

Tác giả: Zuo Ye
Thời trang có tính chu kỳ và Web 3 cũng vậy.
Gần "re" đã trở thành một chuỗi công khai AI. Với tư cách là một trong những người sáng lập Transformer, anh ấy đã có thể tham dự hội nghị NVIDIA GTC và nói chuyện với Lão Hoàng mặc áo da về tương lai của AI có khả năng sinh sản. Solana đã biến đổi thành công thành một nơi hội tụ cho io.net, Bittensor và Render Network. Đối với chuỗi khái niệm AI, cũng có những người chơi mới nổi tham gia vào lĩnh vực điện toán GPU như Akash, GAIMIN và Gensyn.
Nếu chúng ta nâng cao tầm nhìn của mình trong khi giá tiền tệ tăng, chúng ta có thể tìm thấy một số sự thật thú vị:
Cuộc chiến giành tỷ lệ băm GPU đến phi tập trung, tỷ lệ băm càng nhiều thì hiệu quả tính toán càng mạnh, CPU, bộ lưu trữ và GPU gắn liền với nhau;
Mô hình điện toán đang chuyển đổi từ đám mây hóa phi tập trung , đằng sau đó là sự thay đổi về nhu cầu từ đào tạo AI sang lý luận.
Thành phần phần mềm và phần cứng cơ bản cũng như logic vận hành của kiến trúc Internet về cơ bản không thay đổi và lớp tỷ lệ băm phi tập trung chịu trách nhiệm nhiều hơn trong khích lệ kết nối mạng.
Đầu tiên chúng ta hãy phân biệt về mặt khái niệm, tỷ lệ băm đám mây trong thế giới Web3 ra đời trong thời đại khai thác nền tảng đám mây. Nó đề cập đến việc đóng gói và bán tỷ lệ băm của các máy khai thác, loại bỏ khoản chi phí khổng lồ của người dùng để mua máy khai thác. các nhà sản xuất tỷ lệ băm thường “bán quá mức”, chẳng hạn như Trộn và bán tỷ lệ băm của 100 máy khai thác cho 105 người để thu được lợi nhuận vượt mức cuối cùng khiến thuật ngữ này tương đương với một lời nói dối.
Tỷ lệ băm đám mây trong bài viết này đề cập cụ thể đến tài nguyên tỷ lệ băm của các nhà cung cấp đám mây dựa trên GPU. Câu hỏi ở đây là liệu nền tảng tỷ lệ băm phi tập trung là con rối phía trước của nhà cung cấp đám mây hay là bản cập nhật phiên bản tiếp theo.
Sự tích hợp giữa các nhà cung cấp đám mây truyền thống và blockchain sâu hơn chúng ta tưởng tượng. Ví dụ: nút chuỗi công khai , quá trình phát triển và lưu trữ hàng ngày về cơ bản sẽ xoay quanh AWS, Alibaba Cloud và Huawei Cloud, loại bỏ khoản đầu tư đắt đỏ khi mua phần cứng vật lý. gây ra không thể bỏ qua, trong trường hợp cực đoan, việc rút cáp mạng sẽ khiến chuỗi công khai bị sập, vi phạm nghiêm trọng tinh thần phi tập trung .
Mặt khác, các nền tảng tỷ lệ băm phi tập trung hoặc trực tiếp xây dựng "phòng máy tính" để duy trì sự ổn định của mạng hoặc trực tiếp xây dựng các mạng khích lệ, chẳng hạn như chiến lược airdrop của IO.NET để thúc đẩy số lượng GPU và bộ lưu trữ của Filecoin để gửi token FIL . Điểm khởi đầu không phải là để đáp ứng nhu cầu sử dụng mà là để trao quyền cho token. Một bằng chứng là các nhà sản xuất, cá nhân hoặc tổ chức học thuật lớn hiếm khi thực sự sử dụng chúng để đào tạo, lý luận hoặc kết xuất đồ họa ML, dẫn đến lãng phí tài nguyên nghiêm trọng.
Tuy nhiên, trước tình hình giá tiền tệ tăng cao và tâm lý FOMO, mọi cáo buộc cho rằng tỷ lệ băm phi tập trung là một trò lừa đảo tỷ lệ băm đám mây đã biến mất.
Hai loại tỷ lệ băm có trùng tên và may mắn không?
Suy luận và FLOPS, định lượng sức mạnh tính toán của GPU
Yêu cầu về tỷ lệ băm của các mô hình AI đang phát triển từ đào tạo sang suy luận.
Hãy lấy Sora của OpenAI làm ví dụ, mặc dù nó cũng được sản xuất dựa trên công nghệ Transformer nhưng kích thước thông số của nó được so sánh với hàng nghìn tỷ của GPT-4, giới học thuật suy đoán rằng nó dưới hàng trăm tỷ, Yang Likun thậm chí còn nói rằng đó là chỉ 3 tỷ, tức là đào tạo Chi phí thấp, cũng rất dễ hiểu, tài nguyên tính toán cần thiết cho một số lượng nhỏ các tham số cũng bị suy giảm tương ứng.
Nhưng đổi lại, Sora có thể cần khả năng "lý luận" mạnh mẽ hơn. Lý luận có thể được hiểu là khả năng tạo ra các video cụ thể theo hướng dẫn. Video từ lâu đã được coi là nội dung sáng tạo nên đòi hỏi khả năng hiểu AI mạnh hơn và việc đào tạo tương đối đơn giản Có thể hiểu là việc tóm tắt các quy tắc dựa trên nội dung hiện có, xếp chồng tỷ lệ băm không cần não và làm việc chăm chỉ để tạo ra những điều kỳ diệu.
Trước đây, tỷ lệ băm AI chủ yếu được sử dụng cho đào tạo, một lượng nhỏ dùng cho khả năng suy luận và về cơ bản được bao phủ bởi nhiều sản phẩm khác nhau của NVIDIA. Tuy nhiên, sau sự ra đời của Groq LPU (Bộ xử lý ngôn ngữ), mọi thứ bắt đầu thay đổi, và khả năng suy luận tốt hơn, các mô hình lớn được xếp chồng lên nhau để thu gọn và cải thiện độ chính xác, cũng như việc sử dụng bộ não để nói logic đang dần trở thành xu hướng chủ đạo.
Ngoài ra, tôi xin bổ sung thêm cách phân loại GPU, người ta thường thấy chính người chơi game cứu vãn AI, điều hợp lý là nhu cầu mạnh mẽ về GPU hiệu suất cao trên thị trường game bao gồm cả hoạt động nghiên cứu và phát triển. Ví dụ: card đồ họa 4090, những người chơi game và thuật giả kim AI có thể sử dụng được, nhưng cần lưu ý rằng thẻ game và thẻ tỷ lệ băm sẽ dần được tách rời. Quá trình này tương tự như sự phát triển của máy khai thác Bitcoin từ máy tính cá nhân đến máy khai thác chuyên dụng và các chip được sử dụng cũng tuân theo thứ tự từ CPU, GPU, FPGA và ASIC.
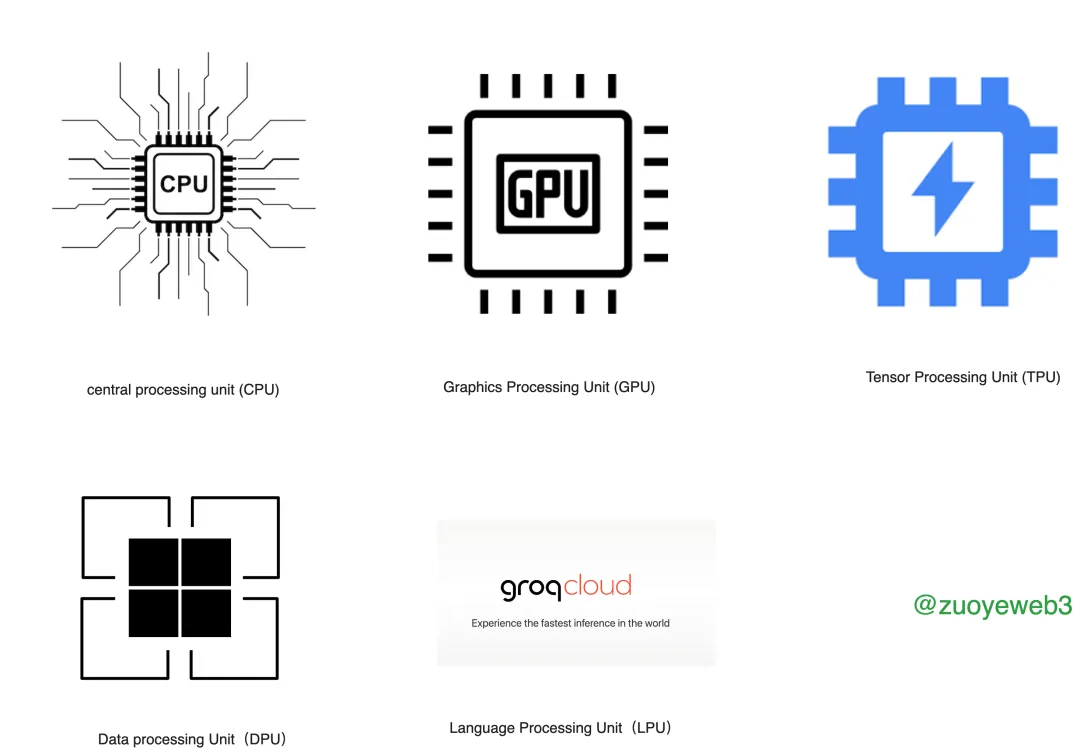
Thẻ đặc biệt LLM đang được phát triển...
Khi công nghệ AI, đặc biệt là lộ trình LLM, trưởng thành và tiến bộ, sẽ ngày càng có nhiều nỗ lực tương tự đối với TPU, DPU và LPU. Tất nhiên, sản phẩm chính hiện tại là GPU của NVIDIA. Tất cả các cuộc thảo luận dưới đây cũng dựa trên GPU và LPU Chờ đợi thêm là sự bổ sung cho GPU và sẽ mất một thời gian để thay thế hoàn toàn.
Cuộc cạnh tranh tỷ lệ băm phi tập trung không cạnh tranh giành các kênh mua lại GPU mà cố gắng thiết lập các mô hình lợi nhuận mới.
Tại thời điểm viết bài này, NVIDIA gần như đã trở thành nhân vật chính. Về cơ bản, NVIDIA chiếm 80 % thị trường card đồ họa. Tranh chấp giữa card N và card A chỉ tồn tại trên lý thuyết, thực tế thì mọi người đều đang nói về tính chính trực.
Sự địa vị tuyệt đối đã tạo ra sự cạnh tranh khốc liệt về GPU, từ RTX 4090 cấp độ người tiêu dùng đến A100/H100 cấp doanh nghiệp và các nhà cung cấp đám mây khác nhau là lực lượng chính trong việc tích trữ. Tuy nhiên, các công ty liên quan đến AI như Google, Meta, Tesla và OpenAI đều có hành động hoặc kế hoạch sản xuất chip tự sản xuất, còn các công ty trong nước đã chuyển hướng sang các nhà sản xuất trong nước như Huawei, và đường đua GPU vẫn vô cùng đông đúc.
Đối với các nhà cung cấp tỷ lệ băm mây truyền phi tập trung , thứ họ bán thực chất là tỷ lệ băm và dung lượng lưu trữ, nên việc có sử dụng chip của riêng họ hay không không cấp bách như các công ty AI. so với đám mây truyền thống Các nhà sản xuất đang cạnh tranh kinh doanh tỷ lệ băm , tập trung vào sức mạnh tính toán giá rẻ và dễ kiếm, tuy nhiên, giống như khai thác Bitcoin trong tương lai, khả năng chip Web3 AI xuất hiện là rất ít.
Một nhận xét bổ sung, kể từ khi Ethereum chuyển sang PoS, ngày càng có ít phần cứng chuyên dụng hơn trong cộng đồng tiền điện tử. Thị trường cho điện thoại di động Saga, tăng tốc phần cứng ZK và DePIN quá nhỏ. Tôi hy vọng phi tập trung tỷ lệ băm phi tập trung có thể được khám phá cho các chuyên dụng Thẻ tỷ lệ băm AI. Tạo lối đi riêng cho Web3.
Tỷ lệ băm phi tập trung là bước tiếp theo hoặc bổ sung cho đám mây.
Sức mạnh tính toán của GPU thường được so sánh trong ngành với FLOPS (Hoạt động dấu phẩy động mỗi giây), đây là chỉ báo được sử dụng phổ biến nhất để đo tốc độ tính toán. Bất kể thông số kỹ thuật của GPU hay các biện pháp tối ưu hóa như song song ứng dụng, cuối cùng nó vẫn là dựa trên FLOPS ở mức cao và thấp.
Đã mất khoảng nửa thế kỷ từ tính toán cục bộ đến chuyển sang đám mây và khái niệm phân phối đã tồn tại kể từ khi máy tính ra đời. Được thúc đẩy bởi LLM, sự kết hợp giữa phi tập trung và tỷ lệ băm không còn mơ hồ như trước nữa. Tôi sẽ làm như vậy Tóm tắt càng nhiều dự án tỷ lệ băm phi tập trung hiện có càng tốt, chỉ với hai khía cạnh:
Số lượng phần cứng như GPU được dùng để đo tốc độ tính toán của chúng, theo Định luật Moore, GPU càng mới thì sức mạnh tính toán càng mạnh, số lượng GPU có cùng thông số kỹ thuật càng nhiều thì sức mạnh tính toán càng mạnh;
Phương pháp tổ chức lớp khích lệ là một đặc điểm của ngành Web3. Token , chức năng quản trị bổ sung, khích lệ airdrop , v.v. giúp dễ hiểu hơn về giá trị lâu dài của từng dự án, thay vì tập trung quá mức vào giá tiền tệ ngắn hạn và chỉ xem xét về lâu dài bạn có thể sở hữu hoặc gửi đi bao nhiêu GPU.
Từ góc độ này, tỷ lệ băm phi tập trung vẫn dựa trên lộ trình DePIN của "phần cứng + mạng khích lệ hiện có", hoặc kiến trúc Internet vẫn là lớp dưới cùng và lớp tỷ lệ băm phi tập trung là khả năng kiếm tiền sau khi "ảo hóa phần cứng", tập trung vào truy cập mà không được phép. Mạng thực sự vẫn cần có sự hợp tác của phần cứng.
Tỷ lệ băm phi tập trung và GPU cần được tập trung
Với sự trợ giúp của khuôn khổ bộ ba bất khả thi blockchain , tính bảo mật của tỷ lệ băm phi tập trung không cần phải được xem xét đặc biệt. Vấn đề chính là phi tập trung và mở rộng . Sau này là mục đích của mạng GPU, hiện đang đi đầu trong AI. .
Bắt đầu từ một nghịch lý, nếu muốn hoàn thành dự án tỷ lệ băm phi tập trung thì số lượng GPU trên mạng phải càng lớn càng tốt, không có lý do nào khác, thông số của các mô hình lớn như GPT đang bùng nổ, và có không có GPU ở quy mô nhất định. Không thể có hiệu ứng đào tạo hoặc suy luận.
Tất nhiên, so với sự kiểm soát tuyệt đối của các nhà cung cấp đám mây, ở giai đoạn hiện tại, các dự án tỷ lệ băm phi tập trung ít nhất có thể thiết lập các cơ chế như không có quyền truy cập và di chuyển tự do tài nguyên GPU. là một nhóm khai thác tương tự trong tương lai? Sản phẩm có thể không giống nhau.
Xét về mở rộng, GPU không chỉ có thể được sử dụng cho AI mà điện toán đám mây và kết xuất cũng là những con đường khả thi.Ví dụ, Render Network tập trung vào công việc kết xuất, trong khi Bittensor và những người khác tập trung vào việc cung cấp đào tạo mô hình. mở rộng tương đương với các kịch bản và mục đích sử dụng.
Do đó, hai tham số bổ sung có thể được thêm vào GPU và mạng khích lệ, đó là phi tập trung và mở rộng, để tạo thành chỉ báo so sánh từ bốn góc độ. Xin lưu ý rằng phương pháp này khác với so sánh kỹ thuật và hoàn toàn chỉ là một bức tranh.
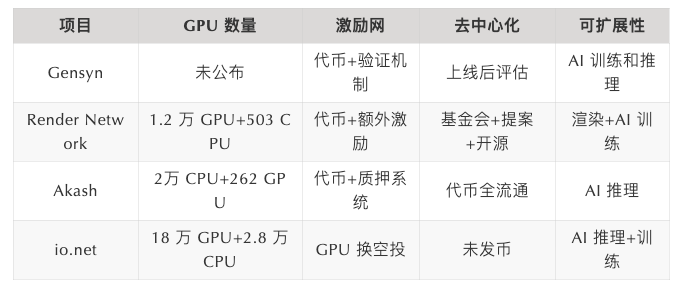
Trong các dự án nêu trên, Render Network thực sự rất đặc biệt, về bản giảm nó là một mạng kết xuất phân tán và mối quan hệ của nó với AI không trực tiếp. , Các thuật toán như Giảm dần độ dốc ngẫu nhiên) hoặc truyền ngược yêu cầu tính nhất quán, nhưng kết xuất và các tác vụ khác không nhất thiết phải như vậy. Video và hình ảnh thường được phân đoạn để tạo điều kiện phân phối nhiệm vụ.
Khả năng đào tạo AI của nó chủ yếu được tích hợp với io.net và tồn tại dưới dạng plug-in của io.net. Dù sao thì GPU vẫn hoạt động, dù khó khăn đến đâu, điều đáng mong chờ hơn là việc nó đào tẩu sang Solana tại thời điểm bị đánh giá thấp, sau đó người ta đã chứng minh rằng Solana phù hợp hơn với yêu cầu hiệu suất cao của kết xuất và các mạng khác.
Thứ hai là lộ trình phát triển quy mô của io.net về việc thay thế GPU bạo lực. Hiện tại, trang web chính thức liệt kê đầy đủ 180.000 GPU. Đây là cấp độ đầu tiên của dự án tỷ lệ băm phi tập trung . Có một mức độ chênh lệch lớn so với các đối thủ khác, và Về mở rộng , io.net tập trung vào lý luận AI và đào tạo AI là một cách làm việc thực hành.
Nói một cách chính xác, đào tạo AI không phù hợp để triển khai phân tán, ngay cả đối với LLM nhẹ, số lượng tham số tuyệt đối sẽ không ít hơn nhiều.Phương pháp tính toán tập trung sẽ tiết kiệm chi phí hơn về mặt chi phí kinh tế.Web 3 và Điểm tích hợp của AI trong đào tạo thiên về các hoạt động mã hóa và crypto dữ liệu nhiều hơn, chẳng hạn như công nghệ ZK và FHE, đồng thời AI suy luận Web 3 có tiềm năng lớn, một mặt nó có yêu cầu tương đối thấp về hiệu suất tính toán GPU và có thể chịu được một mức độ mất mát nhất định. Mặt khác, lý luận AI gần với khía cạnh ứng dụng hơn và khích lệ từ góc độ người dùng là đáng kể hơn.
Filecoin, một công ty khác khai thác và trao đổi mã thông báo, cũng đã đạt được thỏa thuận sử dụng GPU với io.net. Filecoin sẽ sử dụng 1.000 GPU của mình song song với io.net. Đây có thể coi là nỗ lực chung giữa những người đi trước. Chúc các bạn cả hai đều may mắn.
Tiếp theo là Gensyn, chưa được ra mắt . Chúng tôi cũng sẽ lên đám mây để đánh giá. Vì nó vẫn đang trong giai đoạn đầu xây dựng mạng nên số lượng GPU chưa được công bố. Tuy nhiên, kịch bản sử dụng chính của nó là AI Cá nhân tôi cảm thấy số lượng GPU hiệu suất cao không hề nhỏ, ít nhất là vượt xa cấp độ của Render Network. So với AI suy luận, đào tạo AI có mối quan hệ cạnh tranh trực tiếp với các nhà cung cấp đám mây và việc thiết kế cơ chế cụ thể sẽ trở nên phức tạp hơn
Cụ thể, Gensyn cần đảm bảo tính hiệu quả của việc đào tạo mô hình, đồng thời, để nâng cao hiệu quả đào tạo, nó sử dụng các mô hình điện toán off-chain trên quy mô lớn, do đó, hệ thống xác minh mô hình và chống gian lận đòi hỏi nhân vật bên long. Trò chơi:
Người gửi: Người khởi xướng nhiệm vụ, người cuối cùng sẽ trả chi phí đào tạo.
Người giải quyết: đào tạo mô hình và cung cấp bằng chứng về tính hiệu quả.
Người xác minh: Xác minh tính hợp lệ của mô hình.
Người tố cáo: Kiểm tra hoạt động của trình xác thực.
Nhìn chung, phương thức hoạt động tương tự như cơ chế khai thác PoW + bằng chứng lạc quan. Kiến trúc rất phức tạp. Có thể việc di chuyển các tính toán ra khỏi chuỗi có thể tiết kiệm chi phí, nhưng sự phức tạp của kiến trúc sẽ mang lại thêm chi phí vận hành. Hiện tại, phi tập trung chính tỷ lệ băm Tập trung vào thời điểm lý luận AI, tôi cũng chúc Gensyn may mắn.
Cuối cùng là Akash cũ, về cơ bản đã bắt đầu cùng với Render Network. Akash tập trung vào phi tập trung CPU, còn Render Network là người đầu tiên tập trung vào phi tập trung GPU. Không ngờ, sau khi AI bùng nổ, cả hai bên đều bước vào cuộc chiến lĩnh vực điện toán GPU + AI.Sự khác biệt Akash quan tâm nhiều hơn đến khả năng suy luận.
Chìa khóa cho sự trẻ hóa của Akash là quan tâm đến các vấn đề khai thác sau khi nâng cấp Ethereum . GPU nhàn rỗi không chỉ được các nữ sinh viên đại học sử dụng như đồ cũ cho mục đích cá nhân mà giờ đây họ còn có thể cùng nhau làm việc trên AI. tất cả họ đều đang đóng góp cho nền văn minh nhân loại.
Tuy nhiên, một điều tốt về Akash là về cơ bản token đã được lưu hành đầy đủ. Xét cho cùng, đây là một dự án rất cũ và nó cũng tích cực áp dụng hệ thống đặt cược thường được sử dụng trong PoS. Tuy nhiên, đội ngũ dường như theo đạo Phật hơn và họ không trẻ trung như io.net.
Ngoài ra, còn có THETA dành cho điện toán đám mây biên, Phoenix cung cấp các giải pháp thích hợp cho tỷ lệ băm AI và các công ty điện toán cũ và mới như Bittensor và Ritual. thực sự khó tìm Ít hơn số lượng GPU và các thông số khác.
Phần kết luận
Trong suốt lịch sử máy tính, các phiên bản phi tập trung của nhiều mô hình điện toán khác nhau có thể được xây dựng. Điều đáng tiếc duy nhất là chúng không có tác động đến các ứng dụng chính thống. Dự án điện toán Web3 hiện tại chủ yếu là tự quảng bá trong ngành. Người sáng lập Near đã đi đến hội nghị GTC Đó cũng là do quyền tác giả của Transformer chứ không phải tư cách người sáng lập của Near.
Điều bi quan hơn nữa là quy mô thị trường điện toán đám mây hiện tại và những người chơi quá mạnh. Liệu io.net có thể thay thế AWS? Nếu có đủ GPU thì thực sự có thể. Suy cho cùng, AWS từ lâu đã sử dụng Redis mã mã nguồn mở làm nền tảng thành phần.
Ở một khía cạnh nào đó, sức mạnh của mã nguồn mở và phi tập trung không bằng nhau. Các dự án phi tập trung trung tập trung quá mức vào các lĩnh vực tài chính như DeFi và AI có thể là con đường then chốt để thâm nhập thị trường phổ thông.






