

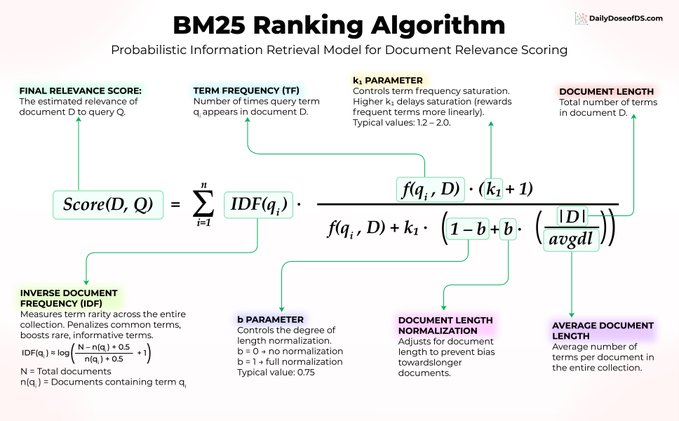
向量搜索并非万能。 一个已有 30 年历史、无需训练、无需嵌入、无需微调的算法,至今仍在为 Elasticsearch、OpenSearch 以及大多数生产级搜索系统提供动力。 它就是 BM25,值得我们探究它为何经久不衰。 假设你在一个机器学习论文库中搜索“transformer attention mechanism”(transformer 注意力机制)。 BM25 使用三个核心思想对文档进行评分: 1) 词语稀有度比词频更重要 每篇论文都包含“the”和“is”,因此这些词本身并不具有任何信号意义。 但“transformer”一词具体且信息丰富,因此 BM25 会赋予它更高的权重。在公式中,这体现在 IDF(qᵢ) 上。 2) 重复出现会有帮助,但收益递减 如果“attention”(注意力)一词在一篇论文中出现 10 次,这是一个很强的相关性信号。但从 10 次到 100 次的出现,对得分的影响微乎其微。 BM25 应用了由 f(qᵢ, D) 和参数 k₁ 控制的饱和曲线,从而防止关键词堆砌操纵搜索结果。 3) 文档长度归一化 一篇 50 页的论文自然比一篇 5 页的论文包含更多的关键词命中。 BM25 使用 |D|/avgdl 进行调整,该值由参数 b 控制,因此较长的文档不会仅仅因为文本量更多而占据排名优势。 三个核心理念。无需神经网络。无需训练数据。仅需经受时间考验的优雅数学。 这里是大多数人忽略的部分:BM25 擅长精确关键词匹配,而这正是嵌入算法的弱项。 当用户搜索“错误代码 5012”时,向量搜索可能会返回语义相似的错误代码。而 BM25 每次都能找到完全匹配项。 这正是混合搜索成为顶级 RAG 系统默认设置的原因。 将 BM25 与向量搜索相结合,即可在单一流程中实现语义理解和精确的关键词匹配。 因此,在您动辄就用 GPU 解决所有搜索问题之前,请考虑一下 BM25 是否已经能够解决问题,或者至少,两者结合后,语义搜索的性能将显著提升。
本文为机器翻译
展示原文
来自推特
免责声明:以上内容仅为作者观点,不代表Followin的任何立场,不构成与Followin相关的任何投资建议。
喜欢
收藏
评论
分享




