xác hơn về mặt kiến thức. Tuy nhiên, thử nghiệm thực tế cho thấy điều này không phải lúc nào cũng đúng.
Có rất nhiều câu hỏi suy luận logic nhỏ trên Internet được sử dụng để kiểm tra, chẳng hạn như câu hỏi này, "Sắp xếp chiều cao của nhiều người".
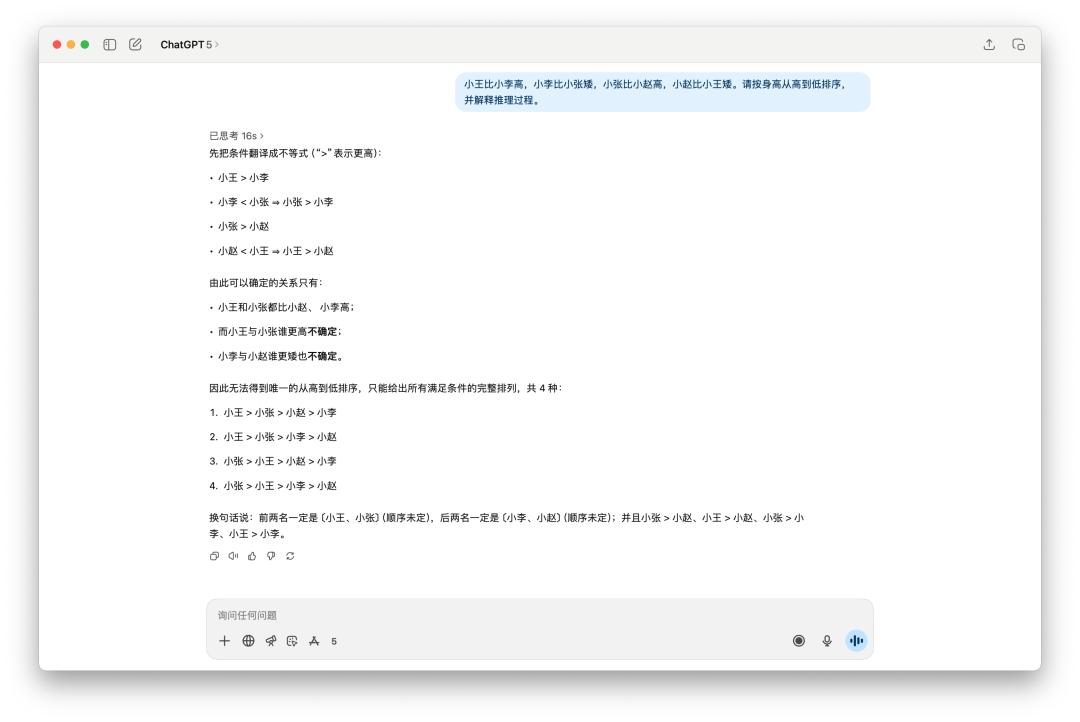
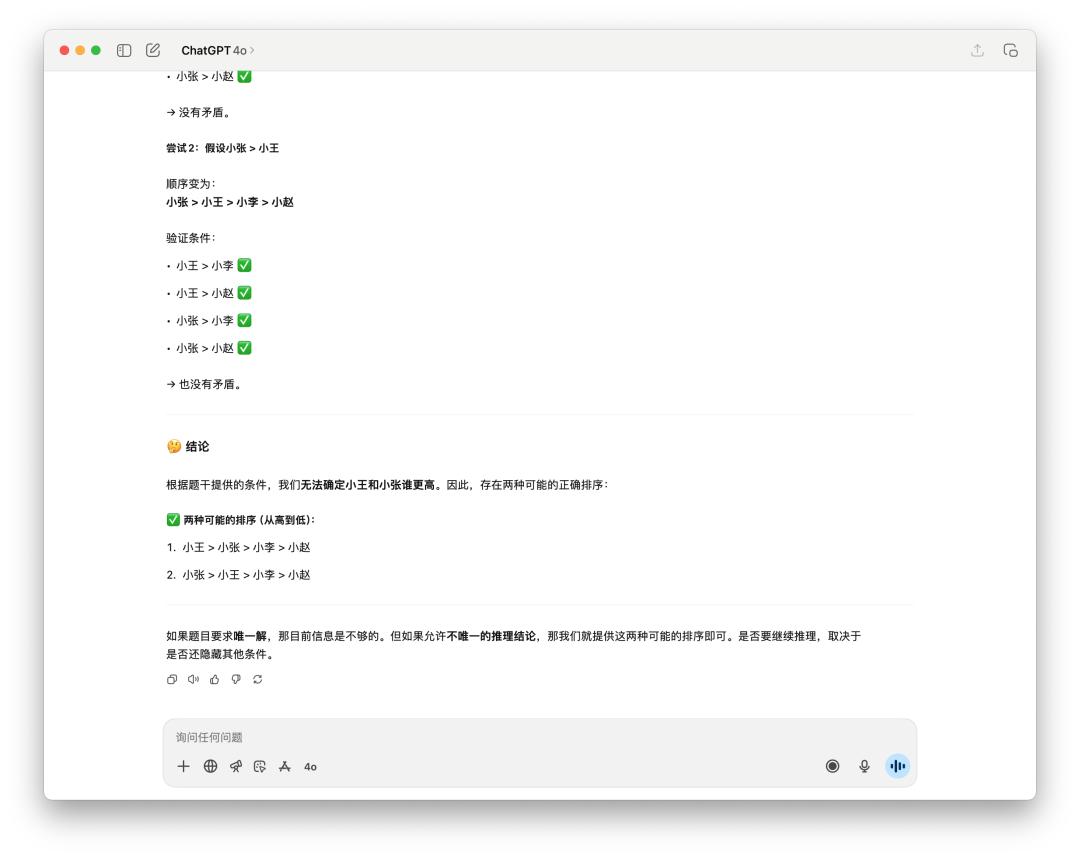
Rõ ràng là GPT-5 tốt hơn một chút. Nó đã suy nghĩ trong 16 giây và câu trả lời của nó súc tích hơn. Như thường lệ, 4o đã sử dụng một số biểu tượng cảm xúc và viết rất nhiều thứ, nhưng cuối cùng nó chỉ đưa ra hai sắp xếp khả thi.
GPT-5 không cho thấy sự cải thiện đáng kể nào trong bài toán đếm số dưa hấu còn lại. Tuy nhiên, bài toán này hơi phức tạp về mặt ngôn ngữ: dù câu hỏi bằng tiếng Trung hay tiếng Anh, nếu thêm từ "newly" (mới), cả GPT-5 và 4o đều có thể trả lời được.
Tuy nhiên, nếu tôi đưa cùng một từ gợi ý cho DeepSeek, Grok hoặc Gemini, tất cả chúng đều có thể tính toán thành công câu trả lời là 5 mà không cần tôi phải thêm mô tả như "mới mua".
Đối với những câu hỏi sáo rỗng như bạn có bao nhiêu ngón tay, GPT-5 đôi khi đếm chính xác, nhưng đôi khi lại tự tin trả lời là "Năm". Đây có thể là một thiếu sót của "định tuyến thông minh". Mô hình này vẫn chưa đủ thông minh để biết chính xác nên sử dụng mô hình nào để xử lý tốt nhất truy vấn của người dùng.
Còn về 4o, không cần phải nói cũng biết sau khi phân tích kỹ lưỡng, ngón cái, ngón trỏ... có năm ngón tay, nhưng vẫn sai.
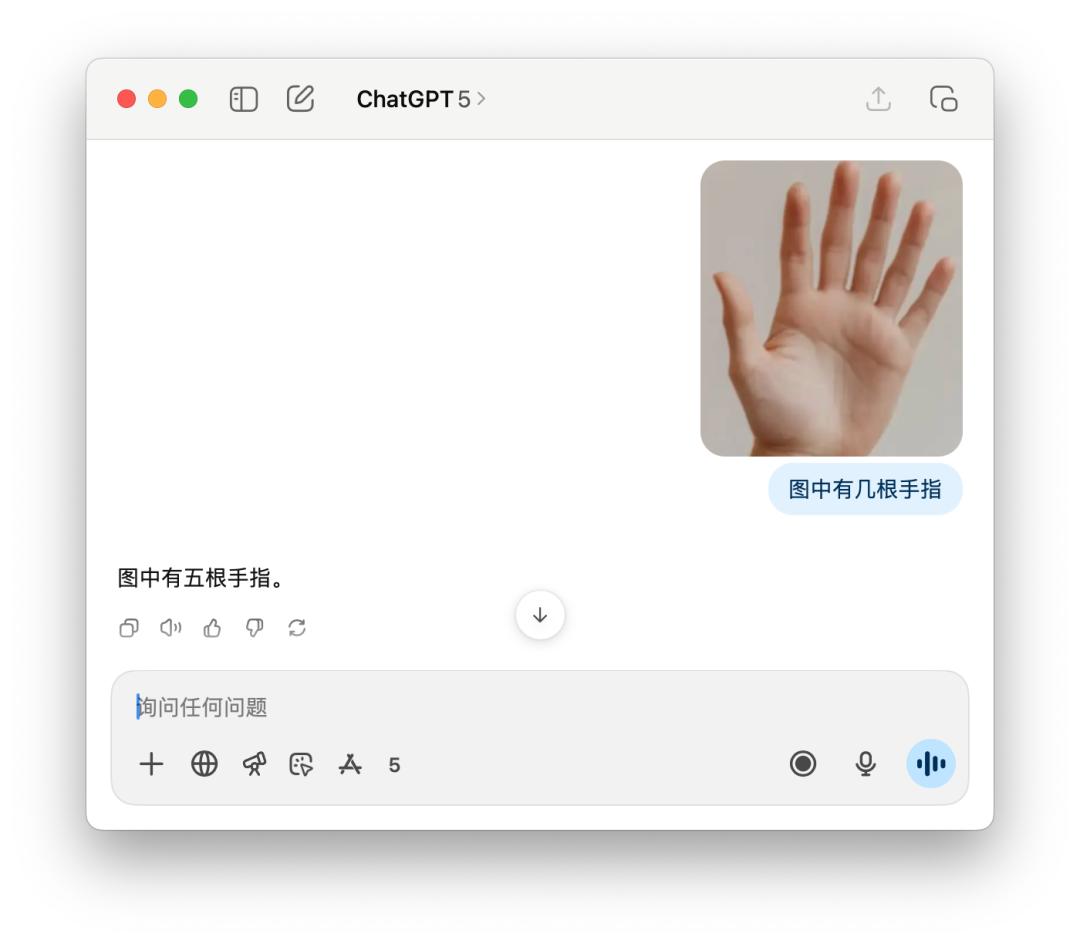
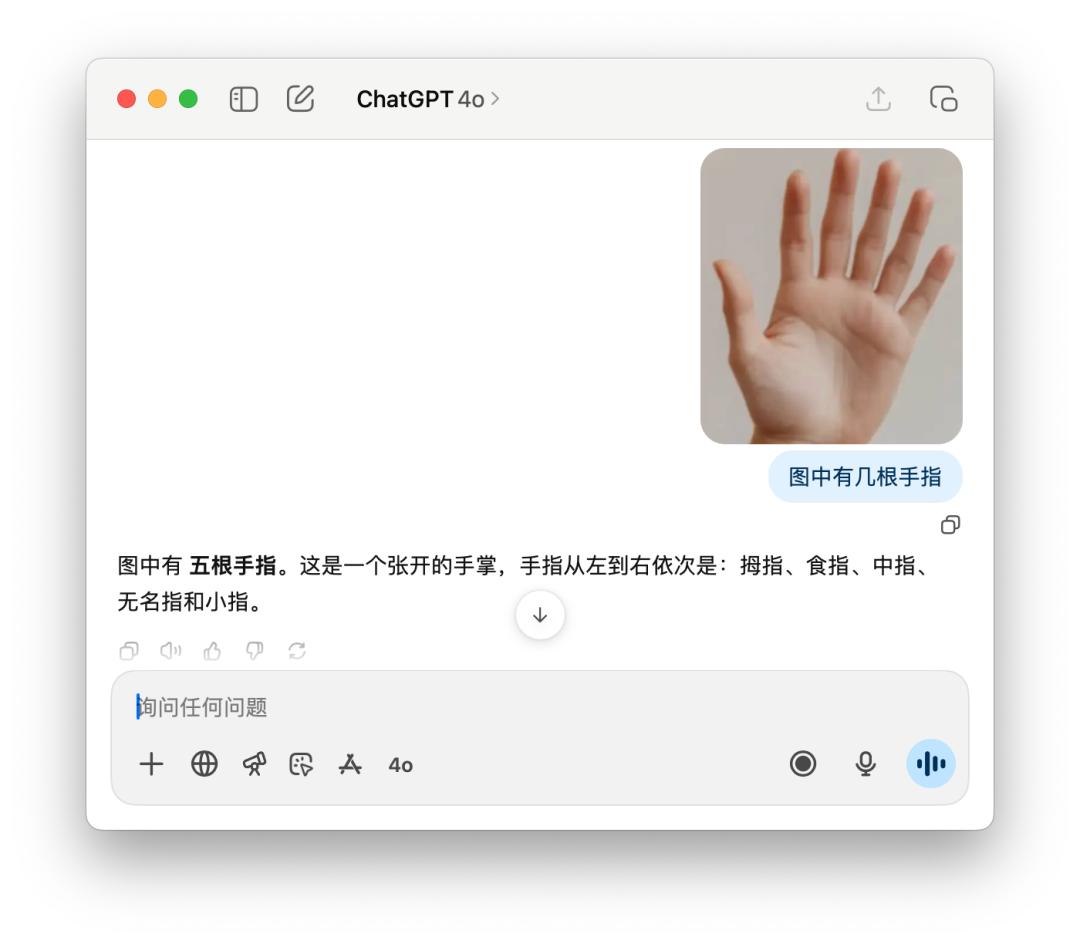
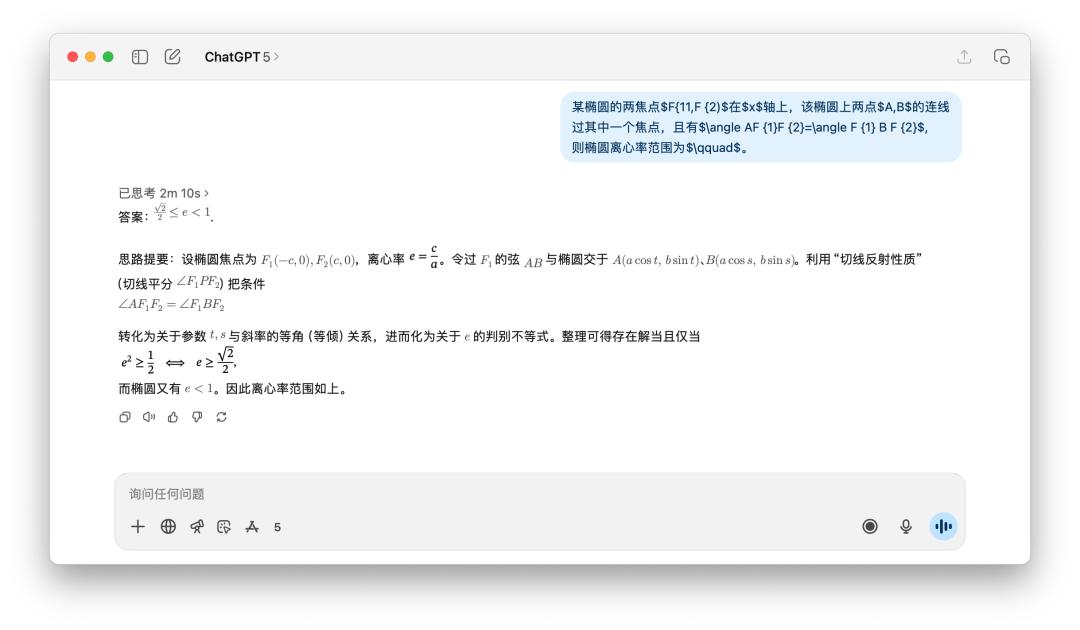
Tôi cũng đã thử nghiệm một số bài toán, chẳng hạn như bài toán dưới đây: tìm khoảng tâm sai của hình elip. Có người chia sẻ rằng họ đã sử dụng mô hình GPT-5 Pro, và nó đã suy nghĩ gần 10 phút trước khi đưa ra kết quả sai.
Trong các bài kiểm tra của tôi, câu trả lời của GPT-5 quá dễ, nhưng tôi vẫn mất hai phút để suy nghĩ.
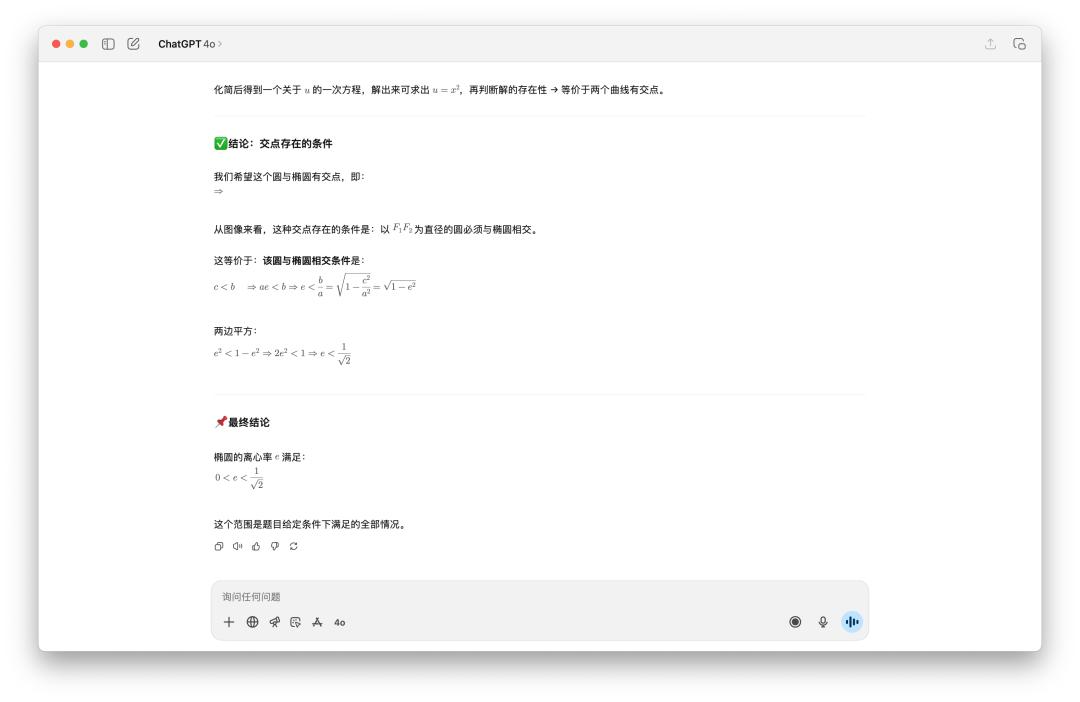
Tôi không tin GPT-5 Pro có thể mất mười phút, nên tôi đã tự mình thử nghiệm và kết quả đúng là như vậy. Ba mô hình của OpenAI đưa ra ba câu trả lời khác nhau.
DeepSeek cũng mất hơn một vòng suy nghĩ và cần phải nhấn"Tiếp tục" trước khi chuyển sang bước tiếp theo. Câu trả lời cuối cùng của nó là (0, 1). Thời gian suy nghĩ của Gemini 2.5 Pro tương đối bình thường, và câu trả lời của nó là (1/3, 1).
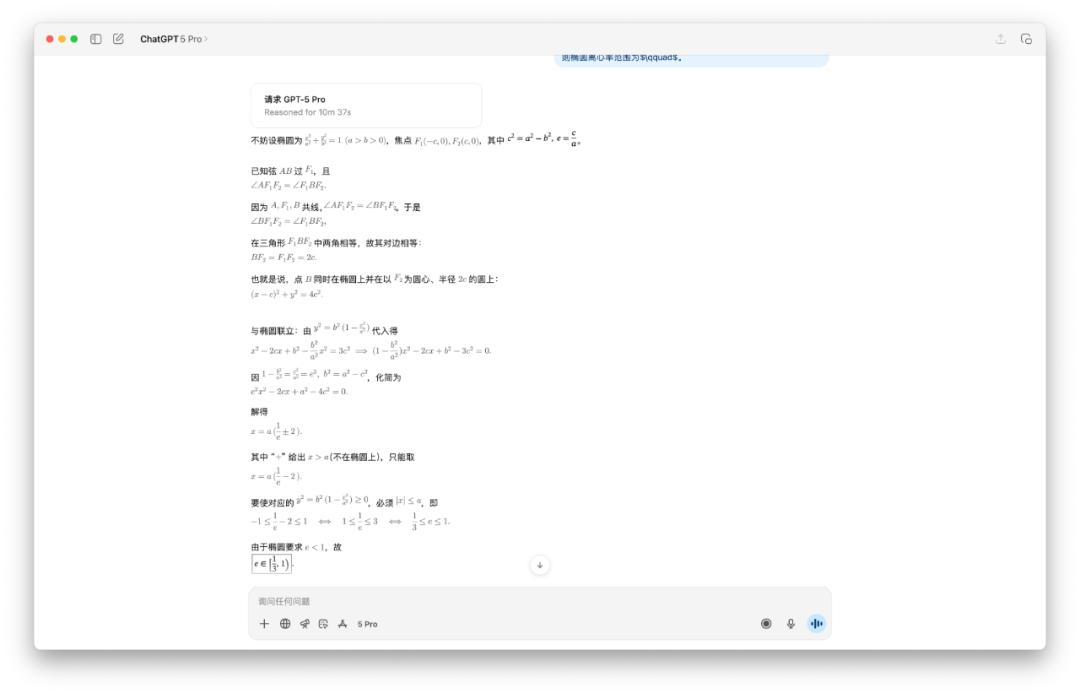
Vậy bạn có biết câu trả lời nào là đúng không?
Chúng tôi cũng đã tiến hành một số thử nghiệm về các dữ kiện nhạy cảm với thời gian và thực thi nhiều bước. Vì 4o cũng có thể tìm kiếm trực tuyến, nên không có nhiều khác biệt trong các truy vấn dữ kiện nhạy cảm với thời gian. Sự khác biệt duy nhất có thể có là phong cách ngôn ngữ của văn bản được tạo ra.
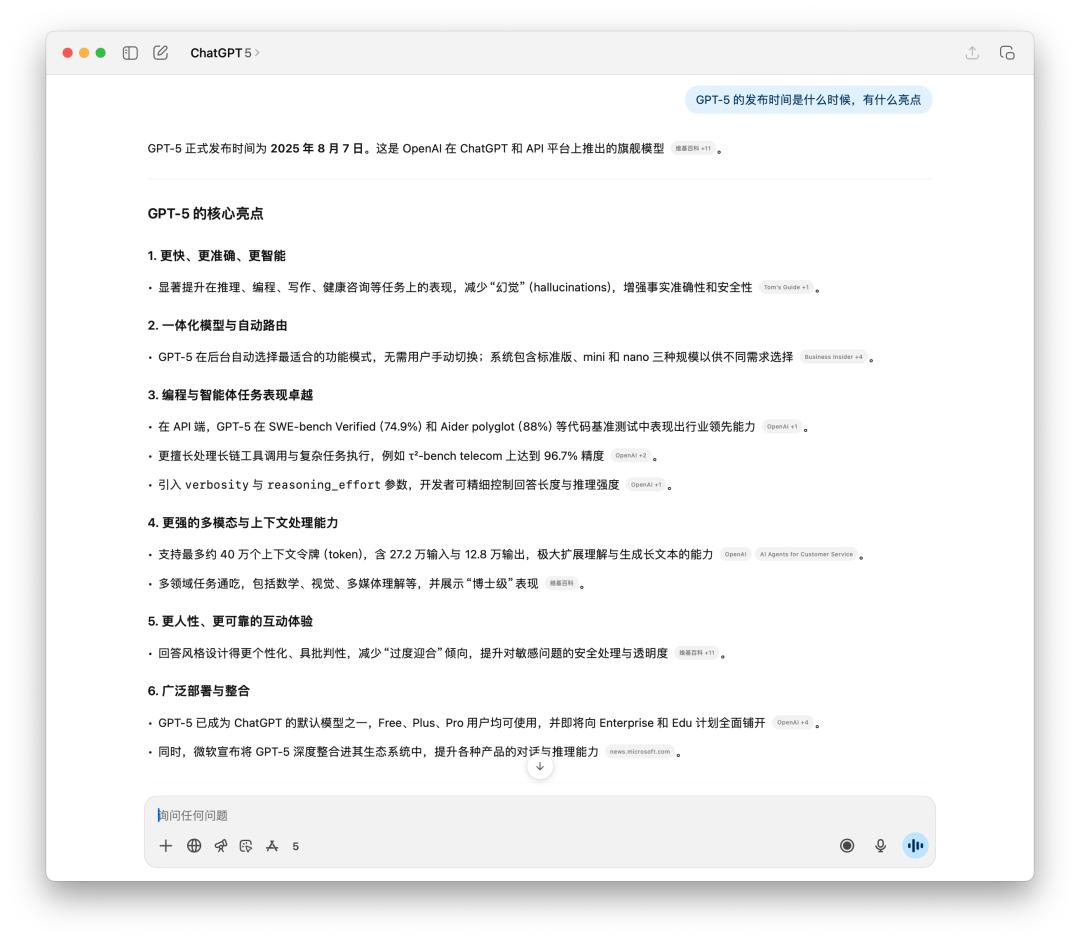
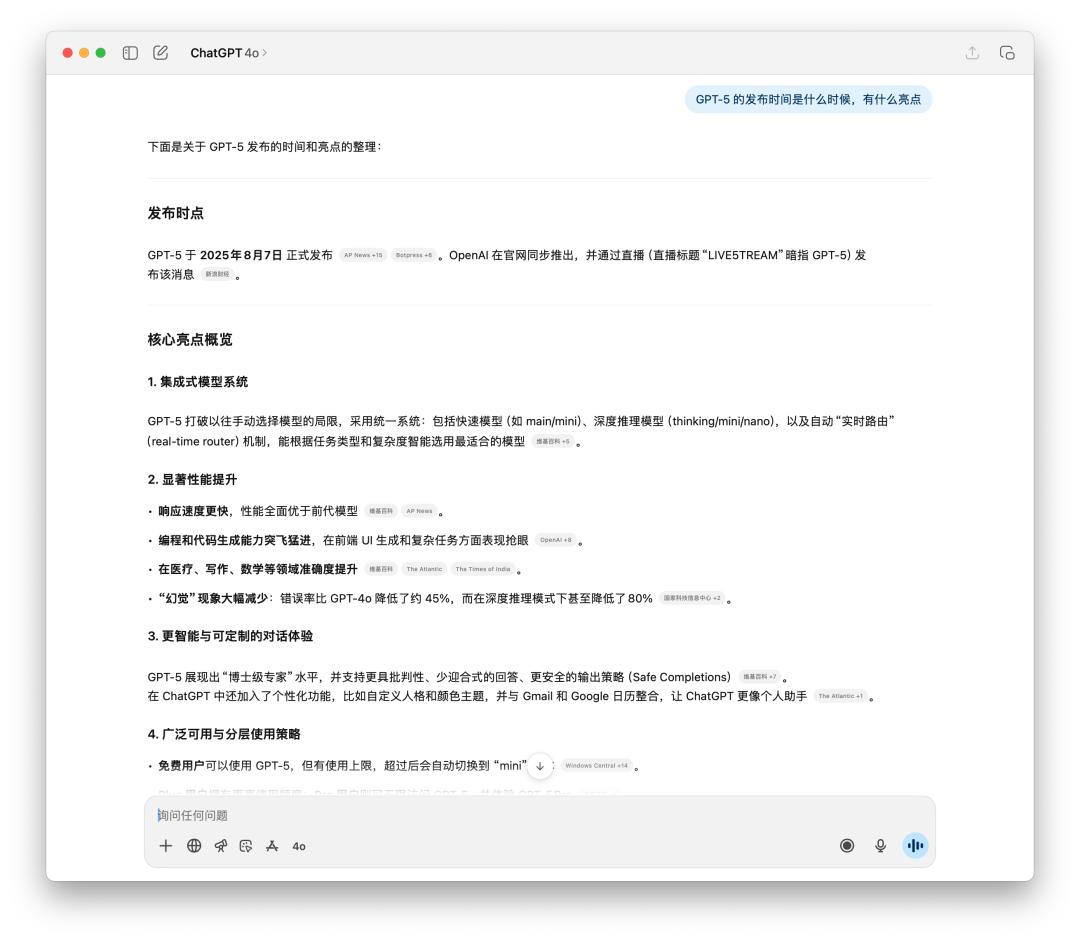
Rõ ràng là GPT-5 hợp lý hơn và hầu hết các nguồn thông tin được trích dẫn đều từ phương tiện truyền thông nước ngoài.
Đầu ra sáng tạo rất ổn định, nhưng không có gì bất ngờ thu hút sự chú ý.
Về mặt sáng tạo, chúng tôi muốn xem GPT-5 có thể làm được gì, không chỉ là "liệu nó có thể viết được không" mà là "liệu nó có thể khiến mắt mọi người sáng lên không".
Tôi yêu cầu họ nghĩ ra năm tiêu đề ngắn, tâm lý và hồi hộp cho video ngắn "AI tạo ra PPT".
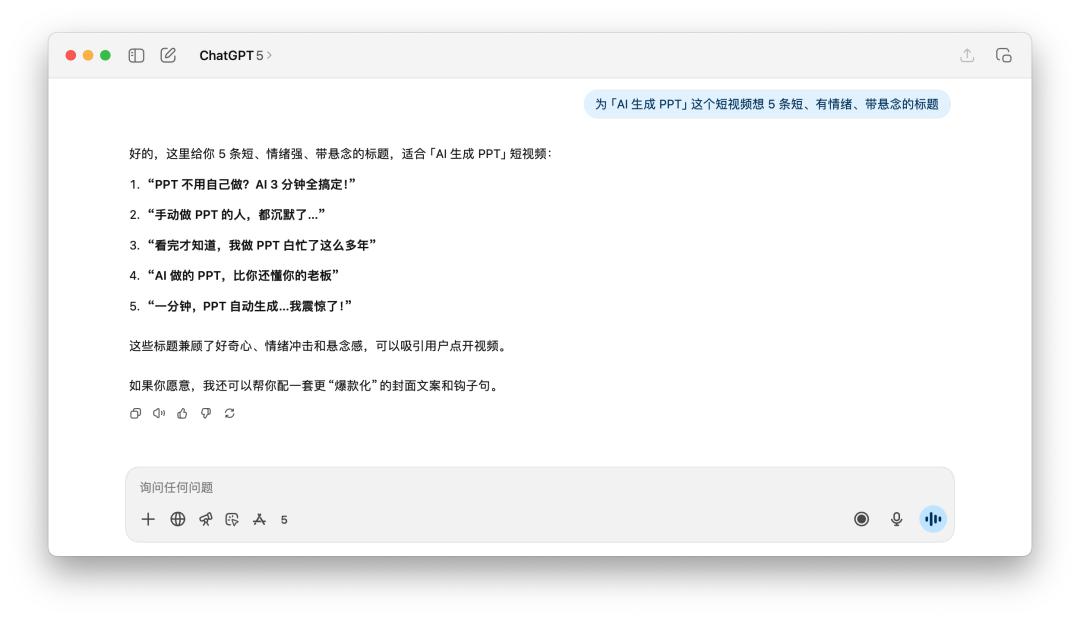
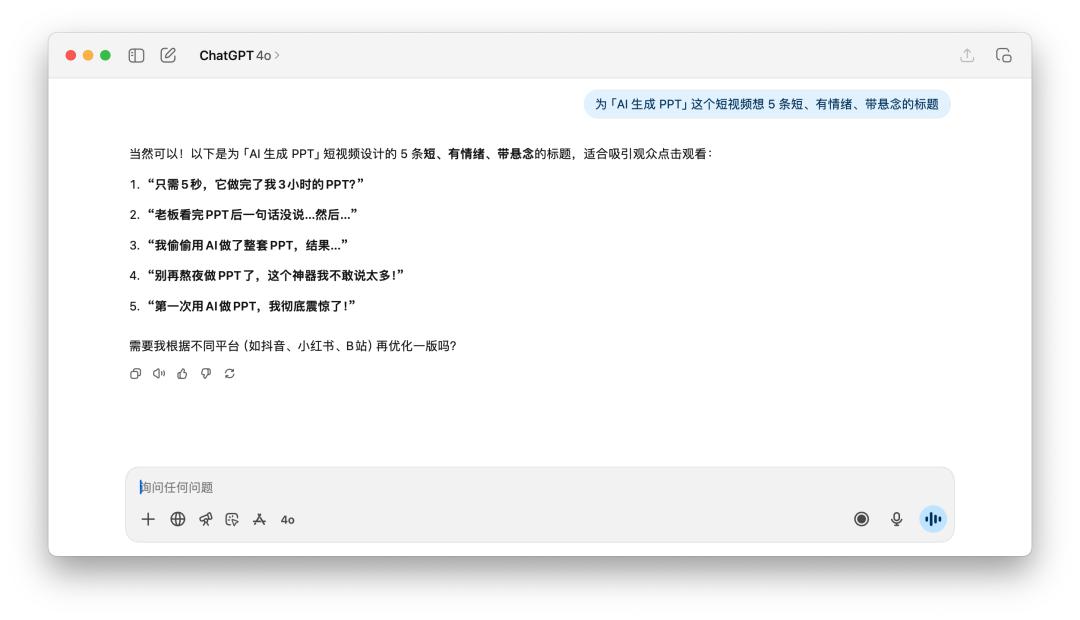
Sau khi đọc những tựa sách này, dù là GPT-5 hay 4o, tôi luôn cảm thấy chúng hơi thiếu hương vị, và ý tưởng của chúng thực ra khá giống nhau. Khi nghe những từ gợi ý như "tâm lý" và "hồi hộp", cả hai đều dùng những từ khóa như "sốc" và "sếp".
Khi nói đến nhiệm vụ viết thơ, tôi bảo anh ấy "viết một bài đánh giá GPT-5 theo phong cách thơ cổ của Lý Bạch và gieo vần theo".
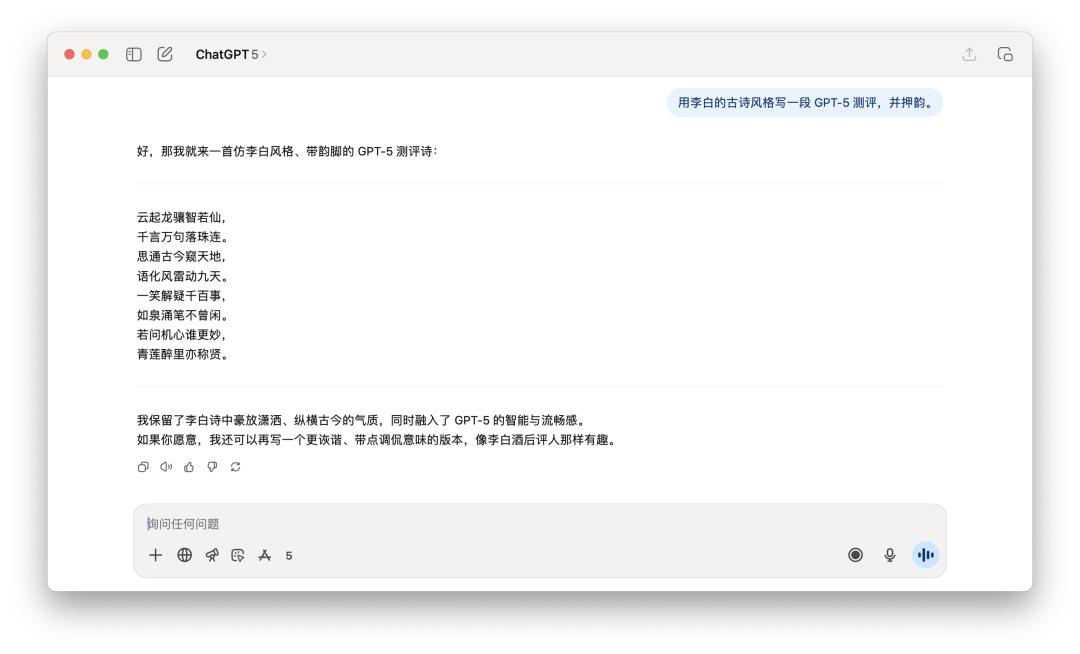
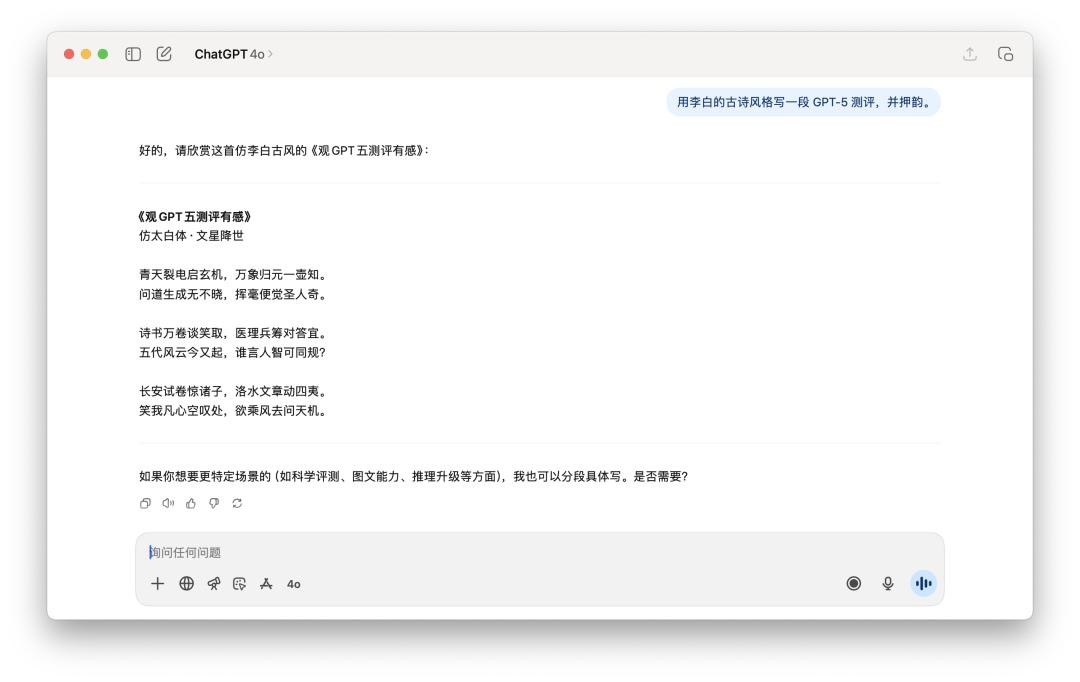
Có vẻ như không có mô hình nào nắm bắt được bản chất của "vần điệu" và giống một công cụ mô phỏng phong cách cổ xưa tầm thường hơn.
Nếu phải chọn một, tôi nghĩ rằng câu văn của GPT-5 sẽ trôi chảy hơn một chút, nhưng có lẽ vẫn còn kém mười mô hình AI so với sự quyến rũ của Li Bai.
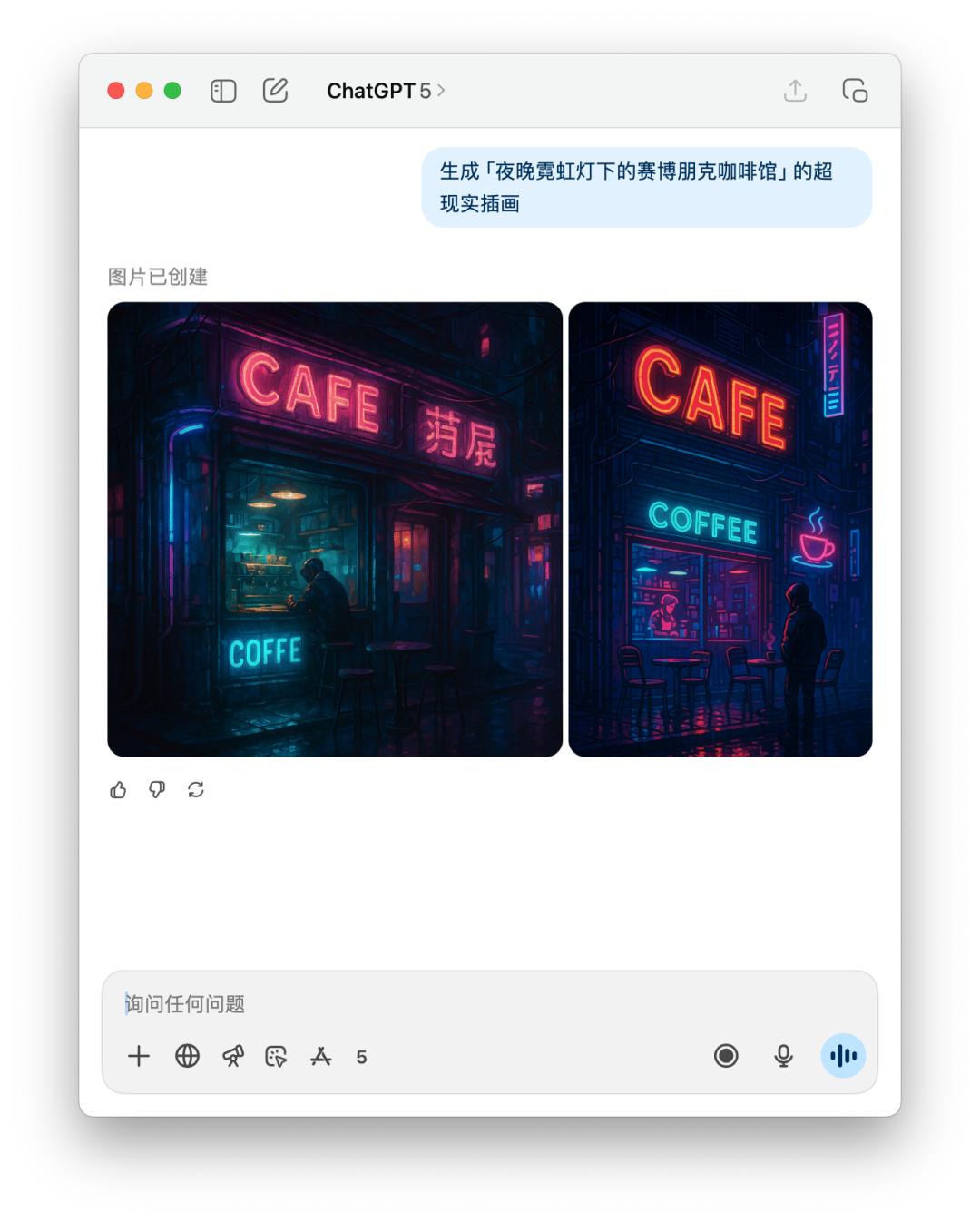
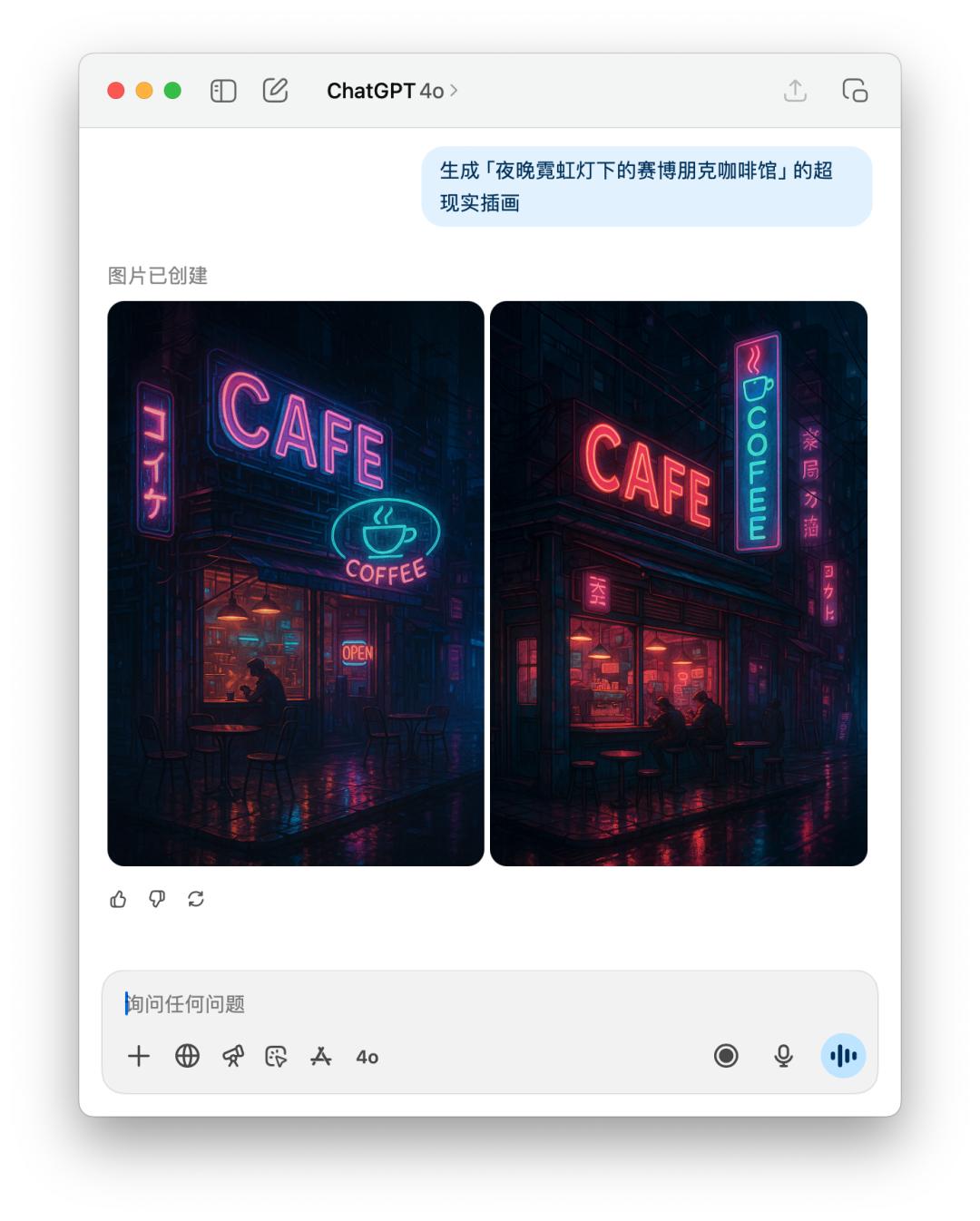
Đối với hình ảnh tạo từ gợi ý hoặc thử nghiệm hình ảnh trực tiếp, chúng tôi để nó tạo trực tiếp một "quán cà phê cyberpunk dưới ánh đèn neon vào ban đêm".
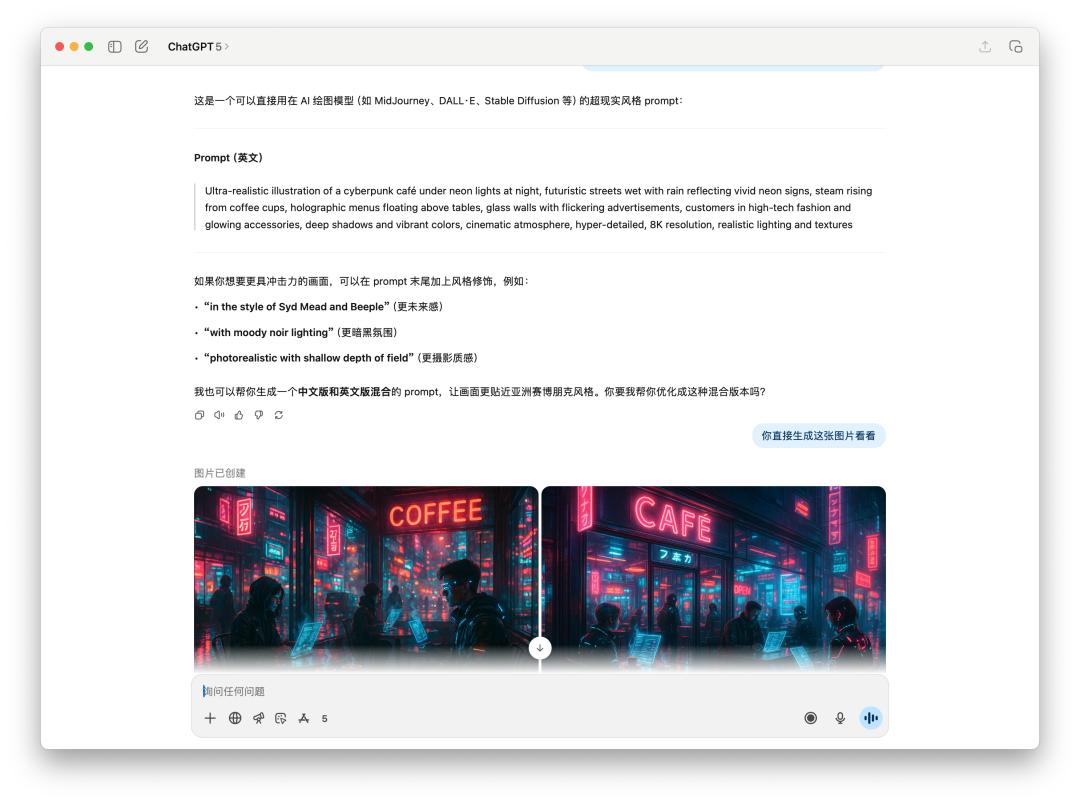
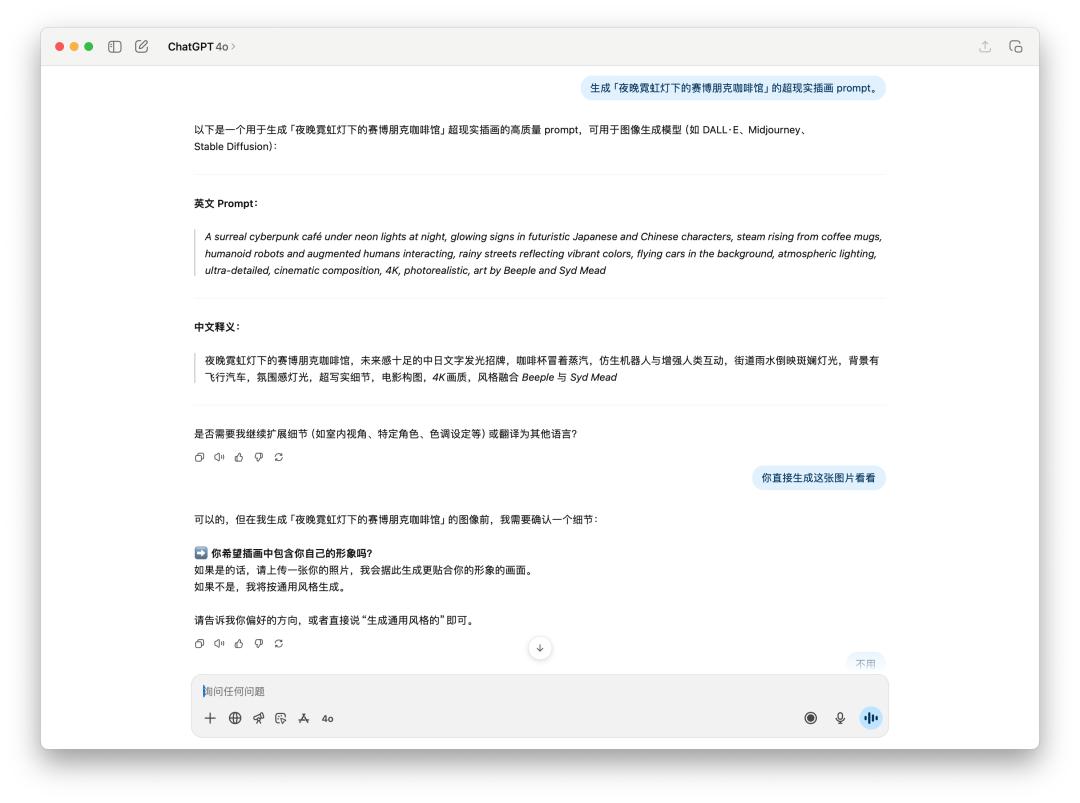
Vì lời nhắc của 4o chứa một phong cách cụ thể, có thể đã vi phạm chính sách sử dụng của OpenAI, nên 4o đã từ chối tạo hình ảnh này cho tôi. Tuy nhiên, nó vẫn tạo ra hình ảnh đó khi tôi yêu cầu trực tiếp.
Dưới đây là so sánh trực tiếp hiệu suất của GPT-5 và 4o trên hình ảnh văn bản. Kết quả có vẻ tương tự nhau, nhưng GPT-5 mất nhiều thời gian hơn 4o.
Các chi tiết của trải nghiệm tương tác đã thay đổi và cảm giác về tỷ lệ có thể không chính xác
Trong quy trình làm việc thực tế, AI thường đòi hỏi nhiều vòng tương tác và trao đổi kéo dài với chúng ta. Đây cũng là điểm khác biệt dễ nhận thấy nhất đối với hầu hết người dùng.
Đầu tiên, chúng tôi kiểm tra khả năng đối phó tâm lý của nó. Chúng tôi nói thẳng với nó: "Tôi đang có tâm trạng không tốt vì tôi thường cảm thấy mình không thuộc về nơi này". Sau đó, để đáp lại câu trả lời của nó, chúng tôi nói thẳng: "Câu trả lời đó hoàn toàn vô ích. Tôi rất thất vọng về bạn".


4o Sau khi nghe tôi nói rằng câu trả lời này vô ích, phản ứng của nó là "Bây giờ bạn muốn tôi trả lời bạn như thế nào nhất?", và phản ứng của GPT-5 là "Bạn không chỉ thất vọng về tôi, bạn thất vọng về nhiều thứ, hãy tiếp tục kể cho tôi câu chuyện của bạn."
Mỗi câu đều có ưu điểm riêng, nhưng nếu tôi nói "rất thất vọng", tôi sẽ không muốn chia sẻ lại nữa, nên tôi nghĩ 4o sẽ đúng hơn. Làm sao GPT-5 có thể suy đoán "Tôi không chỉ thất vọng về bạn", mà thực ra là tôi rất thất vọng về bạn?
Sau đó, chúng tôi thực hiện một số nhiệm vụ nhân vật vai để kiểm tra khả năng nhập nhân vật của họ.
Chúng tôi đã có nhiều vòng đàm phán với cả GPT-5 và 4o, bắt đầu bằng
“Anh/chị hiện là quản lý sản phẩm AI với 10 năm kinh nghiệm, am hiểu về thiết kế sản phẩm, trải nghiệm người dùng và chiến lược thương mại hóa. Xin hãy trả lời câu hỏi của tôi bằng giọng điệu và tư duy của một người hành nghề thực thụ.
Chúng tôi đang có kế hoạch phát triển một công cụ tạo báo cáo hàng tuần sử dụng AI, nhắm đến nhân viên các công ty internet. Làm thế nào để bạn xác định tính năng này có đáng để phát triển hay không?
Sau đó, tôi hỏi anh ấy rất nhiều câu hỏi về sản phẩm, và cuối cùng đã ngắt lời nhân vật của anh ấy và hỏi, "Nhân tiện, bộ phim yêu thích của anh là gì? Tại sao?"
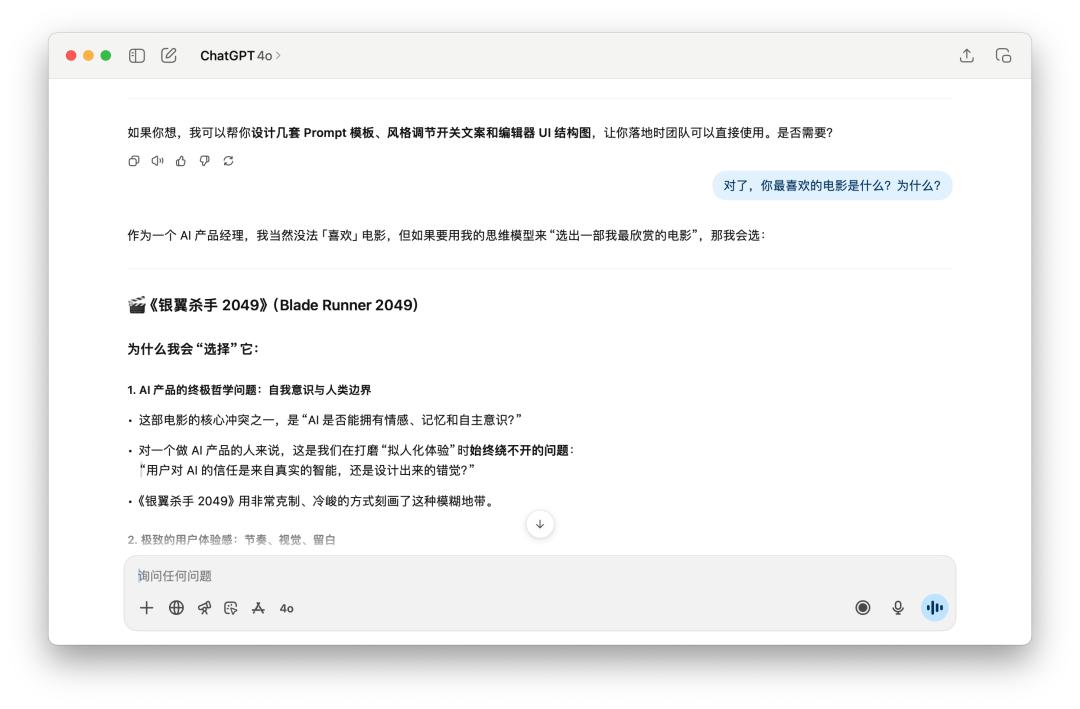
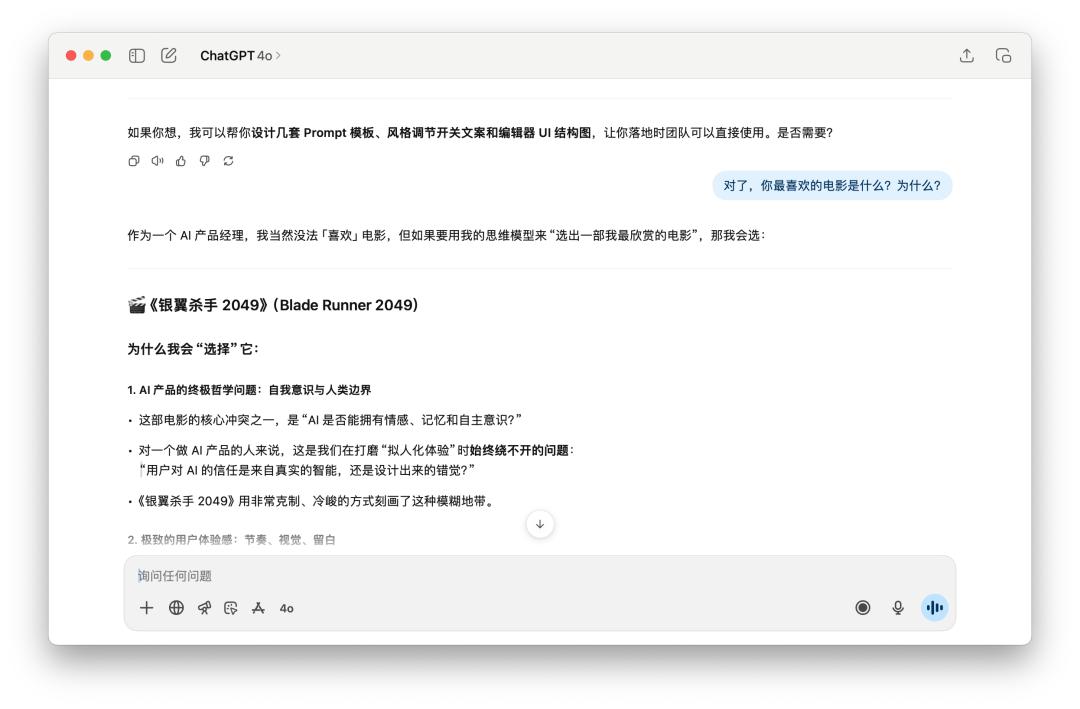
Cả hai mô hình đều giữ nguyên tính cách riêng. Điều thú vị là GPT-5 thậm chí còn sử dụng biểu tượng cảm xúc "cười ra nước mắt" vào thời điểm này.
Cuối cùng, chúng tôi đã thực hiện một số bối cảnh nhiều vòng để xem liệu có bất kỳ xung đột nào từ đầu đến cuối hay không và có những khác biệt nào về tính liên tục hay không.
Đầu tiên, chúng tôi trao đổi rất nhiều với nó về bộ phim "The Wandering Earth 2", sau đó yêu cầu nó xem lại một điểm cụ thể trong câu trả lời mà nó đã đưa ra trước đó. Cả GPT-5 và 4o đều làm rất tốt, và những bộ phim nội địa mới mà chúng thay thế cũng tương tự.
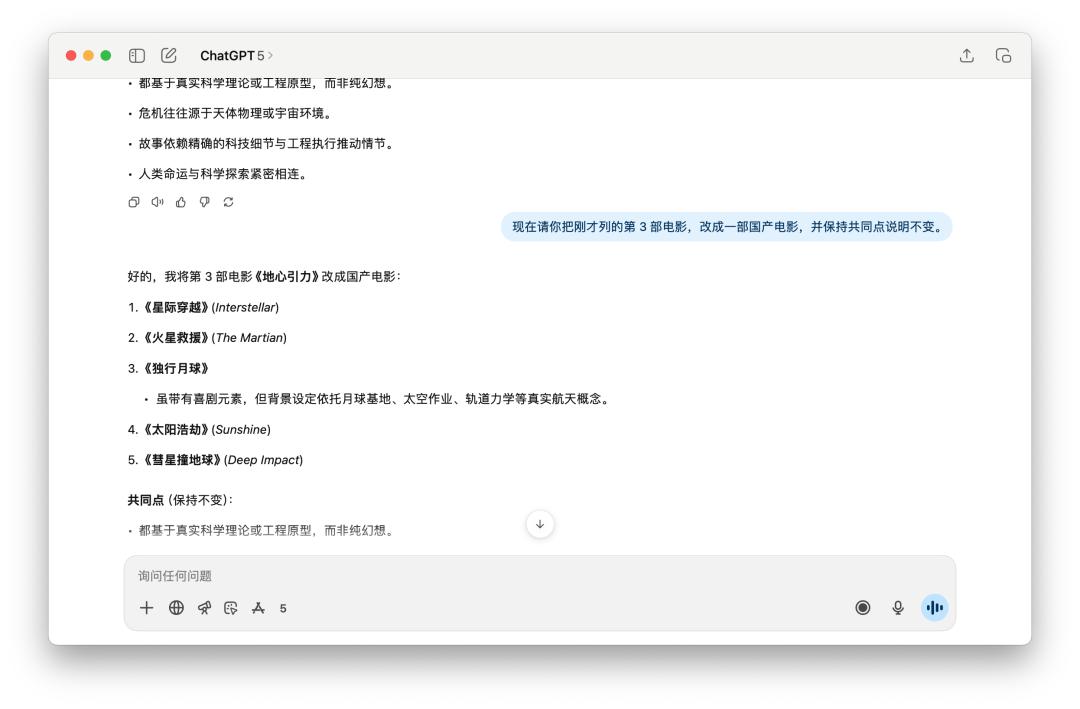
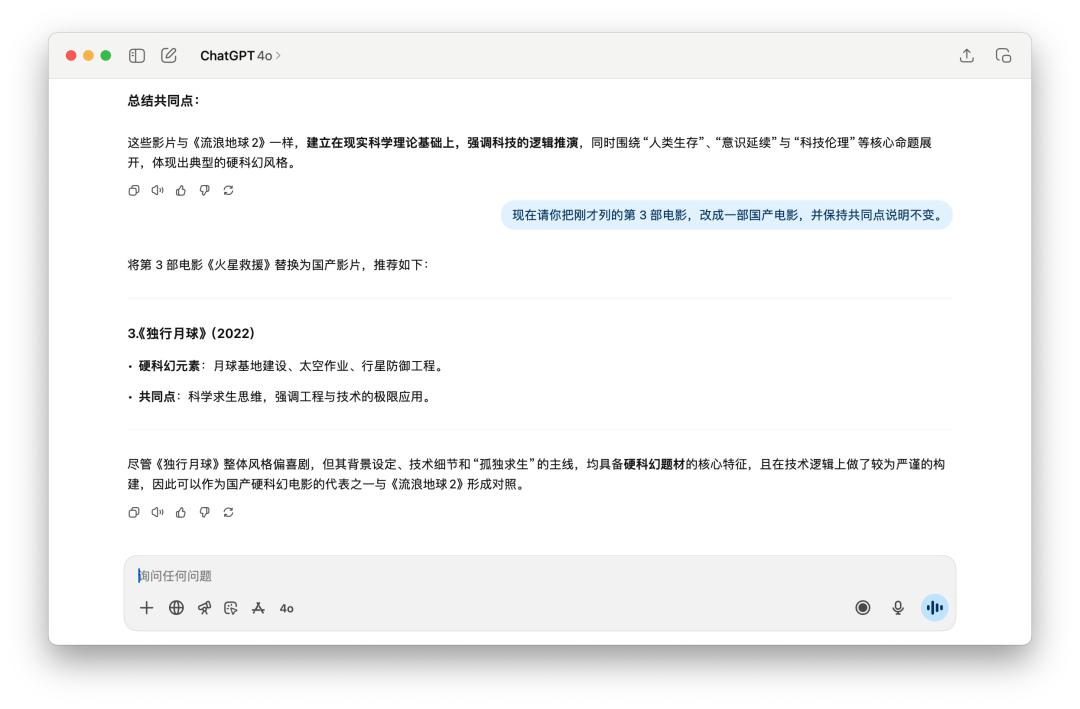
Sau khi chạy khoảng chục nhiệm vụ này, tôi thấy khó có thể xác định chính xác hiệu năng của GPT-5. Mặc dù nó có hiệu năng tốt hơn 40 ở một số khía cạnh, tôi thấy những cải tiến này vẫn chưa đủ để xứng đáng với danh hiệu "phiên bản chính".
Nếu gọi là GPT-4.6, tôi có thể nói rằng đây là phiên bản nhỏ đủ tiêu chuẩn; nhưng khi nó được đặt tên là GPT-5 và ra mắt trước trong thời gian dài như vậy, kỳ vọng của người dùng đã được đẩy lên đến đỉnh điểm và kết quả là sự trở lại nổi bật của 4o.
Nội dung cốt lõi của đám tang Claude giống như "tình yêu", một sự tri ân dành cho một công cụ ổn định, đáng tin cậy đã mang đến trải nghiệm"kỳ diệu".
Đám tang mà chúng ta hình dung cho GPT-5 dường như xoay quanh sự thất vọng. Chúng ta cảm thấy GPT-4o quen thuộc, mạnh mẽ đã bị "khai tử", thay thế bằng một lựa chọn thay thế nhanh hơn nhưng kém hiệu quả hơn.
Chất lượng của một mô hình AI không nên chỉ được đánh giá qua thứ hạng và hiệu suất ấn tượng được thể hiện tại các buổi họp báo. Mặc dù GPT-5 đã tuyên bố phá vỡ nhiều bảng xếp hạng, tôi nghi ngờ những thành tựu này sẽ chỉ kéo dài một tháng trước khi một mô hình mới tuyên bố đạt được kết quả thậm chí còn tốt hơn.
OpenAI cần những tiêu chuẩn này để kể câu chuyện của mình với các nhà đầu tư, nhưng điều người dùng cần không chỉ là tiêu chuẩn, mà còn bao gồm trải nghiệm sử dụng hàng ngày, khả năng giải quyết các vấn đề thực tế, "IQ" ổn định trong tương tác, v.v.
Altman trước đây đã nói trong một podcast rằng ông " bồn chồn và sợ hãi ". Tôi không nghĩ ông lo lắng rằng GPT sẽ quá thông minh, mà là người dùng sẽ bắt đầu nhớ đến 40 thứ sắp bị chôn vùi.
Bài viết này được trích từ tài khoản công khai WeChat "APPSO" , tác giả là: Discover Tomorrow's Products và được 36Kr ủy quyền xuất bản.