

抽象的
我们希望通过按需采样方法,而不是像 Celestia、SPAR 或 Peer/Full DAS 等主流 DAS 方法那样从固定编码集中采样,来推动无速率编码(特别是随机线性网络编码 (RLNC))的使用,从而提高采样效率。
为什么选择固定费率代码?
最初使用编码进行分布式感知系统 (DAS) 的动机是,在匿名性条件下,从未编码数据中采样只能线性降低假阴性概率(验证者错误地认为数据可用,即使实际上不可用),其降低速度与采样数量呈线性关系,即从k未编码数据块中抽取 s 个样本,其关系式为1 - s/k 。然而,如果我们应用例如(n,k) RS 编码,则s采样(不放回)的假阴性概率下降速度将超过(k-1/n)^s
通过无速率编码提高采样效率
通过采用固定速率编码,验证器(轻客户端)本质上只能从预先编码的n符号集中进行采样。观察上述从固定速率编码数据中采样的漏检概率,自然会产生一个问题:为什么不尽可能增大n值,以便即使样本数量较少,漏检概率也足够低呢?这样做存在一些缺点,包括:
这里使用的码通常是像 RS 码这样的码,它们对
n的大小以及(n,k)的可能组合都有固有的限制。数据生产者的存储和计算成本会随着将采样数据分发到保管节点(例如 PeerDAS)的带宽成本的增加而无意中增加。
解决此问题的自然方案是按需生成样本,以避免存储和分发瓶颈。这自然而然地引导我们考虑无速率码,因为在n趋于无穷大的极限情况下,无速率码可以被视为最大距离可分 (MDS) 码。RLNC 就是这样一种无速率码,它通过对原始数据进行随机线性组合来构建编码包。
按需采样(例如从 RLNC 编码)的假阴性概率为(1/q)^s其中q表示编码系数域的基数。本文对其中一种协议进行了完整描述:《从索引到编码: 数据可用性采样的新范式》。
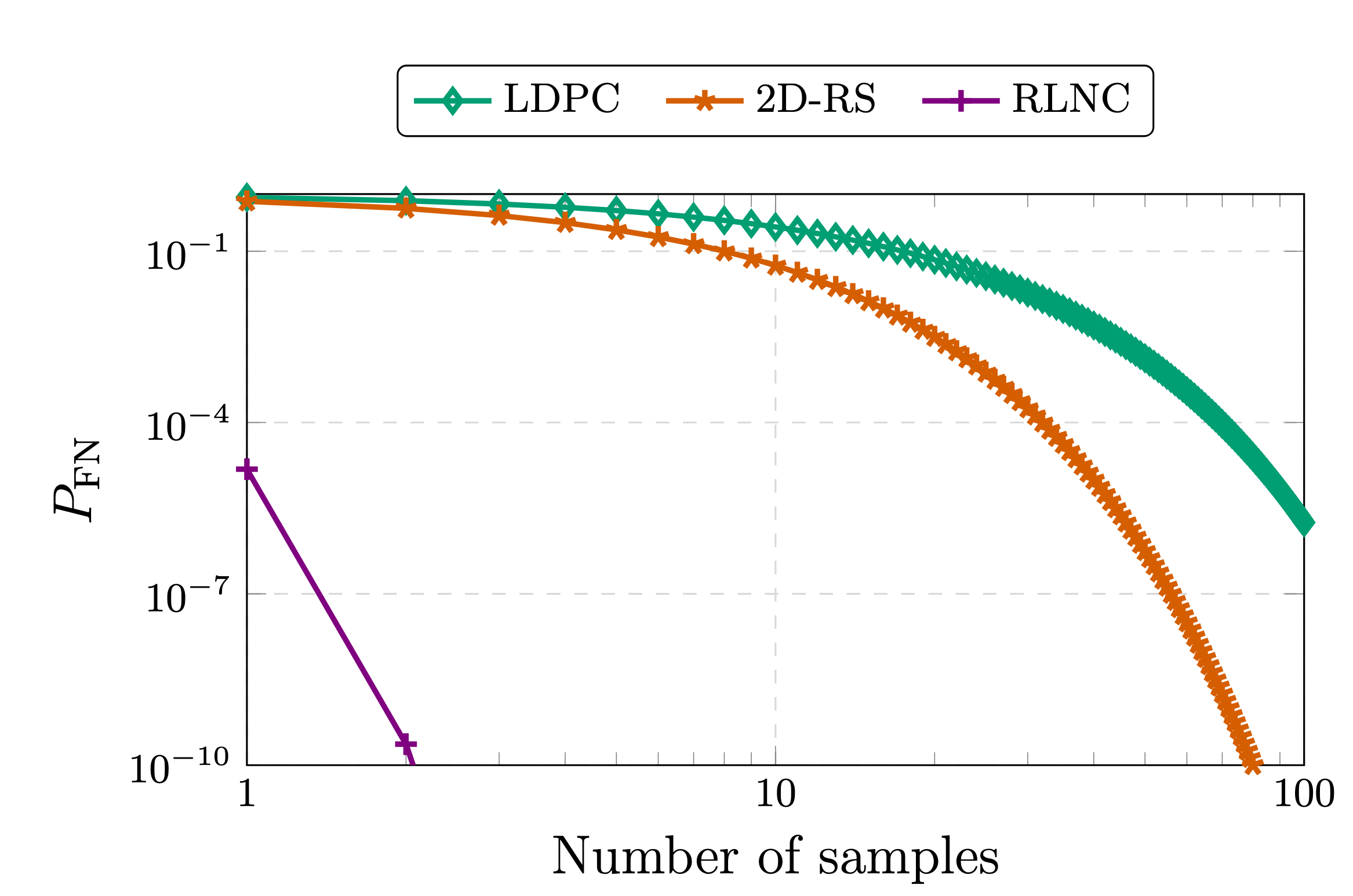
从编码数据中采样时出现假阴性(未检测到底层有效载荷的不可解码性)的概率(参见[1],[2])。
真正去中心化的潜力
固定速率编码数据的另一个缺点是样本是独立的,这会导致修复过程成本高昂。例如,对于 PeerDAS 中使用的 1D RS 码,由于 RS 码局部性较差,丢失 RS 编码数据块中的单个单元格需要下载相当于整个数据块的数据才能重建数据。引入张量码后情况会有所改善,但像 RLNC 这样的非结构化编码也可以提供更去中心化的分布式托管方案。
@Nashatyrev提出了一种使用 RLNC的去中心化托管协议,该协议在修复带宽以及传播和存储开销方面表现出良好的特性。
参考
[1] Al-Bassam, Mustafa 等。“欺诈和数据可用性证明:检测轻客户端中的无效区块。”国际金融密码学和数据安全会议。柏林,海德堡:Springer Berlin Heidelberg,2021 年。
[2] Yu, Mingchao 等。“编码默克尔树:解决区块链中的数据可用性攻击。”国际金融密码学与数据安全会议。Cham:Springer International Publishing,2020。





