

许多人在日常生活中使用人工智能,却并不关注自己的数据是如何被处理的。Nesa提出的问题旨在唤起人们对这种漠不关心的关注。
要点总结
如今人工智能已成为我们日常生活的一部分,人们毫不犹豫地上传大量数据,却忽略了数据实际上要经过中央服务器这一事实。
就连负责美国安全的CISA代理局长也向ChatGPT泄露了机密文件。
为了解决这个问题,NESA 在数据传输之前使用数据转换 (EE) 和节点到节点分区 (HSS-EE),以确保任何一方都看不到原始数据。
Nessa 的技术非常先进,经过了大量的学术验证,并已获得宝洁等大型企业的认可和应用案例。
然而,整体市场更倾向于大型科技公司的集中式 API,因此未来是否会有更多客户采用去中心化的隐私 AI 仍有待观察。
1. 您输入的数据安全吗?

2026 年 1 月,有消息透露,美国网络安全和基础设施安全局 (CISA) 代理局长 Madhu Gottumukkala将敏感的政府文件上传到 ChatGPT,其目的仅仅是为了总结和整理与合同相关的文件。
当然,这些内容并未存储在 ChatGPT 内部,也未被上报政府。这起案例中,相关内容是由公司自身的安全系统检测到,并因涉嫌违反安全规定而展开调查。
就连美国国家安全局也经常使用人工智能,甚至包括上传机密文件。
用户输入的数据经过加密,因此是安全的。没错,数据确实经过了显式加密。然而,它的结构实际上是可以解密的。信息只能在持有有效搜查令或紧急情况下才能提供,但我们并不清楚幕后发生了什么。
率先了解亚洲 Web3 市场的洞察,超过 23,000 位 Web3 市场领导者正在阅读此内容。
2. Nesa:人工智能在日常生活中的隐私保护
人工智能已经融入我们日常生活的方方面面。从文章摘要到代码编写,甚至电子邮件的撰写,它都深度嵌入其中。更令人担忧的是,正如上述案例所示,我们常常在缺乏足够谨慎的情况下,将机密文件和个人信息委托给人工智能。
问题的关键在于所有这些数据都要经过服务提供商的中央服务器。即使数据经过加密,解密密钥也掌握在服务提供商手中。我们怎么能相信这一点呢?
用户输入数据可能通过多种渠道暴露给第三方,包括模型改进、安全审查和法律诉讼。对于企业用户,组织管理员可以访问聊天记录;即使是个人用户,也可以通过搜查令访问数据。

随着人工智能日益深入地融入我们的日常生活,现在是时候重新审视隐私问题了。
Nesa项目旨在改变这种现状。它创建了一个去中心化的基础设施,无需将数据委托给中央服务器即可实现人工智能推理。用户输入的数据以加密形式处理,任何节点都无法查看原始数据。
3. 内萨是如何解决这个问题的?
假设有一家医院使用NESA。
一位医生想诊断患者的核磁共振图像是否存在肿瘤。目前的AI服务只是简单地将图像传输到OpenAI或谷歌的服务器。但使用NESA,图像会在离开医生的电脑之前,根据特定的规则进行转换。
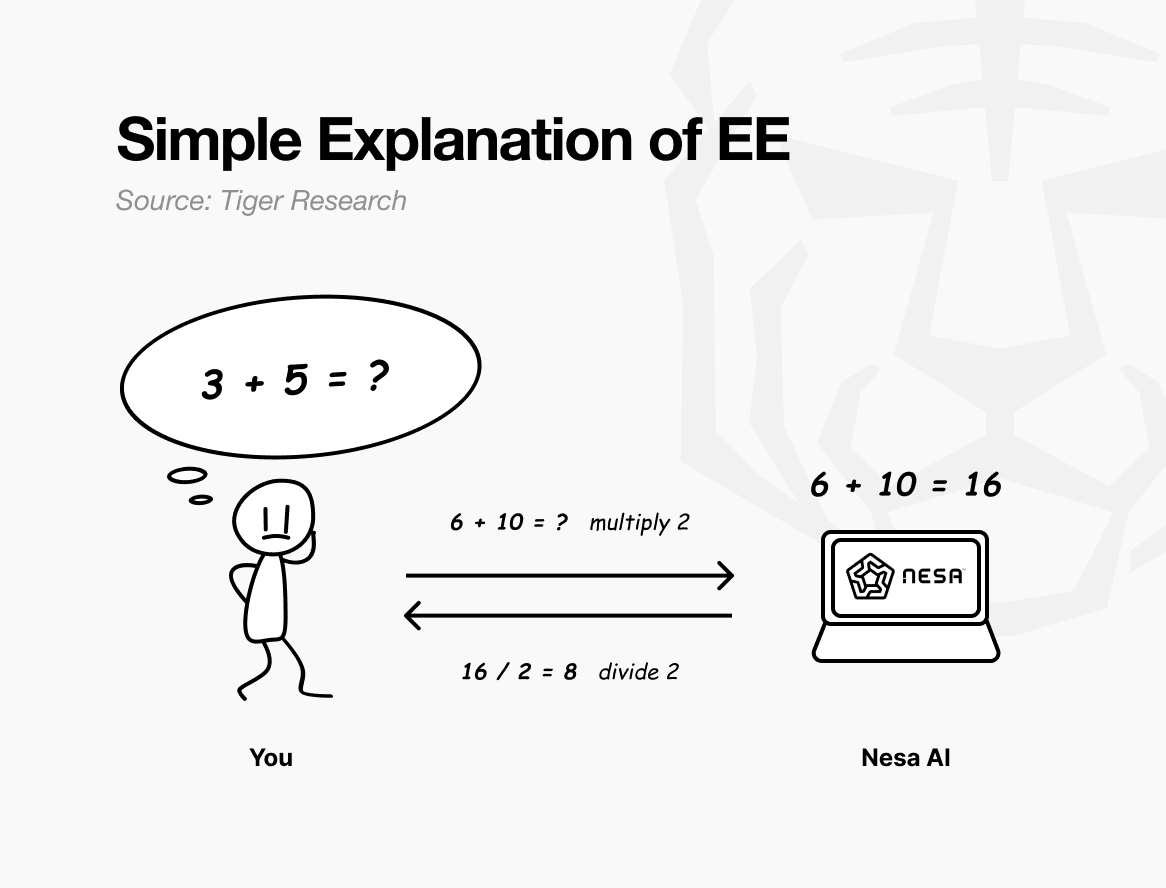
简单来说,我们来想一个数学测试题。假设原题是“3 + 5 = ?”。如果你把这道题给别人看,他们会立刻明白你想计算什么。
但是,如果你在发送之前将所有数字乘以 2,对方收到的问题就变成了“6 + 10 = ?”。对方解出这个问题后,会返回答案 16。
我再次应用÷2,得到8。这和我最初解题的答案一样。另一个人帮我计算了,但他不知道我最初的答案是3和5。
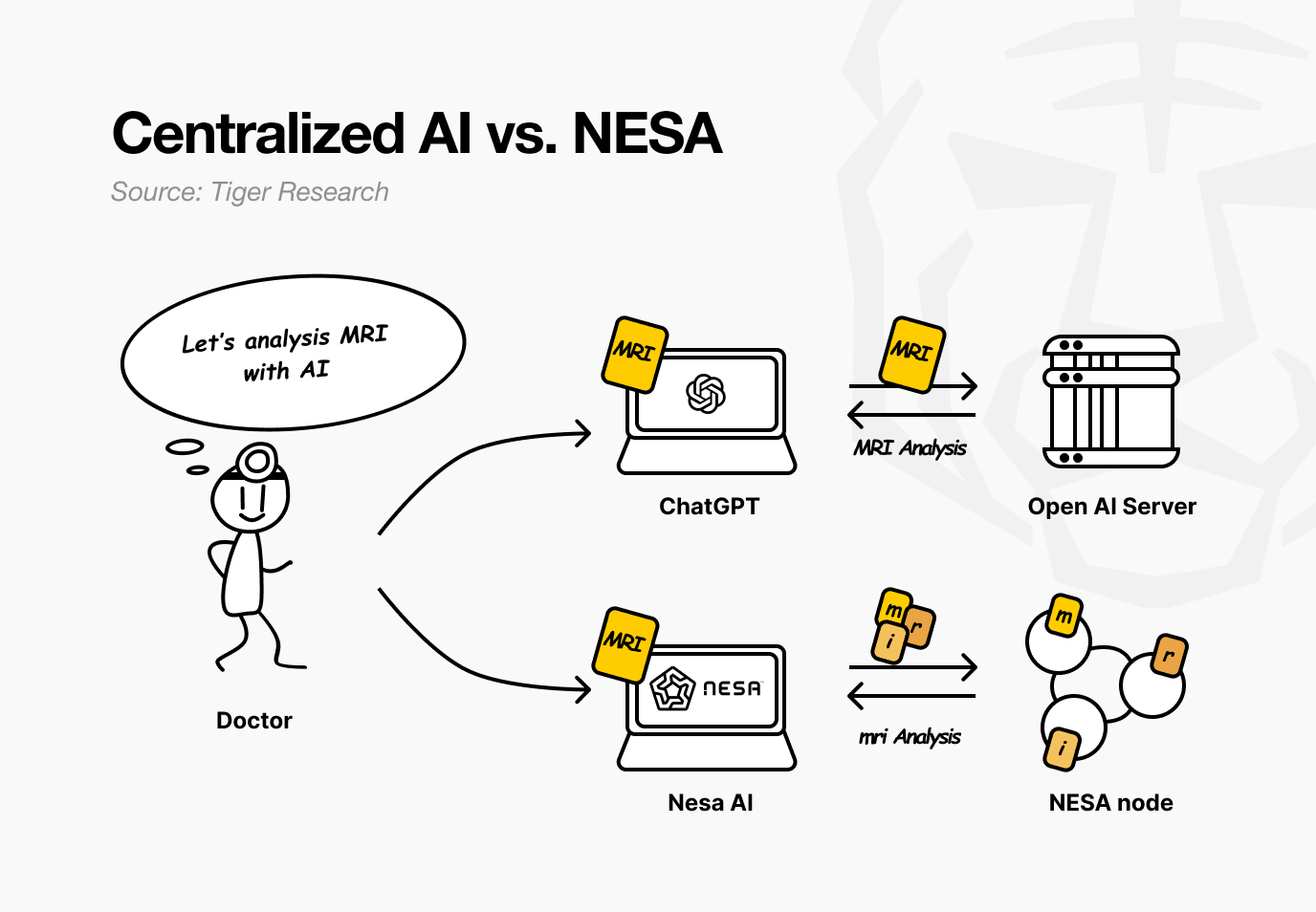
回到医院后,医生没有任何感觉。上传图像和接收结果的流程与之前相同。不同之处在于,流程中的任何节点都无法查看患者的原始核磁共振图像。
NESA更进一步。虽然EE本身可以阻止节点查看原始数据,但转换后的数据却完全存储在单个服务器上。HSS-EE(基于加密嵌入的同态秘密共享)技术甚至可以分割这些转换后的数据。
总而言之,EE 是一种“转换数据,使原始数据不可见”的技术,而 HSS-EE 则“将转换后的数据进一步拆分,使其不会集中在一个位置收集”。这种结构提供了双重隐私保护。
4. 提高隐私保护会减慢进程吗?
加强隐私意味着降低速度。这是密码学中一条由来已久的原则。最广为人知的全同态加密(FHE)比标准计算慢1万到100万倍。这使得它不适用于实时人工智能服务。
Nesa的同构加密 (EE) 则有所不同。回到数学试卷的比喻,先应用 ×2 再回到 ÷2 的额外成本微乎其微。这是因为,它不像全同态加密 (FHE) 那样将问题完全转换到不同的数学框架,而只是在现有计算的基础上增加了一个简单的变换。
EE(等效加密):基于LLaMA-8B,延迟时间增加小于9%(准确率达到原值的99.99%或更高)
HSS-EE(分布式加密):基于LLaMA-2 7B,每次推理耗时700-850毫秒。
本文中,名为 MetaInf 的元学习调度器控制着整个网络的效率。该系统能够根据模型大小、GPU 规格和输入特征自动选择最快的推理技术。与现有的基于机器学习的选择器相比,它实现了 89.8% 的准确率和 1.55 倍的加速比。该方案已在 COLM 2025 会议上发表,进一步验证了其学术价值。
以上数据来自受控测试环境。然而,NESA 的推理基础设施已在实际企业环境中投入使用,展现了其在实际应用中的性能。
5. 谁来撰写?如何撰写?
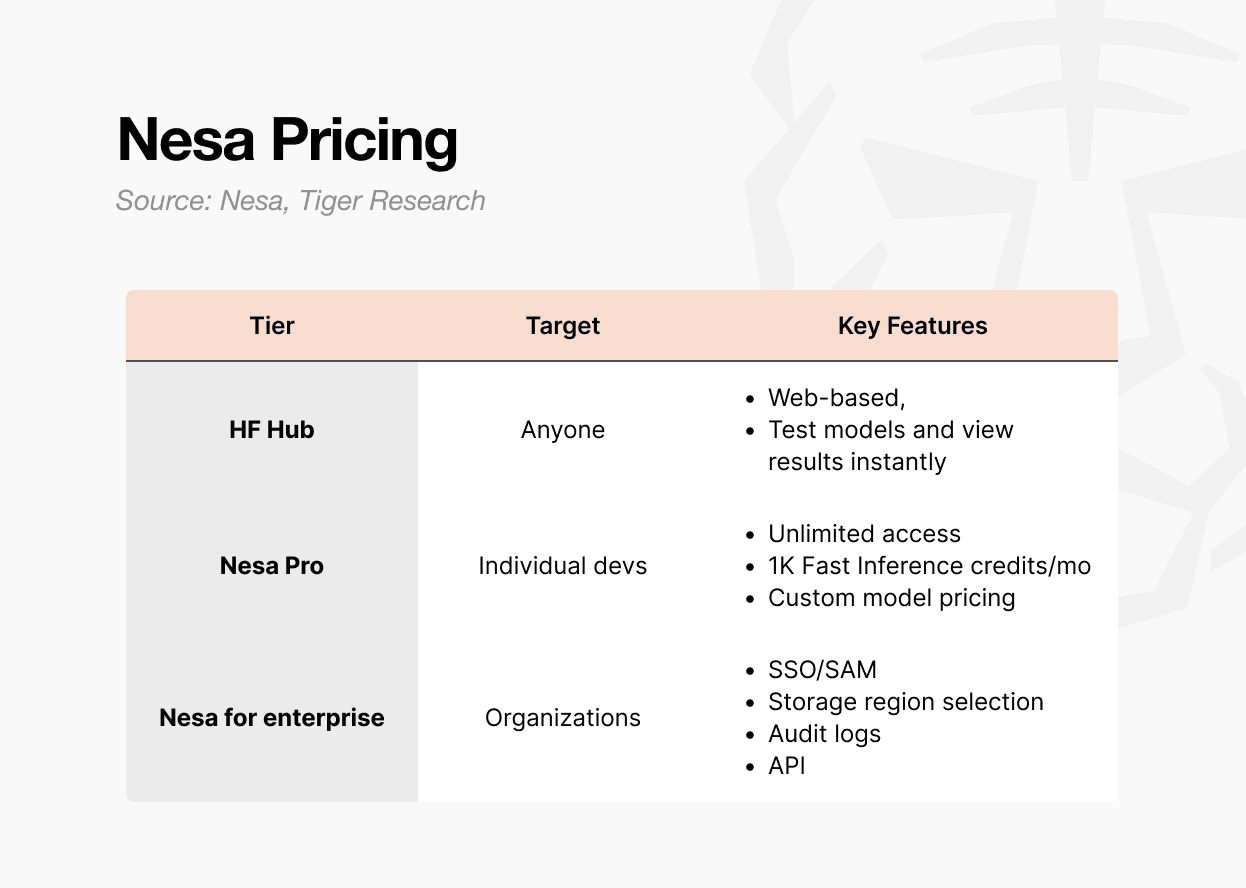
第一个是 Playground。这是一个可以直接从网页选择和测试模型的环境。您无需是开发人员即可使用它。您可以尝试每个模型的输入,并查看结果。这是亲身了解去中心化 AI 推理实际运作方式的最快捷径。
第三种选择是企业版。这是一种独立的合同结构,并非公开计划。它包含单点登录/SAML 支持、存储区域选择、审计日志、精细访问控制以及基于年度承诺的计费方式。
总而言之,如果您想轻松试用,请选择 Playground;如果您想进行个人开发或小规模开发,请选择 Pro;如果您想在组织层面引入,请选择 Enterprise。
6. 为什么需要令牌?
去中心化网络缺乏中央管理员。运行服务器的实体和验证结果的实体都分散在全球各地。这就引出了一个问题:为什么这些人要启动他们的GPU并为他人处理AI推理?
它还作为一种治理工具,决定着网络的发展方向。$NES 持有者可以提议并投票表决核心网络参数,例如费用结构和奖励率。
总而言之,$NES 有三个用途:它既是推理请求的支付手段,又是矿工的抵押品和奖励,还参与网络治理。节点运行需要代币,而节点的运行是隐私人工智能正常运行的必要条件。
然而,有一点值得注意:代币经济要按预期运行,需要一些先决条件。
必须有足够的推理需求,才能确保矿工获得有意义的奖励,留住矿工,并有足够的矿工来维持网络质量。
7. 隐私人工智能的必要性
NESA 试图解决的问题很明确:它希望改变在使用人工智能时向第三方公开数据的结构。
在去中心化人工智能项目中,很少见到对专有加密原语进行纸面验证并将其部署到实际基础设施上。像宝洁这样的企业客户正在该基础设施上运行推理,这对于这样一个早期项目来说是一个重要的信号。
其次,是产品可用性。虽然 Playground 为用户提供了一个可以亲身体验模型的空间,但它目前的配置更像是一个旨在吸引投资的 Web3 服务,与我们日常使用的 AI 服务相去甚远。
第三,规模验证。在受控环境下进行基准测试与在数千个节点同时运行的生产环境中进行测试截然不同。网络在完全扩展后能否保持相同的性能是另一个问题。
当隐私人工智能市场全面开放时,它将成为首批被命名的项目之一。
🐯 来自 Tiger Research 的更多内容
이번 리서치와 관련된 더 많은 자료를 읽어보세요.免责声明
本报告部分内容由美国国家环境科学研究院 (NESA) 提供支持,但研究是独立进行的,并且基于可靠的信息来源。 然而,本报告中的结论、建议、预测、估计、展望、目标、意见和观点均基于编制时的最新信息,并可能随时更改,恕不另行通知。因此,对于因使用本报告或其内容而造成的任何损失,我们概不负责,且不对信息的准确性、完整性或适用性作出任何明示或暗示的保证。此外,其他人士或机构的意见可能与本报告的意见不同或不一致。本报告仅供参考,不应被视为法律、商业、投资或税务建议。此外,任何提及证券或数字资产的内容仅用于说明目的,并不构成投资建议或提供投资咨询服务的要约。本资料并非面向投资者或潜在投资者。
使用条款
Tigersearch在其报告中支持合理使用原则。该原则允许出于公共利益目的广泛使用内容,前提是不得影响其商业价值。根据合理使用原则,无需事先获得许可即可使用报告。但是,引用Tigersearch报告时,必须:1)明确注明“Tigersearch”为来源;2)按照Tigersearch品牌指南,使用Tigersearch 黑白标识。转载材料需另行协商。未经授权的使用可能导致法律诉讼。





