

本文已转载至Chainbound 博客的“使用 PeerDAS 进行区块和 Blob 传播”版块。
由Chainbound 的Pierre-Louis和mempirate撰写
简而言之,本文分析了以太坊网络的各项关键指标,以衡量 PeerDAS 和不断增加的 blob 数量的影响。这些指标包括区块和 blob 验证延迟、证明率和孤块率。我们发现,PeerDAS 引入后,更高的 blob 数量与上述指标的负面变化之间存在明显的关联(结果摘要链接)。我们认为,尤其是在 PBS 这种竞争激烈且对延迟高度敏感的机制下,这可能会人为地限制 blob 数量,使其低于协议定义的任何限制。针对这些问题,我们提出了一个超级节点网络的设计方案,旨在缓解部分问题。
| 斑点计数是否会影响: | 阻止延迟? | 认证率? | 孤块率? |
|---|---|---|---|
| 主网不带 PeerDAS(基线) | 是的,所有方面都是如此。 | 是的,但仅适用于p99 | 结果不确定 |
| 主网(含 PeerDAS-BPO1) | 是的,所有方面都是如此。 | 是的,所有方面都是如此。 | 数据不足 |
| Hoodi 和 PeerDAS-BPO2 | 是的,斑点数量≥9 | 是的,斑点计数≥14 | 不 |
介绍
PeerDAS 。以太坊最近部署了Fusaka,这是其以Rollup为中心的路线图上的一个重要里程碑,它引入了PeerDAS作为其首个支持数据可用性采样(DAS)的功能集。PeerDAS的具体目标是帮助网络支持每个区块中更多的blob。在Fusaka部署之前,以太坊网络支持的blob数量(目标,最大值)为6,9,预计到2026年将支持高达48,72。PeerDAS对blob机制进行了重大修改;它改变了blob的创建、引用、分发/托管和验证方式。因此,PeerDAS自然会带来一些权衡取舍。
DAS 的局限性。虽然 PeerDAS 的出现使得验证者无需再下载和验证完整的区块,但提议者却需要执行更多计算并上传更多数据。PeerDAS 使用 Reed-Solomon 编码,导致编码后的区块大小是 PeerDAS 之前的两倍(128 kB → 256 kB)。区块提议者将区块的编码区块组织成一个二维矩阵,其中每个区块对应矩阵的一行。提议者将矩阵分割成 128 列,计算每列的KZG 承诺,并将每列分别分发给 128 个验证者子网络。与 PeerDAS 之前相比,提议者需要计算和上传更多数据,这主要是由于 Reed-Solomon 编码造成的。随着 BPO 的推出,每个区块将包含更多区块,这个问题将会更加严重。一些值得关注的 DAS 未来提案,包括FullDAS和FullDASv2 ,都旨在实现 2D 编码,这将使编码开销进一步翻倍,从而进一步加剧建设者、提议者和中继的带宽成本,并对所有验证者的传播延迟产生影响。
实证分析。本文档主要基于 ethPandaOps 的Xatu 数据库中记录的观测数据,分析了每个区块的 blob 数量对以太坊的影响。具体而言,该分析研究了 blob 数量对以下三个方面的影响:(1)验证者接收区块和 blob 的延迟;(2)验证者成功验证区块的概率;(3) 区块未被最终确认而成为孤儿的概率。测量基于以下数据:
- 主网在 PeerDAS 部署之前,将作为基线,其 blob 计数为
(6, 9) - 主网在 PeerDAS 和 BPO1 之后,因此 blob 计数为
(10, 15) - Hoodi post-PeerDAS 和 BPO2,blob 计数为
(14, 21)
结果[汇总表] 。在几乎所有观察的网络中,无论在PeerDAS实施前后,增加blob数量都会显著恶化区块延迟和认证率。此外,我们观察到PeerDAS实施后的尾延迟比实施前更严重,并且随着blob数量的增加,尾延迟的恶化程度也随之增加。然而,增加blob数量对孤儿率没有明显影响;部分结果尚无定论,总体而言,需要更多数据才能对孤儿率得出有意义的结论。
提议:  种子网络。考虑到分析结果,我们建议在以太坊网络中添加一个由专用超级节点组成的网络,旨在加速区块、blob 和 blob 列从区块提议者(PBS 中的中继节点)向网络其他部分的传播。这项新增服务将起到辅助网络的作用,确保 PBS 供应链中的专用参与者不会因为担心包含 blob 的风险而人为地限制 blob 的数量,正如本次演示中所讨论的。
种子网络。考虑到分析结果,我们建议在以太坊网络中添加一个由专用超级节点组成的网络,旨在加速区块、blob 和 blob 列从区块提议者(PBS 中的中继节点)向网络其他部分的传播。这项新增服务将起到辅助网络的作用,确保 PBS 供应链中的专用参与者不会因为担心包含 blob 的风险而人为地限制 blob 的数量,正如本次演示中所讨论的。
斑点计数实证分析
目前在以太坊网络中,我们已经可以观察到blob对某些指标的影响。以下分析重点阐述了我们关于每个区块中blob数量的主要观察结果,并表明在PeerDAS部署后,仍有改进空间。
分析范围
本分析主要关注以下问题:增加斑点数量是否会影响:
- 验证器接收区块和所需blob列需要多长时间?
- 验证者能否在 4 秒截止时间前对区块进行认证?
- 一个区块最终成为孤立区块的概率是多少?
分析结构
我们研究了四种网络和分支的组合,每种组合都有四种不同的斑点数量:
- 主网基于 Pectra 分叉,拥有20,000 个稳定节点,支持
(6, 9)blob(target, max)。该数据集可作为 PeerDAS 的基线数据。 - 主网基于 Fusaka 分叉,启用了 PeerDAS 和 BPO1,以支持 blob 数量为
(10, 15)。我们观察到 BPO1 启用后噪声显著降低,因此选择不包含启用前的数据,即 Fusaka 的第一周数据。该数据集可作为 PeerDAS 启用后稳定的案例研究。 - Hoodi 测试网基于 Fusaka 分支,采用 PeerDAS 架构,由2000 个节点运行,并启用了 BPO2 以支持
(14, 21)个 blob。该网络稳定性较差,规模也小于主网,但已启用 BPO2。作为测试网,Hoodi 的架构与主网最为接近,因此比 Sepolia 更适合研究。本数据集可作为 PeerDAS 和 BPO2 的案例研究。
设置
来源:所有结果均提取自 ethPandaOps 维护的 Xatu 数据库。用于获取图表的确切查询可在GitHub 上公开获取以供复现 - chainbound/blob-seeder-data:与 PeerDAS 分析相关的数据,这些数据激发了 blob 种子网络的构建。
图表:部分图表使用箱线图来展示结果分布。箱体采用经典的箱线图形式:箱体的两端分别代表第25和第75百分位数(分别标记为p25和p75),箱体内的横线代表中位数(p50)。以下图表包含两对须线,以便更清晰地展示尾部潜伏期行为;须线一端代表p1和p5,另一端代表p95和p99。异常值用位于须线范围之外的半透明彩色圆圈表示。箱线图的参数标注在图表的右上角。
结果总结
| 斑点计数是否会影响: | 阻止延迟? | 认证率? | 孤块率? |
|---|---|---|---|
| 主网不带 PeerDAS(基线) | 是的,所有方面都是如此。 | 是的,但仅适用于p99 | 结果不确定 |
| 主网(含 PeerDAS-BPO1) | 是的,所有方面都是如此。 | 是的,所有方面都是如此。 | 数据不足 |
| Hoodi 和 PeerDAS-BPO2 | 是的,斑点数量≥9 | 是的,斑点计数≥14 | 不 |
- 延迟:blob 数量对延迟有明显影响。
- 比较 PeerDAS 启用前后相同 blob 数量的区块的延迟,数据显示,即使 blob 数量较低(3 到 9), PeerDAS 也比 Pectra 改善了主网上 95% 验证者的验证延迟,但对剩余的少数验证者而言,延迟却有所增加。然而,启用 PeerDAS 后区块的分发速度比未启用时更快,这表明对于剩余的 5% 验证者而言,启用 PeerDAS 后用于验证的 blob 数据的分发速度实际上比未启用时更慢。
- 主网未启用 PeerDAS 时:延迟随 blob 数量线性增加。这一趋势贯穿整个分布,从 p5 到 p99 值均可见。此外,所有 blob 数量的 p99 值均达到或超过 4 秒的截止时间;9 个 blob 的 p99 值甚至超过 5 秒。
- 启用 PeerDAS-BPO1 的主网:线性增长的趋势在启用 PeerDAS 后依然存在,从上到下,p5 到 p99 的所有值都呈现出这种趋势。与未启用 PeerDAS 的节点相比,大多数启用 PeerDAS 的节点延迟略有改善,因为大多数 p50 和 p75 值都降低了 100-200 毫秒。然而,对于最不理想的 1% 的验证节点,由于 blob 数量 ≥ 3 时 p99 值均有所增加,因此启用 PeerDAS 后区块延迟反而更高。当 blob 数量 ≥ 9 时,p99 值均超过 5 秒;当 blob 数量为 14 时,p99 值超过 6 秒;当 blob 数量达到最大值 15 时,p99 值甚至达到 12.4 秒。
- 使用 PeerDAS-BPO2 的 Hoodi 分析显示:blob 计数 ≥ 9 的值呈现明显的增长趋势,且在所有 p1 到 p99 节点上基本呈线性增长。这表明,一旦 BPO2 在主网上部署,该趋势很可能继续保持线性增长。
- 认证率:斑点计数对认证率有明显影响。
- 主网没有 PeerDAS:当 blob 计数 ≥ 4 时,较高的 blob 计数会增加 p99 的失败证明率。否则,blob 计数对证明率几乎没有影响。
- 启用 PeerDAS-BPO1 的主网:启用 PeerDAS 后,认证失败率总体上显著高于未启用时。启用 PeerDAS 前,p75 在所有 blob 数量下均稳定在 0.6%,但启用 PeerDAS 后,随着 blob 数量的增加,p75 从 0.9% 上升至 1.8%。同样,p95 也从 1 个 blob 时的 2.4% 上升至 15 个 blob 时的 7%。
- 使用 PeerDAS-BPO2 的 Hoodi:当 blob 数量 ≥ 14 时,失败的证明率随 blob 数量的增加呈线性增长。未证明最终区块的验证者的中位数率从 14 个 blob 的 4% 增加到 21 个 blob 的 5%,p99 从 14 个 blob 的 11% 增加到 21 个 blob 的 37%。
- 孤立块率:blob 数量对孤立块率几乎没有影响。
- 不使用 PeerDAS 的主网:结果尚无定论。基于总槽位数计算孤块率(绝对值)的图表显示,blob 数量增加与孤块率增加之间存在相关性。然而,基于包含相同数量 blob 的已完成区块数量计算孤块率(即比例值)的图表则未显示任何规律。
- 主网上的 PeerDAS-BPO1:孤儿节点很少见,而且目前数据还不够。
- 使用 PeerDAS-BPO2 的 Hoodi:Hoodi 上似乎没有发现 blob 数量与孤立块发生率之间的相关性。显示绝对发生率的图表主要突出显示了两个异常值,而显示比例发生率的图表则主要突出显示了 6 到 13 个 blob 之间块延迟的模式。
主网延迟比较
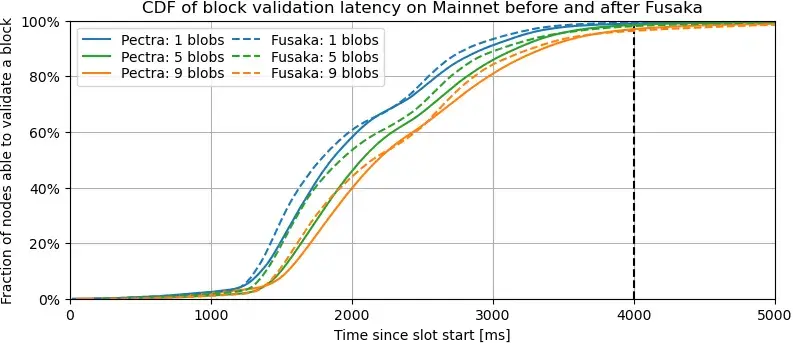
描述。此图展示了在主网上,当区块包含 1、5 和 9 个 blob 时,使用 Pectra 共识规则和 Fusaka 共识规则,已收到足够数据以验证区块的验证者比例的变化情况。更准确地说,它描绘了区块验证延迟的累积分布函数 (CDF),我们将区块验证延迟定义为验证者能够根据共识规则验证区块的最早时间。在 Pectra 共识规则下,验证者必须收到区块及其所有 blob sidecar 才能验证区块;而在 Fusaka 共识规则下,验证者只需收到区块及其至少 8 个 blob 列(包括其必须保管的所有 blob 列)即可。Pectra 和 Fusaka 数据集的详细信息(分别为 PeerDAS 之前的主网和 PeerDAS-BPO1 之后的主网)将在各自的延迟图描述中进一步解释。
要点:按blob数量配对的三组曲线呈现出相似的模式:与Pectra相比,Fusaka中的大多数验证者能够更早地验证区块,即虚线大多位于实线之上。此外,在区块中添加blob自然会增加延迟。我们观察到在2.3-2.5秒左右传播速度略有下降,这可能是由于密集验证者集群之间的跨洲延迟造成的。
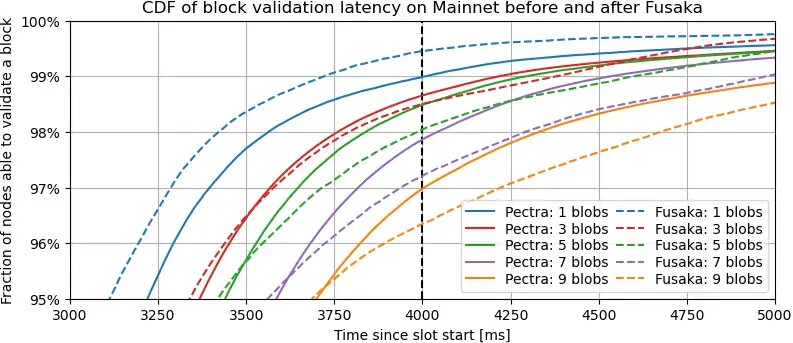
描述。此图是上述图的放大版本,添加了第 3 个和第 7 个斑点的线条,以突出显示传播尾部的开始,超过第 95 页。
要点总结。对于单个区块,两条曲线的行为与上图一致:当区块数量较低时,超过 99% 的验证者在 Fusaka 下验证区块的速度比在 Pectra 下更快。然而,对于更高的区块数量,情况则相反:最不走运的 4-5% 的验证者在使用 Fusaka 接收验证数据所需的时间实际上比使用 Pectra 更长。随着区块数量的增加,这种趋势愈发明显,如同色实线和虚线之间的差距所示。这两张图表明,PeerDAS 改善了 95% 验证者的延迟,但却加剧了剩余少数验证者的延迟。
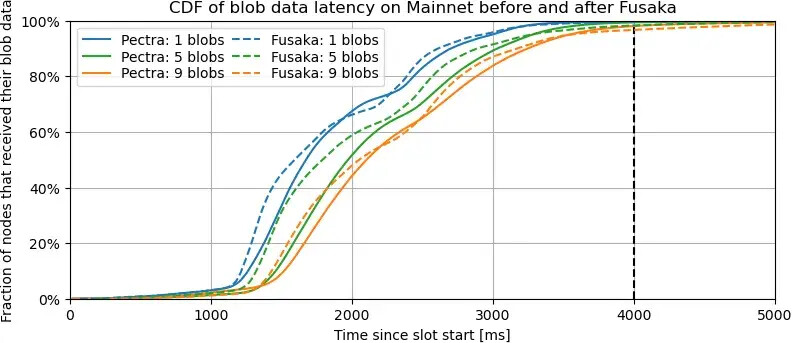
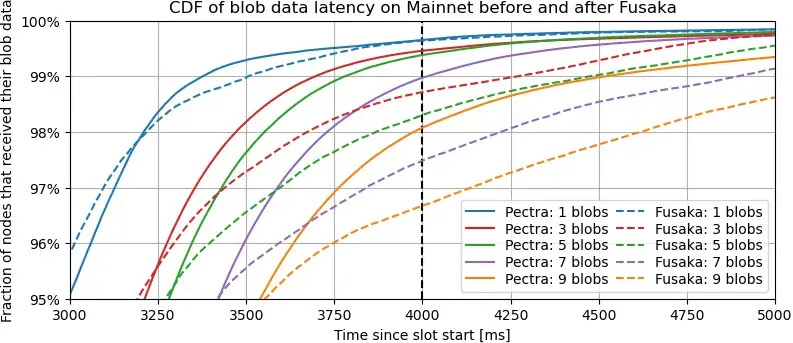
说明:这两张图与上图类似,但侧重于验证器接收足够数据以验证区块所需的延迟,即 Pectra 中每个区块的所有数据(即所有数据)与 Fusaka 中仅所需的数据列之间的延迟。这些图不考虑区块延迟,仅考虑数据列延迟。
要点。这两张图证实了之前的推断,即大多数节点在 Fusaka 中接收 blob 数据的速度比在 Pectra 中更快,而对于最不幸的 5% 的节点来说,情况则相反,并且随着 blob 数量的增加,这种趋势会恶化。
在 PeerDAS 之前
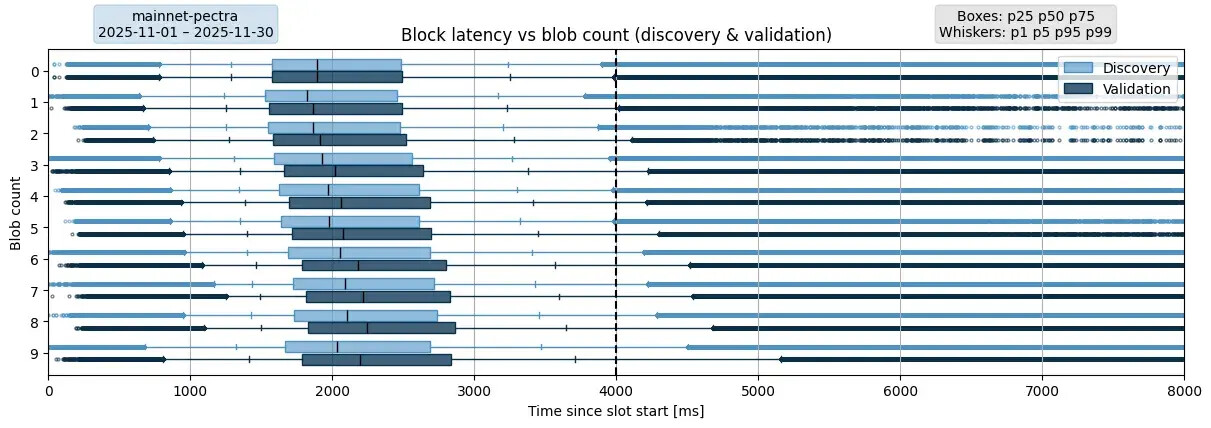
描述。此图展示了 Pectra 主网上区块发现和验证延迟的分布情况(PeerDAS 之前),并根据每个区块引用的 blob 数量进行了划分。如上所述,Pectra 要求验证节点下载区块中引用的所有 blob sidecar 才能验证该区块。这种延迟体现在发现延迟和验证延迟之间的差异上。图中的每个数据点都是一个唯一的元组:(接收节点,最终区块)。为了去除明显的异常值,已过滤掉延迟超过 30 秒的区块。数据集汇总了 2025 年 11 月整个月份的数据。4 秒处的黑色垂直线表示区块证明截止时间。
要点:从 p25 到 p99,所有指标都呈现出明显的上升趋势,表明 blob 数量越多,区块验证延迟就越高。对于 blob 数量为 0-1 的区块,p99 的延迟已经达到 4 秒的截止时间;而对于 blob 数量 ≥ 2 的区块,延迟则超过了该截止时间。然而,验证者不仅需要在截止时间前接收区块,还需要处理区块及其关联的 blob。
使用 PeerDAS-BPO1
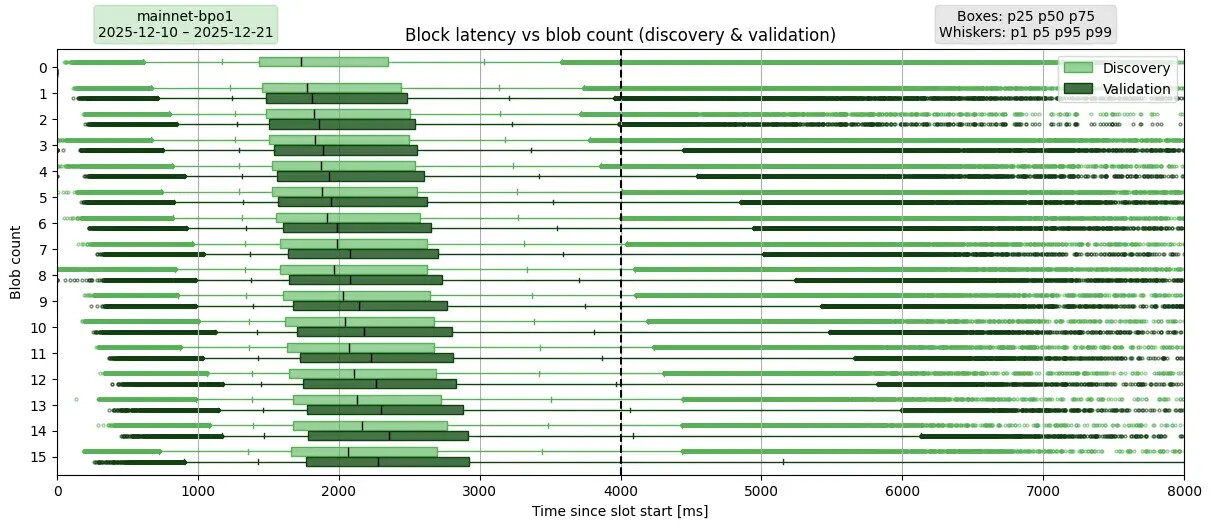
描述:此图复现了之前在主网上的延迟图,但这次是在部署了 PeerDAS 和 BPO1 之后。此外,它还显示了区块发现延迟,作为每个层级的第一个方框。这使得仅由 blob 列传播引起的额外延迟更加清晰。
如上所述,Fusaka 的验证规则有所不同,它要求验证者不能下载完整的 blob,而是至少下载 8 个 blob 列,其中包括其托管所需的所有 blob 列。11 天的采样周期从 2025 年 12 月 10 日 00:00 UTC(BPO1 激活后不久)开始,到 2025 年 12 月 21 日 23:59 UTC 结束。
要点总结。从 p5 到 p99,PeerDAS 实施前后趋势基本一致。值得注意的是,PeerDAS 实施后,p50 值总体提升了 100-200 毫秒,但当 blob 数量 ≥ 3 时,p99 值反而下降,这意味着最不走运的 1% 验证者体验到了更低的服务质量。当 blob 数量 ≥ 9 时,所有 p99 值均超过 5 秒,其中 blob 数量为 14 时达到 6.1 秒,最大 blob 数量为 15 时甚至达到 12.4 秒。
使用 PeerDAS-BPO2 在 Hoodi 上测试延迟
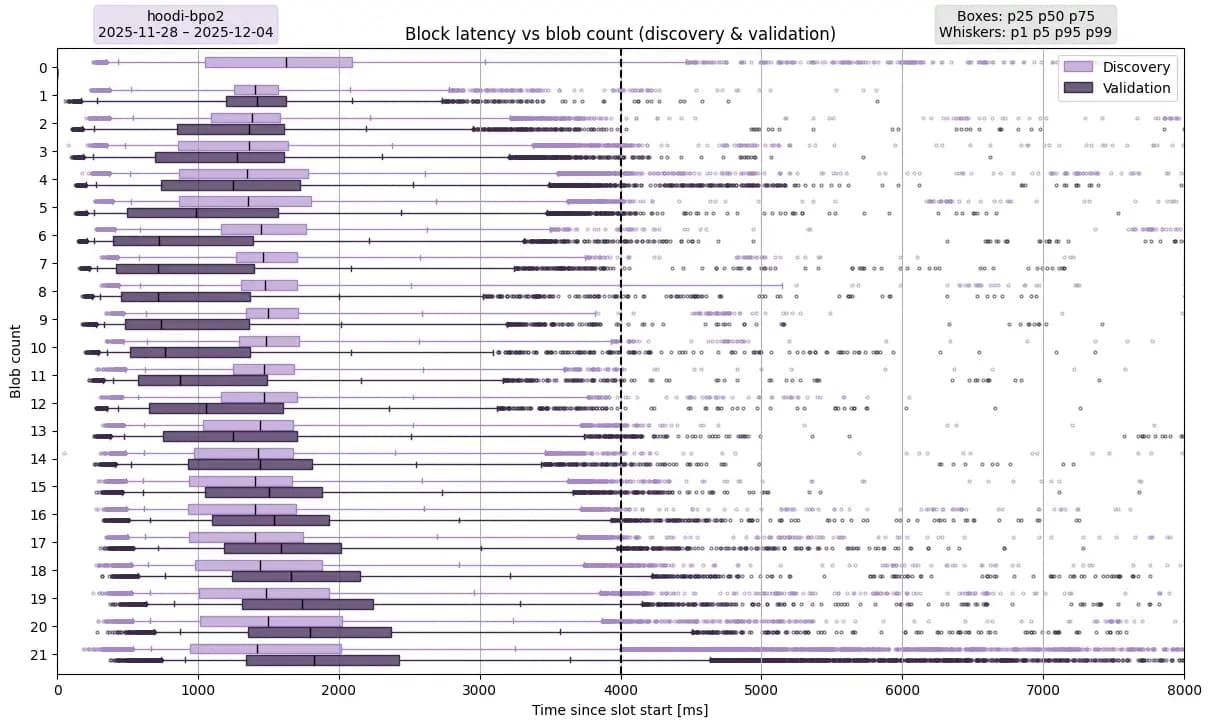
描述。此图描绘了在 Hoodi 上部署 PeerDAS 和 BPO2 后的区块验证延迟。BPO2 已于 2025 年 11 月 12 日部署在 Hoodi 上,并将 blob 数量提升至目标值(14, 21)由于 Hoodi 测试网的波动性远高于主网,因此本图所用的数据采样时间为 7 天,从 2025 年 11 月 28 日 00:00:00 UTC 到 2025 年 12 月 4 日 00:00:00 UTC,而主网的数据采样时间为一个月。
要点:在 Hoodi 上,blob 数量对区块延迟的影响不如在主网上那么明显。对于所有 p1 到 p99 值,blob 数量 ≥ 9 时,延迟呈现明显的线性增长趋势。我们观察到,许多节点接收到的 blob 列不足以验证区块,因此人为地降低了整体延迟,因为图中只考虑了成功验证的情况。
认证率
PeerDAS 之前的主网
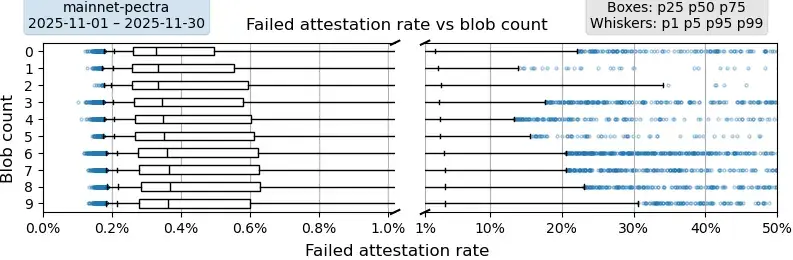
描述。此图显示了从未验证过某个区块的验证者比例,该比例取决于区块中的blob数量。每个数据点对应一个最终区块。例如,p99 为 30% 表示 1% 的区块仅由 70% 的验证者验证。数据汇总自 2025 年 11 月主网上的整个月份。为了提高箱线图和须线的可读性,图表的 x 轴被分为两个不同刻度的线性轴。
要点:中位数略有上升趋势,而当 blob 计数 ≥ 4 时,p99 值呈现更明显的上升趋势。所有 p75 值均接近或低于 0.6% 的失败认证率,这表明即使 blob 计数为 9,网络也保持稳定。
主网与 PeerDAS-BPO1
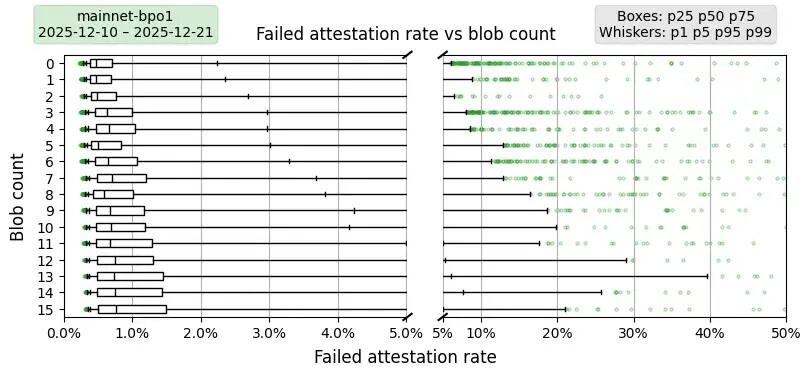
描述。此图复现了主网上的上述认证率,但时间范围为 PeerDAS 激活后至 BPO1 激活前。为了便于阅读,该图同样分为两部分。
要点总结。最重要的是,整体认证率有所下降:在启用 PeerDAS 之前,p75 的认证失败率约为 0.6%,而启用 PeerDAS 后,随着数据块数量的增加,认证失败率从 0.9% 上升到 1.8%。从 p50 到 p99 的所有测量结果都呈现出类似的趋势:随着数据块数量的增加,数据块的认证率下降。与之前未启用 PeerDAS 的图表相比,启用 PeerDAS 后,认证率受数据块数量的影响要大得多。
Hoodi 与 PeerDAS-BPO2
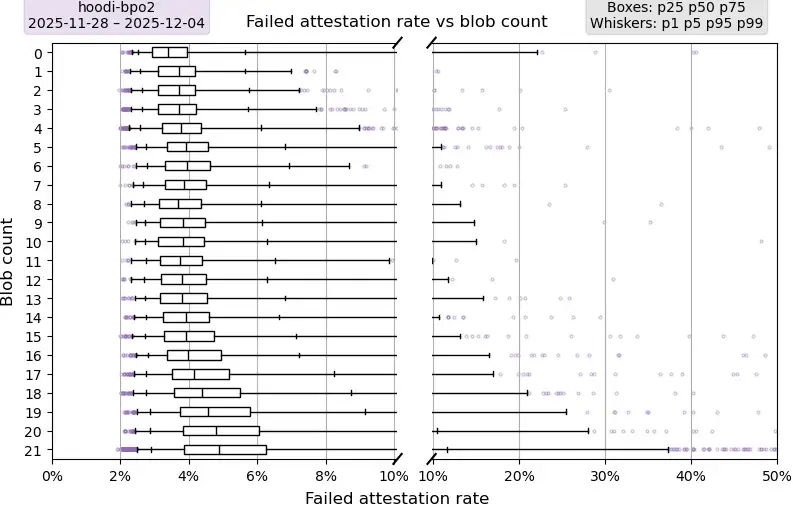
描述:此图复现了上述认证率图,但使用的是已启用 BPO2 的 Hoodi 版本。由于 Hoodi 版本的波动性远高于主网,因此数据仅采样了一周;在某些情况下,增加样本量反而会增加异常值。
要点:从 12 个 blobs 开始,所有高于 p25 的指标都随着 blobs 数量的增加而明显恶化,呈现出明显的上升趋势。此外,p99 也随着 blobs 数量的增加而全面恶化。与 PeerDAS 之前的 Mainnet(其 p75 低于 1%)相比,启用 PeerDAS 后的 Hoodi 的 p75 值要高得多,目前在 5% 到 7% 之间波动。
孤儿区块率
PeerDAS 之前的主网
绝对
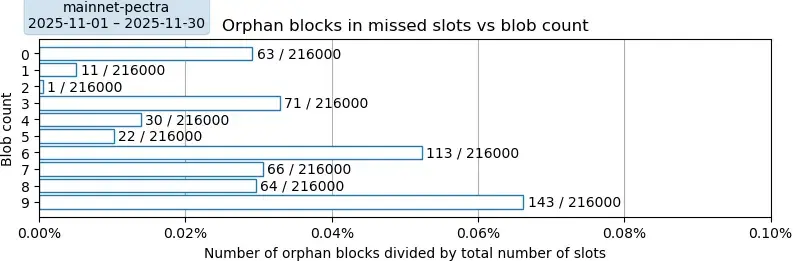
描述。此图描绘了孤立区块率,并按这些区块中引用的blob数量进行分类。这些孤立区块由其各自槽位的预期提议者创建,但由于未知原因,最终并未包含在最终的区块链中。这些比率的计算与采样期内的槽位总数成正比:2025年11月共有216,000个槽位。
要点:以太坊的孤儿率总体较低,为 584 / 216000 = 0.27%,这表明以太坊的正常运行时间为 99.73%。我们在此图中观察到两种模式。首先,似乎每隔 3 行就会重复出现一种模式,即某一行的高值之后紧接着两个较低的值:例如,0 个 blob 时有 63 个孤儿,接下来的两行分别是 11 个和 1 个孤儿;3 个 blob 时有 71 个孤儿,接下来的两行分别是 30 个和 22 个孤儿;6-9 个 blob 的情况也类似。第二种模式表明,增加 blob 数量会增加孤儿率,但这只有在考虑第一种模式的情况下才成立。当仅观察 blob 数量为 0、3、6 和 9 时,这种上升趋势很明显。由于我们无法解释第一种模式,因此对第二种解释的置信度较低。
比例

描述。此图复现了上述绝对孤立块率图,但更改了率计算中使用的除数。此图显示的是“比例”率,因为它们基于与孤立块具有相同 blob 计数的已完成块的数量。
要点:我们主要观察到最终区块中斑点数量的分布较为多样(柱状图旁边分数中的除数),并且存在两个异常值,斑点数量分别为 2 和 9。忽略异常值后,斑点数量似乎并不影响孤儿率,这与显示绝对孤儿率的图表有所不同。
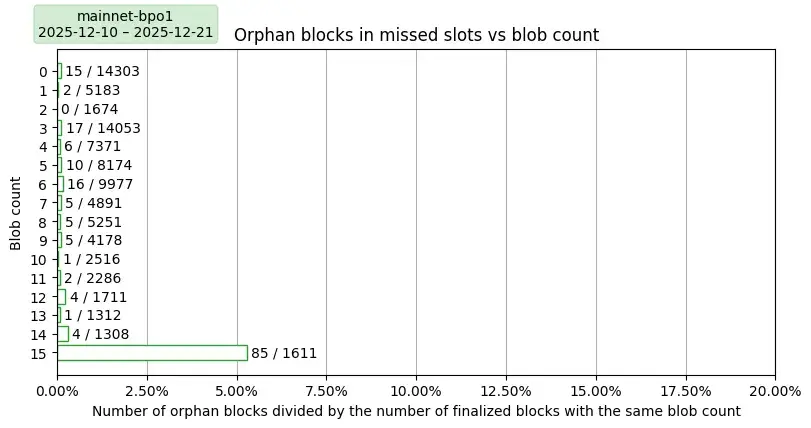
主网与 PeerDAS-BPO1
收集足够的数据来绘制Fusaka更新后主网上的孤块图需要数周时间。作为对比,上图显示的是PeerDAS更新前主网上的孤块情况,尽管计算周期长达一个月,但孤块率仍然很低。下图显示的是高blob计数的观测值数量非常少,因此不具有代表性。其中,15个blob异常值非常突出,它们的孤块率超过5%。
Hoodi 与 PeerDAS-BPO2
绝对
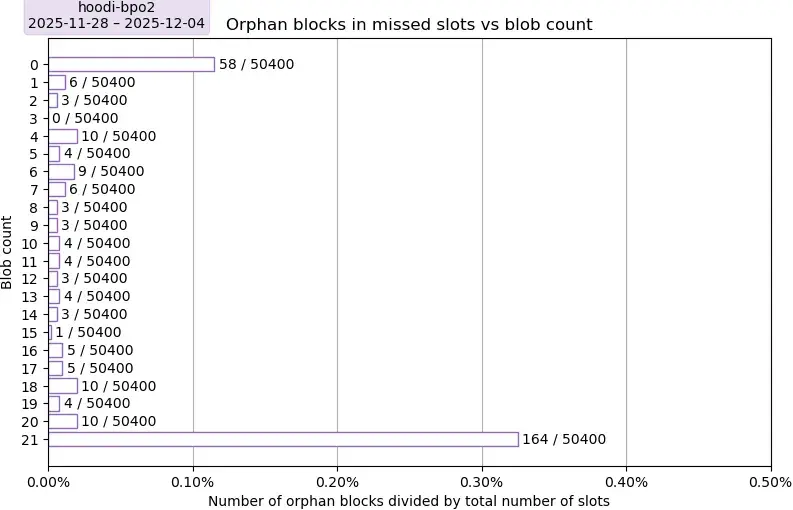
描述。该图描绘了 Hoodi 上孤立区块的比例,以采样期内(7 天内 50,400 个区块)的总区块数为基准。
要点:在抽样期间,孤块率总体较低,为 319 / 50400(孤块数 / 总槽位数)= 0.63%,略高于主网的 0.27%。有两个明显的异常值,分别为 0 个 blob 和 21 个 blob,并且没有明显的趋势表明 blob 数量对 Hoodi 的孤块率有任何影响。
比例
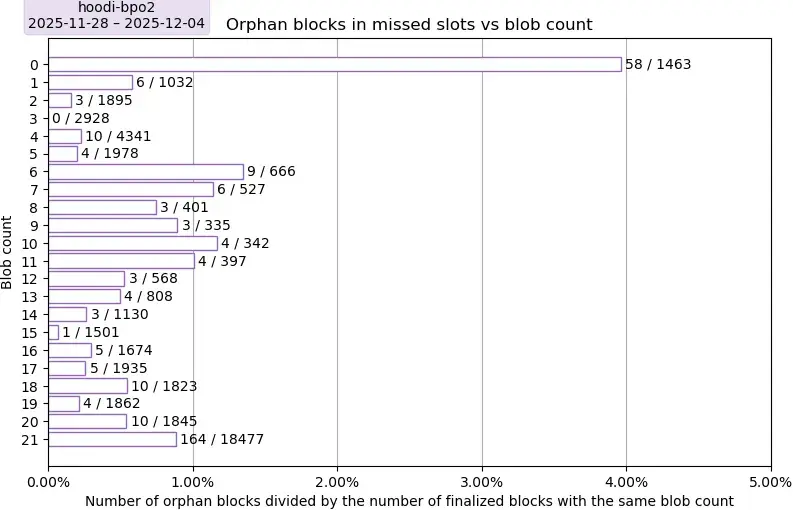
描述。此图显示了 Hoodi 上孤立区块在一周内的比率,以具有相同 blob 计数的已完成区块的数量为基准。
要点:在 6 到 13 个 blobs 之间,孤块率出现了显著的激增;我们目前尚无法解释这一现象。0 个 blobs 的值显然是一个异常值,而 21 个 blobs 的值也可以被视为异常值,因为其除数非常高,比其他 blobs 数量对应的除数高出 4 到 46 倍。剔除最后一行 21 个 blobs 的异常值后,没有明显的趋势表明 blobs 数量与孤块率之间存在相关性。
相关研究
- 2024-11:PeerDAS 前期数据显示块+blob 大小与传输延迟之间存在趋势[帖子]
- 2025-09: Ethpandas BPO 报告显示,在 Fusaka devnet 5 上,使用 30-50 个 blob 但数据集较小的情况下,blob 的安全性和及时性存在问题[帖子]
- 2025-09: EF 在一篇研究 6 秒时段可行性的文章中详细分析了认证时间[文章]
- 2025-10:Ethpandas 报告了 Fusaka devnet 5 上各种类型节点的上下行带宽消耗情况[帖子]
- Sunnyside Labs发布了很多分析报告[报告]
- 2025年10月10日[报告]补充了 Ethpandas BPO 报告[帖子] :随着 blob 数量从 10 增加到 40,全节点错过证明截止时间(与报告中的“头部正确性”指标相反)的比例上升到 50% 以上。超级节点基本正常。每个区块包含 50-60 个 blob 时,p75 延迟达到 3 秒,因此尾部延迟更高(报告中未明确说明)。每个区块包含 60 个以上 blob 时,很难获取采样列,这可能是由于网络争用造成的:执行客户端需要过多的带宽,而共识客户端难以响应列请求。
- 2025-09-30 [报告] :Fusaka devnet 5 拥有 1,700 个节点(主网的 1/8):高 blob 计数的瓶颈是全节点上行链路,这是由于内存池(执行客户端)中 blob 的数量很高,而超级节点的带宽主要在采样列(共识客户端)中。
- 2025-07-14 [报告] :附录 B 列出了 Grafana 仪表板,附录 D 列出了增加 blob 数量时节点上的一些简单平均带宽和最大带宽。
提案:种子网络
正如分析中所强调的,PeerDAS 会对与共识稳定性相关的多项指标产生负面影响,尤其是在区块尾部。就其本身而言,对于即将到来的 BPO 带来的 blob 数量小幅波动,这本身并不值得担忧。然而,在 PBS 供应链中,毫秒级的延迟至关重要。中继节点为验证者提供服务,使其能够尽可能延迟提交区块,从而最大化 MEV(时间博弈)。目前,这种方法之所以有效,是因为包含 blob 的延迟惩罚相对较小。然而,正如我们前面所看到的,这种情况正在发生变化,这可能导致 PBS 供应链中的某些实体人为地设定 blob 数量上限,而该上限远低于实际上限。这将抵消 PeerDAS 的主要存在意义——DA 扩容优势。
正因如此,我们提议构建一个全球超级节点网络,其唯一任务是加速数据(区块和数据块)从区块发起者(PBS 中的中继节点)向网络其余部分的传播。我们预期种子网络能够通过减少和限制向大多数验证者分发数据所需的通信跳数,可靠地降低并稳定验证者所经历的延迟。此外,它还能确保构建者能够可靠地包含经济上最优数量的数据块而不会增加任何额外的延迟,从而提高数据块的使用效率。
种子网络的概念与Rainbow 质押框架相符(尽管协议本身有所不同),因为它依赖于功能更强大的超级节点为网络做出比普通节点更多的贡献,最终提升所有用户的服务质量。这些超级节点扩展了PeerDAS 原始文章中描述的DAS 提供者的概念。一些设计方案提出将 PBS 中继节点转变为 DAS 提供者,并提供 RPC 服务供验证者查询以获取样本。我们建议在这些设计方案的基础上,增加对 GossipSub 的支持,使超级节点能够主动加速数据传播,而不仅仅是被动地等待客户端查询。
具体来说,这个种子网络将由高性能、高连通性的超级节点组成,这些超级节点将作为网络枢纽,以便将尽可能多的数据传递给尽可能多的节点。超级节点将通过订阅用于数据块( beacon_block )和128个blob列子网( data_column_sidecar_[0-127] )的GossipSub主题来参与数据块和blob列的传播。此外,超级节点还将响应相关的数据块、blob和blob列的RPC请求,例如BeaconBlocksByRoot 、 BlobSidecarsByRoot和DataColumnSidecarsByRange 。
超级节点间的连接将采用久经考验、性能卓越的GitHub项目chainbound/msg-rs:这是一个用Rust语言编写的分布式系统消息传递库,曾用于支持我们的低延迟内存池服务Fiber 。每个超级节点的地理位置和网络拓扑结构都将经过精心设计,以最大限度地降低验证者的整体数据分发延迟和请求延迟,确保在弗吉尼亚、法兰克福和东京等热点地区实现适当的分布。
预期指标改进
我们预期种子网络在以下方面将比以太坊网络有明显的改进:
- 块和块接收延迟:由高性能超级节点组成的小型网络能够以比更大、更异构的网络更少的跳数进行传播。
- 证明率和孤块率:由于区块和 blob 列的传播速度加快,验证者能够更快地证明区块,从而降低区块未能及时得到证明,最终成为无用的孤块而不是最终链的一部分的概率。
- PBS 中战略性块限制的减少:由于上述 2 项改进,PBS 供应链中战略性(较低)块纳入的好处被抵消了。
致谢
我们感谢 ethPandaOps 团队允许我们访问并协助我们使用 Xatu 数据库,也感谢 Xatu 的贡献者们为我们提供用于分析的数据。我们还要感谢在 SIGMETRICS 2026 会议上发表的区块链网络分析报告《36 种加密货币的多面性》 ([arXiv 版本])的作者们,特别是 Lucianna Kiffer,感谢她分享了关于各种以太坊网络规模的最新数据。






