Karpathy 分享了他如何构建本地的 AI 知识库
跟我用的方法也很相似,但还是有很多可以借鉴的地方,推荐看看。
都是用的 Obsidian,纯本地 MD,然后用一些反向链接、索引的方式把它们连起来。
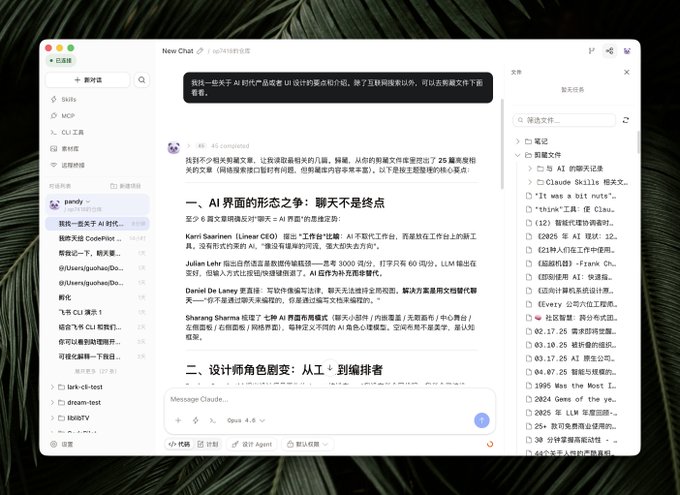
他构建了一个用大语言模型驱动的个人 Wiki 知识库,然后把原始资料都丢进一个叫 RAW 的目录。
然后让大语言模型把这些原始资料编译成一个 Markdown Wiki,实现以下功能:自动创建摘要、创建索引、创建概念条目、添加相互链接、生成可视化等等。
我是在内容收集的时候就已经做好了,用的是 Obsidian 的那个剪藏插件。
在收集内容的时候,AI 就会自动进行以下处理:打标签、自动总结、翻译、创建摘要,目前就是还没有反向链接。
然后它的 Wiki 构建好以后,就可以在这个 Wiki 上提问,确保数据来源的可置信度。
比如说大语言模型会自己查索引、读相关的文档,写出回答或者报告,不只是在网页上搜。这样的话,它获取的信息基本上都是跟你相关的。
然后它的输出也尽量不是一句话,而是新的文件、新的可视化网页或者是 PPT,然后再回归到知识库里,让知识库越用越厚。
但这个会造成一个问题,就是 Obsidian 的作者也说了,这会污染知识库。所以最好把可靠性来源和 AI 生成的东西分开放。
还有一个比较好的点是,它会让大模型对 Wiki 做健康度检查。比如:找一些自相矛盾的地方、补发一些缺失的信息、发现一些新的关联、提高一致性。
其实现在很多人都是这样做的,我也把这套理念放到了 CodePilot 里。
关于助理文件夹的选择,我一般建议使用 Obsidian 文件夹。
如果你有自己的 Obsidian 文件夹,进去以后 AI 就会直接获取你所有的上下文和知识。
比如这里我就让他从我的 Obsidian 文件夹和网络同时找了一些关于 AI 时代的 UI 设计原则的文章,质量非常高。
这样一来,你直接就能获得一个拥有完整记忆的 AI 助理。
如果你不知道怎么实践的话,推荐用 Codepilot 的助理试试。
把你的 Obsidian 文件夹放进去,让它帮你整理,同时让它把这些原则写到 Claude.md 里面。

Andrej Karpathy
@karpathy
LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating

香蕉🍌做的图

歸藏(guizang.ai)
@op7418
用香蕉做一张图片,来解释 Karpathy 的方法和我的方法之间的一些区别和共性 x.com/op7418/status/…
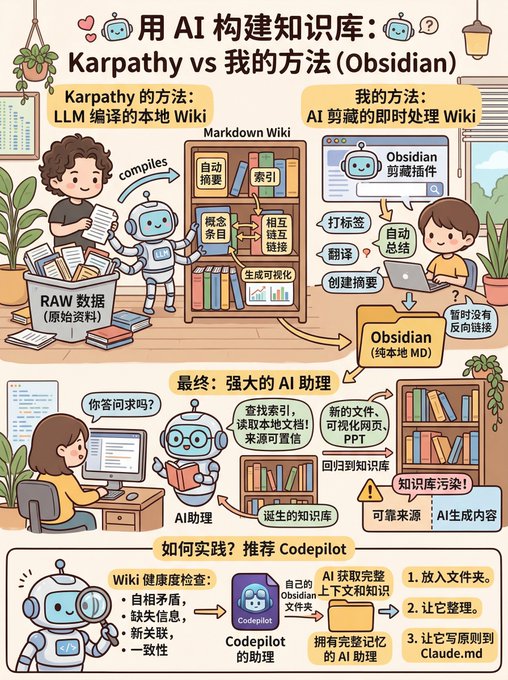
来自推特
免责声明:以上内容仅为作者观点,不代表Followin的任何立场,不构成与Followin相关的任何投资建议。
喜欢
收藏
评论
分享