

假设有大量对象可供用户发送,所有对象(如果有效)都需要广播,以便最终的构建节点能够发现并包含它们。假设有效性条件可以用 STARK 表示,并且我们处于后量子环境中,椭圆曲线 SNARK 将无法工作。
这至少适用于以太坊的三种用例:
- 后量子执行层签名聚合,尤其是在用户使用隐私协议的情况下
- 后量子共识层签名聚合,用于处理大量验证者
- 在分布式块构建模型中,我们假设块的总数过大,构建者无法完全下载,因此构建者必须从块提交者处下载根,然后使用分布式应用服务(DAS)验证其可用性。STARK 验证纠删码的计算是否正确。
问题在于:STARK 开销巨大,即使在高度优化的实现中,也需要 128 kB 的空间。如果用户发送的每个对象都连同全部 128 kB 的 STARK 开销一起广播给所有人,那么带宽需求(包括中间内存池节点和构建器的带宽)将非常高。
以下是解决这个问题的方法。
当用户将对象发送到内存池时,他们可以将该对象与有效性的直接证明(例如,一个或多个签名、通过某些验证函数的 EVM 调用数据)或 STARK 有效性证明一起发送。
内存池节点遵循以下算法:
- 它们被动地等待并接收用户发送的物品。当它们看到物品时,会验证其证明。如果证明有效,它们就会接受该物品。
- 每周期(例如 500 毫秒),它们都会生成一个递归的 STARK 验证,证明所有已知仍然有效的对象。它们会将此验证转发给其他节点,同时还会将尚未发送给该节点的任何对象(不带验证)发送给其他节点。
递归 STARK 的逻辑如下。公共输入可以是位域或哈希列表,表示证明所验证的对象集合。证明过程需要:
- 0 个或多个对象,及其有效性证明(直接证明或 STARK 证明)
- 0 个或多个其他相同类型的递归 STARK 函数
- 一个包含待丢弃对象哈希列表的位域(这允许丢弃过期对象)。
该证明证明了所有对象和所有递归 stark 公共输入的并集的有效性,减去被丢弃的对象。
以图表形式表示(此处以执行层签名聚合用例为例):
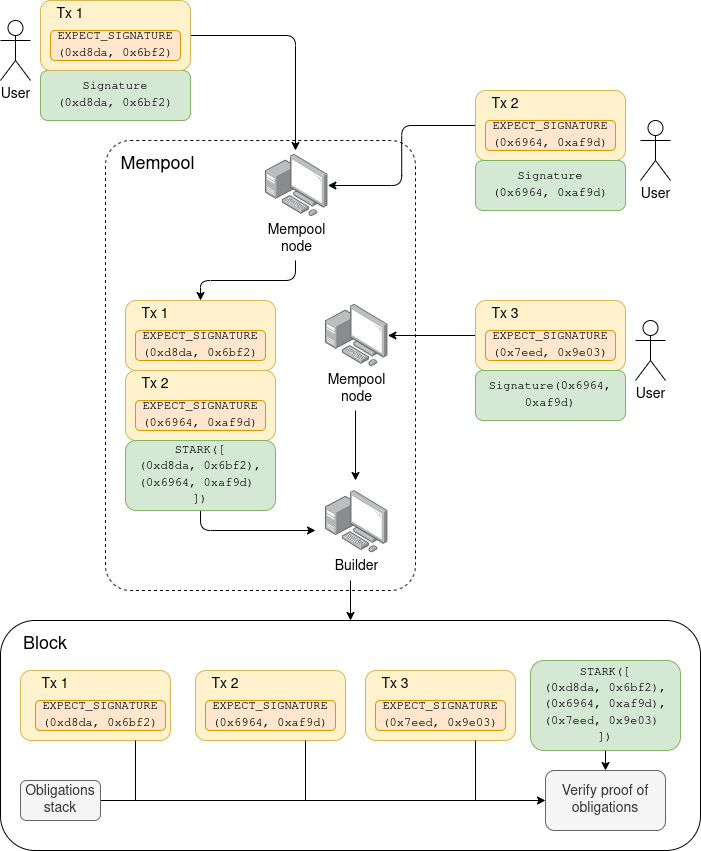
在这个例子中,第一个内存池节点看到交易 Tx 1 和 Tx 2(带有直接证明),并创建一个递归 STARK 证明,证明{Tx 1, Tx 2}有效。第二个内存池节点看到来自第一个节点的消息,该消息包含交易 Tx 1 和 Tx 2(没有直接证明)以及 STARK 证明,并且它还看到交易 Tx 3(带有直接证明),于是它创建一个递归 STARK 证明,证明{Tx 1, Tx 2, Tx 3}有效。它将此证明发送给它的对等节点,其中一个是构建节点,该构建节点接收并包含此证明。
如果构建器收到多条包含非完全重叠对象集的消息,并且构建器想要同时包含这些对象集,则构建器可以自行创建一个递归的 STARK 合并器来合并它们。构建器还可以丢弃任何它认为不再有效的对象(此处指交易)。
该方案的总开销为:
- 每个对象,如果没有签名,都会被广播到每个节点。这与目前的现状带宽相同,区别在于我们可以去除签名。
- 每个节点都拥有额外的入站和出站带宽,其大小等于每个时间刻一个 STARK 的数据量乘以其对等节点的数量(例如,8 个对等节点,时间刻为 500 毫秒,则带宽为 128 kB * 8 / 0.5 = 2 MB/秒)。该带宽是恒定的,不会随着用户发送的对象数量的增加而增加。






