

「Google 把全链条攥在自己手里。它不依赖 Nvidia,拥有高效、低成本的算力主权。」
巴菲特曾说,「永远不要投资一家你无法理解的企业」。然而在「股神时代」即将谢幕之际,巴菲特却作出了一个违背「家规」的决定:买入 Google 股票,且是以约 40 倍自由现金流的高溢价。
是的,巴菲特首次买了「AI 题材股」,不是 OpenAI,也不是 Nvidia。所有投资者都在问一个问题:凭什么是 Google?
回到 2022 年底。那时 ChatGPT 横空出世,Google 的高管层拉响「红色警报」,他们不断开会,甚至还紧急召回两位创始人。可那时的 Google,看起来就像是一头行动迟缓、官僚主义缠身的恐龙。
它匆忙推出了聊天机器人 Bard,但在演示中犯下事实性错误,公司股价大跌,市值一日蒸发上千亿美元。接著,它整合旗下 AI 团队,推出多模态的 Gemini1.5。
但这款被看做撒手锏的产品,也仅在科技圈掀起几小时热议,便被 OpenAI 随后推出的影片生成模型 Sora 夺去所有声量,迅速变得无人在意。
稍显尴尬的是,正是 Google 的研究人员在 2017 年发表的开创性的学术论文,为这轮 AI 革命奠定了扎实的理论基础。

《Attention Is A You Need》论文
提出的 Transformer 模型
对手嘲讽 Google。OpenAI 的执行长奥特曼,看不上 Google 的品味,「我无法不去思考 OpenAI 和 Google 之间的美学差异。」
Google 的前执行长也不满公司的懒惰,「Google 一直认为,工作与生活的平衡……比赢得竞争更加重要」。
这一系列窘境,也让人怀疑,Google 在 AI 竞争中掉队了。
但变化终于来了。11 月份,Google 推出了 Gemini 3,它在多数基准测试指标上都超越了竞争对手,包括 OpenAI。更加关键的是,Gemini 3 完全由 Google 自研的 TPU 晶片训练完成,而这些晶片现已被 Google 定位为 Nvidia GPU 的低价替代品,正式向外部客户大出售。
Google 在两条战线上显露锋芒,以 Gemini 3 系列正面回应 OpenAI 的软体战线;另一条则是以 TPU 晶片挑战 Nvidia 长期统治地位的硬体战线。
脚踢 OpenAI,拳打 Nvidia。
奥特曼早在上个月就感受到压力,他在内部信上说,Google「可能给我们公司带来一些暂时的经济逆风」。而这周听闻大厂购买 TPU 晶片后,股价盘中一度暴跌 7% 的 Nvidia,只得亲自发信,安抚市场。
Google 执行长桑达尔·皮查伊在最近的一档播客中说,Google 的员工们应该去补补觉。「若从外部视角看,那段时间我们或许显得沉寂或落后,但实际上,我们正在夯实所有基础构件,并在此基础上全力推进。」
如今局势已然逆转。皮查伊说:「我们现在已经迎来了拐点。」
此时,ChatGPT 发布刚好三周年。这三年里,AI 拉开了一场矽谷资本的盛宴与合纵连横;而盛宴之下,泡沫隐忧浮现,行业是否迎来了拐点?
反超
11 月 19 日,Google 发布了最新的人工智慧模型 Gemini 3。
一项测试数据显示,在涵盖专家知识、逻辑推理、数学及图像识别等绝大多数测试中,Gemini 3 得分均显著领先于包括 ChatGPT 在内的其他公司的最新模型。仅在唯一一项程式设计能力测试中,其表现略逊,位列第二。
《华尔街日报》说,「不妨称之为美国下一代顶尖模型」。彭博社说,Google 终于醒了。马斯克、奥特曼对它赞赏有加。一些网友开玩笑说,这就是奥特曼理想中的 GPT-5。
云端内容管理平台 Box 公司的执行长在提前试用 Gemini 3 后表示,其性能提升幅度之大令人难以置信,以至于他们一度怀疑自己的评测方法有误。但反复测试后证实,该模型在所有内部评估中均以两位数优势胜出。
Salesforce 的执行长说,他用了 ChatGPT 三年,但 Gemini 3 仅用两小时就颠覆了他的认知:「Holy shit……回不去了。这简直是质的飞跃,推理、速度、图文影片处理……全都更锐利、更迅捷。感觉世界又一次天翻地覆了。」

Gemini 3
为何 Gemini 3 的表现如此突出,Google 又做了哪些事情呢?
Gemini 专案负责人发帖说,「简单:改进了预训练和后训练」。有分析说,该模型的预训练仍然在遵循 Scaling Law 的逻辑——透过优化预训练 (比如更大规模的资料、更高效的训练方法、更多的参数等),让模型能力实现提升。
最想了解 Gemini 3 秘密的人,当数奥特曼。
上个月,在 Gemini 3 发布前,他在发给 OpenAI 员工的内部信上就打了预防针,「无论从哪个方面来看,Google 近期的工作都十分出色」,尤其是在预训练方面,Google 取得的进展,可能为公司「带来一些暂时的经济逆风」,「接下来一段时间外界的氛围会比较严峻」。
虽然就使用者量而言,ChatGPT 对 Gemini 仍优势显著,但差距正在缩小。
这三年,ChatGPT 使用者数量增长迅猛。今年 2 月,它的周活跃使用者数为 4 亿,到这个月,跃升到 8 亿。Gemini 公布的是月活数据,7 月份,Gemini 月活使用者数为 4.5 亿,到这个月,这跃升至 6.5 亿。
凭借在全球网路搜寻市场约九成的份额,Google 自然掌握了推广其 AI 模型的核心管道,能够直接触达海量使用者。
OpenAI 目前估值为 5000 亿美元,是全球估值最高的新创企业。它也是史上增长最迅猛的公司之一,营收从 2022 年近乎为 0 猛增至今年预估的 130 亿美元,但它也预计,为了实现通用人工智慧,未来几年将烧掉超 1000 亿美元,同时还需花费数千亿美元租赁伺服器。换句话说,它还得去寻求融资。
Google 有一个不容忽视的优势:钱袋子更厚。
Google 最新一个季度的财报显示,其营收首次突破千亿美元,达到 1023 亿美元,同比增长 16%,利润 350 亿美元,同比增长 33%。公司的自由现金流是 730 亿美元,围绕 AI 的资本支出在今年将达到 900 亿美元。
它暂时也不用担忧搜寻业务会被 AI 侵蚀,其搜寻和广告仍显示出两位数增长。它的云端业务蒸蒸日上,连 OpenAI 都租用它的伺服器。
除了具备自我造血能力的现金流,Google 还掌握著 OpenAI 无法企及的筹码,比如用于训练和优化模型的海量现成资料,以及自建的算力基础设施。

11 月 14 日,Google 宣布投资 400 亿美元新建资料中心
OpenAI 长袖善舞,与各方签订了价值超过 1 兆美元的算力交易协议。所以,当 Google 携著 Gemini 快速逼近的时候,投资者的疑惑更强烈:OpenAI 画出的增长大饼,是否真能填上亏空?
裂缝
一个月前,Nvidia 市值突破 5 兆美元,市场对人工智慧的激情,将这家「AI 军火商」推向了新的高峰。但 Google Gemini 3 使用的 TPU 晶片,在 Nvidia 的坚固堡垒上,撞开了一道裂缝。
《经济学人》援引投资研究公司伯恩斯坦的数据称,Nvidia 的 GPU 占典型 AI 伺服器机架总成本的三分之二以上,相比之下,Google 的 TPU 晶片价格仅为同等性能 Nvidia 晶片的 10% 至 50%。这些节省累积起来相当可观。投资银行 Jefferies 估计,Google 明年将生产约 300 万颗此类晶片,几乎是 Nvidia 产量的一半。
上个月,知名的 AI 新创公司 Anthropic 已计划大规模采用 Google 的 TPU 晶片,据传交易额据称达数百亿美元。11 月 25 日的报导称,科技巨头 Meta 也在洽谈,拟于 2027 年前在其资料中心采用 TPU 晶片,价值达到数十亿美元。

Google 执行长桑达尔·皮查伊介绍 TPU 晶片
矽谷的网路大厂们也都在押注晶片,要么自研,要么与晶片公司合作,但没有哪家公司像 Google 一样取得这般进步。
TPU 的历史可以追溯到十多年前。当时的 Google 为了提高搜寻、地图与翻译的运行效率,开始研发一款公司内部使用的专用加速晶片。从 2018 年开始,它开始向云端运算客户销售 TPU。
此后,TPU 也被用于支援 Google 内部 AI 开发。在 Gemini 等模型的研发过程中,AI 团队与晶片团队形成互动:前者提供实际需求与回馈,后者据此定制优化 TPU,反过来又提升了 AI 研发效率。
Nvidia 目前占据了超 90% 的 AI 晶片市场。它的 GPU 最初用于逼真渲染游戏画面,依靠数千个计算核心并行处理任务,这一架构也使其在人工智慧的运行上遥遥领先。
而 Google 打造的 TPU,是所谓的专用积体电路 (ASIC),是「专才」,专门为特定的计算任务而设计,它牺牲了一定的灵活性与适用性,因此能效更高。Nvidia GPU 则像是「通才」,功能灵活、编程性强,但代价就是成本高。
不过,在当前的阶段,包括 Google 在内的任何公司,都没有能力完全取代 Nvidia。尽管 TPU 晶片已经开发到第七代,但 Google 依然是 Nvidia 的大客户。一个显而易见的理由是,Google 的云端业务要服务全球成千上万的客户,利用 GPU 的算力,能保证对客户的吸引力。
即便购买 TPU 的公司也得拥抱 Nvidia。Anthropic 宣布与 Google TPU 合作后不久,又宣布了一笔重大的 Nvidia 交易。
华尔街日报称,「投资者、分析师和资料中心营运商表示,Google 的 TPU 是 Nvidia 在 AI 运算市场主导地位面临的最大威胁之一,但要挑战 Nvidia,Google 必须开始更广泛地向外部客户销售这些晶片」。
Google 的 AI 晶片成为 Nvidia 晶片为数不多的替代品之一,这直接拉低了 Nvidia 的股价。Nvidia 下场发帖安抚 TPU 引发的市场恐慌情绪。它对「Google 取得的成功感到高兴」,但强调 Nvidia 已经领先行业一代,其硬体比 TPU 及其他专为特定任务设计的同类晶片更具通用性。
Nvidia 的压力还在于市场对泡沫的担忧情绪,投资人害怕巨额资本投入与盈利前景不匹配。投资情绪也是随时切换,既怕 Nvidia 的业务被人抢,又愁 AI 晶片卖不动。
美国知名「空头」麦可·贝瑞说,他已押注逾 10 亿美元做空 Nvidia 公司等科技企业。此人因在 2008 年做空美国房地产市场而出名,他的故事后来被拍成高分电影《大卖空》。他说,当今的 AI 的狂热与 21 世纪初期的网路泡沫类似。

麦可·贝瑞
Nvidia 向分析师分发了一份七页长的文件,反驳贝瑞等人的批评。但这份文件并未平息争议。
模式
Google 迎来了一段甜蜜的日子,它的股价在 AI 泡沫中逆势上涨。巴菲特的公司三季度购买了它的股票,Gemini 3 获得积极反响,TPU 晶片让投资者期待,这一切都将 Google 推向的高位。
近一个月来,Nvidia、微软等 AI 概念股下跌均超 10%,Google 的股价已上涨约 16%。目前,它以 3.86 兆美元的市值,排名世界第三,仅次于 Nvidia 和苹果。
分析师们将 Google 的人工智慧模式称作垂直整合。
作为科技圈里罕见的「全栈自造」的玩家,Google 把全链条攥在自己手里:Google 云端上部署自研的 TPU 晶片,训练 Google 自己的 AI 大模型,并且这些模型又能无缝嵌入搜寻、YouTube 等核心业务。这种模式的优势也是一眼可见,不依赖 Nvidia,拥有高效、低成本的算力主权。
另外一种模式则是较为常见的松散联盟模式。巨头们各司其职,Nvidia 负责 GPU,OpenAI、Anthropic 等负责研发 AI 模型,微软等云端巨头采购晶片厂商的 GPU,用于托管这些 AI 实验室的模型。在这个网路中,没有绝对的盟友或对手:能联手时就协同共赢,该交锋时也不手软。
玩家们形成了一种「循环结构」,资金在少数几家科技巨头之间形成闭环流转。
一般来说,循环融套路是这样的:A 公司先向 B 公司支付一笔钱 (如投资、贷款或租赁),B 公司再用这笔钱回头购买 A 公司的产品或服务,若没有这笔「启动资金」,B 可能根本买不起。
一个例子是,OpenAI 豪掷 3000 亿美元向甲骨文买算力,甲骨文转手花数十亿采购 Nvidia 晶片建资料中心,Nvidia 则反投最多 1000 亿美元给 OpenAI——条件是继续用它的晶片。(OpenAI 付 3000 亿美元给甲骨文 → 甲骨文拿这笔钱买 Nvidia 晶片 → Nvidia 用赚的钱反投 OpenAI。)
这样的案例催生出一堆如迷宫般的资金图谱。摩根士丹利分析师在 10 月 8 日的报告中,用一张照片描绘矽谷 AI 生态系统的资本流动。分析师警告称,资讯不透明,投资者难以厘清其真实的风险与回报。
华尔街日报评价这张照片时说,「连接它们的箭头就像一盘义大利面一样错综复杂」。
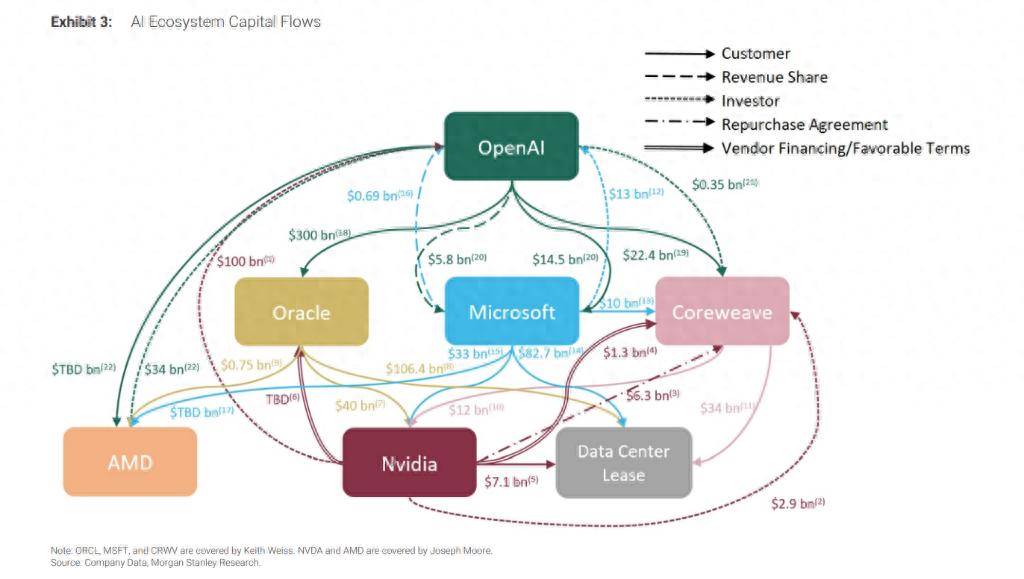
在资本的助推下,那巨物的轮廓正在等待著成形,无人知晓其真容。有人恐慌,有人惊喜。







