

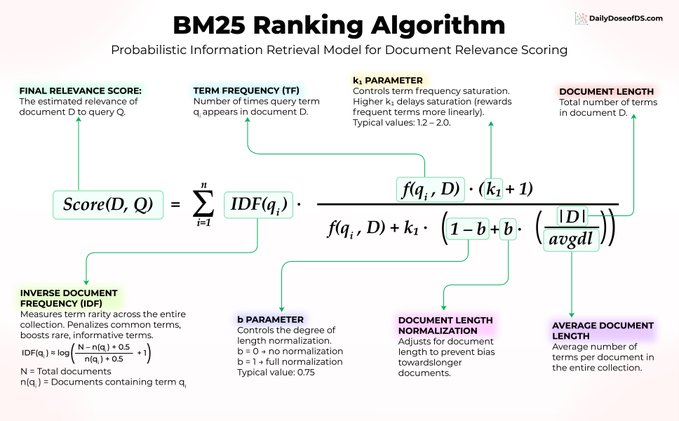
Tìm kiếm vector không phải lúc nào cũng là câu trả lời. Một thuật toán 30 năm tuổi, không được huấn luyện, không có embedding và không được tinh chỉnh, vẫn đang vận hành Elasticsearch, OpenSearch và hầu hết các hệ thống tìm kiếm sản xuất hiện nay. Nó được gọi là BM25, và đáng để tìm hiểu lý do tại sao nó vẫn tồn tại. Giả sử bạn đang tìm kiếm "cơ chế chú ý transformer" trong thư viện các bài báo về học máy. BM25 chấm điểm tài liệu bằng cách sử dụng ba ý tưởng cốt lõi: 1) Độ hiếm của từ quan trọng hơn tần suất xuất hiện của từ Mọi bài báo đều chứa "the" và "is", vì vậy những từ đó không mang tín hiệu gì. Nhưng "transformer" là từ cụ thể và giàu thông tin, vì vậy BM25 cho nó trọng số cao hơn nhiều. Trong công thức, điều này được thể hiện bằng IDF(qᵢ). 2) Sự lặp lại có ích, nhưng hiệu quả giảm dần Nếu từ "attention" xuất hiện 10 lần trong một bài báo, đó là một tín hiệu liên quan mạnh mẽ. Nhưng sự tăng từ 10 lên 100 lần xuất hiện hầu như không làm thay đổi điểm số. BM25 áp dụng đường cong bão hòa được điều khiển bởi f(qᵢ, D) và tham số k₁, ngăn chặn việc nhồi nhét từ khóa làm sai lệch kết quả. 3) Độ dài tài liệu được chuẩn hóa Một bài báo 50 trang đương nhiên sẽ chứa nhiều từ khóa khớp hơn một bài báo 5 trang. BM25 điều chỉnh điều này bằng cách sử dụng |D|/avgdl, được điều khiển bởi tham số b, do đó các tài liệu dài hơn không thống trị bảng xếp hạng chỉ vì chúng có nhiều văn bản hơn. Ba ý tưởng. Không có mạng nơ-ron. Không có dữ liệu huấn luyện. Chỉ là toán học thanh lịch đã được kiểm chứng qua thời gian. Đây là phần mà hầu hết mọi người bỏ qua: BM25 vượt trội trong việc khớp từ khóa chính xác, điều mà các embedding thực sự gặp khó khăn. Khi người dùng tìm kiếm "mã lỗi 5012", tìm kiếm vector có thể trả về các mã lỗi tương tự về mặt ngữ nghĩa. BM25 sẽ luôn hiển thị kết quả khớp chính xác. Đây chính xác là lý do tại sao tìm kiếm kết hợp đã trở thành mặc định trong các hệ thống RAG hàng đầu. Kết hợp BM25 với tìm kiếm vector mang lại cho bạn sự hiểu biết về ngữ nghĩa VÀ khớp từ khóa chính xác trong một quy trình duy nhất. Vì vậy, trước khi bạn vội vàng sử dụng GPU cho mọi bài toán tìm kiếm, hãy cân nhắc rằng BM25 có thể đã giải quyết được vấn đề đó, hoặc ít nhất, sẽ cải thiện đáng kể khả năng tìm kiếm ngữ nghĩa khi kết hợp cả hai.
Bài viết này được dịch máy
Xem bản gốc
Từ Twitter
Tuyên bố từ chối trách nhiệm: Nội dung trên chỉ là ý kiến của tác giả, không đại diện cho bất kỳ lập trường nào của Followin, không nhằm mục đích và sẽ không được hiểu hay hiểu là lời khuyên đầu tư từ Followin.
Thích
Thêm vào Yêu thích
Bình luận
Chia sẻ
Nội dung liên quan





