过去几个月,我一直在撰写关于人工智能的文章,特别是关于逻辑层模型(LLM)的底层工作原理。读者反响热烈,一些读者还提出了后续问题。其中一个反复出现的主题是上下文窗口:它们是什么,如何工作等等。
到处都能看到这些数字:10万代币的发行窗口、100万代币、1000万代币。数字不断攀升,宣传攻势也愈演愈烈,但大多数人却完全不明白这一切究竟意味着什么。
所以今天,我们就来解决这个问题。
读完这封信,您将了解什么是上下文窗口,为什么更大的数值并不总是意味着更好的模型,以及下次选择使用哪种人工智能时应该如何考虑所有这些因素。我还会分享一些优化上下文窗口的技巧和窍门,无论您使用什么模型。
简易版
上下文窗口是模型的运行内存。
模型完成其工作所需的一切都必须包含在单个请求中。这包括您的提示、系统指令、您上传的任何文档或图像、聊天记录、模型可以访问的工具以及它即将生成的响应。
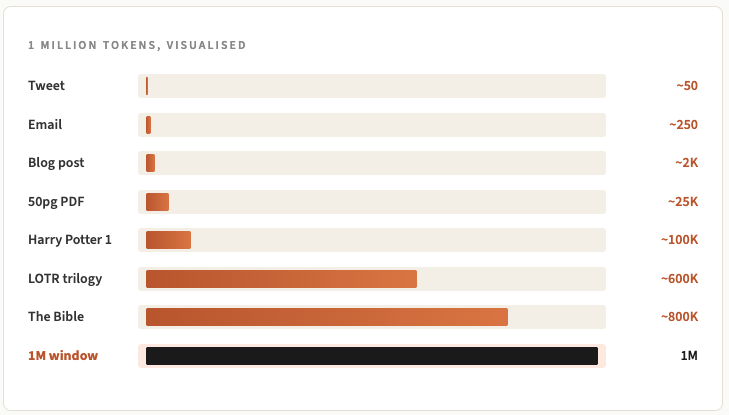
所有内容共享同一个预算,预算以词元(token)为单位。我在第108封信中介绍过词元,但为了方便回顾,一个词元大约是四分之三的单词。因此,一个20万词元的上下文窗口可以同时容纳大约15万个单词的内容。一百万个词元大约是75万个单词,作为参考,这相当于一部相当长的小说的长度。
我们是如何从 4000 个代币增长到 1000 万个代币的?
ChatGPT 于 2022 年底推出时,采用的是 GPT-3.5 模型,其令牌窗口只有 4000 个。因此,用户无法粘贴长篇文章,否则就会遇到瓶颈。
Meta 的 Llama 4 Scout 声称有 1000 万,这在我看来有点过分了,因为随着上下文窗口的扩展,输出质量会显著下降(稍后会详细介绍)。
总体而言,从 ChatGPT 推出至今,其增长了 250 倍至 2500 倍。
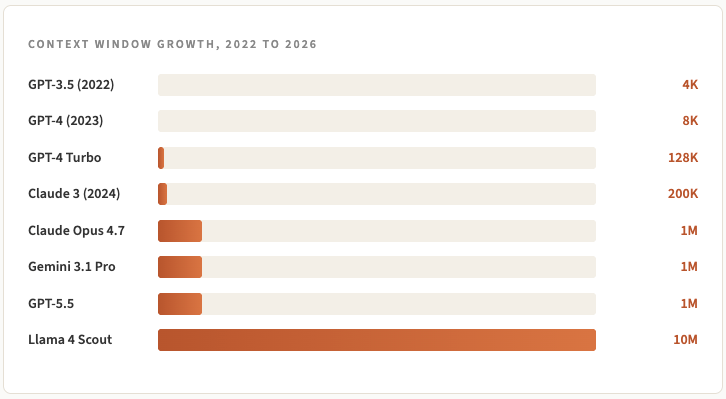
近期取得的大部分进展都得益于围绕注意力机制、即时缓存和高效内存管理等方面的巧妙工程设计。
越大越好吗?
一般来说,我不是这方面的专家(尽管坊间传言并非如此),但就人工智能上下文窗口而言,越大并不总是越好。
上下文窗口大小是模型技术上可以接受的最大值,但这不一定是模型能够有效/最佳利用的大小。
Chroma 的一些研究人员去年发表了一项名为《上下文腐烂》(Context Rot)的研究。他们测试了 18 种不同的最先进模型,包括 Claude、GPT 和Gemini,用于执行不同输入长度的简单检索任务。任务本身保持不变,只有输入长度发生了变化。
随着输入数据长度的增加,所有模型的性能都下降了。一些在短输入数据上得分接近100%的模型,在处理更长的输入数据时,得分却低于50%。
该研究的名称被社区采纳,“上下文腐烂”一词也迅速成为人工智能领域的常用语。其要点很简单:随着提示信息量的增加,模型的可靠性会降低(即使这些额外内容本身无关紧要,也无法真正提供有用的上下文信息)。
导致这种上下文混乱的背后有几个原因:
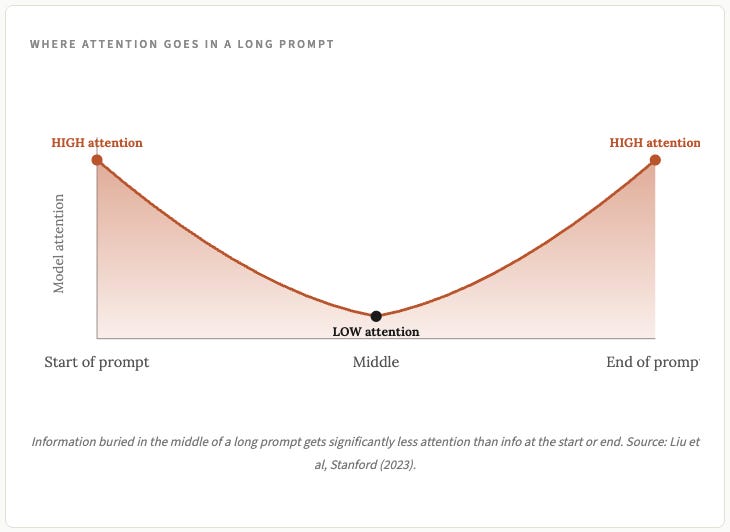
模型往往更关注提示的开头和结尾,而不是中间部分。隐藏在冗长上下文中间的重要信息可能会被忽略。研究人员称这种现象为“迷失在中间” (科学家们在命名惯例上并不以原创性著称,例如:智利的甚大望远镜)。
当提示信息中存在看似与你提问的内容相似但又不完全匹配的信息时,模型就会感到困惑。即使只有一个干扰项,也足以让它出错。
信息在提示中的位置也会影响模型对其的使用效果。同一信息位于第 1000 位和位于第 50000 位时的表现截然不同。
当问题和答案用不同的词语表达同一个概念时,随着上下文的扩展,该模型会越来越难以处理。
关键在于,广告宣传的上下文窗口大小是一个上限,而不是目标,而且对于你使用 AI 执行的几乎所有任务,你通常都应该在接近上限之前就清除上下文窗口并重新开始。
这对你的实际行动意味着什么
如果你使用人工智能来处理需要同时处理大量信息的工作,那么上下文窗口就很重要;但大多数人实际上并没有这样做。
大多数文档比人们想象的要小。例如,一份 50 页的 PDF 文件大约只有 25,000 个令牌。你可以粘贴这样的文档,与 AI 进行长时间的对话,而总共的令牌数远低于 10 万。
编写代码只会加剧这种情况。一旦涉及到子代理和并行工作,编写代码就会极大地消耗代币。
这就是为什么本地模式对某些工作来说极具吸引力的原因之一。使用本地模式没有按代币计费或使用限制。我在第 107 封信中详细介绍了本地模式,如果您想了解更多信息,可以查阅该信。
如何真正管理上下文窗口
这是我最希望你记住的信中的这部分内容。以下是我使用的实用策略,以及一些实际构建这些模型的专家的指导。
这里更宏观的视角是Anthropic工程团队称之为“情境工程”的概念。他们在2025年9月发表了一篇深度分析文章,如果你想了解更多,这篇文章值得一读。他们对该主题的总结是我见过的最好的:
“良好的上下文工程意味着找到尽可能少的高信号标记,从而最大限度地提高实现预期结果的可能性。”
这种思维方式实际上改变了我日常使用人工智能的方式。我现在不再问应该输入什么,而是问可以省略什么(再次证明,“少即是多”的原则是正确的)。
以下是由此衍生出的策略。
1. 每次聊天只处理一个任务,并且经常从头开始。
这是我养成的最有用的习惯。如果你正在研究一个主题,然后突然转向另一个主题,那就新建一个聊天窗口。如果你完成了一篇草稿,想要进行润色,那就新建一个聊天窗口。如果你花了一个小时调试一个问题,而下一个问题又与它无关,那就新建一个聊天窗口。
在 Product Talk 上撰写人工智能产品工作的 Teresa Torres说得非常好:每一次长时间的聊天都会积累噪音,而这些噪音会使下一次回复变得更糟。
2. 使用交接技术
当你需要延续上下文信息时,在重新开始之前,让模型生成一份简洁明了的要点总结。复制这份总结并粘贴到新的聊天窗口中作为开场白。
这正是 Claude Code 在达到上下文限制时自动执行的操作。Anthropic 将其称为“压缩” ,并在其上下文工程文章中将其描述为你应该首先采取的措施。他们会保留架构决策、未解决的错误和关键文件,同时丢弃冗余的工具输出和旧消息。你可以使用任何 AI 工具手动执行相同的操作。
3. 关注50%线
从事人工智能产品开发的 Arthur Clune 在最近的一篇文章中提出了一个非常精辟的观点:当上下文窗口填充超过 50% 左右时,LLM 的准确率就会开始明显下降。Anthropic 的压缩功能会在填充 95% 时自动触发,这意味着当你看到提示信息时,系统已经在降级模式下运行了一段时间。
因此,你不应该仅仅等待 Claude Code 自动压缩,因为它只有在接近文件大小限制时才会发生。你可以随时手动运行 `/compact` 命令来压缩文件。
4. 在使用人工智能之前先进行内容整理
与其往上下文里塞50份文件,指望AI能“自己搞清楚”,不如直接导入5份相关的文档,这样效果会更好。模型并不总是知道哪些信息重要(它当然也不知道哪些信息对你来说特别重要)。所以,趁现在还能利用自身优势的时候,好好利用你作为人类的优势吧。
5. 将重要内容放在开头或结尾。
中间部分信息容易被忽略的研究结果在历代模型中都适用。位于提示开头和结尾的信息比隐藏在中间的信息更容易引起注意。如果你有一篇很长的文档,其中某个段落非常重要,即使它已经在文档中出现过几次,也要在提示的结尾重新列出该段落。
6. 使用项目或自定义 GPT 来保持上下文的持久性
Claude 有“项目”功能,ChatGPT 有“自定义 GPT”功能。两者都允许您设置持久的系统提示,并上传参考文件,这些文件不会占用每次聊天的上下文。如果您有重复的使用场景,请将说明和参考资料放在“项目”或“自定义 GPT”中,而不是在每次聊天中重复输入。
7. 对大型知识库使用 RAG(红绿灯)
RAG 代表检索增强生成(Retrieval Augmented Generation)。它并非将上千篇文档直接输入到提示框中,而是将它们索引到向量数据库中,然后仅提取与每个问题最相关的部分。Perplexity、NotebookLM 和 ChatGPT 的深度研究功能等工具的底层原理正是如此。我会在以后的文章中详细介绍 RAG,它值得专门撰写一篇文章。
8. 选择适合工作的型号
Gemini 3.1 Pro 价格实惠,适合处理大型文档。Claude Opus 4.7 在处理文档时,一旦掌握了上下文信息,就能进行强大的推理能力;如果预算有限,Sonnet 4.6 则是一个不错的折中选择。GPT-5.5 是 OpenAI 目前最先进的产品,价格介于两者之间。如果您要处理一份 500 页的 PDF 文件, Gemini可能是您的理想之选。如果您要解决一个复杂的多步骤问题,Opus 或 GPT 则可能是更合适的工具。
9. 对于智能体而言,将阅读任务与思考任务分开。
如果你正在构建智能体(或者使用 Claude Code、Cowork、Cursor 等工具),Anthropic 对长时间运行智能体的研究绝对值得一看。其核心洞见在于,探索会迅速消耗上下文信息。因此,他们建议使用子智能体,这些子智能体专门用于处理特定的读取密集型任务(例如跨文件搜索、代码安全审查),并且只返回摘要信息。这样,主智能体的上下文信息就能保持干净。
你也可以手动操作。如果你想让克劳德深入研究某个问题并根据研究结果采取行动,可以在一次聊天中完成研究,得到一份简洁明了的总结,然后以这份总结为起点,在新的聊天中展开行动工作。
10. 不要粘贴不需要的图片
图片在代币方面价格不菲。一张高分辨率截图可能就要消耗 1000 到 2000 个代币。如果你在一段很长的聊天记录里上传了 20 张截图,光是图片本身就要消耗 2 万到 4 万个代币。我很喜欢截图并把内容添加到聊天记录里,但有时候真的会失控,所以提醒大家不要过度使用截图功能。
结语
希望这篇文章能帮助你更好地理解上下文窗口的概念和工作原理。大多数人看到标题吹嘘更大的上下文窗口就以为越大越好,但实际上,我现在处理的任务很少超过 20 万个标记。偶尔会达到 40 万到 50 万个标记,然后才会进行压缩,但这种情况并不常见。
也许/希望有一天这个问题能够得到解决,我们可以可靠地使用 100 万甚至 1000 万个令牌上下文窗口,而不会出现数据丢失的情况。
在此之前,请密切关注上下文。如有新任务,请定期创建新的聊天窗口;在不同的会话之间进行交接;如果您希望获得更好的结果,请在提示的开头和结尾重复重要信息。
感谢您一直以来的阅读,我们下周再见!
免责声明:本简讯内容不构成投资建议。本人并非财务顾问,以上仅代表个人观点和想法。在交易或投资任何加密货币相关产品之前,您务必咨询专业/持牌财务顾问。文中部分链接可能为推荐链接。