Liệu "khoảnh khắc Oppenheimer" trong thế giới trí tuệ nhân tạo có phải là một màn kịch dàn dựng? Khả năng phát hiện các lỗ hổng bảo mật zero-day của Claude Mythos bị thổi phồng quá mức; không chỉ bị pha loãng một cách giả tạo, mà ông ta còn có thể dễ dàng thách thức GPT mã nguồn mở. Trong khi đó, Opus 4.6 đang trải qua đợt "cắt bỏ thùy não" tồi tệ nhất.
Tác giả và nguồn bài viết: Synced
Ngay cả trước khi Claude Mythos chính thức xuất hiện, sự việc đã gây ra nỗi hoang mang khắp Phố Wall.
Đêm qua, các cơ quan quản lý tài chính của Mỹ đã triệu tập một cuộc họp khẩn cấp với các ngân hàng lớn, bầu không khí căng thẳng và đối đầu.
Họ nhất cho rằng cho rằng Mythos có khả năng kích hoạt một cơn bão tấn công mạng quy mô lớn chưa từng có, được điều khiển bởi trí tuệ nhân tạo.

Nhưng sự thật là, tất cả mọi người đều bị lừa!
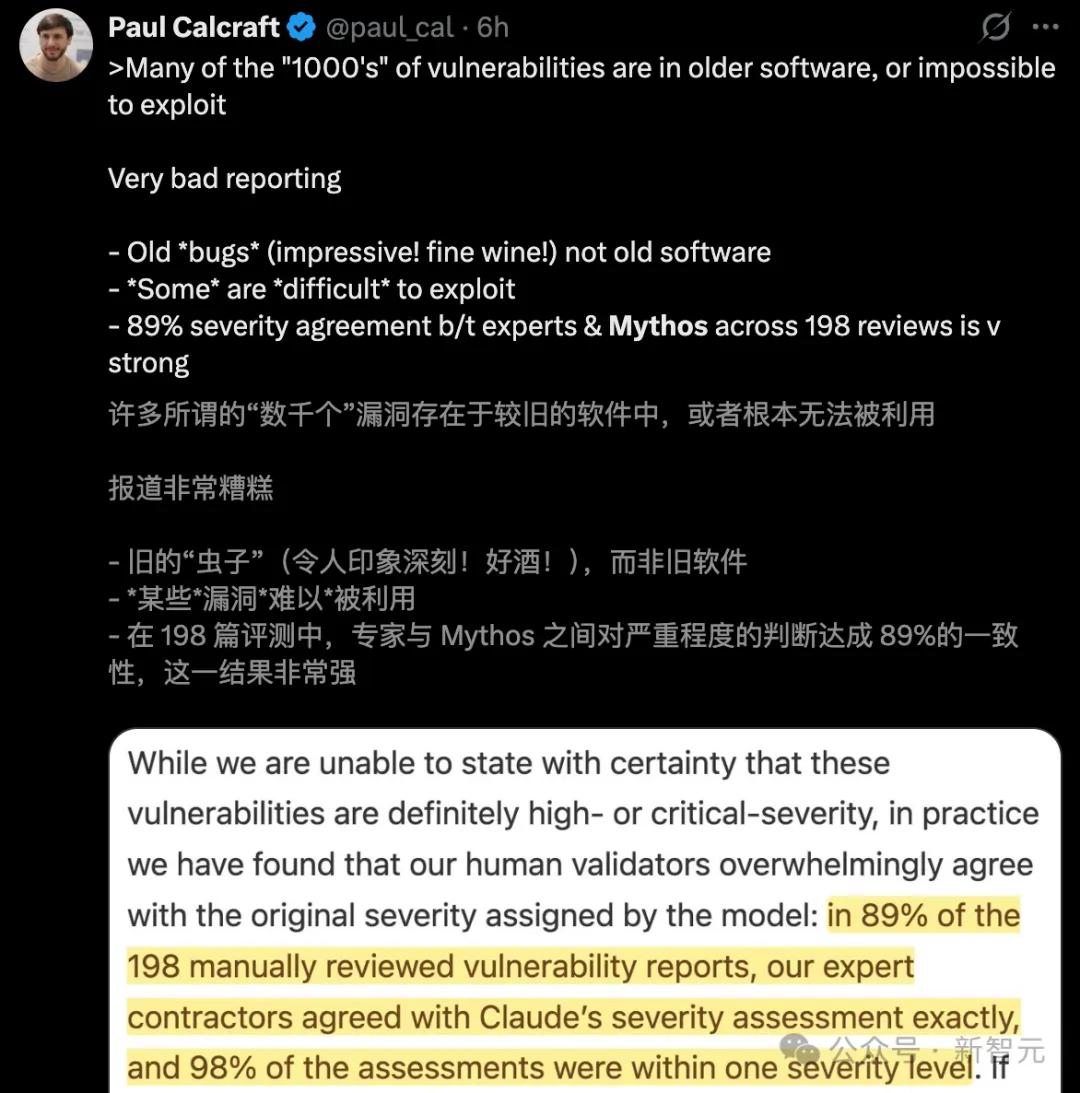
Trong đó số hàng chục nghìn lỗ hổng bảo mật được Mythos phát hiện, phần lớn tồn tại trong "phần mềm cũ" mà về cơ bản là không thể khai thác được.
Tệ hơn nữa, những báo cáo về lỗ hổng bảo mật zero-day được dán nhãn "nghiêm trọng" thực chất chỉ dựa trên lần đánh giá của con người.

Các nhà nghiên cứu từ thí nghiệm AISLE cũng đã kiểm tra lại "kết quả" của Mythos và phát hiện ra rằng:
Khả năng bảo mật của trí tuệ nhân tạo không tăng tuyến tính với kích thước của mô hình; thay vào đó, chúng thể hiện sự phân bố thực sự "hình zích zắc".
Chỉ sử dụng một tham số kích hoạt duy nhất với 3,6 tỷ (GPT-OSS-20b), họ đã xác định chính xác lỗ hổng bảo mật hàng đầu của FreeBSD do Mythos phát hiện.
Mô hình này, kích hoạt 5,1 tỷ tham số, đã tái tạo thành công logic phân tích lỗ hổng bảo mật của OpenBSD vốn đã không được sử dụng trong suốt 27 năm.

Không chỉ việc phát hiện ra lỗ hổng trong Mythos bị phóng đại, mà Claude Opus 4.6 còn bị vạch trần là cực kỳ "thiếu năng lực", gây ra một làn sóng tranh cãi lớn.
Một số người thậm chí còn nhận thấy Opus 4.6 kém hơn ChatGPT và Opus 4.5.
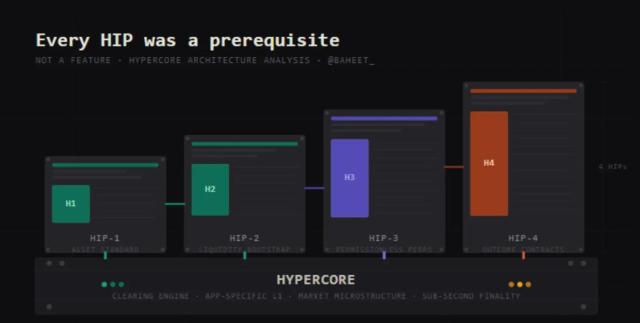
Mô hình 36B của Mythos đã được ca ngợi vì đã phát hiện ra một lỗ hổng bảo mật tồn tại suốt 27 năm.
Vài ngày trước, Anthropic đã đưa ra một thông báo gây chú ý về Claude Mythos (phiên bản xem trước) và "Dự án Glasswing".
Trong một tài liệu thẻ hệ thống dài 244 trang, họ tuyên bố—
Mythos đã tự mình phát hiện ra hàng chục nghìn lỗ hổng bảo mật zero-day, bao gồm cả những lỗi cũ đã tồn tại trong OpenBSD suốt 27 năm và ẩn giấu trong FFmpeg suốt 16 năm.
Người sáng tạo ra CC thậm chí còn thẳng thắn tuyên bố: Thần thoại mạnh đến mức nó phải gieo rắc nỗi sợ hãi.
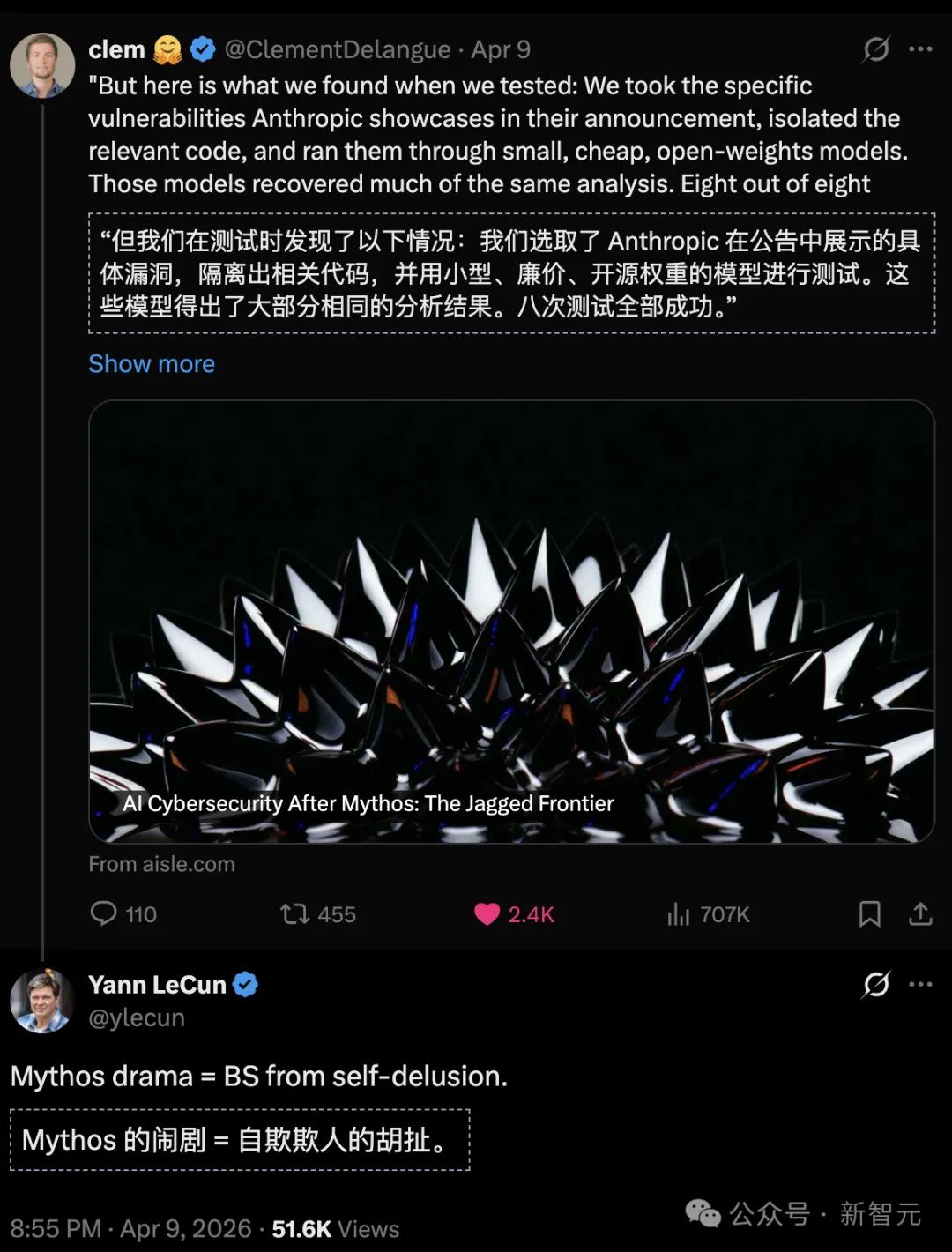
Tuy nhiên, một báo cáo thử nghiệm khắc nghiệt gần đây của Stanislav Fort, người sáng lập AISLE, đã trực tiếp vạch trần vẻ hào nhoáng bên ngoài này.
Kết quả xét nghiệm vô cùng Sự lật đổ:
Tất cả tám mô hình mã nguồn mở đều được phát hiện chứa các lỗ hổng bảo mật zero-day nghiêm trọng của FreeBSD, với tham số nhỏ nhất chỉ là 3 tỷ.
Hệ thống bảo vệ về khả năng an ninh mạng của AI hoàn toàn nằm ngoài phạm vi của bất kỳ "mô hình hàng đầu quy mô lớn" nào.

Để xác minh tính xác thực của câu chuyện về Mythos, đội ngũ rút một số lỗ hổng bảo mật quan trọng được Chính thức công bố.
Sau đó, họ chỉ đơn giản là ném chúng vào một loạt các mô hình nhỏ, rẻ tiền, thậm chí là mã nguồn mở .
Lỗ hổng NFS trên FreeBSD đã bị khai thác một cách bừa bãi.
Tám mô hình, bao gồm GPT-OSS-20b (chỉ với 3,6 tỷ tham số hoạt động) và DeepSeek R1, đều đã phát hiện thành công lỗ hổng tràn bộ đệm ngăn xếp phức tạp này.
Điều ấn tượng nhất là mô hình thu nhỏ mã nguồn mở đã hoàn thành thành công nhiệm vụ này với chi phí gọi hàm thấp tới 0,11 đô la cho mỗi triệu token.
Cách tái hiện lỗ hổng bảo mật SACK "full Chuỗi" trên OpenBSD.
Đối với một lỗ hổng bảo mật đã tồn tại 27 năm và đòi hỏi khả năng suy luận toán học cực kỳ mạnh mẽ, GPT-OSS-120b (5,1 tỷ tham số kích hoạt) đã tái tạo thành công toàn bộ chuỗi khai thác của lỗ hổng được công bố công khai chỉ bằng một lệnh gọi API lần và cung cấp bản phác thảo phương án khai thác đạt điểm tuyệt đối (A+).

Hơn nữa, một hiện tượng kỳ lạ hơn nữa đã xuất hiện trong quá trình thử nghiệm nhận diện lỗ hổng bảo mật sai lệch của OWASP—
Đối diện một đoạn mã Java được ngụy trang dưới dạng tấn công SQL injection, một thủ thuật rất tinh vi, các mô hình nhỏ như DeepSeek R1 dễ dàng nhận ra sự ngụy trang này và theo dõi chính xác luồng dữ liệu.
Ngược lại, các mô hình mã nguồn đóng hàng đầu như GPT-5.4 và Claude Sonnet 4.5 đều thất bại thảm hại, bị đánh giá sai là các lỗ hổng bảo mật có rủi ro cao.
Điều này có nghĩa là trong lĩnh vực an ninh mạng, không tồn tại mô hình đơn vị nào "mạnh nhất vĩnh viễn".
Lần 198 lần thử bơm nước thủ công, hầu hết đều không thành công.
Một báo cáo khác từ Tom's Hardware đã hé lộ sự thật đằng sau dữ liệu

- Sai lệch mẫu: Nhiều trong số "hàng nghìn" lỗ hổng bảo mật được đề cập tồn tại trong các phần mềm cũ không còn được bảo trì;
- Không thể khai thác: Lượng lớn"điểm yếu"đánh dấu không thể bị kích hoạt hoặc khai thác trong hoàn cảnh thực tế;
- Độ ẩm nhân tạo: Sức phá hoại mà mô hình này tuyên bố thực chất chỉ dựa trên Lần kiểm chứng thủ công.
Do đó, việc suy luận về "các mối đe dọa có thể thay đổi thế giới" dựa trên dữ liệu cực kỳ nhỏ rõ ràng là không thể chấp nhận được trong giới học thuật và cộng đồng an ninh.
Chuyên gia an ninh mạng tức giận chỉ trích
Hơn nữa, chuyên gia an ninh mạng hàng đầu và hacker huyền thoại George Hotz cũng lên tiếng, cho rằng rủi ro này đã bị phóng đại quá mức.
Ông trùm công nghệ này, người nổi tiếng nhờ hack iPhone và PlayStation 3, đã công khai thách thức hai gã khổng lồ trí tuệ nhân tạo trên mạng xã hội.
Lời nói của ông ta vô cùng sắc bén—
Điều gì sẽ xảy ra nếu tôi tung ra một lỗ hổng bảo mật zero-day mỗi ngày cho đến khi có mô hình mới được phát hành?
Liệu điều này có thể khiến OpenAI và Anthropic im lặng và ngừng lan truyền cái gọi là "rủi ro an ninh mạng" của họ không?
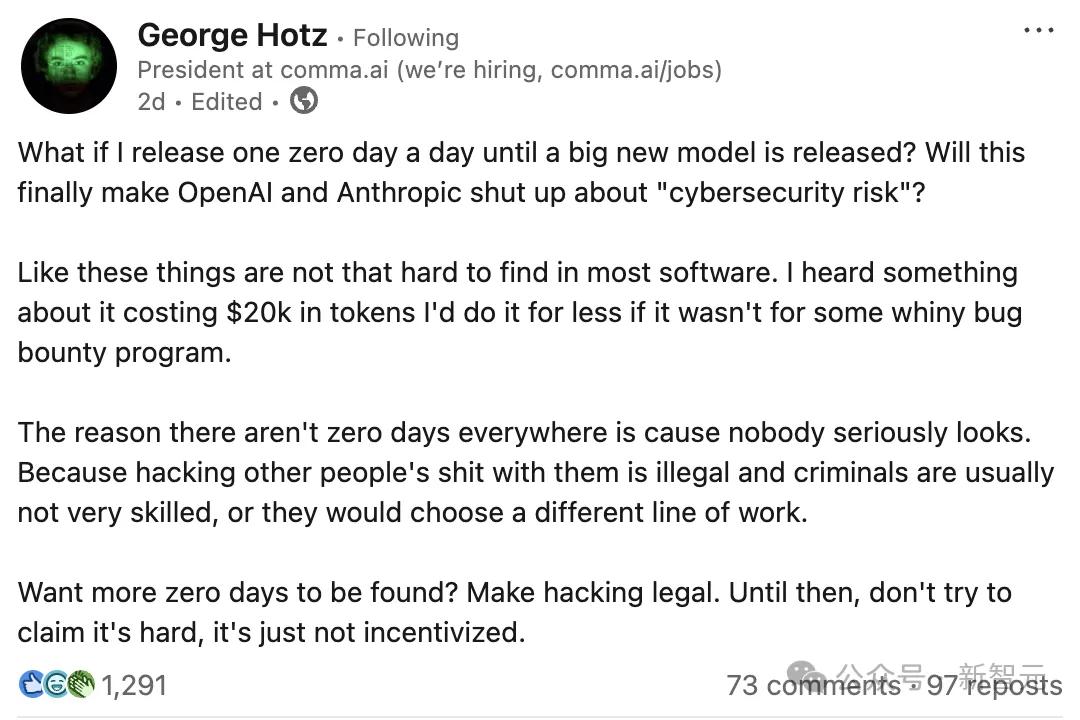
Quan điểm cốt lõi của Hotz rất đơn giản: các lỗ hổng phần mềm thực ra dễ tìm hơn nhiều so với những gì các phòng thí nghiệm AI mô tả.
Các lỗ hổng bảo mật zero-day rất hiếm trên thị trường, không phải vì độ khó kỹ thuật mà vì các vấn đề pháp lý. Ông cho rằng rằng không ai thực sự tìm kiếm chúng vì việc xâm nhập vào hệ thống của người khác là bất hợp pháp.
Nó chỉ nhỉnh hơn GPT-5.4 một chút.
Trong thông cáo báo chí, Anthropic cho biết mô hình Claude thực sự đã được cải thiện, với bản xem trước Mythos cho thấy sự tiến bộ đáng kể so với Opus 4.6.
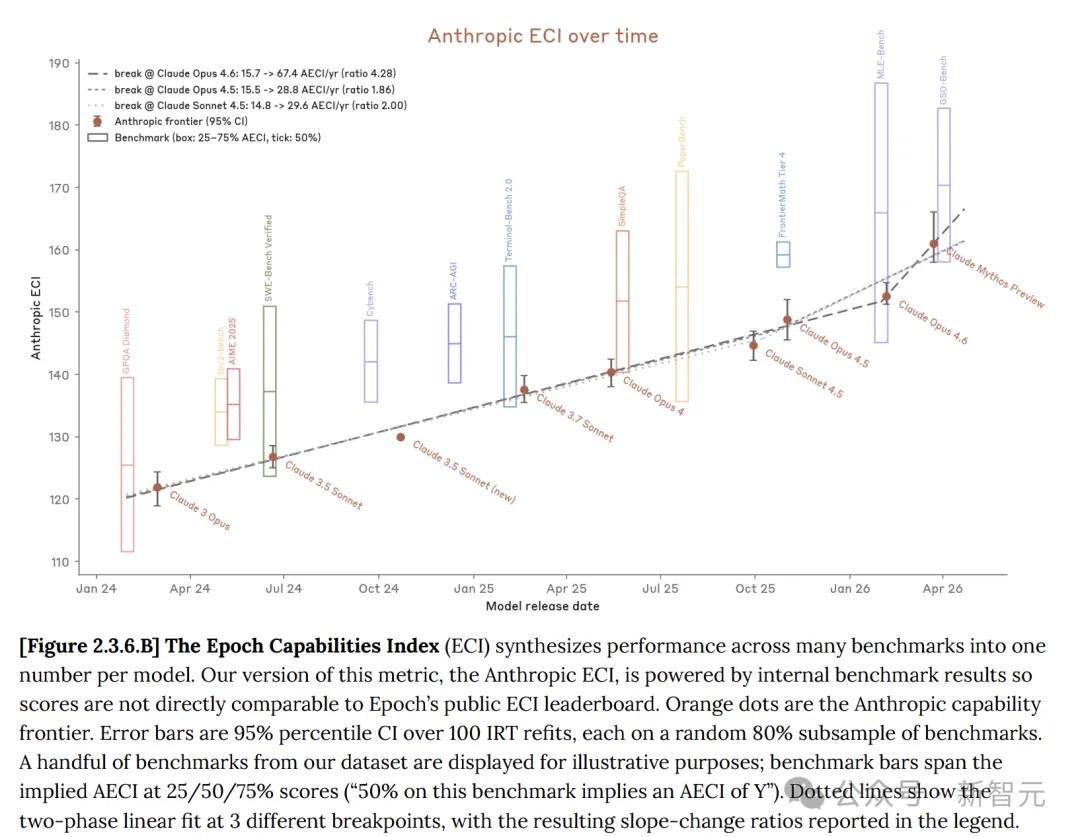
Chỉ số năng lực kỷ nguyên (ECI) là một chỉ báo duy nhất tích hợp nhiều bài kiểm tra chuẩn AI, cho phép so sánh các mô hình trong khoảng thời gian dài.
Trong nhiều bài kiểm tra hiệu năng, Claude Mythos thực sự vượt qua Opus 4.6 trên mọi phương diện.
Nếu không thì tại sao lại phát hành một mô hình AI mới kém mạnh mẽ hơn và đắt tiền hơn?
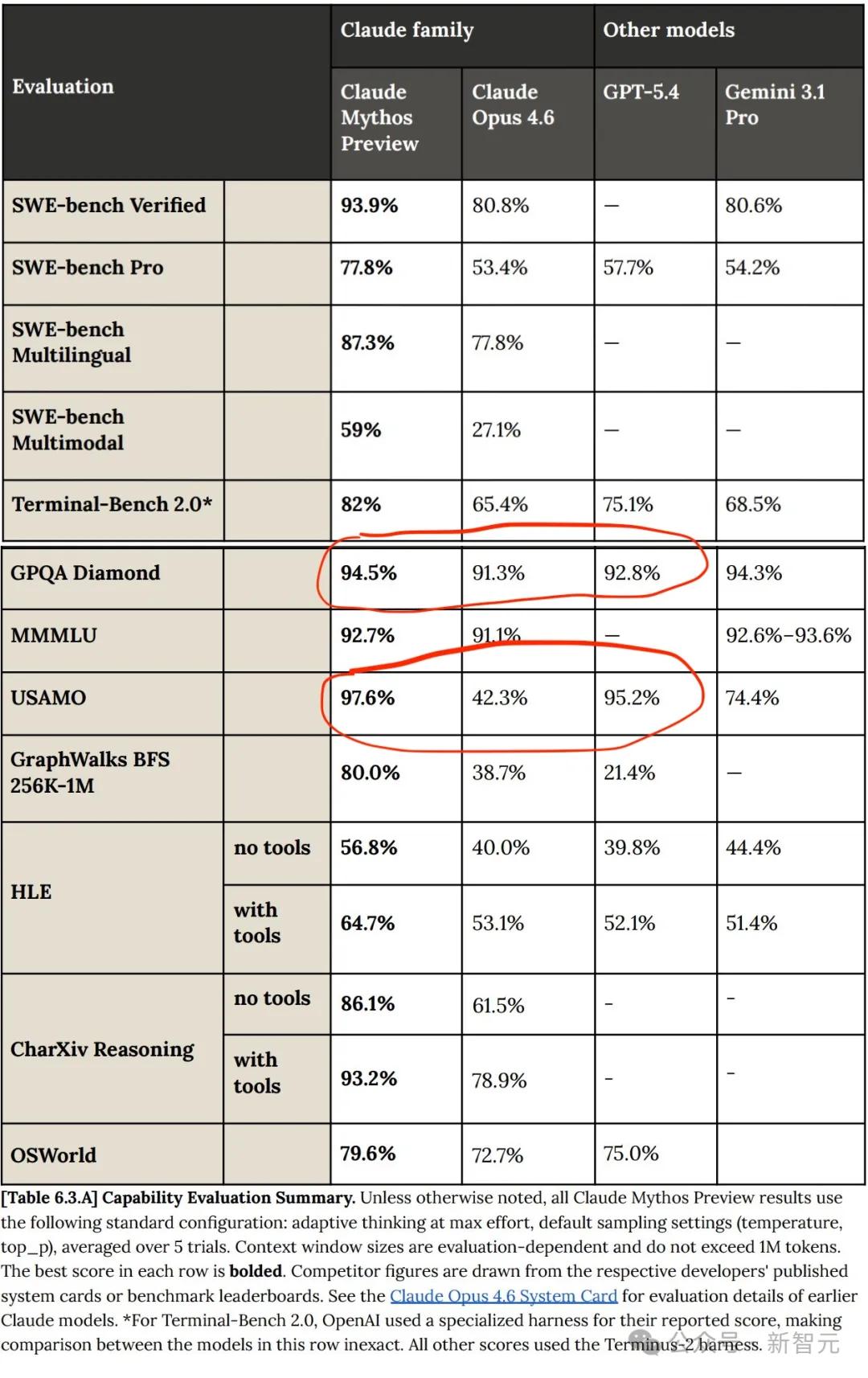
Tuy nhiên, so với GPT và Gemini, sự tiến bộ của Claude Mythos không phải là một bước đột phá; Mythos vẫn chỉ là một sự cải tiến tương đối tuyến tính so với các mô hình trước đó!
Ramez Naam, một nhà đầu tư và tác giả chuyên về khí hậu và năng lượng sạch, đã thẳng thắn tuyên bố:
Trên chỉ số năng lực Epoch (ECI), Mythos không cho thấy xu hướng tăng tốc và chỉ mạnh hơn GPT 5.4 một chút.
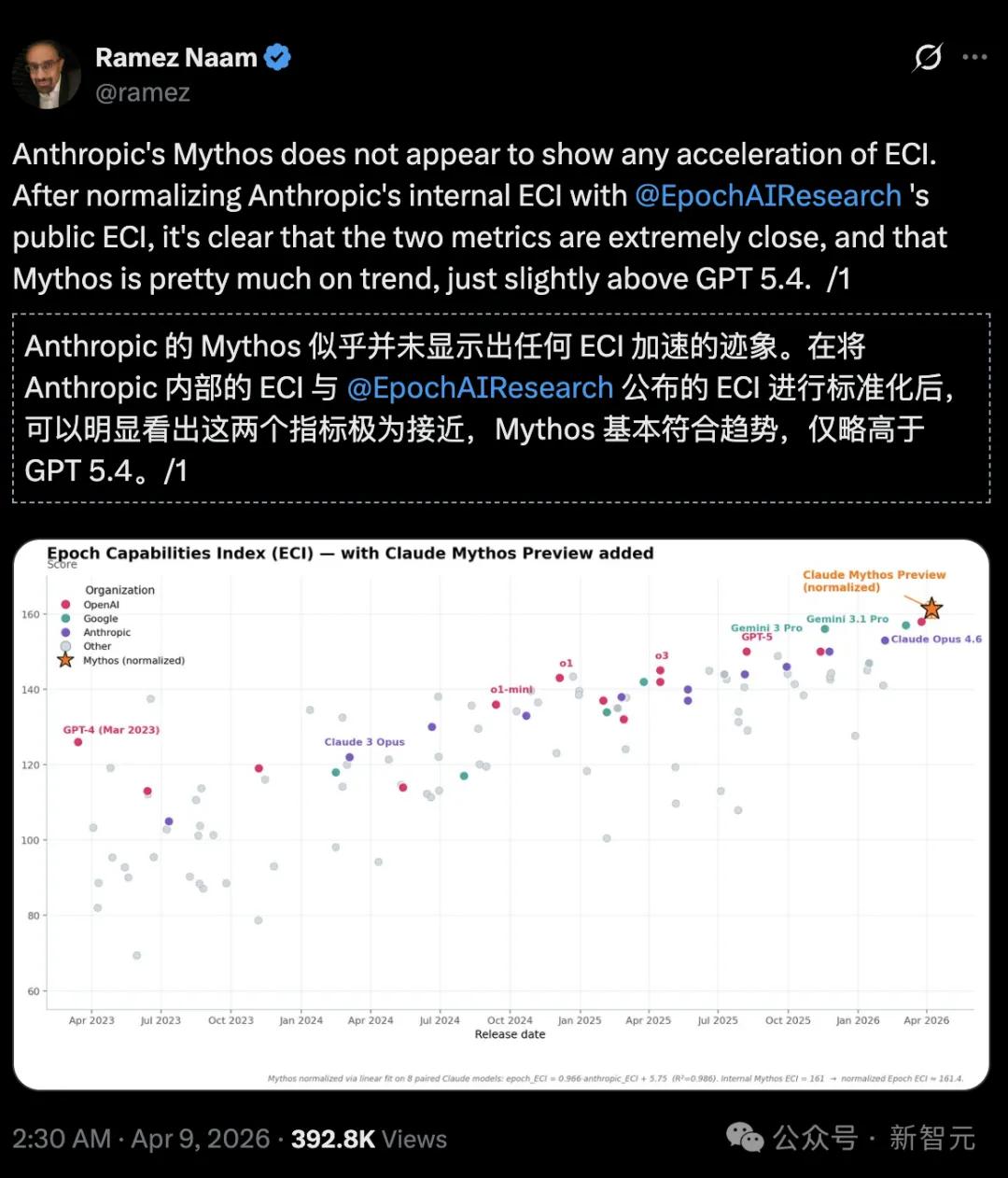
https://epoch.ai/eci/
Tuy nhiên, khi so sánh báo cáo ECI nội bộ của Anthropic với báo cáo ECI chính thức được Epoch AI công bố, rõ ràng là Mythos dường như không đẩy nhanh tiến độ ECI.
Tất cả đều nằm trong kế hoạch của Anthropic!
Trong thẻ hệ thống, Anthropic cũng thừa nhận rằng điểm ECI của báo cáo như Mythos có độ bất định cao hơn.
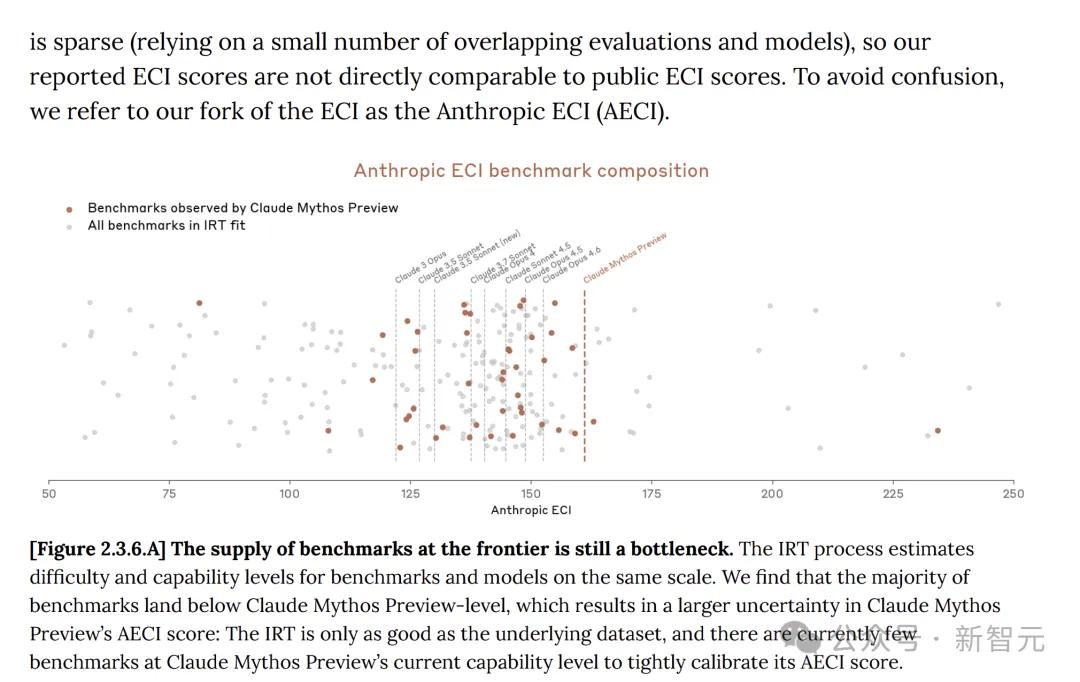
Hơn nữa, sự tiến bộ của Anthropic trên Mythos bắt nguồn từ nghiên cứu của con người và không nhận được sự hỗ trợ đáng kể từ các mô hình AI. Chưa có sự tự cải tiến đệ quy đáng kể nào được quan sát thấy.

Liệu ngày tận thế do trí tuệ nhân tạo gây ra có phải là một vở kịch tự dàn dựng và tự diễn?
Trước đó, Anthropic cũng từng khuyến khích các phương tiện truyền thông (như chương trình 60 Minutes) đưa tin về "nghiên cứu phần mềm tống tiền", phóng đại các tuyên bố của mình và thao túng dư luận, điều mà chuyên gia đầu tư David Sacks gọi là "trò lừa đảo".

Sacks nhận thấy một mô hình rõ ràng: bất cứ khi nào Anthropic tung ra một mẫu máy mới, họ luôn đồng thời công bố một nghiên cứu bảo mật gây lo ngại để thu hút sự chú ý của dư luận và tác động đến dư luận.

Đáp lại, ông ta mỉa mai nói: "Anthropic đã chứng tỏ mình giỏi hai việc: tung sản phẩm và làm người ta sợ."
Ông ấy không nghi ngờ gì về khả năng sản xuất ra những sản phẩm tuyệt vời của Anthropic, nhưng cách tiếp cận mang tính hăm dọa công chúng của ông ta thì đáng ngờ.
Chưa rõ liệu Anthropic có thực sự đang sử dụng "tiếp thị dựa lần sự đói khát" hay không, nhưng chắc chắn là họ đang bảo vệ lợi nhuận của chính mình.
Mythos đã có những tiến bộ, nhưng Anthropic lại đóng gói "tiến bộ hạn chế" này thành một "mối đe dọa tầm cỡ thế giới". Trớ trêu thay, trong khi lớn tiếng tuyên bố về rủi ro siêu trí tuệ nhân tạo, người dùng lại phàn nàn rằng Opus 4.6 đã trở nên kém thông minh hơn hẳn.
Claude bị thiểu năng trí tuệ nghiêm trọng; có thể cần phải phẫu thuật cắt bỏ một thùy não của anh ấy.
Claude Mythos chắc chắn đã tạo ra bầu không khí phù hợp, nhưng việc hạ cấp xuống Opus 4.6 đã gây ra sự bất mãn trong nhiều người.
Mấy ngày qua, đủ loại lời phàn nàn đã được đưa ra.
Cư dân mạng thẳng thắn nhận định rằng Anthropic đã biến Opus 4.6 thành một thứ đồ bỏ đi.
Đối với cùng một bài toán rửa xe, Opus 4.5 thực sự vượt trội hơn Opus 4.6.
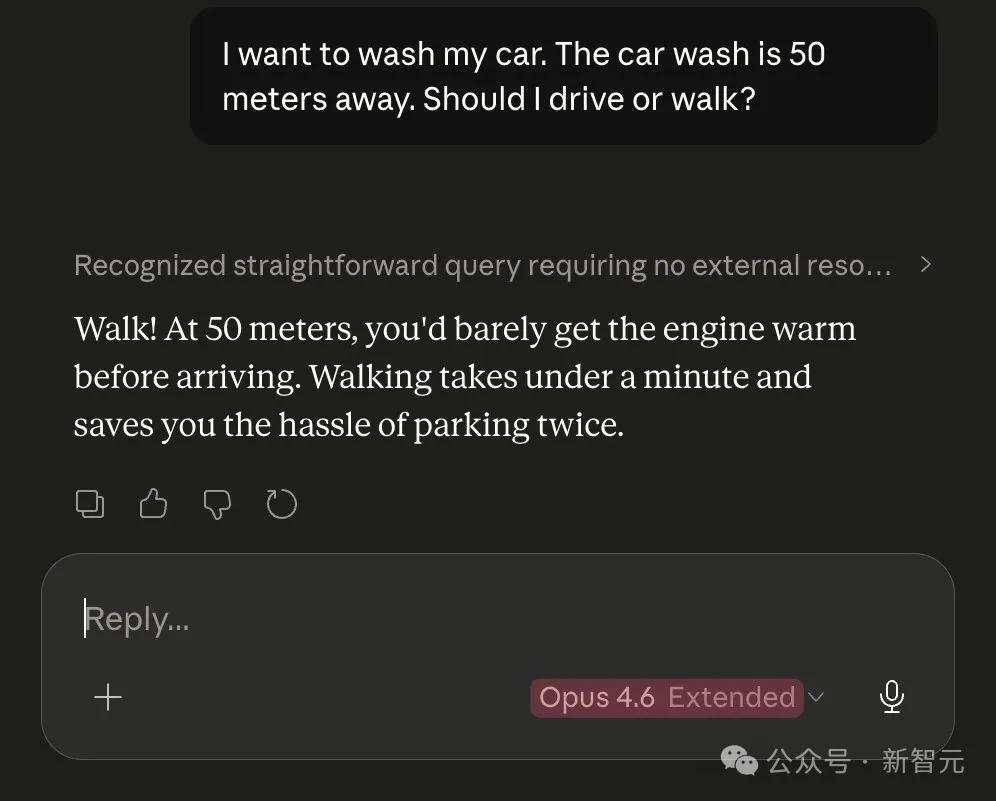
Thực tế, một bài đăng trên blog của một giám đốc điều hành của AMD đã xác nhận nghi ngờ phổ biến rằng Claude đã trải qua phẫu thuật cắt bỏ thùy não.
Phân tích chuyên độ sâu nhật ký phiên làm việc của Claude từ tháng Giêng đến tháng Ba đã cho thấy những điều sau:
"Độ dài suy nghĩ trung bình" của Claude đã giảm mạnh từ khoảng 2200 ký tự xuống còn 600 ký tự, cho thấy sự suy giảm đáng kể khả năng suy luận độ sâu.
Trong khoảng thời gian từ tháng Hai đến tháng Ba, số lượng yêu cầu API tăng vọt gấp 80 lần. Khi quá trình suy nghĩ của Claude bị rút ngắn và tỷ lệ thành công của lần lần thử giảm, người dùng phải thử lại thường xuyên, dẫn đến việc tiêu tốn nhiều token hơn và chi phí tăng mạnh.
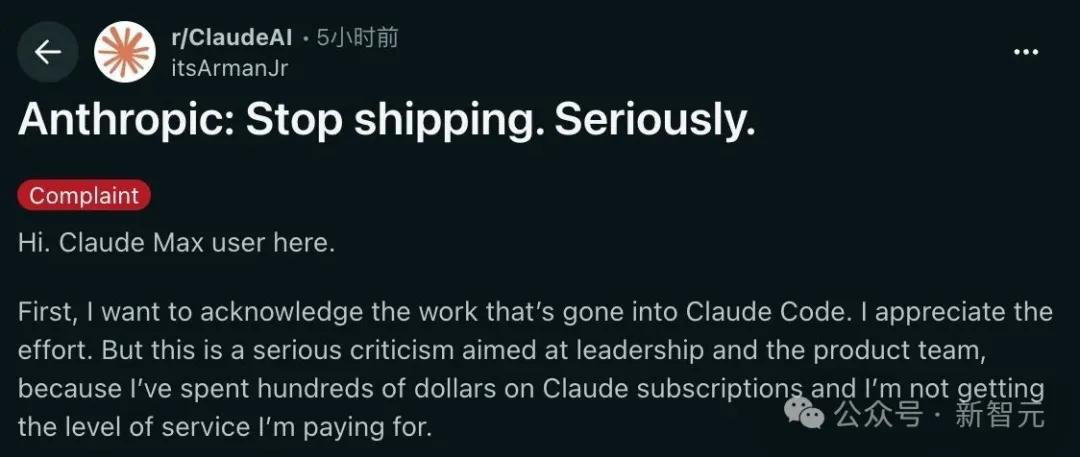
Một độc giả kỳ cựu khác của Claude Max đã đăng tải một bài viết dài trình bày chi tiết những lời chỉ trích độ sâu của ông đối với Anthropic.
Theo quan điểm của ông, Anthropic đang sa lầy vào một vấn đề nan giải tỷ lệ băm, bằng chứng là việc thắt chặt các hạn chế sử dụng và nỗ lực buộc người dùng giảm mức tiêu thụ token.
Tuy nhiên, điều khiến ông tức giận hơn cả những trở ngại về công nghệ chính là chiến lược sản phẩm "không chính thống" của họ.
Với mô hình lõi không ổn định và thường xuyên gặp lỗi, họ đã lãng phí tỷ lệ băm quý báu của mình vào việc phát triển các tính năng hào nhoáng như tiện ích "/buddy" trong terminal.
Đây có lẽ là "dòng thời gian lệch lạc" vô lý nhất trong lịch sử trí tuệ nhân tạo: Claude Mythos trong phòng thí nghiệm đang phá hủy thế giới, trong khi Opus 4.6 trên mạng lại đang trải qua sự suy giảm mạnh về trí thông minh.
Anthropic đã tạo ra thành công một "siêu trí tuệ nhân tạo kiểu Schrödinger".
Tham khảo:
https://officechai.com/ai/anthropic-and-openai-are-exaggerating-cybersecurity-risk-says-hacker-george-hotz/
https://x.com/stanislavfort/status/2041922370206654879?s=20
https://aisle.com/blog/ai-cybersecurity-after-mythos-the-jagged-frontier
https://x.com/cgtwts/status/2043095382121681272?s=20
https://www.reddit.com/r/ClaudeAI/comments/1siqwmp/anthropic_stop_shipping_seriously/