

Gossipsub 的部分消息扩展和单元级传播
或者如何让 blob 传播更快、更高效
感谢 Raúl Kripalani、Alex Stokes 和 Csaba Kiraly 对早期草稿的反馈。
概述
Gossipsub 新增的部分消息扩展功能,允许节点无需硬分叉即可升级到单元级传播。这提升了本地内存池(getBlobs)数据的实用性。
这里有一个 PR 草案,指定了共识客户端如何使用部分消息扩展:通过部分消息规范添加单元传播,作者:MarcoPolo · 拉取请求 #4558 · ethereum/consensus-specs · GitHub 。
介绍
Fusaka 在EIP-7594中引入了 PeerDAS。如 EIP 所述,纠删码数据块以单元格列的形式传播。这些列的类型为DataColumnSidecar 。这些列通过 gossipsub 传播到网络。如果某个节点已从其本地内存池中获取某一列中所有引用的数据块,则它可以自行获取 DataColumnSidecar,而无需等待 Gossipsub 传播。然后,它还会传播该列以帮助快速传播。Gossipsub 的 IDONTWANT 消息用于抑制来自已拥有 IDONTWANT 消息的对等节点的此类推送。
如果一个区块的所有引用 blob 都出现在大多数节点的内存池中,那么达到托管要求的速度会很快。数据已经存储在本地。但是,即使只有一个 blob 缺失,节点也必须等待所有列在网络中传播完毕后才能达到托管要求。
理想情况下,我们只传播给定行缺失的单元格。这样节点就可以利用本地已有的数据。这就是 Gossipsub 的部分消息扩展所做的。
部分消息扩展允许节点简洁地发送、请求和广播单元。这是网络层的一项改进,无需共识机制变更,可以向后兼容的方式部署,并且无需硬分叉。
部分消息扩展概述
完整的草案规范可以在libp2p/specs找到。
部分消息的行为与普通的 Gossipsub 消息类似。关键区别在于,部分消息不是通过哈希值引用,而是通过组 ID 引用。组 ID 由应用程序定义,并且必须能够在无需完整消息的情况下推导出来。借助组 ID 和位图,节点可以有效地指定其缺少哪些部分以及可以提供哪些部分。
对于 PeerDAS,组 ID 即The Block块根。它在每个主题中都是唯一的。完整的列构成一条完整的消息,而单元则是最小的部分消息。单元由子网主题(列索引)、组 ID(区块根)以及位图中的位置唯一且简洁地标识。节点在收到The Block后即可开始广播和请求单元。这是最快的速度,因为The Block声明了包含的 blob。
使用常规 gossipsub 消息进行单元级传播非常棘手。每个单元都必须通过其完整的消息 ID(20 字节)引用,并且节点无法预先请求缺失的单元;它们必须首先知道单元如何映射到其对应的消息 ID。相比之下,使用部分消息时,节点会通过位图中的一位来引用每个单元,并且可以通过部分IHAVE和部分IWANT来交换它们能够提供什么以及它们需要什么的信息。
可以将部分消息急切地推送给对等方,而无需等待对等方请求部分消息,或者可以根据请求提供部分消息。
Gossipsub 部分消息需要应用程序的配合,因为应用程序知道消息是如何组合和拆分的。应用程序负责:- 对可用部分和缺失部分进行编码(例如位图)。- 解码部分请求,并使用已编码的部分消息进行响应。- 验证已编码的部分消息。- 合并已编码的部分消息。
假设示例流程
为了直观地了解部分消息在实际中的工作原理,请考虑以下两个示例。第一个例子使用即时推送来减少延迟,第二个例子则等待对方的请求,这可以减少重复消息,但会造成延迟(本例中 RTT 为 1/2)。
对于这两个例子,假设:
- Peer P 是区块的提议者。它知道区块中的所有 blob。
- 对等体 A 和 B 是验证者。
- The Block中的第一个 blob 之前并未公开分享给 A 和 B,因此他们都在本地内存池中丢失了这个 blob。
- P 连接到 A,A 连接到 B。P <=> A <=> B
急切推动
┌──────────────────┐ ┌──────────────────┐ ┌──────────────────┐│ P │ │ A │ │ B │└──────────────────┘ └──────────────────┘ └──────────────────┘┌────────────────┐ │ ││Proposes Block B│ │ │└───────┬────────┘ │ ││ ┌──────────────┐ │ │├───│Forwards block│──▶│ ┌──────────────┐ ││ └──────────────┘ ├───│Forwards block│──▶││ ┌──────────────┐ │ └──────────────┘ ││ │ Eager push │ │ ┌──────────────┐ │├───│cell at idx=0 │──▶│ │ Eager push │ ││ └──────────────┘ ├──│cell at idx=0 │──▶ ││ │ └──────────────┘ ││ │ ││ │ ││ │ │▼ ▼ ▼请求/响应
┌──────────────────┐ ┌──────────────────┐ ┌──────────────────┐│ P │ │ A │ │ B │└──────────────────┘ └──────────────────┘ └──────────────────┘│ │ │┌───────┴────────┐ │ ││Proposes Block B│ │ │└───────┬────────┘ │ ││ ┌──────────────┐ │ │├───│Forwards block│──▶│ ┌──────────────┐ ││ └──────────────┘ ├───│Forwards block│──▶││ ┌──────────────┐ │ └──────────────┘ ││ │ IWANT │ │ ┌──────────────┐ ││◀──│ idx=0 │───│ │ IWANT │ ││ └──────────────┘ │◀──│ idx=0 │───││ ┌──────────────┐ │ └──────────────┘ ││ │ Respond with │ │ ┌──────────────┐ │├───│ cell@idx=0 │──▶│ │ Respond with │ ││ └──────────────┘ ├───│ cell@idx=0 │──▶││ │ └──────────────┘ │▼ ▼ ▼请注意,对等体在知道对方拥有什么数据之前会请求数据。该请求包含在对方的 IWANT 位图中,该位图与 IHAVE 位图一起发送。这意味着,当对方能够提供数据时,数据可以在一个 RTT 内接收。相比之下,一个“宣布、请求、响应”流程需要 1.5 个 RTT。
出版策略
急切推送比请求/响应更快,但有发送重复信息的风险。
因此,出版策略应该是:
当确信这是该部分消息的第一次传递时,会急切地推动。
在具有私有 blob 的场景中,当节点收到私有 blob 时,以急切的推送进行转发是合理的。
在具有分片内存池的场景中,节点急切地推送它知道对等节点由于其分片策略而不会推送的单元是合理的。
作为一种弹性机制,一些重复信息是预料之中的,也是必需的。可以通过调整即时推送的概率和向对等节点请求的概率来调整重复信息的数量。
然而,即使是一个简单的策略,通过利用内存池中的本地数据,其性能也应该显著优于我们目前的全列方法。重复的部分消息会导致重复的单元格,而不是重复的整列。
Devnet 概念验证
目前有一个正在进行中的部分消息扩展的 Go 实现。此外,还有一个使用部分消息的Prysm 补丁。
为了验证概念,我们创建了一个 Kurtosis 开发网络,使用已修补的 Prysm 客户端连接到已修补的 geth 客户端(以便在 getBlobs 调用中返回部分 blob)。一些节点会使用“私有” blob 构建区块。当这种情况发生时,其他节点会只请求缺失的“私有”单元,并使用其本地内存池中的 blob 填充列的其余部分。
为了粗略地了解带宽节省情况,我们还创建了一个较小的峰度网络,该网络仅包含两个“超级”节点,用于接收和发送所有列。其中一个节点提议私有 blob。这意味着,当上述节点提议私有 blob 时, getBlobs 将无法为另一个节点返回完整的列。
我们测量了启用和禁用部分消息时DataColumnSidecar消息的发送数据。结果表明,启用部分消息后,节点发送的数据量减少了 10 倍。原因有二:
- 当前 Prysm 的部分消息实现从不主动推送。节点会等待收到请求后再响应数据。
- 仅发送请求的部分。如果某个列只有一个私有 Blob,则我们只发送该 Blob。
在这种低延迟环境中(使用峰度在本地运行),IDONTWANT 并不有效。因此,我们认为,不急切地推送数据会带来很大的好处。
然而,在存在私有 blob 的情况下,IDONTWANT 将不适用,因此这里的性能优势仍然代表更高延迟的更现实的环境。
图表:
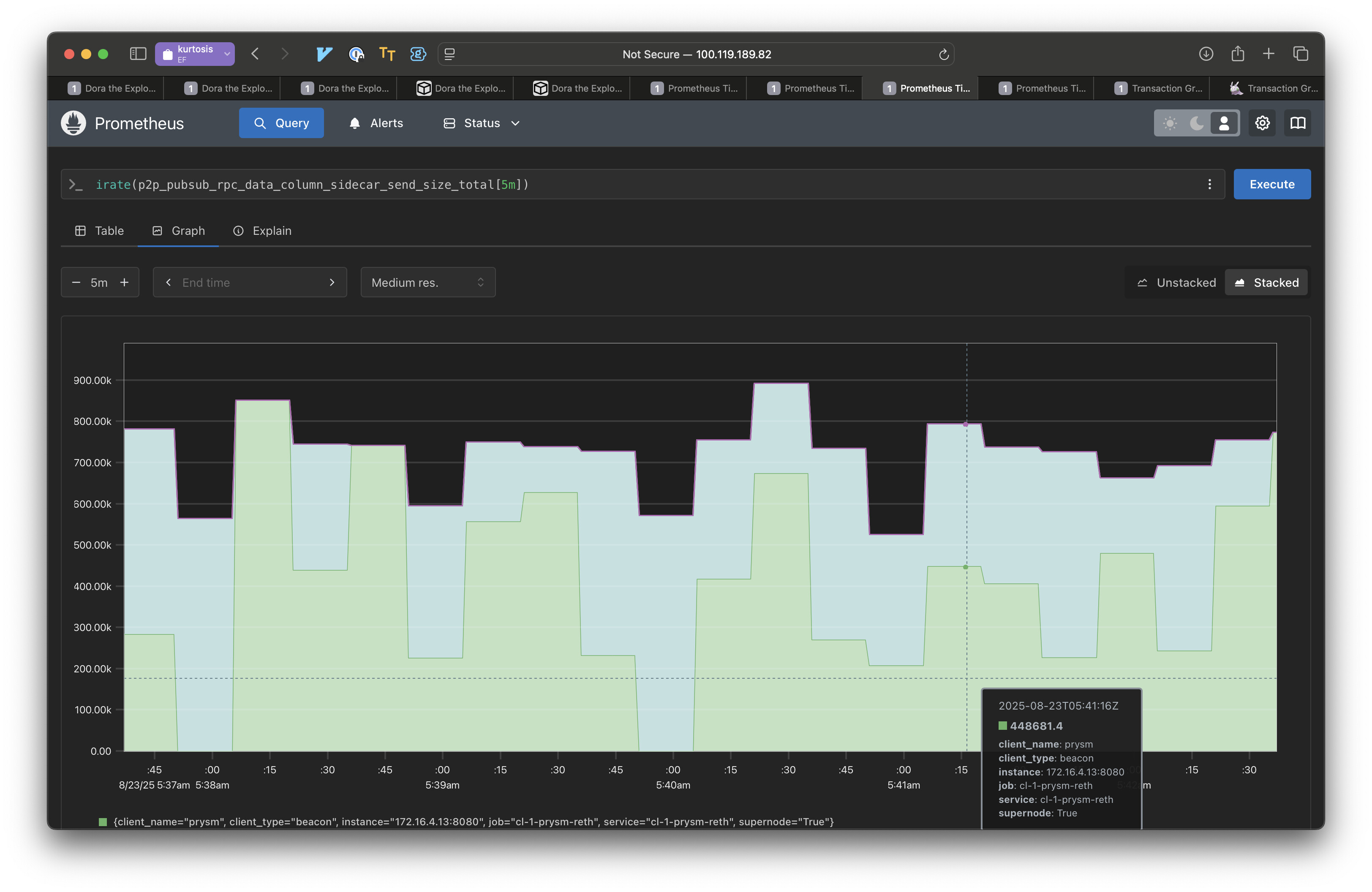
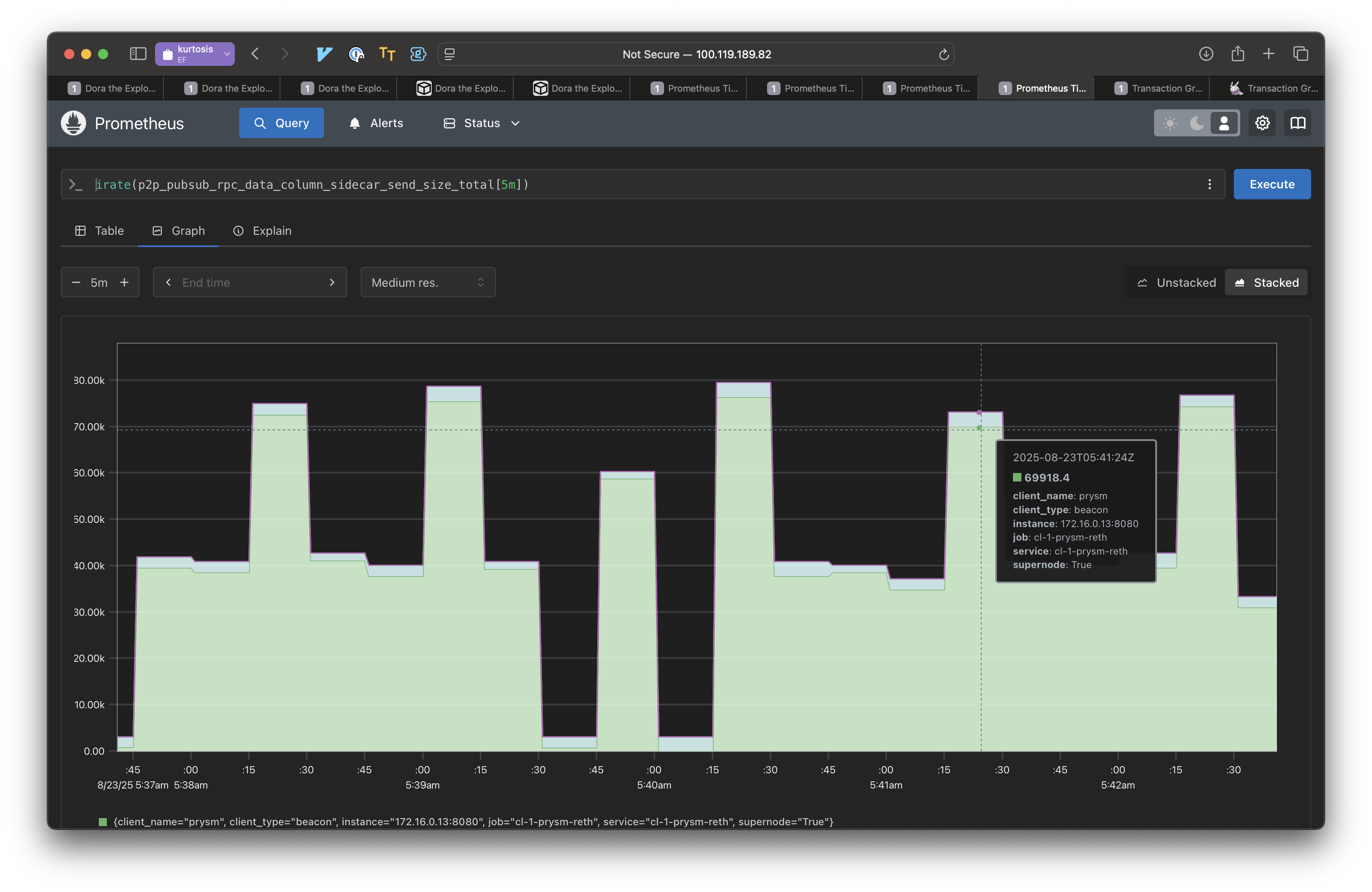
这只是两个对等节点的实验,但在包含更多对等节点的网格中,每次成对交互的行为应该相同。这是用于传播数据列的带宽。
内存池分片
内存池分片的未来方向只会使节点更有可能丢失一些单元,因此需要某种形式的单元级传播。
基于“行”的传播
请注意,如果某个节点在某一列的某个索引处缺失单元格,则它很可能在所有其他列的相同位置也缺失单元格。未来的一项改进可能是允许节点向其网格对等节点通告整行。这样做的好处是,节点可以一次性填充该行所有缺失的单元格。缺点是存在出现较大重复消息的风险。
后续步骤Next steps
- 指定支持返回部分 blob 的 getBlobs V3 api。
- 在 Rust libp2p 中实现部分消息扩展。(正在进行中)
- 指定 DataColumnSidecars 的部分消息编码。正在进行中
- 集成到 CL 客户端。
- 在测试网上部署
- 在主网部署
- 缩放斑点计数






