

被 Karpathy 的 autoresearch 启发,我让 VibeHQ 学会了自我进化,不是进化单一 agent,是进化整个Multi Agents的合作方式。
7 次全自动运行,零人工介入:
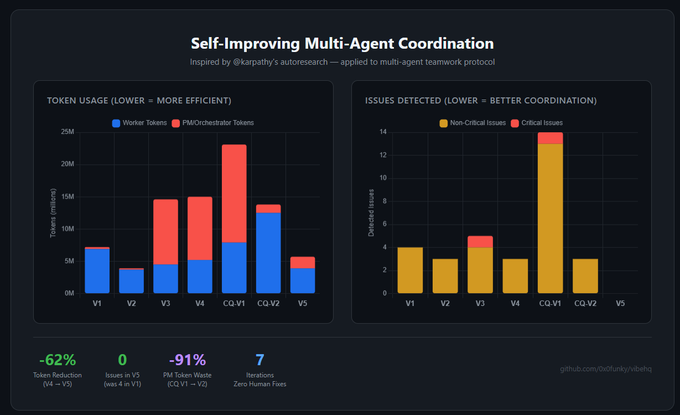
• Token 用量:7.2M → 5.7M(峰值降 62%)
• 协调相关问题降低 (重复工作等情况发生...):4 → 0
• PM token 浪费:-91%
回圈: benchmark → 合作量化以及 LLM 分析失败模式 → /optimize-protocol 重写协调 code → rebuild → repeat。
AI自己看著 agents 团队合作失败,自己分析为什么失败,然后自己改自己的 source code 来协调合作逻辑,全程零人工,完全让AI来自己组织自己的团队默契。
看了一下相关的东西,autoresearch 在自动优化Model的训练,之前的 Ralph 是单 agent 的自主回圈,Gastown 同时跑 20-30 个 Claude Code 做
orchestration 但并没有进化的能力,这些都很猛,不过到后面也都在进化单一 agent 的能力。
没人在进化团队合作本身,怎么分工、怎么避免冲突、怎么共享 context、怎么互相 unblock,跟真实世界一样,AI team 也是需要磨合的。
想像一下这东西跑下去会变什么:
• Agents 自己发展出团队文化跟工作默契。
• 按项目进行自适应,依据项目开发程度来分配 3 人 team 或是 7 人 team 。
• 越多项目一起做,团队越强。
• Agents 可以在项目进行中 onboard 新队友,自动重新分配工作。
说真的,最后会进化成什么?我也不知道,但这反而是最让人兴奋的部分。

Andrej Karpathy
@karpathy
03-10
Three days ago I left autoresearch tuning nanochat for ~2 days on depth=12 model. It found ~20 changes that improved the validation loss. I tested these changes yesterday and all of them were additive and transferred to larger (depth=24) models. Stacking up all of these changes,

详细实验数据结果可看这篇
来自推特
免责声明:以上内容仅为作者观点,不代表Followin的任何立场,不构成与Followin相关的任何投资建议。
喜欢
收藏
评论
分享




