

Hiểu rõ chi phí I/O ổ đĩa thực tế của việc tra cứu KV trong hệ thống Blockchain
Nghiên cứu thực nghiệm về Pebble dưới tải trọng công việc thực tế của chuỗi khối
Tóm tắt
Nhiều phân tích blockchain và mô hình hiệu năng giả định rằng việc đọc dữ liệu lưu trữ cặp khóa-giá trị (KV) gây ra độ phức tạp I/O đĩa O(log N) (ví dụ: TrieDB , QMDB ), đặc biệt khi sử dụng các công cụ cây LSM như Pebble hoặc RocksDB. Giả định này bắt nguồn từ kịch bản xấu nhất của việc duyệt cây SST, trong đó việc tra cứu phải truy cập nhiều cấp độ và ở mỗi cấp độ, phải kiểm tra các bộ lọc Bloom, khối chỉ mục và khối dữ liệu.
Tuy nhiên, chúng tôi nhận thấy mô hình này không phản ánh hành vi thực tế. Trên thực tế, bộ nhớ đệm thường lưu trữ hầu hết các khối lọc và chỉ mục, điều này có thể giảm đáng kể số lượng thao tác I/O.
Để hiểu rõ hành vi I/O đĩa thực tế của các cơ sở dữ liệu dựa trên LSM trong điều kiện bộ nhớ đệm thực tế, chúng tôi tiến hành các thí nghiệm có kiểm soát rộng rãi bằng cách sử dụng Pebble làm công cụ đại diện, bao gồm các tập dữ liệu từ 22 GB đến 2,2 TB ( 200 triệu đến 20 tỷ khóa ), và nhận thấy rằng:
- Khi các bộ lọc Bloom (ngoại trừ LLast ) và Top-Index nằm gọn trong bộ nhớ cache, hầu hết các thao tác tìm kiếm phủ định sẽ không phát sinh I/O đĩa nào , và số I/O cho mỗi thao tác Get sẽ nhanh chóng giảm xuống còn khoảng 2.
(Đọc 1 khối chỉ mục và đọc 1 khối dữ liệu). - Khi tất cả các khối chỉ mục cũng nằm trong bộ nhớ cache , số thao tác I/O trên mỗi thao tác Get sẽ hội tụ hơn nữa về khoảng 1,0–1,3 , hầu như không phụ thuộc vào kích thước tổng thể của cơ sở dữ liệu.
- Việc lưu trữ dữ liệu theo khối chỉ có tác động nhỏ đến hiệu suất I/O tổng thể trong điều kiện xử lý đọc ngẫu nhiên thuần túy.
Nhìn chung, khi bộ nhớ đệm đủ để chứa các bộ lọc Bloom (ngoại trừ LLast) và Top-Index
— chiếm khoảng ~0,1%–0,2% tổng kích thước cơ sở dữ liệu dưới các khối lượng công việc giống như blockchain, Pebble thể hiện hành vi I/O đĩa hiệu quả O(1) đối với các thao tác đọc ngẫu nhiên , thách thức quan điểm phổ biến
Giả định rằng mỗi lần tra cứu KV vốn dĩ tiêu tốn O(log N) I/O vật lý. Điều này có tác động trực tiếp đến việc mô hình hóa hiệu năng và thiết kế cơ sở dữ liệu cây trie blockchain và hệ thống lưu trữ lớp thực thi.
Động lực
Các lớp thực thi blockchain thường phụ thuộc vào kho lưu trữ KV dạng cây LSM để phục vụ hàng tỷ khóa được truy cập ngẫu nhiên. Một giả định phổ biến là:
“Mỗi lần tra cứu KV trong cây LSM tốn
O(log N)thao tác I/O đĩa.”
Tuy nhiên, trong các hệ thống blockchain thực tế, những giả định này thường không đúng. Các công cụ KV dựa trên LSM hiện đại như Pebble phụ thuộc rất nhiều vào:
- Bộ lọc Bloom loại bỏ hầu hết các tìm kiếm tiêu cực;
- Cấu trúc chỉ mục nhỏ, có khả năng tái sử dụng cao;
- Bộ nhớ đệm khối và bộ nhớ đệm trang của hệ điều hành giúp lưu trữ siêu dữ liệu được truy cập thường xuyên trong bộ nhớ.
Do đó, hành vi I/O vật lý thực tế của việc tra cứu KV thường bị giới hạn bởi một hằng số nhỏ (≈1–2 I/O), và trở nên phần lớn không phụ thuộc vào kích thước tổng thể của cơ sở dữ liệu một khi các bộ lọc Bloom và khối chỉ mục nằm gọn trong bộ nhớ cache.
Những quan sát này đặt ra một câu hỏi thực tiễn quan trọng:
Trong các kịch bản blockchain thực tế, chi phí I/O ổ đĩa thực tế cho việc tra cứu KV ngẫu nhiên là bao nhiêu?
Nghiên cứu này nhằm mục đích trả lời câu hỏi này bằng các phép đo thực nghiệm trực tiếp, để:
- Xác nhận hoặc thách thức giả định phổ biến về tra cứu KV
O(log N), - Xác định lượng bộ nhớ đệm thực sự cần thiết để đạt được tốc độ đọc/ghi dữ liệu gần như không đổi.
- Đưa ra các khuyến nghị dựa trên kinh nghiệm về kích thước bộ nhớ đệm cho các hệ thống lưu trữ KV bền vững ở lớp thực thi blockchain, bao gồm cây trạng thái và kho lưu trữ KV ảnh chụp nhanh.
Cách chúng tôi xác thực giả thuyết
Phần này mô tả cách chúng tôi xác thực giả thuyết rằng, trong điều kiện bộ nhớ đệm thực tế, chi phí I/O đọc thực tế của Pebble chủ yếu được chi phối bởi thời gian lưu trữ siêu dữ liệu trong bộ nhớ đệm chứ không phải bởi độ sâu của cây LSM như được đề xuất bởi các mô hình O(log N) trường hợp xấu nhất. Trước tiên, chúng tôi xem xét đường dẫn đọc của Pebble để xác định các nguồn I/O cụ thể, sau đó giới thiệu hai điểm uốn do bộ nhớ đệm điều khiển đặc trưng cho sự thay đổi chi phí I/O trong hành vi đọc. Cuối cùng, chúng tôi phác thảo thiết lập thí nghiệm được sử dụng để quan sát các giai đoạn này một cách thực nghiệm và định lượng tác động của chúng đến số lượng I/O trên mỗi lần lấy dữ liệu .
Hiểu về Pebble
Đọc đường dẫn và nguồn I/O của Pebble
Thao tác Get trong Pebble diễn ra như sau:
1. Lookup MemTable / Immutable MemTables and return value if found ( in memory) 2. Lookup MANIFEST to find candidate SST files ( in memory) 3. For each SST:a) Load Top - level index at reader initialization (used to locate internal index blocks after filter check )b) Table - level Bloom filter check ( except LLast) → skip SST if key absentc) Internal index block lookup → locate data blockd) Data block lookup → read value and returnĐường dẫn đọc ở trên tham chiếu đến một số thành phần nội bộ xuất hiện xuyên suốt bài báo này. Chúng tôi sẽ giới thiệu ngắn gọn chúng ở đây để dễ hiểu hơn.
Chỉ số cấp cao nhất (viết tắt là Top-Index)
Một chỉ mục cấp cao nhỏ gọn cho mỗi SST trỏ đến các khối chỉ mục nội bộ.
Thông tin này được truy cập trong hầu hết mọi lần tìm kiếm và thường được lưu trữ đầy đủ trong bộ nhớ cache.
Khối chỉ mục nội bộ (viết tắt là Khối chỉ mục)
Chỉ mục các khối bên trong mỗi SST ánh xạ các phạm vi khóa tới các khối dữ liệu.
Chúng được truy cập sau khi kiểm tra bộ lọc thành công và có thể phát sinh một thao tác I/O ổ đĩa nếu không được lưu vào bộ nhớ đệm.
Cuối cùng
Cấp độ sâu nhất của cây LSM. Nó lưu trữ hầu hết dữ liệu và không sử dụng bộ lọc Bloom trong quá trình tra cứu.
Do đó, các truy vấn đến LLast sẽ đi theo toàn bộ đường dẫn: Chỉ mục cấp cao nhất → khối chỉ mục → khối dữ liệu .
Tại sao bộ lọc lại loại trừ LLast?
Việc sử dụng bộ lọc Bloom cho LLast sẽ quá lớn, tốn kém để duy trì trong bộ nhớ cache và mang lại lợi ích hạn chế trong thực tế vì hầu hết các tìm kiếm tích cực cuối cùng đều truy vấn LLast bất kể thế nào. Do đó, Pebble không sử dụng bộ lọc Bloom cho LLast.
Hai điểm uốn thực tiễn của bộ nhớ đệm
Từ đường dẫn đọc được mô tả ở trên, rõ ràng là thao tác Get liên tục tham khảo một tập hợp nhỏ và được xác định rõ các thành phần siêu dữ liệu. Việc các thành phần này có nằm trong bộ nhớ cache hay không sẽ trực tiếp quyết định phần nào của đường dẫn đọc phát sinh I/O vật lý. Dựa trên quan sát này và tổng dung lượng bộ nhớ cache của mỗi lớp siêu dữ liệu, chúng tôi định nghĩa hai ngưỡng kích thước bộ nhớ cache — được gọi là điểm uốn của bộ nhớ cache — đóng vai trò là cơ sở để phân tích hành vi I/O đọc trong các phần tiếp theo.
Điểm uốn 1 — Filter + Top-Index
Bộ nhớ cache có thể chứa:
- Tất cả các bộ lọc Bloom (không phải LLast)
- Tất cả các khối Top-Index
→ Tra cứu phủ định hầu như luôn được giải quyết trong bộ nhớ.
Điểm uốn 2 — Filter + All-Index
Bộ nhớ cache có thể chứa:
- Tất cả các bộ lọc Bloom (không phải LLast)
- Tất cả các khối chỉ mục trên tất cả các cấp độ
→ Tra cứu tích cực giúp tránh lỗi chỉ mục và giảm thiểu thao tác I/O.
Định nghĩa các thành phần
- Bộ lọc: Bộ lọc Bloom cho tất cả các cấp độ không phải LLast
- Chỉ mục hàng đầu: Tất cả các khối chỉ mục cấp cao nhất theo SST
- Tất cả chỉ mục: Chỉ mục đầu trang + tất cả các khối chỉ mục nội bộ
Ba giai đoạn hoạt động I/O đọc dựa trên bộ nhớ đệm
Dựa trên hai điểm uốn của bộ nhớ đệm được xác định ở trên, chúng tôi chia kích thước bộ nhớ đệm thành ba giai đoạn và mô tả hành vi I/O đọc dự kiến trong mỗi giai đoạn.
Giai đoạn 1 —
Cache Size < Inflection Point 1
Việc bỏ sót các bộ lọc và chỉ mục hàng đầu xảy ra thường xuyên → nhiều lần kiểm tra SST không cần thiết → chi phí I/O đọc dự kiến cao hơn .Giai đoạn 2 —
Inflection Point 1 < Cache Size < Inflection Point 2
Bộ lọc và chỉ mục hàng đầu được lưu vào bộ nhớ đệm → các tìm kiếm phủ định phần lớn được giải quyết trong bộ nhớ → hoạt động đọc/ghi dự kiến sẽ giảm khi các khối chỉ mục bắt đầu nằm trong bộ nhớ đệm.Giai đoạn 3 —
Cache Size > Inflection Point 2
Các bộ lọc và tất cả các khối chỉ mục đều được lưu vào bộ nhớ đệm → hoạt động I/O còn lại dự kiến chủ yếu đến từ các khối dữ liệu → hiệu quả giảm dần sau điểm này.
Thiết lập thí nghiệm
Phần này mô tả phương pháp thực nghiệm được sử dụng để đánh giá hành vi I/O đọc ngẫu nhiên thực tế của Pebble dưới các khối lượng công việc tương tự như blockchain. Nó tóm tắt môi trường thử nghiệm, tập dữ liệu, khối lượng công việc và các chỉ số được sử dụng để đo lường thời gian lưu trữ bộ nhớ cache và I/O trên mỗi lần truy xuất , tập trung vào hành vi đọc ngẫu nhiên ở trạng thái ổn định.
Phần cứng và phần mềm
- CPU: 32 lõi
- Bộ nhớ: 128 GB
- Ổ cứng: 7 TB NVMe RAID0
- Hệ điều hành: Ubuntu
- Công cụ lưu trữ: Pebble v1.1.5
Lưu ý: Tất cả các thí nghiệm đều được thực hiện trên Pebble v1.1.5. Hành vi đường dẫn đọc, bố cục bộ lọc hoặc hành vi bộ nhớ đệm có thể khác nhau trên Pebble v2 trở lên và cần được đánh giá riêng.
Tất cả mã kiểm chuẩn, công cụ đo lường của Pebble và nhật ký thí nghiệm thô đều được công khai.
Có sẵn tại bench_kvdb để kiểm tra khả năng tái tạo kết quả.
Tập dữ liệu
| Tập dữ liệu | Bé nhỏ | Trung bình | Lớn |
|---|---|---|---|
| Chìa khóa | 200 triệu khóa | 2B Keys | 20B Keys |
| Kích thước DB | 22 GB | 224 GB | 2,2 TB |
| Số lượng tệp | 1418 | 7105 | 34647 |
| Bộ lọc + Chỉ mục hàng đầu | 32 MB (0,14%) | 284 MB (0,12%) | 2,52 GB (0,11%) |
| Bộ lọc (bao gồm cả LLast) | 238 MB | 2,3 GB | 23 GB |
| Chỉ mục toàn diện | 176 MB | 1,7 GB | 18 GB |
| Bộ lọc + Chỉ mục toàn bộ | 207 MB (0,91%) | 2.0 GB (0.89%) | 20,5 GB (0,91%) |
Khóa: Mã băm 32 byte
Giá trị: 110 byte (xấp xỉ kích thước RLP trung bình của các nút cây trie geth)
Khối lượng công việc
- Đọc ngẫu nhiên
- 10 triệu lượt thực hiện mỗi lần kiểm tra
- Khởi động: 0,05% không gian phím
- Không có quét phạm vi
- Không có thao tác ghi dữ liệu lớn hoặc nén dữ liệu đồng thời.
Ghi chú.
Tất cả các thí nghiệm đều tập trung vào khối lượng công việc đọc ngẫu nhiên thuần túy ở trạng thái ổn định trên một nút duy nhất, không có các thao tác ghi nặng đồng thời, áp lực nén dữ liệu hoặc quét phạm vi.
Số liệu
Chúng tôi dựa vào số liệu thống kê nội bộ của Pebble để mô tả hành vi đọc, bao gồm:
- Tỷ lệ kích hoạt bộ lọc Bloom
- Tỷ lệ truy cập chỉ số hàng đầu
- Tỷ lệ truy cập khối chỉ mục
- Tỷ lệ truy cập khối dữ liệu
- Tỷ lệ truy cập bộ nhớ đệm khối tổng thể
- Số lượng I/O trên mỗi lần lấy dữ liệu — chỉ số mục tiêu cuối cùng
Trong Pebble, tất cả các khối dữ liệu (khối bộ lọc, Top-Index, chỉ mục và dữ liệu) đều được đọc trong quá trình thao tác Get
Dữ liệu được định tuyến qua BlockCache. Mỗi lần tra cứu đều tham khảo bộ nhớ đệm trước tiên, và việc không tìm thấy dữ liệu trong BlockCache thường dẫn đến một lần đọc vật lý duy nhất với sự can thiệp tối thiểu từ việc đọc trước và nén dữ liệu.
trong đó BlockCacheMiss là tổng số lần truy cập bộ nhớ đệm khối bị lỗi trên tất cả các loại khối.
(Bộ lọc Bloom, khối Top-Index, khối chỉ mục và khối dữ liệu), và GetCount là số lượng thao tác Get đã hoàn thành được đo lường.
Do đó, BlockCacheMiss theo sát áp lực đọc vật lý thực tế và cung cấp một thước đo ổn định, phù hợp với cách triển khai về chi phí I/O cho mỗi lần tra cứu.
Kết quả
Trước tiên, chúng tôi phân tích ảnh hưởng của kích thước bộ nhớ cache đến tỷ lệ truy cập thành công của các bộ lọc Bloom, các khối Top-Index và các khối chỉ mục. Sau đó, chúng tôi chỉ ra cách những ảnh hưởng này tác động đến tỷ lệ truy cập thành công tổng thể của bộ nhớ cache khối và cuối cùng là chỉ số I/O trên mỗi lần lấy dữ liệu.
Trong phần này, Điểm uốn 1 (IP1) đề cập đến kích thước bộ nhớ cache cần thiết để chứa tất cả các bộ lọc Bloom không phải LLast và các khối Top-Index (khoảng 0,11%–0,14% kích thước cơ sở dữ liệu trong các tập dữ liệu thử nghiệm của chúng tôi), trong khi Điểm uốn 2 (IP2) đề cập đến kích thước bộ nhớ cache cần thiết để chứa tất cả các bộ lọc Bloom không phải LLast và tất cả các khối chỉ mục (khoảng ~0,9% kích thước cơ sở dữ liệu trong các tập dữ liệu thử nghiệm của chúng tôi).
Bộ lọc Bloom & Tỷ lệ truy cập chỉ mục hàng đầu
| Kích thước bộ nhớ đệm | Bộ dữ liệu nhỏ (Lọc theo tỷ lệ truy cập) | Bộ dữ liệu cỡ trung bình (Lọc theo tỷ lệ truy cập) | Tập dữ liệu lớn (Lọc theo tỷ lệ truy cập) | Bộ dữ liệu nhỏ (Tỷ lệ truy cập chỉ mục hàng đầu) | Bộ dữ liệu cỡ trung bình (Tỷ lệ truy cập chỉ mục hàng đầu) | Tập dữ liệu lớn (Tỷ lệ truy cập chỉ mục hàng đầu) |
|---|---|---|---|---|---|---|
| Tại IP1 | 98,5% | 99,6% | 98,9% | 96,4% | 97,8% | 95,4% |
| Ngoài IP1 (≈0,2% DB) | 100% | 100% | 100% | 100% | 100% | 100% |
Khi bộ nhớ đệm vượt qua Điểm uốn 1 , cả bộ lọc Bloom và Chỉ mục hàng đầu đều đạt tỷ lệ truy cập gần 100% và các tìm kiếm phủ định được giải quyết trong bộ nhớ.
Tỷ lệ truy cập khối chỉ mục
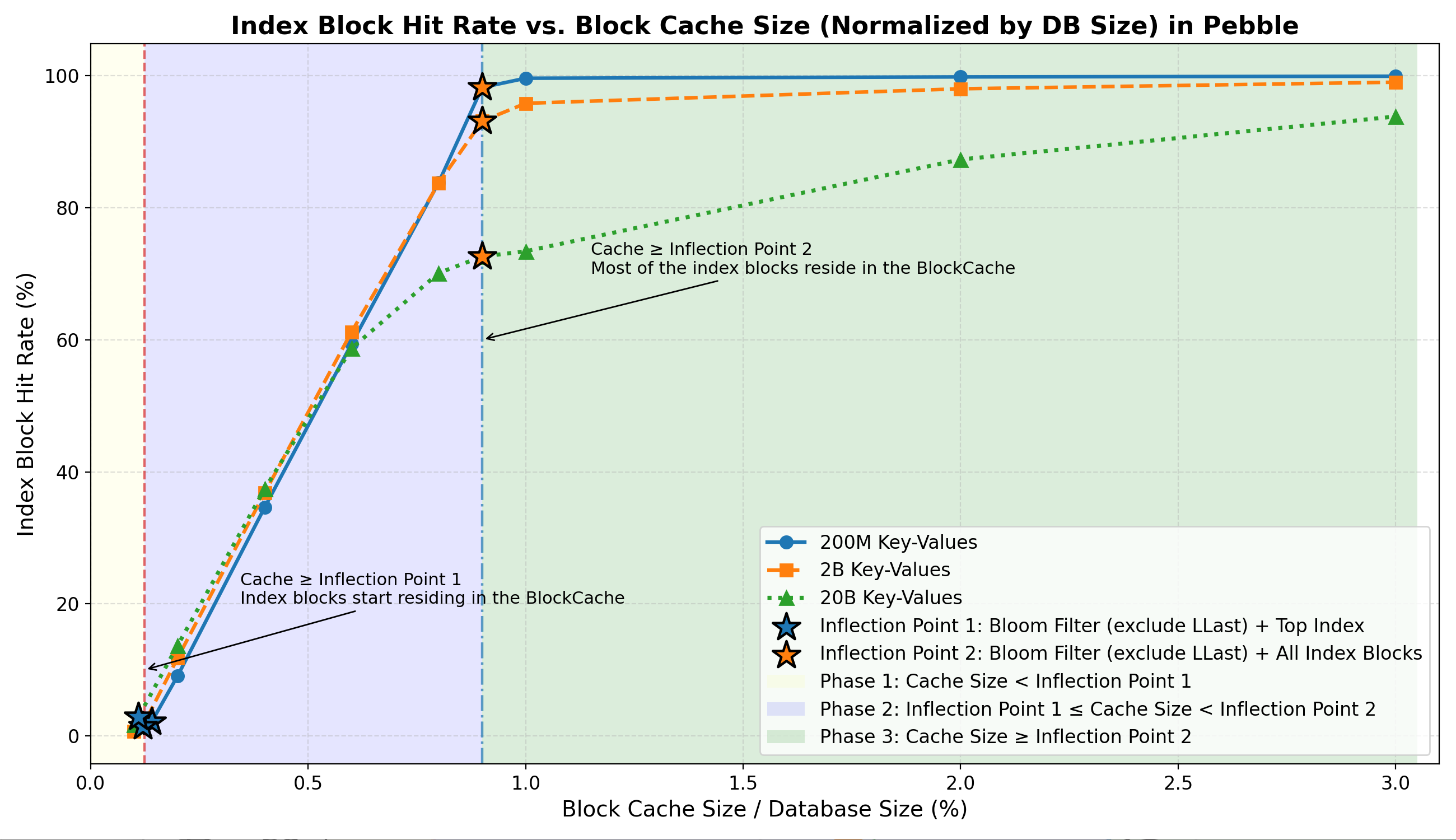
- Giai đoạn 1: Rất ít khối chỉ mục được lưu vào bộ nhớ đệm (có thể khoảng ~1%–3% ).
- Giai đoạn 2: Tỷ lệ truy cập thành công tăng mạnh lên khoảng 70–99% khi bộ nhớ đệm tiến gần đến Điểm uốn 2 .
- Giai đoạn 3: Hầu hết các khối chỉ mục nằm trong bộ nhớ và tỷ lệ truy cập đạt mức cao ổn định (~70%–99%) với mức tăng thêm không đáng kể.
Tỷ lệ truy cập khối dữ liệu
| Kích thước bộ nhớ đệm | Bộ dữ liệu nhỏ (Tỷ lệ truy cập khối dữ liệu) | Bộ dữ liệu cỡ trung bình (Tỷ lệ truy cập khối dữ liệu) | Tập dữ liệu lớn (Tỷ lệ truy cập khối dữ liệu) |
|---|---|---|---|
| Tại IP1 | 1,0% | 0,7% | 1,3% |
| Ngoài IP1 (≈0,2% DB) | 1,2% | 0,9% | 1,6% |
| Tại IP2 | 1,4% | 1,1% | 2,4% |
| Ngoài IP2 (≈3% DB) | 3,2% | 3,0% | 4,3% |
Trong cả ba giai đoạn, tỷ lệ truy cập khối dữ liệu vẫn duy trì ở mức thấp, bộ nhớ đệm khối dữ liệu đóng góp rất ít vào việc giảm I/O được quan sát thấy trong các tác vụ đọc ngẫu nhiên.
Tỷ lệ truy cập bộ nhớ đệm khối tổng thể
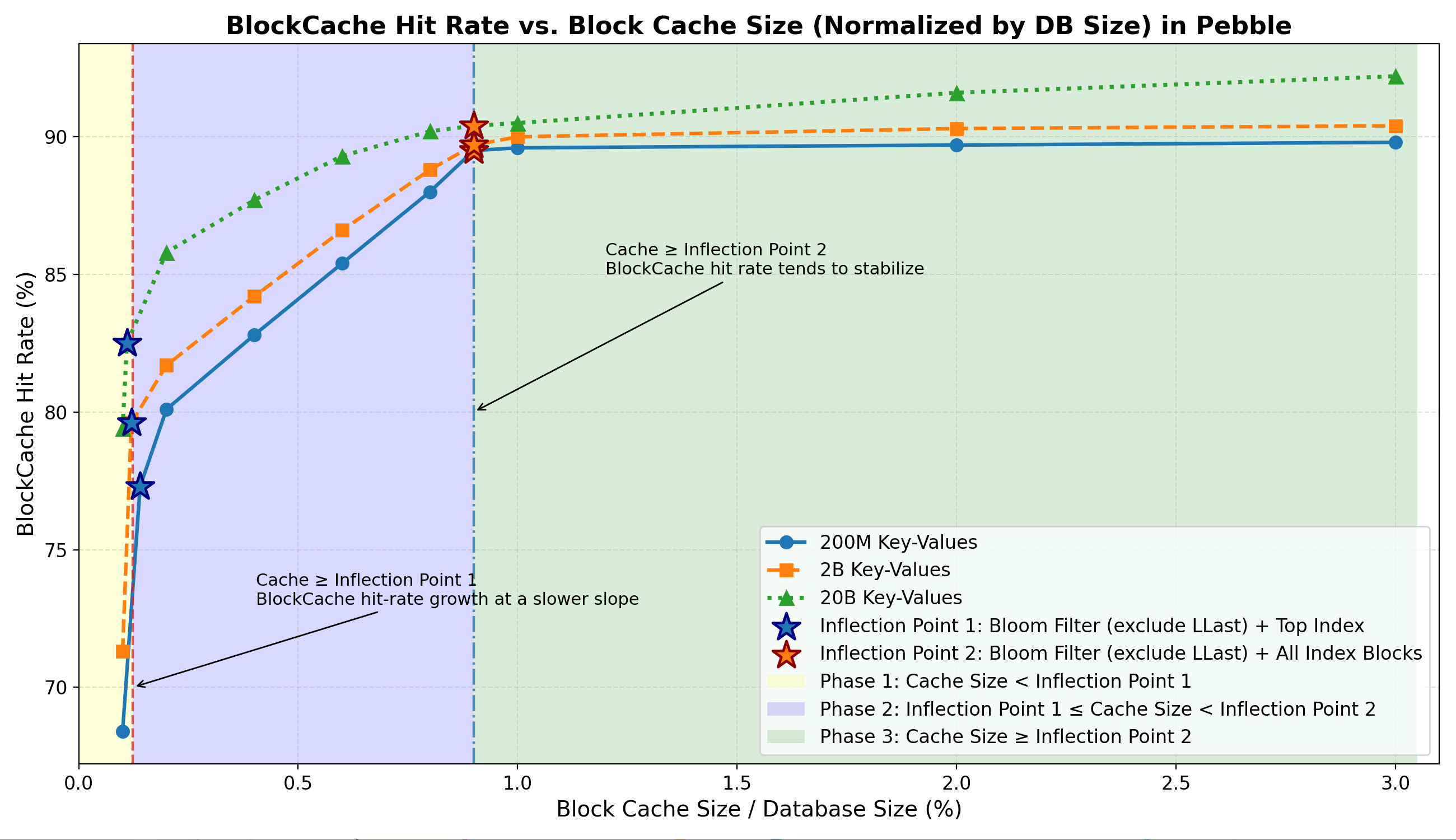
- Giai đoạn 1: Tỷ lệ truy cập tăng mạnh, nhờ vào khả năng lưu trữ nhanh chóng các bộ lọc Bloom và Top Index trong bộ nhớ .
- Giai đoạn 2: Tỷ lệ truy cập tăng chậm hơn do các khối chỉ số trở thành cư dân thường trú.
- Giai đoạn 3: Tỷ lệ truy cập ổn định , vì bộ nhớ đệm khối dữ liệu đóng góp rất ít vào khối lượng công việc đọc ngẫu nhiên.
Chi phí đọc I/O cho mỗi lần truy xuất (Kết quả chính)
Phần này tóm tắt cách mà thời gian lưu trữ trong bộ nhớ cache của các thành phần siêu dữ liệu khác nhau cuối cùng ảnh hưởng đến chi phí I/O đọc ngẫu nhiên từ đầu đến cuối.
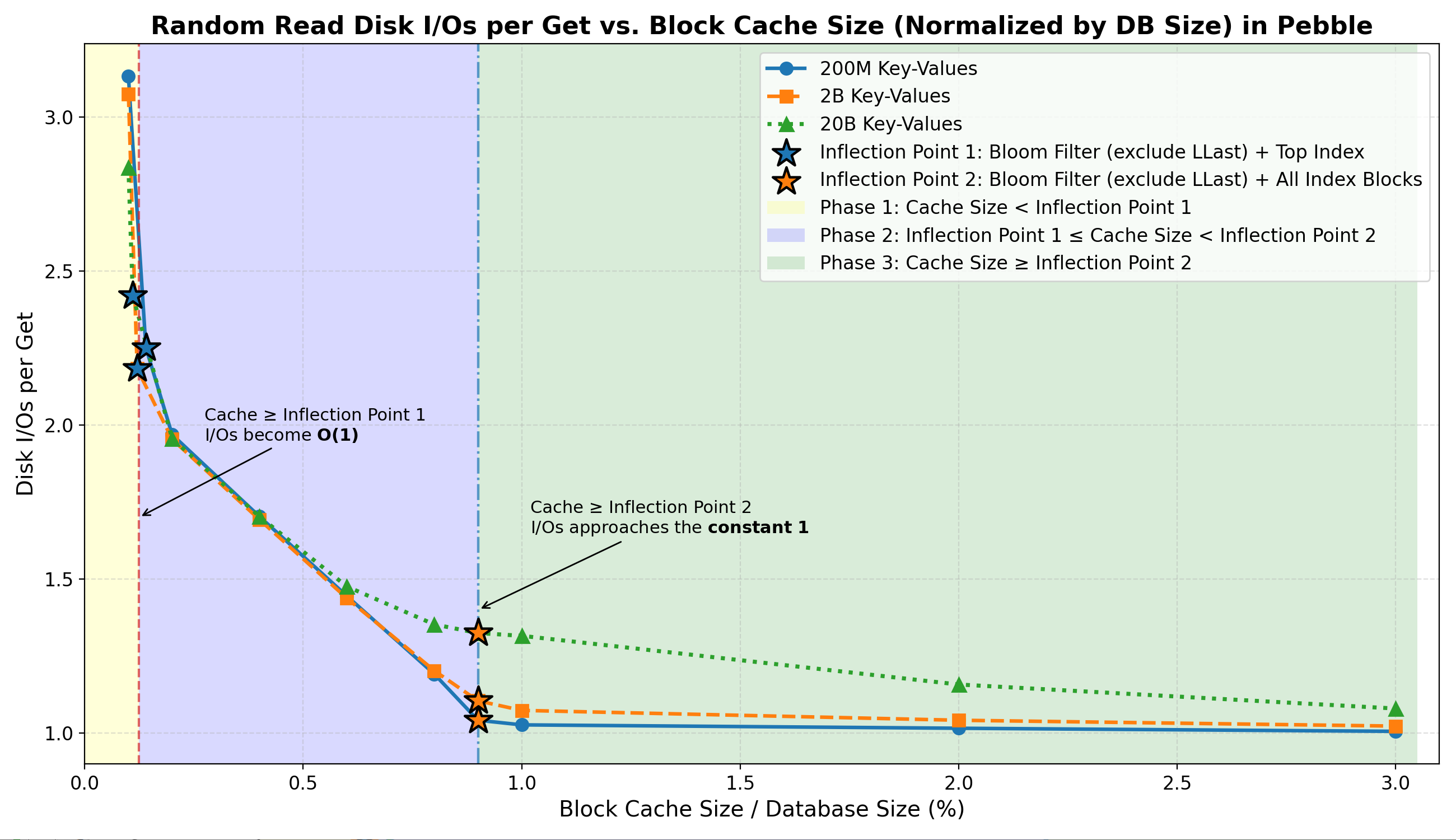
- Điểm uốn 1 (
Filter + Top-Index)
Khi bộ nhớ đệm đạt đến điểm này:- Tỷ lệ truy cập thành công của Filter & Top Index đạt khoảng 100% .
- Hầu hết các tìm kiếm phủ định đều được giải quyết hoàn toàn trong bộ nhớ .
- Số lần đọc ngẫu nhiên
I/Os per Getổn định ở mức ~2,2–2,4 ( thực tế là O(1) tra cứu ).
- Giai đoạn 2 (giữa hai điểm uốn)
Trong vùng chuyển tiếp này:- Tỷ lệ cư trú trong khối chỉ số tăng nhanh và tỷ lệ trúng khối chỉ số tăng mạnh lên khoảng 70%–99% .
- Số lượng thao tác I/O trên mỗi lần lấy dữ liệu giảm mạnh xuống còn 1.0–1.3.
- Điểm uốn 2 (
Filter + All-Index)
Từ điểm này trở đi:- Số lần đọc ngẫu nhiên
I/Os per Getsẽ tiến gần đến giới hạn dưới chặt chẽ ~1 . - Việc mở rộng bộ nhớ cache hơn nữa chỉ mang lại sự giảm thiểu I/O không đáng kể .
- Số lần đọc ngẫu nhiên
- Việc lưu trữ dữ liệu vào bộ nhớ đệm vẫn không đáng kể trong tất cả các giai đoạn.
- Hành vi này nhất quán trên các kích thước tập dữ liệu khác nhau (22 GB – 2,2 TB):
Điều này xác nhận:
Nhìn chung, hoạt động đọc/ghi ngẫu nhiên chủ yếu được điều chỉnh bởi bộ lọc Bloom và thời gian lưu trú của chỉ mục.
Kết luận và khuyến nghị
Mặc dù độ phức tạp đọc lý thuyết trong trường hợp xấu nhất của Pebble là O(log N) , nhưng giới hạn này hiếm khi được quan sát thấy trong thực tế với các cấu hình bộ nhớ đệm thực tế.
Với thời gian lưu trữ bộ nhớ đệm đủ của các bộ lọc Bloom (không bao gồm LLast) và các khối chỉ mục, hành vi I/O đọc thực tế của Pebble có hiệu quả là O(1) và luôn hội tụ về 1–2 I/O cho mỗi thao tác Get .
Các đề xuất về cấu hình bộ nhớ đệm
Kết quả của chúng tôi cho thấy chi phí I/O đọc của Pebble chủ yếu được quyết định bởi các thành phần siêu dữ liệu nào phù hợp với bộ nhớ cache , chứ không phải bởi độ sâu của cây LSM. Trên thực tế, kích thước bộ nhớ cache do đó có thể được lựa chọn trực tiếp dựa trên hiệu suất đọc mong muốn.
Hiệu suất đọc gần như không đổi (~2 thao tác I/O mỗi lần truy xuất)
Bộ nhớ đệm vượt quá Điểm uốn 1 (Bộ lọc Bloom loại trừ các khối LLast + Top-Index).
Điều này chỉ yêu cầu một bộ nhớ đệm rất nhỏ (thường < 0,2% kích thước cơ sở dữ liệu ) và loại bỏ hầu hết các thao tác I/O tìm kiếm phủ định.
Thích hợp cho các triển khai có bộ nhớ hạn chế yêu cầu hiệu suất đọc ổn định.Đọc dữ liệu gần như đơn I/O (~1,0–1,3 I/O mỗi lần lấy dữ liệu)
Bộ nhớ đệm vượt quá Điểm uốn 2 (Bộ lọc Bloom + tất cả các khối chỉ mục).
Điều này yêu cầu một bộ nhớ đệm nhỏ (thường < 1,5% kích thước cơ sở dữ liệu ) và đưa số lần đọc gần đến giới hạn dưới thực tế.
Thích hợp cho các lớp thực thi yêu cầu độ trễ thấp và các khối lượng công việc đọc dữ liệu chuyên sâu.
Vượt quá Điểm uốn 2 , việc tăng thêm kích thước bộ nhớ cache chỉ mang lại sự giảm thiểu I/O không đáng kể đối với các tác vụ đọc ngẫu nhiên.





