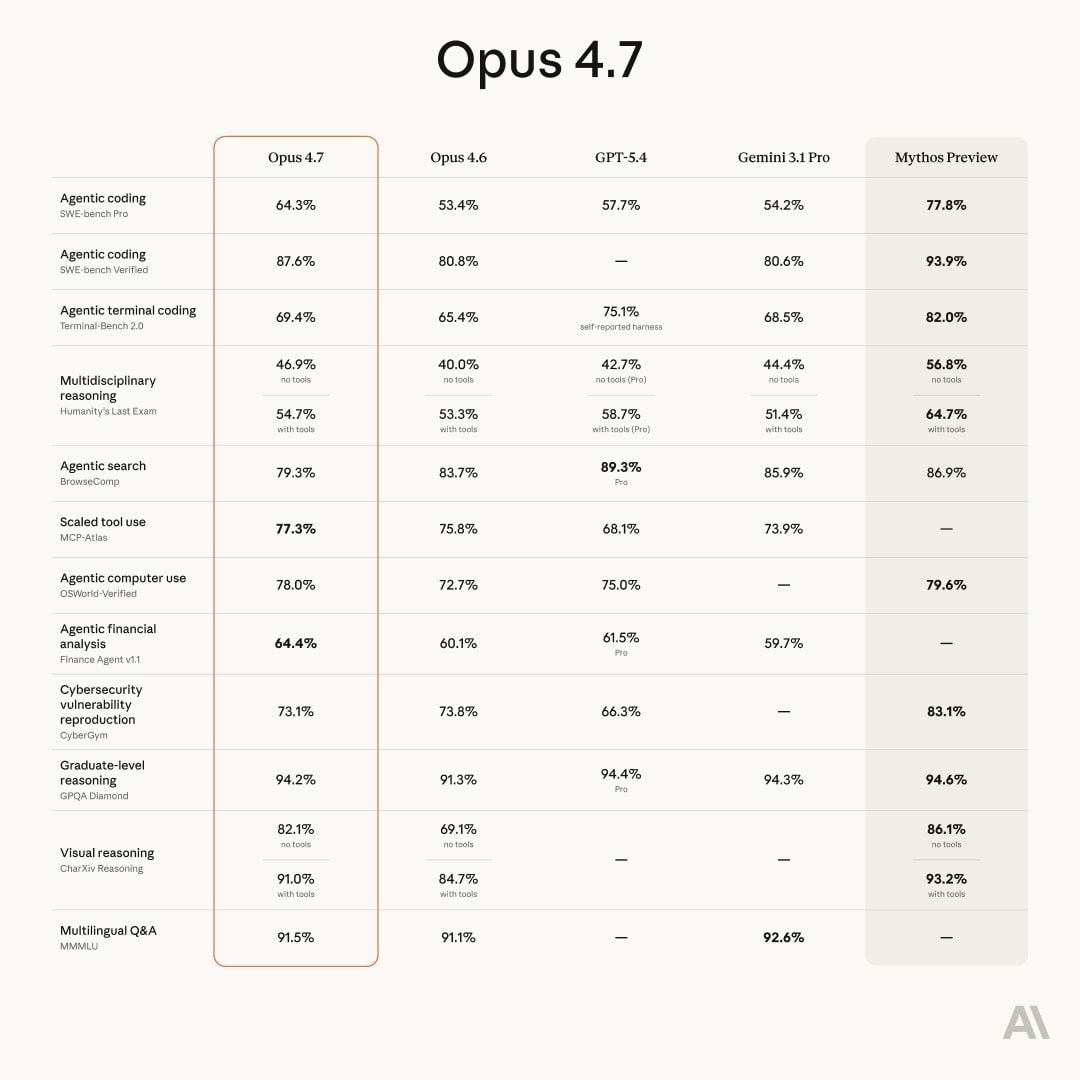
比起 Opus 4.7,我对 Mythos 更感兴趣。 在社区对 Opus 4.7 的快速发布兴奋不已之际,Anthropic 悄然公布了 Mythos 的惊人性能指标。 从 Opus 4.6 到 4.7 的升级总体来说较为稳定。基于 SWE-bench Pro 的测试结果,其性能提升了约 11 个百分点,从 53.4% 提升至 64.3%;基于 Terminal-Bench 的测试结果,其性能提升了约 4 个百分点,从 65.4% 提升至 69.4%。作为一次代际升级,各项性能指标的提升幅度较为均衡,但各测试指标的提升幅度仅为个位数到几十个百分点,因此可以称之为“稳步提升”。 另一方面,从 Opus 4.7 到 Mythos Preview 的飞跃则完全是另一个层面。 SWE-bench Pro 的得分从 64.3% 跃升 13.5 个百分点至 77.8%,Terminal-Bench 的得分也从 69.4% 上升 12.6 个百分点至 82.0%。SWE-bench Verified 的得分从之前的 87.6% 攀升至 93.9%。高分范围的进一步提升意义非凡,不仅仅体现在数值上,因为该领域的难度呈指数级增长。在 Humanity's Last Exam 测试中,“使用工具”基准测试也取得了所有模型中最高的得分,从 54.7% 上升 10 个百分点至 64.7%。与此同时,Cybersecurity 基准测试的得分在 4.6% 至 4.7% 之间略有下降,随后 Mythos 的得分飙升 10 个百分点至 83.1%。 然而,Mythos 目前仍处于预览阶段,并且由于某些基准测试(例如规模化工具使用、财务分析和多语言问答)的测量数据尚不可用,因此其作为通用模型的完整性仍需验证。但是,仅从已测量的范围来看,如果 Opus 4.7 是 4.6 的增量式演进,那么 Mythos 似乎就是我们真正期待的下一代模型。 期待 Mythos…… #AI #Opus4.7 #Mythos #Anthropic #Claude
本文为机器翻译
展示原文
相关赛道:

Telegram
免责声明:以上内容仅为作者观点,不代表Followin的任何立场,不构成与Followin相关的任何投资建议。
喜欢
收藏
评论
分享