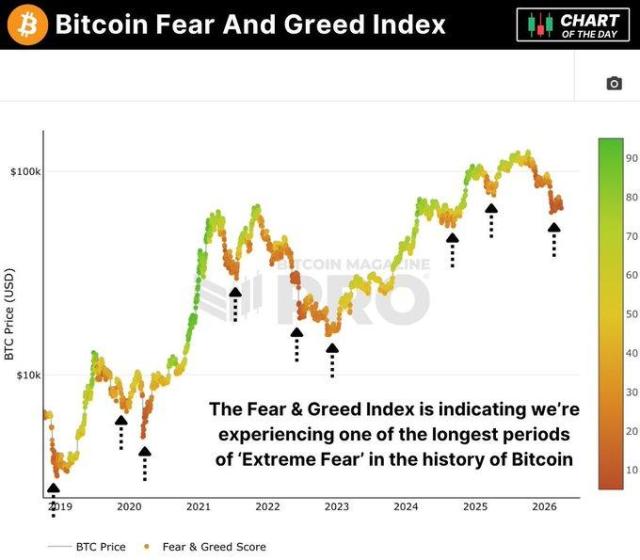
下一代LLM的benchmark,不应该在swe-bench lite/verified/pro/ultra上跑了,
应该每月封闭单独偷偷随机在github上找到5000个issues,用同样的harness,让所有模型跑,让一个裁判agent写test case来确定是否成功,
因为issue都是随机找的,也不用关心resolved数量和百分比,直接看相对排名就可以了。
这样也不用担心用swe-bench去fine tuning甚至作弊,也不用担心A厂商能复现、B厂商无法复现、C厂商cherry pick最佳结果等等不可控因素,
大家只要看本月最新的官方leaderboard大排名就可以了。
比以前同时跑俩model,让网友手动投票左边还是右边好用,要强得多。
注意,这个排名的纵向是没有参考价值的,也许3月份第一名A模型解决了60%的问题,4月份第一名B模型只解决了40%的问题,因为3月和4月的issues是完全不同的,也就没有任何纵向对比的必要性。
只要看本月相对排名的名次就可以了。
这才是真正的赛博斗蛐蛐。
来自推特
免责声明:以上内容仅为作者观点,不代表Followin的任何立场,不构成与Followin相关的任何投资建议。
喜欢
收藏
评论
分享