Trong vài tháng qua, tôi đã viết về AI, và cụ thể hơn là cách thức hoạt động của LLM (Learning Learning Module). Phản hồi rất tích cực, và một vài bạn đã viết thư hỏi thêm chi tiết. Một chủ đề thường xuyên được đề cập là về Cửa sổ ngữ cảnh (Context Windows): chúng là gì, hoạt động như thế nào, ETC
Bạn thấy những con số được nhắc đến ở khắp mọi nơi. Cửa sổ ngữ cảnh 100.000 Token , 1 triệu token, 10 triệu token. Các con số cứ tăng lên, chiến dịch marketing ngày càng rầm rộ, và hầu hết mọi người không hiểu rõ ý nghĩa thực sự của chúng là gì.
Vậy nên hôm nay, chúng ta sẽ khắc phục điều đó.
Đến cuối bức thư này, bạn sẽ biết cửa sổ ngữ cảnh là gì, tại sao số lớn hơn không phải lúc nào cũng đồng nghĩa với mô hình tốt hơn, và cách suy nghĩ về tất cả những điều đó vào lần tới khi bạn chọn AI để sử dụng. Tôi cũng sẽ chia sẻ một số mẹo và thủ thuật để tối ưu hóa cửa sổ ngữ cảnh của bạn bất kể bạn đang sử dụng mô hình nào.
Phiên bản đơn giản
Cửa sổ ngữ cảnh là bộ nhớ làm việc của mô hình.
Mọi thứ mà mô hình cần để thực hiện công việc của nó trong một yêu cầu duy nhất đều phải nằm gọn trong đó. Điều này bao gồm lời nhắc của bạn, hướng dẫn hệ thống, bất kỳ tài liệu hoặc hình ảnh nào bạn đã tải lên, lịch sử cuộc trò chuyện từ trước đó, các công cụ mà mô hình có quyền truy cập và phản hồi mà nó sắp tạo ra.
Tất cả đều dùng chung một ngân sách, và ngân sách này được đo bằng token. Tôi đã đề cập đến token trong Thư 108, nhưng để nhắc lại, một Token xấp xỉ 3/4 từ. Vì vậy, một cửa sổ ngữ cảnh 200.000 Token chứa khoảng 150.000 từ cùng một lúc. Một triệu token tương đương khoảng 750.000 từ, để dễ hình dung, đó là độ dài của một cuốn tiểu thuyết khá dài.
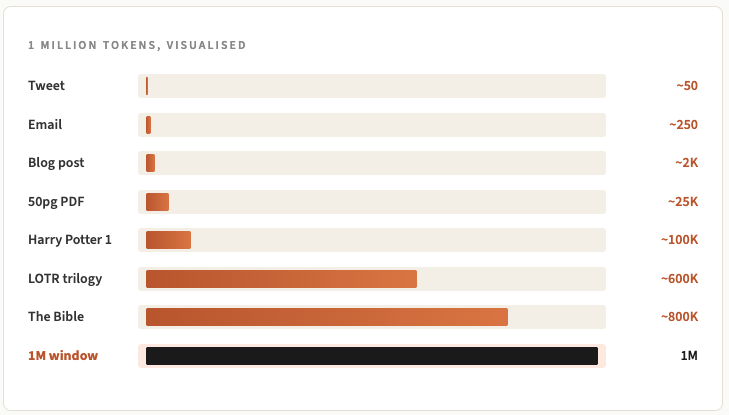
Làm thế nào chúng tôi đạt được từ 4.000 token lên 10 triệu token?
Hãy cùng nhìn nhận xem mọi thứ đã phát triển nhanh chóng như thế nào trong vài năm qua.
Nhìn chung, từ khi ChatGPT ra mắt đến nay, số lượng người dùng đã tăng từ 250 đến 2500 lần.
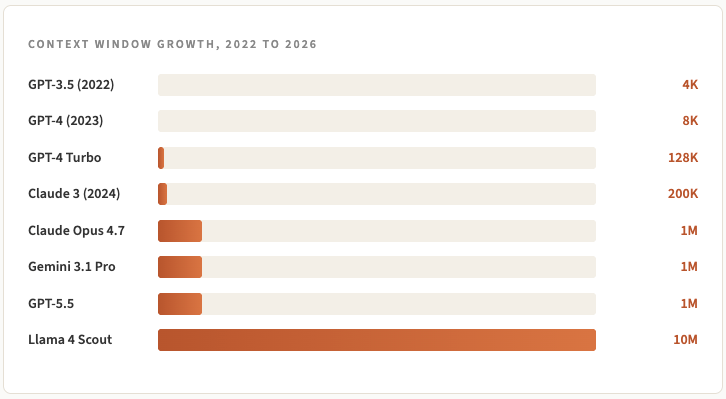
Liệu lớn hơn luôn tốt hơn?
Một số nhà nghiên cứu tại Chroma đã công bố một nghiên cứu vào năm ngoái có tên là Context Rot . Họ đã thử nghiệm 18 mô hình tiên tiến khác nhau, bao gồm Claude, GPT và Gemini, trên các nhiệm vụ truy xuất đơn giản với độ dài đầu vào khác nhau. Bản thân nhiệm vụ vẫn giữ nguyên, chỉ có độ dài của đầu vào thay đổi.
Mọi mô hình đều hoạt động kém hiệu quả hơn khi dữ liệu đầu vào dài hơn. Một số mô hình đạt điểm gần 100% với dữ liệu đầu vào Short lại đạt dưới 50% khi thực hiện cùng nhiệm vụ đó với dữ liệu đầu vào dài hơn.
Cộng đồng đã sử dụng tên của nghiên cứu này và cụm từ “sự mục nát ngữ cảnh” nhanh chóng trở thành một phần của ngôn ngữ chuyên ngành AI. Ý chính rất đơn giản: khi bạn nhồi nhét càng nhiều thông tin vào một câu hỏi gợi ý, mô hình càng trở nên kém tin cậy hơn (ngay cả khi nội dung bổ sung đó không thực sự quan trọng và không bổ sung thêm ngữ cảnh hữu ích).
Có một vài vấn đề tiềm ẩn đang gây ra hiện tượng "lỗi ngữ cảnh" này:
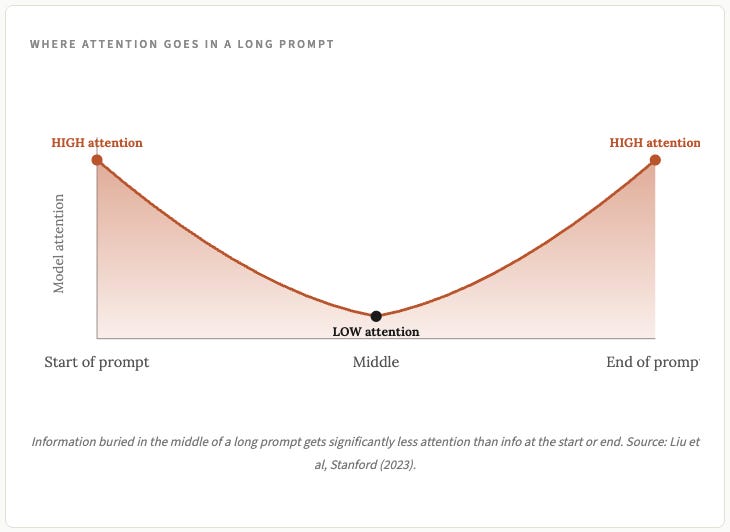
Các mô hình thường chú ý nhiều hơn đến phần đầu và cuối của một câu hỏi hơn là phần giữa. Thông tin quan trọng bị chôn vùi ở giữa một đoạn văn dài có thể bị bỏ qua. Các nhà nghiên cứu gọi đây là "mất mát ở giữa" ( các nhà khoa học không nổi tiếng về sự độc đáo trong cách đặt tên, ví dụ: Kính viễn vọng rất lớn ở Chile).
Khi nội dung trong câu hỏi trông có vẻ tương tự nhưng không hoàn toàn chính xác, mô hình sẽ bị nhầm lẫn. Chỉ cần một yếu tố gây nhiễu nhỏ cũng có thể khiến mô hình hoạt động sai.
Vị trí của thông tin trong câu hỏi cũng ảnh hưởng đến hiệu quả sử dụng thông tin đó của mô hình. Cùng một thông tin ở vị trí 1.000 sẽ cho kết quả khác so với cùng một thông tin ở vị trí 50.000.
Khi câu hỏi và câu trả lời sử dụng những từ ngữ khác nhau cho cùng một ý tưởng, mô hình sẽ gặp nhiều khó khăn hơn khi ngữ cảnh trở nên phức tạp hơn.
Điều này có nghĩa gì đối với những việc bạn đang thực sự làm?
Đây là một trong những lý do tại sao mô hình cục bộ có thể là một lựa chọn rất hấp dẫn cho một số công việc nhất định. Không có phí trên mỗi token hoặc giới hạn sử dụng khi bạn sử dụng mô hình cục bộ. Tôi đã đề cập đến mô hình cục bộ trong Thư 107 nếu bạn muốn tìm hiểu thêm.
Cách quản lý cửa sổ ngữ cảnh hiệu quả
Đây là phần quan trọng nhất trong bức thư mà tôi muốn bạn ghi nhớ. Dưới đây là những chiến thuật thực tiễn mà tôi sử dụng, cùng với hướng dẫn từ một số chuyên gia thực sự xây dựng các mô hình này.
Góc nhìn tổng quát hơn ở đây là điều mà nhóm kỹ thuật của Anthropic gọi là kỹ thuật ngữ cảnh . Họ đã công bố một bài phân tích chuyên sâu về vấn đề này vào tháng 9 năm 2025 và bài viết đó rất đáng đọc nếu bạn muốn tìm hiểu sâu hơn những gì bài viết này đề cập. Câu tóm tắt của họ là câu hay nhất mà tôi từng thấy về chủ đề này:
“Kỹ thuật tạo ngữ cảnh tốt nghĩa là tìm ra tập hợp nhỏ nhất có thể các token tín hiệu cao nhằm tối đa hóa khả năng đạt được kết quả mong muốn.”
Cách tiếp cận đó thực sự đã thay đổi cách tôi sử dụng AI hàng ngày. Thay vì hỏi tôi nên đưa gì vào, giờ đây tôi hỏi tôi có thể bỏ gì đi (một lần nữa, "càng ít càng tốt" lại đúng).
Dưới đây là các chiến thuật được rút ra từ đó.
1. Mỗi cuộc trò chuyện chỉ nên giao một nhiệm vụ và nên bắt đầu lại từ đầu thường xuyên.
Đây là thói quen hữu ích nhất mà tôi đã học được. Nếu bạn đang nghiên cứu một chủ đề rồi chuyển sang chủ đề khác, hãy bắt đầu một cuộc trò chuyện mới. Nếu bạn hoàn thành bản thảo và muốn chỉnh sửa thêm, hãy bắt đầu một cuộc trò chuyện mới. Nếu bạn dành một giờ để gỡ lỗi một vấn đề và vấn đề tiếp theo không liên quan, hãy bắt đầu một cuộc trò chuyện mới.
Teresa Torres, người viết về công việc phát triển sản phẩm AI trên Product Talk, đã diễn đạt rất hay : mỗi cuộc trò chuyện dài đều tích tụ thêm nhiễu loạn, và nhiễu loạn đó đang chủ động làm cho phản hồi tiếp theo trở nên tồi tệ hơn.
2. Sử dụng kỹ thuật chuyển giao
Khi cần tiếp tục nội dung, hãy yêu cầu người mẫu viết một bản tóm tắt ngắn gọn những điểm quan trọng trước khi bạn bắt đầu lại. Sao chép và dán nó vào cuộc trò chuyện mới làm tin nhắn mở đầu.
Về cơ bản, đây là những gì Claude Code tự động thực hiện khi đạt đến giới hạn ngữ cảnh. Anthropic gọi đó là nén dữ liệu , và họ mô tả nó trong bài viết về kỹ thuật ngữ cảnh như là đòn bẩy đầu tiên bạn nên sử dụng. Họ bảo toàn các quyết định kiến trúc, các lỗi chưa được giải quyết và các tệp quan trọng trong khi loại bỏ các đầu ra công cụ dư thừa và các thông báo cũ. Bạn có thể thực hiện điều tương tự theo cách thủ công với bất kỳ công cụ AI nào.
3. Quan sát đường 50%
Arthur Clune, người làm việc trong lĩnh vực sản phẩm AI, đã đưa ra một nhận xét rất sắc bén trong một bài đăng gần đây. Độ chính xác của LLM bắt đầu giảm đáng kể khi cửa sổ ngữ cảnh đầy khoảng 50%. Cơ chế nén của Anthropic tự động kích hoạt ở mức 95%, điều đó có nghĩa là đến lúc bạn nhìn thấy thông báo, bạn đã hoạt động ở chế độ suy giảm hiệu suất được một thời gian rồi.
Đó là lý do tại sao bạn không nên chỉ chờ Claude Code tự động nén, vì điều đó chỉ xảy ra khi bạn gần đạt đến giới hạn. Bạn có thể tự chạy nó bằng cách gõ /compact bất cứ khi nào bạn muốn.
4. Hãy chọn lọc thông tin trước khi làm việc với AI.
Việc chỉ chọn lọc 5 tài liệu liên quan sẽ mang lại kết quả tốt hơn là nhồi nhét 50 tài liệu vào và hy vọng AI có thể "tự hiểu". Mô hình không phải lúc nào cũng biết điều gì quan trọng (và chắc chắn nó không biết điều gì quan trọng đối với riêng bạn). Vì vậy, hãy tận dụng lợi thế của con người khi còn có thể.
5. Đặt những nội dung quan trọng ở đầu hoặc cuối.
Nghiên cứu về hiện tượng thông tin bị chìm ở giữa đã được chứng minh là đúng qua nhiều thế hệ mô hình. Thông tin ở đầu và cuối câu hỏi thường thu hút sự chú ý hơn thông tin bị chôn vùi ở giữa. Nếu bạn có một tài liệu dài và một đoạn văn thực sự quan trọng, hãy nhắc lại đoạn văn đó ở cuối câu hỏi, ngay cả khi nó đã xuất hiện vài lần trong tài liệu.
6. Sử dụng Dự án hoặc GPT tùy chỉnh để duy trì ngữ cảnh
Claude có các Dự án. ChatGPT có các GPT Tùy chỉnh. Cả hai đều cho phép bạn thiết lập lời nhắc hệ thống cố định và tải lên các tệp tham chiếu mà không tính vào ngữ cảnh của từng cuộc trò chuyện riêng lẻ. Nếu bạn có Use Case lặp đi lặp lại, hãy đặt hướng dẫn và tài liệu tham khảo vào một Dự án hoặc GPT Tùy chỉnh thay vì lặp lại chúng trong mỗi cuộc trò chuyện.
7. Sử dụng RAG cho các cơ sở tri thức lớn.
RAG là viết tắt của Retrieval Augmented Generation (Tạo thông tin được tăng cường bằng cách truy xuất). Thay vì đưa hàng nghìn tài liệu vào lời nhắc, bạn lập chỉ mục chúng trong cơ sở dữ liệu vector, và chỉ lấy ra những phần thông tin liên quan nhất cho mỗi câu hỏi. Đây chính là cách mà các công cụ như Perplexity, NotebookLM và tính năng nghiên cứu chuyên sâu của ChatGPT hoạt động. Tôi sẽ đề cập chi tiết hơn về RAG trong một bài viết khác, nó xứng đáng được dành riêng một bài.
8. Chọn mô hình phù hợp với công việc
Gemini 3.1 Pro có giá rẻ cho việc xử lý tài liệu dung lượng lớn. Claude Opus 4.7 mạnh nhất trong việc suy luận dựa trên ngữ cảnh, còn Sonnet 4.6 là lựa chọn tầm trung tuyệt vời nếu chi phí là yếu tố quan trọng. GPT-5.5 là sản phẩm tiên tiến nhất hiện nay của OpenAI và có giá nằm giữa hai công cụ trên. Nếu bạn đang xử lý một tệp PDF 500 trang, Gemini có lẽ là công cụ phù hợp. Nếu bạn đang giải quyết một vấn đề phức tạp nhiều bước, Opus hoặc GPT có lẽ là công cụ tốt hơn.
9. Đối với các nhân viên, hãy tách biệt nhiệm vụ đọc và nhiệm vụ suy nghĩ.
Nếu bạn đang xây dựng các agent (hoặc sử dụng Claude Code, Cowork, Cursor, v.v.), nghiên cứu của Anthropic về các agent chạy dài hạn là vô cùng quý giá. Điểm mấu chốt là quá trình khám phá làm tiêu hao ngữ cảnh rất nhanh. Vì vậy, họ khuyến nghị sử dụng các subagent, được tạo ra cho các tác vụ đọc dữ liệu chuyên sâu cụ thể (tìm kiếm trên nhiều tệp, xem xét mã nguồn để tìm lỗi bảo mật) và chỉ trả về bản tóm tắt. Ngữ cảnh của agent chính vẫn được giữ nguyên.
Bạn cũng có thể áp dụng điều này theo cách thủ công. Nếu bạn muốn Claude nghiên cứu sâu một vấn đề nào đó rồi hành động dựa trên kết quả, hãy thực hiện nghiên cứu trong một cuộc trò chuyện, tóm tắt ngắn gọn và sử dụng bản tóm tắt đó làm điểm khởi đầu trong một cuộc trò chuyện mới để bắt đầu công việc hành động.
10. Đừng dán những hình ảnh bạn không cần.
Ảnh chụp màn hình khá tốn Token . Một ảnh chụp màn hình độ phân giải cao có thể dùng từ 1.000 đến 2.000 token. Nếu bạn tải lên 20 ảnh chụp màn hình vào một cuộc trò chuyện dài, chỉ riêng chi phí cho ảnh đã là từ 20.000 đến 40.000 token. Tôi rất thích chụp ảnh màn hình và thêm nội dung vào cuộc trò chuyện, nhưng đôi khi việc này có thể Bit quá đà, và đây là lời nhắc nhở tốt để không lạm dụng chúng.
Lời kết
Hy vọng điều này đã giúp bạn hiểu rõ Bit về cửa sổ ngữ cảnh là gì và cách chúng hoạt động. Hầu hết mọi người chỉ thấy những tiêu đề khoe khoang về cửa sổ ngữ cảnh lớn hơn và nghĩ rằng lớn hơn thì luôn tốt hơn, nhưng thực tế là tôi hiếm khi sử dụng quá 200.000 token cho bất kỳ tác vụ nào của mình hiện nay. Thỉnh thoảng tôi sẽ đạt đến 400-500.000 token trước khi nén lại, nhưng không thường xuyên như vậy.
Có lẽ/hy vọng một ngày nào đó vấn đề này sẽ được giải quyết và chúng ta có thể sử dụng 1 triệu hoặc thậm chí 10 triệu cửa sổ ngữ cảnh Token một cách đáng tin cậy mà không lo bị mất dữ liệu trong mớ hỗn độn đó.
Tuy nhiên, cho đến lúc đó, hãy chú ý đến ngữ cảnh. Thường xuyên bắt đầu các cuộc trò chuyện mới khi bạn có nhiệm vụ mới, chuyển giao công việc từ phiên này sang phiên khác và nhắc lại những điểm quan trọng ở đầu và cuối lời nhắc nếu bạn muốn có kết quả tốt hơn.
Cảm ơn các bạn đã luôn theo dõi, và hẹn gặp lại vào tuần sau!
Tuyên bố miễn trừ trách nhiệm: Nội dung trong bản tin này không được coi là lời khuyên đầu tư. Tôi không phải là cố vấn tài chính. Đây chỉ là ý kiến và quan điểm cá nhân của tôi. Bạn nên luôn tham khảo ý kiến của cố vấn tài chính chuyên nghiệp/có giấy phép trước khi giao dịch hoặc đầu tư vào bất kỳ sản phẩm liên quan đến tiền điện tử nào. Một số liên kết được chia sẻ có thể là liên kết giới thiệu.