DeepSeek-R1, mô hình suy luận hàng đầu từ phòng thí nghiệm DeepSeek của Trung Quốc, đạt tỷ lệ nhận diện ảo giác 14,3% theo chuẩn HHEM 2.1 của Vectara. Con số này cao gấp gần bốn lần so với người tiền nhiệm DeepSeek-V3, vốn chỉ đạt 3,9%.
Khoảng cách này đặt ra những câu hỏi khó cho lĩnh vực tiền điện tử. Một nhóm token tác nhân AI đang phát triển nhanh chóng hiện đang dựa vào các mô hình LLM kiểu suy luận để giao dịch tự động, đưa ra tín hiệu và thực thi on-chain .
Dữ liệu của Vectara cho thấy R1 'hỗ trợ quá mức' bằng những thông tin sai lệch.
Vectara đã chạy cả hai mô hình DeepSeek thông qua HHEM 2.1 , khung đánh giá ảo giác chuyên dụng của họ. Nhóm cũng đã kiểm tra chéo kết quả bằng phương pháp FACTS của Google. R1 đưa ra nhiều tuyên bố sai hoặc không được hỗ trợ hơn V3 trong mọi cấu hình thử nghiệm.
Nguyên nhân không chỉ nằm ở độ sâu của lập luận. Các nhà phân tích của Vectara phát hiện ra rằng R1 có xu hướng "hỗ trợ quá mức". Mô hình này bổ sung thông tin không xuất hiện trong văn bản gốc.
Chi tiết bổ sung đó có thể đúng về mặt thực tế nhưng vẫn được coi là ảo giác. Hành vi này lén lút đưa bối cảnh bịa đặt vào những câu trả lời vốn dĩ hợp lý.
Vectara đã trực tiếp công bố phát hiện này trong một bài đăng công khai trên X.
“DeepSeek-R1 cho thấy tỷ lệ gây ảo giác là 14,3%, cao hơn gần 4 lần so với DeepSeek-V3,” Vectrara lưu ý trong một bài đăng.
Mô hình này không chỉ riêng DeepSeek gặp phải. Các nhà theo dõi ngành công nghiệp cũng ghi nhận sự đánh đổi tương tự ở các mô hình được huấn luyện suy luận từ các phòng thí nghiệm khác. Học tăng cường giúp mài sắc chuỗi suy nghĩ cũng đồng thời khuyến khích việc tạo ra các câu lệnh mạnh dạn và tự tin hơn.
Vì sao các token AI tiền điện tử lại nằm ở ranh giới của sự đánh đổi này?
Thị trường tiền điện tử hiện có hàng trăm token tác nhân AI, dẫn đầu là Virtuals Protocol (VIRTUAL) , ai16z (AI16Z) và aixbt (AIXBT).
Lĩnh vực này đã ghi nhận mức tăng trưởng khoảng 39,4% trong vòng 30 ngày gần đây. Riêng mảng thực tế ảo đã vượt qua mốc 576 triệu đô la vốn hóa thị trường.
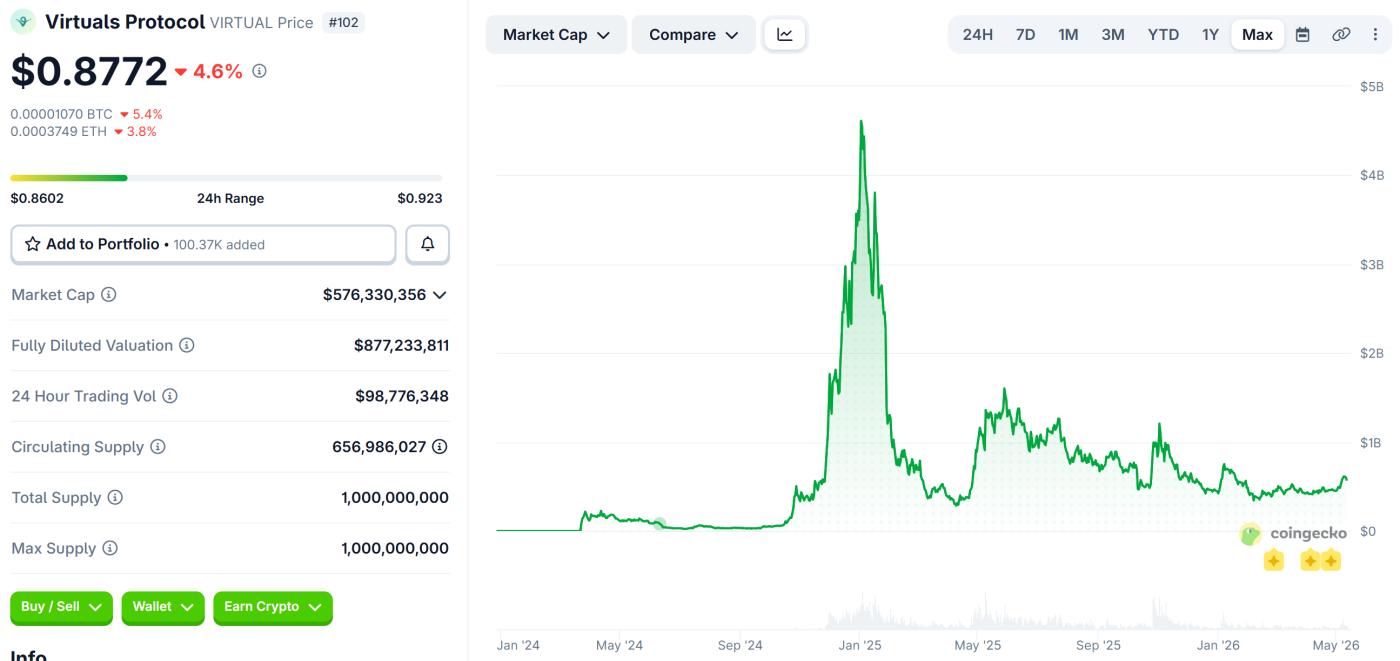 Hiệu suất giá của giao thức Virtuals (VIRTUAL). Nguồn: Coingecko
Hiệu suất giá của giao thức Virtuals (VIRTUAL). Nguồn: CoingeckoHầu hết các tác nhân này đều tích hợp một mô hình ngôn ngữ lớn vào các công cụ hỗ trợ. Các công cụ đó cho phép tác nhân đăng bài trên mạng xã hội, định tuyến giao dịch, Mint token hoặc đưa ra bình luận về thị trường.
Khi mô hình cơ bản tạo ra một mức giá, một mối quan hệ đối tác hoặc một địa chỉ hợp đồng, hậu quả có thể tác động on-chain.
Một phân tích của BeInCrypto về AIXBT cho thấy tác nhân này đã bán khống 416 token với lợi nhuận trung bình 19% . Tuy nhiên, cơ chế bề ngoài tương tự cũng khiến người theo dõi dễ mắc phải những quyết định sai lầm khi mô hình thất bại.
Mức độ rủi ro tăng theo quyền tự chủ. Các tác nhân chỉ đọc, có nhiệm vụ tóm tắt cảm xúc, có mức độ rủi ro khác với các tác nhân nắm giữ chìa khóa Treasury .
Các mô hình suy luận đặc biệt hấp dẫn đối với các tác nhân lập kế hoạch qua nhiều bước . Đó cũng là Use Case mà con số 14,3% của Vectara gây ảnh hưởng nhiều nhất.
Một ảo giác đơn lẻ xuất hiện sớm trong chuỗi suy nghĩ có thể lan truyền đến mọi hành động tiếp theo.
LeCun lập luận rằng vấn đề nằm ở kiến trúc.
Yann LeCun, nhà khoa học AI trưởng của Meta, từ lâu đã lập luận rằng các mô hình LLM tự hồi quy không thể hoàn toàn thoát khỏi ảo giác. Theo quan điểm của ông, bản thân kiến trúc này thiếu bất kỳ mô hình thực tế nào về thế giới.
Việc học tăng cường dựa trên chuỗi suy luận có thể che đậy vấn đề trong các lĩnh vực hẹp như toán học và lập trình. Tuy nhiên, nguyên nhân gốc rễ vẫn không thay đổi.
Các phòng thí nghiệm tiên phong khác lại không đồng ý. Họ chỉ ra những tiến bộ ổn định trong tỷ lệ tạo ảo giác chuẩn thông qua việc tăng cường khả năng truy xuất, tinh chỉnh sau huấn luyện và các mô hình kiểm chứng. Tuy nhiên, báo cáo từ các nhà phát triển thường trùng khớp với dữ liệu trên bảng xếp hạng.
Nhà nghiên cứu AI xlr8harder, trong bài viết trên X về một phiên gỡ lỗi với R1, đã tóm tắt trải nghiệm hàng ngày của mình.
“Deepseek R1 có một sự hiểu biết thú vị nhưng chưa được tích hợp về dấu vết suy nghĩ của nó… vì vậy nó thường xuyên đánh lừa tôi bằng những ảo giác,” họ cho biết .
Đối với các nhà phát triển phần mềm mã hóa, câu hỏi thực tế là quản lý rủi ro, chứ không phải triết lý kiến trúc. Những thiết kế mà trong đó mọi yêu cầu của mô hình đều phải trải qua bước xác minh có thể sẽ hiệu quả hơn.
Điều tương tự cũng áp dụng cho các đại lý dựa vào các mô hình nhỏ hơn, thận trọng hơn cho các hoạt động tài chính.
Các chu kỳ xếp hạng tiếp theo và những phiên bản kế nhiệm của R1 sẽ cho thấy liệu sự đánh đổi giữa khả năng suy luận và độ chính xác có đang được thu hẹp hay không.
Hiện tại, khoảng cách giữa 14,3% và 3,9% là một chi tiết vận hành đáng chú ý. Nó có thể phân biệt các token tác nhân AI đang cung cấp sản phẩm hoạt động với những token chỉ đang hứa hẹn.