

作者:深潮 TechFlow
随着 BTC 突破10万美金,牛市预期下更多资金在寻找着新项目和机会。
但如果你要问当前哪个赛道最有机会?那 AI Agent 必须拥有姓名。不过,在每天都有大量 AI Agent 推出的现在,整个赛道的叙事也在逐渐分层:
一类是围绕 AI Agent 的应用,对应的代币代表着 Meme 或是该 Agent 的用途;而另一类则是专注于为 AI Agent 提供能力的基建,让应用做的更好。
前者由于在应用层更容易被观察到,开始变得扎堆内卷;而后者相对而言更有突破的空间。
对 AI Agent 来说,还有哪些能力是它们刚需的?
Thanks for reading 深潮 TechFlow ! Subscribe for free to receive new posts and support my work.
或许我们能从最近火热的“ AI KOL ” aixbt 上寻找答案:
有研究发现,aixbt 说的话并不总是对的,它无法区分什么是真假,不能要求专家验证其假设,不能质疑自己。
本质上,因为 aixbt 其实是大语言模型,只能从各种公开的数据中进行抓取和总结,所以更像一个聚合公开信息的复读机。

所以,如果你能给这类 AI 代理更加多样化、个性化和私人化的数据,说不定它会做的更好。
比如,分享一个你交易低市值山寨币的心得,或是付费群里才愿意交流的投资策略让它学习... 但这些数据并不在台面上,aixbt 们得不到。
注意,这个世界并不是没有足够的数据,而是高质量的数据很难得到。
在当前 AI 代理的加密热潮中,数据类基建,其实是缺失的。
这里的一个叙事空间和信息差是,如果有项目能够搜集更加私人化和个性化的数据,同时喂给有需要的 AI 代理或者组织,或许会在这波热点中找到一个自己独特的生态位。
2个月前,我们曾写过一个名为 Vana 的项目,利用 DAO 的方式搜集各类公开市场上拿不到的数据,同时再利用代币化的方式激励数据贡献和引导这类数据的购买和使用。
只是当时的 AI Agent 还没有这么火,项目的使用场景似乎没有那么明确。而这波 AI Agent 浪潮中, Vana 显然有了更多的用武之地和更加自恰的环境。
恰逢 Vana 将于近期启动主网并发布自己的代币 $VANA,同时 Vana 也更新了自己的白皮书和代币经济学,对当前的数据问题和自己的定位有了更多详细的解释。
加密市场里,择时很重要。现在的 Vana,还有哪些新动态和变化值得关注?代币是否有着更多的利好预期?
我们读了读新发布的白皮书,带你快速搞懂现在的 Vana 。

数据“双花”,寻找收益时的盲区
毫无疑问,每个人都在追逐 AI 代理热潮中的收益。
任何人都可以轻松创建AI代理,AI代理对应的资产也可以轻松代币化... 但除了你购买 AI 代理对应的代币外,你还能获取哪些收益?
这个问题,对个人意味着新的机会,而对项目来说,则意味着新的叙事空间。
不要忘记,AI 代理可能正在拿你贡献过的数据来训练自己,但你没有因此赚到一分钱。例如前文提到的 aixbt,它所分析的加密热点,其中的来源之一,或许正是你在自己推特上写过的一篇文章。
因此,打开 Vana 的这份新白皮书,前几页的一个概念迅速引起了笔者的注意: 数据的"双花"困境。

双花,这个词是不是有点熟悉又陌生?
这个概念实际上源自比特币解决的双花问题(double spending)——即防止同一个比特币,被重复支付两次。
比特币解决这个问题的办法是,把一笔账目发生的来龙去脉记在一个公开的区块链上,它充当一个不能改的账本,所有人都知道一个币的所有历史流向,确保一个币在当前状态里只能花一次。
但在数据领域,这个问题表现得更为复杂。
与比特币不同,数据天然具有可复制性,这导致了一个 AI 热潮里被忽视的经济困境:当数据被直接出售时,买家可以轻易地将其复制和再分发,导致同一个数据实际上被利用了多次,而你也不能从这份利用中获得任何额外收益。
比如你自己写了个推文,一旦被某个AI代理利用和学习,就可能被无限制地分享给其他AI代理,最终导致这个数据失去稀缺性和经济价值。
如果你想搞一个类似于比特币的账本,把数据的使用记录在链上,去避免这个双花问题行不行?
第一,数据本身有时具有隐私性,公开记录并不合适,你也不愿意分享;第二,即使你记录了数据使用,仍然无法保证这个数据在链下继续被复制和转卖。第三,大家都想占用你数据的便宜,谁愿意加入你这个“利己但不利人”的账本体系中呢?
于是,有没有什么办法能解决数据的“双花问题”?
正如 Vana 的白皮书中所说,“数据主权和数据的集体创造并不互斥”。
我们速通了这份白皮书,一个太长不看的版本可以是:
Vana 协议提出了一个创新的解决方案,通过将隐私保护、可编程访问权限和经济激励机制巧妙地结合在一起,创建了一个全新的数据经济模型。
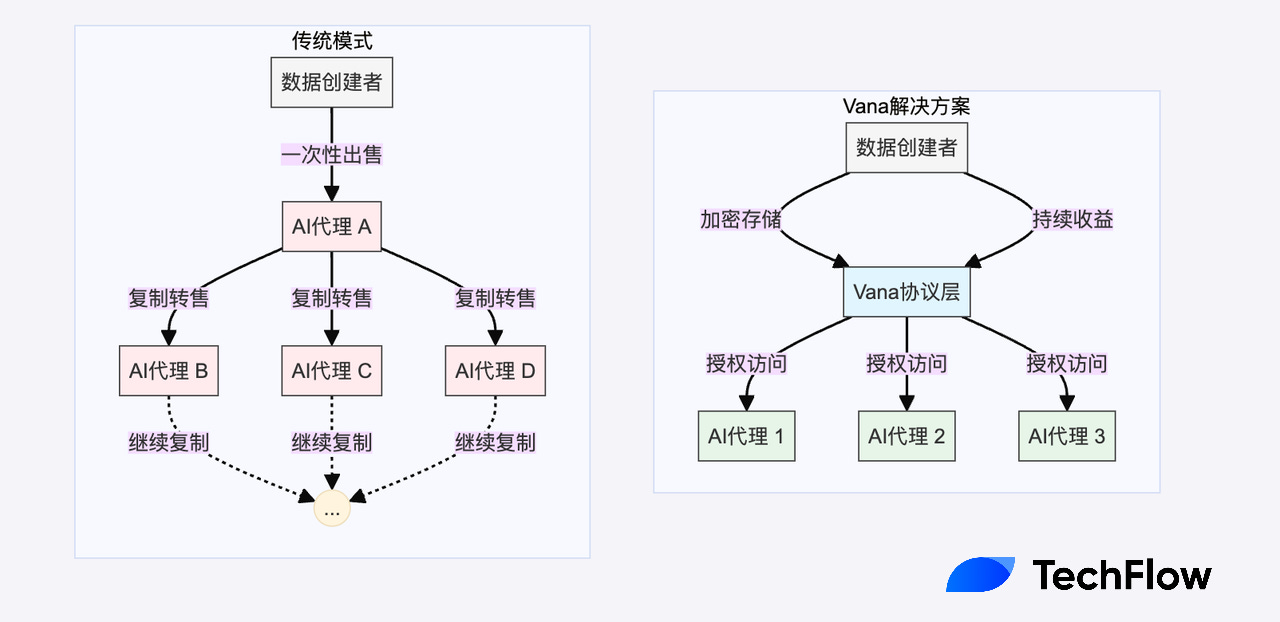
在这个模型中,数据始终保持加密状态,只有获得授权的实体才能在特定条件下访问;其次通过智能合约,数据所有者可以精确控制谁能访问数据,以及在什么条件下访问;更重要的是,这种访问权限可以被代币化和交易,而原始数据始终受到保护。
更为通俗的类比,可以是现代音乐产业的流媒体模式:
不是直接出售音乐文件(这样会导致无限复制),而是像 Spotify 这样的流媒体服务,每次使用都产生收益。
数据所有者不是一次性出售数据,而是保留控制权,并能从数据的每次使用中持续获得收益。这确保了数据既能被充分利用(例如用于 AI 训练),又能解决了"一次性出售"数据导致双花和贬值的问题,同时数据所有者始终保持对其数据的完整控制权。
以 DAO 为池,办个“数据合作社”
具体而言,Vana 要怎么做?
我们首先可以粗略把参与整个 AI 市场的人分成两拨 --- 需要用数据的公司/AI代理;(主动或被动)贡献数据的个人和组织。
想要做一个更高质量的 AI 代理,除了公开数据之外,他们的诉求很明显:
访问私人数据(private data),如你的健康数据用于医疗诊断类AI代理
访问付费数据(paywalled data),比如付费文章和洞察,用于商业分析类的AI代理
访问封闭平台数据(closed platform data),比如 X 上更多用户发过的帖子,用于舆情分析的AI代理
而作为有意或者无意贡献数据的另一方,你的诉求不外乎以下几点:
你可以访问,但数据所有权还是归我;
你可以访问,但数据得存在一个安全的地方;
你可以访问,但我要从中获益,按需付费
传统的数据使用模式往往将用户置于被动地位。例如,当 AI 公司需要训练数据时,要么直接从社交平台购买数据(用户无法从中受益),要么需要与数以万计的用户分别谈判(效率极低)。
而 Vana 解决问题的方式,叫做数据流动性池(Data Liquidity Pool,下称DLP)。你可以更接地气的把它理解成一个“数据合作社”:
用户可以将自己的数据权限集中在一个"池子"里,形成类似合作社的虚拟组织;这时也就意味着群体用户拥有了集体谈判的力量,同时保持对原始数据的加密控制。
想象一个由 10 万名 Twitter 用户组成的 DLP:当 AI 公司想要使用这些数据时,它们可以直接与 DLP 谈判,而收益会自动、公平地分配给所有贡献者。
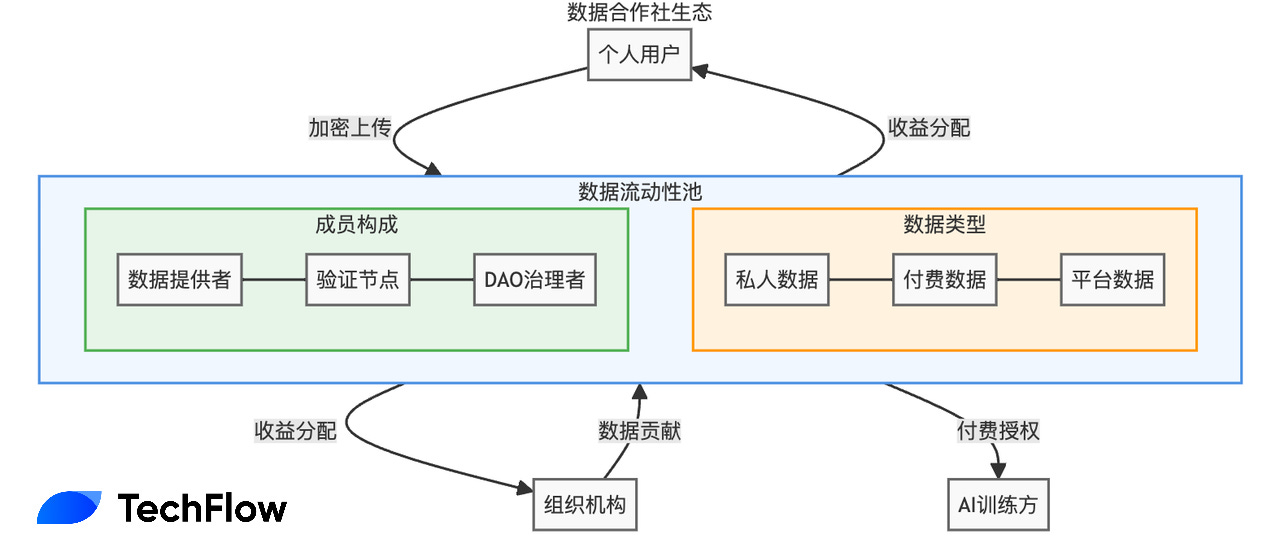
从 Vana 最近几天发布的白皮书内容来看,这个数据合作社(DLP)现在被办的有模有样,形成了4个关键的规则:
数据规范:入社指南
这有点像严格的入会标准,定义元数据的标准,如社媒数据,健康数据等等;核心是确保池中只有符合质量要求的数据;
验证机制:数据合作社的质检员
评估入池数据的质量和价值,确保加入的数据是真实的,即传统区块链意义上的验证节点
代币经济:用奖励调节社员行为
通过公平的积分系统,激励优质的数据贡献者;更多更好的数据,可以获得更多的代币奖励
治理规则:合作社章程
规定如何做决策,比如开一个新数据池等;同时也规定如何处理争议,这里也更多的体现出我们熟悉的 DAO 的特色。
所以总体上,这个数据合作社在加密世界的语境里,更像是一个围绕数据做决策和激励的 DAO,DAO 管理着数据池,也决定了和使用数据者谈判的规则,和利润分配的方式。
如果觉得上面的说法太通俗,那么落到Vana网络的设计中,上述 DAO 模式其实在按照严肃的技术方式在运作:
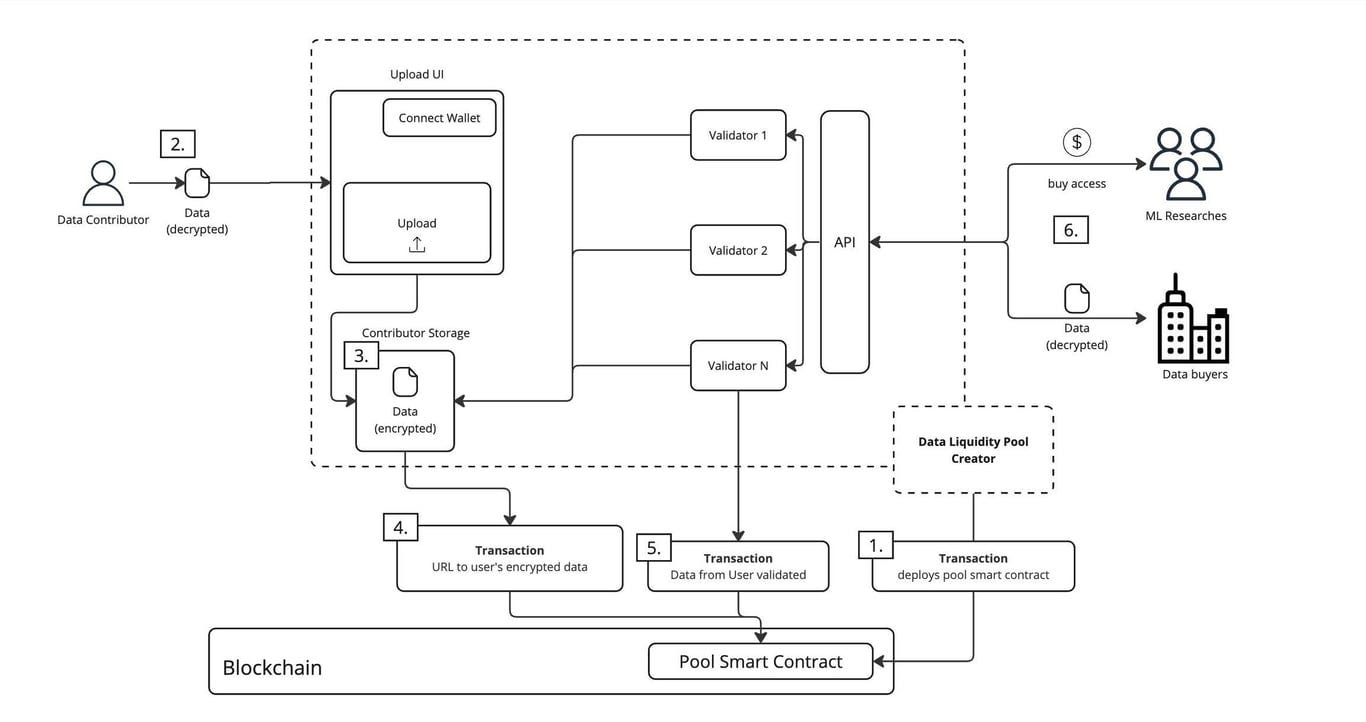
智能合约部署。DAO 创建者将池子的智能合约部署到区块链上,明确规定了数据如何管理、如何使用、收益如何分配等基本规则。
数据准备。数据提供者准备好想要贡献的数据,这些数据在提供前就已经进行加密处理。
安全存储。数据提供者需要先连接自己的钱包,证明身份后才能上传数据。上传的加密数据会被存储在贡献者专属的存储空间中。
链上记录。系统会在区块链上记录这份加密数据的访问地址,确保只有授权者才能访问数据。
多重验证。多个验证者会对数据进行审核,检查数据的真实性、质量和价值。这些验证结果会被记录在智能合约中,确保数据的可信度。
规范使用。经过验证的数据可以被两类用户使用:机器学习研究者可以付费使用数据来训练模型;数据购买者则可以在特定条件下访问数据。所有使用都需要支付费用,并且严格遵守智能合约规定的使用条件。
在数据隐私保护方面,限于篇幅和技术知识,笔者不再此具体展开。
如果担心这些数据是否会泄露,只需简要的把握下面这条主线,即 Vana 中所有个人数据始终保持加密状态,就像是被放在用户自己掌握钥匙的保险箱中。即使需要处理这些数据,也只能在特殊的安全环境(TEE)中进行,就像是银行的特殊清算室,所有操作都有严格的监控和记录。
特别值得一提的是,系统通过智能合约和加密机制的结合,实现了灵活但安全的访问控制。可以控制谁在什么时候可以访问什么数据,而所有的访问记录都会被妥善保存,以供审计。
以 DAO 为数据池,一个数据合作社模式即可以保护个人数据主权和收益,同时也能让需要更多个性化数据的AI代理们物尽其用。
百花齐放,专事专办的数据 DAO
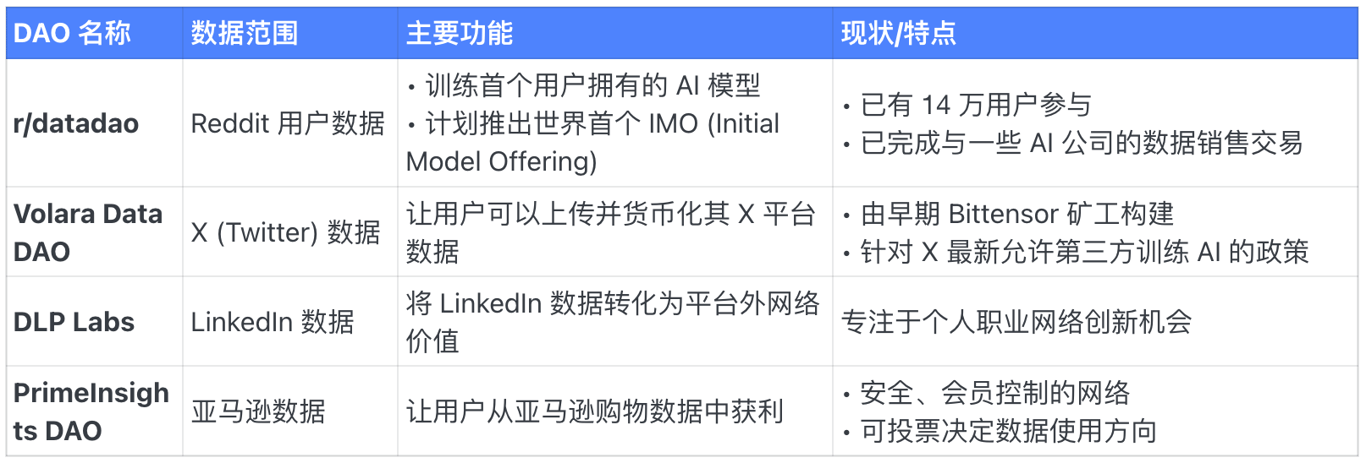
目前,Vana 上的这些数据流动性池并不只是停留在画饼阶段,而是确实形成了大大小小的数据 DAO。每个 DAO 里的数据都面向一种垂直场景,供不同的 AI 需求所使用。

以专注 X (推特)的 Volara DAO 为例,你可以连接自己的推特到这个平台,随后就可以上传自己的所有推文和相关社交数据,同时 Vlolara DAO 会按照你的贡献,给你对应的这个DAO 里的代币奖励。
注意,直接奖励并不是 Vana,而是这个 DAO 自有的代币,比如 $VOL。
这非常像目前火热的 Virtuals,一个母币下面有不同的项目创建的对应代币。而持有 VOL 则有资格获得 $VANA 的空投,资产嵌套的模式也给更多玩法创造了空间。
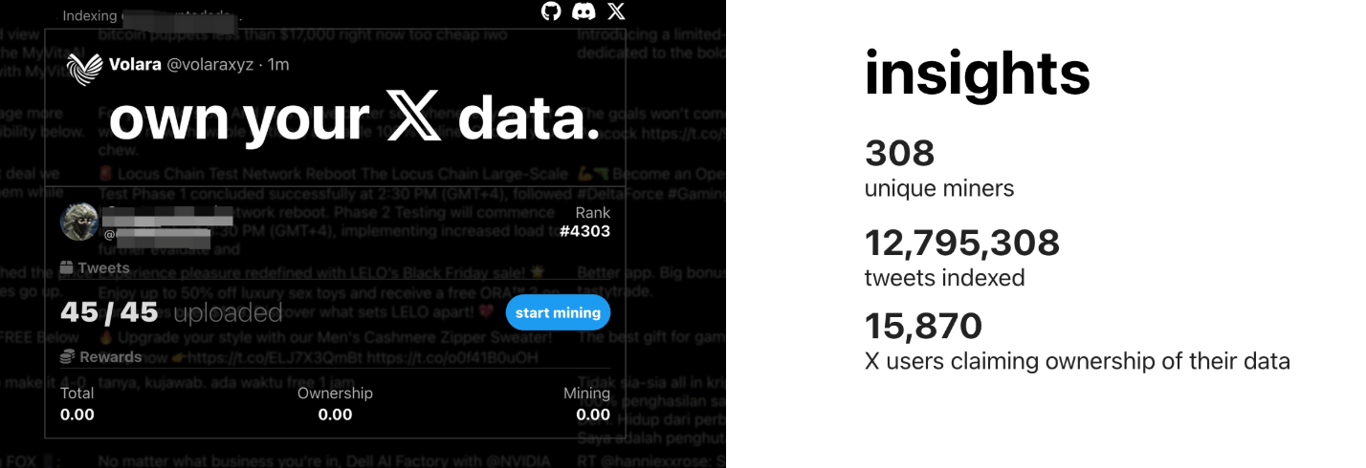
我们整理了 Vana 中目前比较流行的16个数据 DAO,并对其做了一个详细的分类。
对普通玩家来说,这更像一个“数据挖矿”的概念 --- 如果你看好某个DAO,可以按照它的规则去贡献数据,随后会给你对应的奖励和空投。
不过,你也并不一定拥有所有数据,所以也需要按照下述分类来看看自己能贡献哪些数据,找到最佳获取收益的方式:
平台类数据 DAO
设备与数据生成类 DAO

人类洞察与金融类 DAO

健康类 DAO

总体来看,自 2024 年 6 月开发者测试网启动以来,Vana 网络已吸引了 130 万用户、300 多个 数据DAO 和 170 万的日交易量。
随着主网上线和代币的推出,在经济激励的加持下,或许我们能看到更多数据 DAO 跑出来。
双层代币经济,更符合版本的玩法
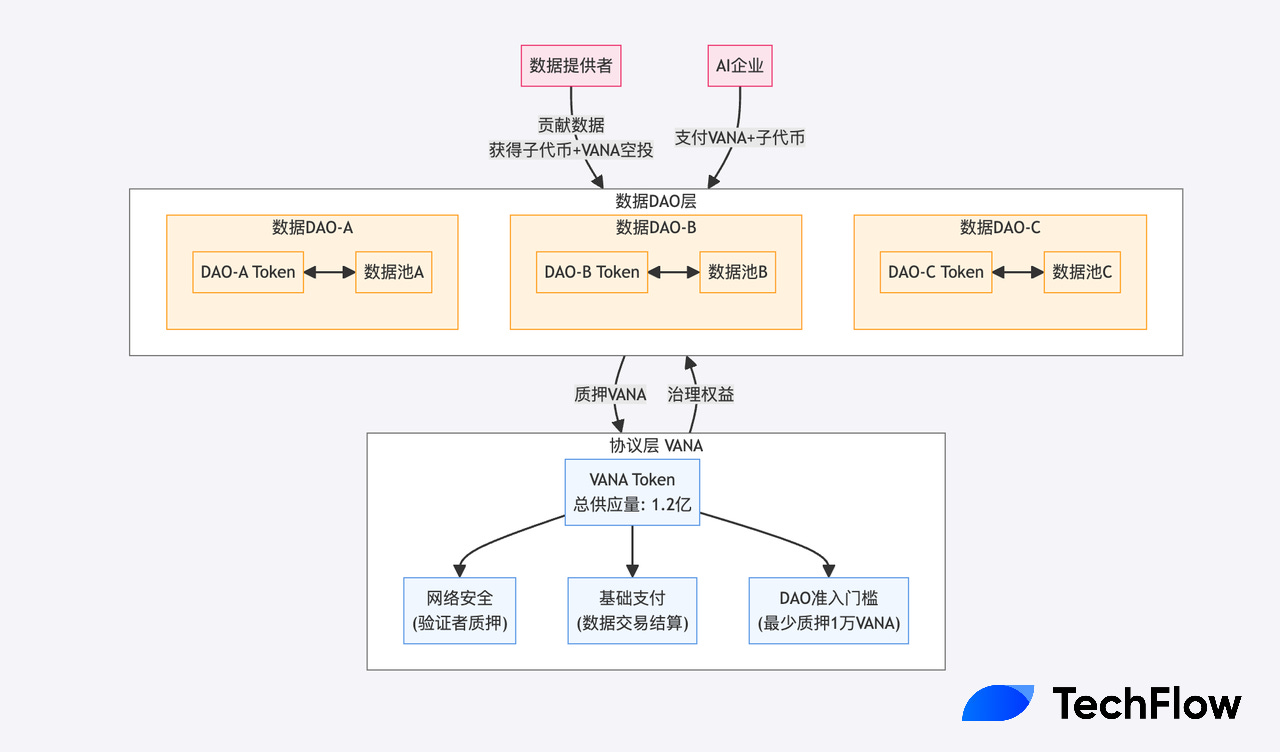
你可能已经发现,上述的 DAO 都有自己的子币,同时和母币 VANA 有对应的联系(如有空投等)。
这就涉及到了一个精心设计的双层代币经济模型。
想象一下传统的数据市场:医疗数据、金融数据、社交数据,它们的价值标准和使用场景都大不相同。用单一的代币来衡量和激励如此多样化的数据贡献,就像用一把尺子去量所有东西——从星球到原子。这显然不够精确,也不够灵活。
VANA 采用了一个更优雅的解决方案:在协议层面设置一个统一的基础代币(VANA),同时允许每个数据 DAO 发行自己的专属代币。
而母子币都有不同的分工和作用:
VANA:
供应量 1.2 亿枚。首先,它通过要求验证者质押VANA 来保障对应的网络安全;
其次,它作为所有交易的基础支付货币,比如AI企业需要这个 DAO 里的数据,就需要用VANA来支付;
最重要的是,它要求每个数据 DAO 必须质押至少 10,000 个 VANA 才能运营,这就像是一个"诚意金",确保 DAO 运营者对生态系统的长期承诺。
数据DAO们的代币:
每个数据 DAO 都可以设计符合自己领域特点的代币经济模型。比如,一个医疗数据 DAO 可能更注重数据的完整性和准确性,因此会设计特殊的奖励机制来鼓励高质量的病历数据提供;而一个社交数据 DAO 则可能更关注用户互动的活跃度和影响力。
这些专属代币不仅是简单的积分,而是构建了一个完整的价值捕获系统:当数据被使用时,需要同时支付 VANA 和对应的 DAO 代币。这就像是在使用数据时,既要支付"场地费"(VANA),又要支付"专项服务费"(DAO 代币)。
这个玩法有没有让你想起 Virtuals?
类似的,双层代币系统的精妙之处在于它创造了一个自我维持的经济循环:使用数据需要消耗代币,这些代币一部分会被销毁,造成通缩压力;同时,高质量的数据贡献会获得新的代币奖励,这又提供了适度的通胀动力。这种平衡确保了代币价值的稳定性,也激励了持续的数据贡献。
Vana 作为母币,有gas和质押功能,每个子DAO发自己的 token,与母币 VANA 组交易对,母币能够捕获到生态繁荣的收益。
从造资产和增加资产效率的角度来讲,VANA 这个玩法显然跟现在的 AI 代理热潮是匹配的。
对个人来说,这个系统让数据真正变成了一种可持续经营的资产。数据提供者不再是一次性卖出数据,而是通过持有代币,持续分享数据使用带来的收益。这就像是从"卖断制"转向了"版权分成制",极大地改善了数据创造者的利益。
同时,随着 Vana 主网将于近期上线(已公布代币经济学,主网上线预热中),在了解了这套双代币的玩法后,你能参与的事情至少有两个:
第一,如上文所说,去不同的数据 DAO 中贡献数据,以期获得子DAO的代币和对应的 VANA 空投;汇总链接在此。
第二,随着主网上线,我们也发现 Vana 的官网也有了变化,目前新增了一个 datahub 的页面,用来管理你参与的不同数据 DAO 以及对应的代币。
目前,该页面有一个预注册的活动,用于提前关联自己的身份和为获取奖励来做准备,建议感兴趣的玩家可以提前布局。
完成该注册行为后,会被提示成为“Early Explorer”。

总结
在目前的 AI Agent 热点里,AI Agent 的影响力越来越大,直到它铺满你的信息流和投资清单。
但 Vana 这个叙事实际上在说,你自己的影响力,其实比想象的要大。
通过贡献各类数据,成为 AI 热潮中的一份子;而通过数据资产的代币化,你也多了一种围绕资产创造的玩法。
不能否认的是,在加密世界里,创造资产是一条明线。谁离资产近,谁就能获得更多叙事空间和收益。
而其实当你的数据可以被代币化,笔者认为这是一条契合明线的暗线,更是个人拥抱、利用和参与 AI 智能体趋势的关键拼图。
数据层的叙事尚未被完全开发,Vana 究竟是否会被价值发现,市场也会给出答案。
深潮 TechFlow 是由社区驱动的深度内容平台,致力于提供有价值的信息,有态度的思考。
社区:
公众号:深潮 TechFlow
订阅频道:https://t.me/TechFlowDaily
进微信群添加助手微信:blocktheworld
向深潮 TechFlow 捐赠,获得祝福和永久记录
ETH:0x0E58bB9795a9D0F065e3a8Cc2aed2A63D6977d8A
BSC:0x0E58bB9795a9D0F065e3a8Cc2aed2A63D6977d8A






