

PANDAS:以太坊下一代數據可用性採樣的實用方法
作者:Onur Ascigil1、Michał Król2、Matthieu Pigaglio3、Sergi Reñé4、Etienne Rivière3、Ramin Sadre3
總結
- PANDAS 是一種網絡層協議,支持 32 MB 及以上的Danksharding 。
- PANDAS 的目標是實現隨機採樣的 4 秒截止時間(在緊密分叉選擇模型下)。
- 在提議者-構建者分離(PBS)之後,資源豐富的構建者對節點執行樣本的初始分發(即播種)。
- PANDAS 在每個時隙期間分兩個階段進行:1)播種階段,其中時隙的選定構建器將二維編碼 blob的行和列的子集分發給驗證器節點,2)行/列合併和採樣階段,其中節點對隨機單元進行採樣,同時檢索和重建指定的行/列以提高單元的數據可用性。
- PANDAS 使用直接通信方式,這意味著 1 跳,即點對點通信,用於播種和採樣階段,而不是基於八卦的多跳方法或 DHT。
在設計 PANDAS 時,我們做出以下假設:
假設 1)資源豐富的構建者:按照提議者-構建者分離(PBS)方案,在 PANDAS 中,一組資源豐富的構建者(例如,具有足夠高上傳帶寬(如 500 Mbps 或更高)的雲實例)負責將種子樣本分發到網絡。[1]
假設 2)建造者激勵:建造者有動機確保 blob 數據可用,因為只有 DAS 成功,The Block才會被接受。然而,不同的建造者可以擁有不同數量的資源。理性建造者的興趣在於確保在花費最少資源的同時,數據將被視為可用。
假設 3)驗證節點(VN)是 DAS 協議的主要實體:單個驗證節點(VN)僅執行單個採樣操作(作為一個實體),與其託管的驗證器數量無關。
假設 4)不誠實的大多數:大多數(甚至絕大多數)的 VN 和建設者可能是惡意的,因此可能無法正確遵守協議。
假設 5)抗 Sybil 攻擊的VN :誠實的 VN 可以使用驗證器證明方案來證明其至少擁有一名驗證器。如果多個節點嘗試重複使用相同的證明,則其他誠實節點和構建者可能會將其列入黑名單。
以下是 PANDAS 的目標:
目標 1)緊密分叉選擇:誠實的驗證者節點(VN)在對區塊進行投票之前完成隨機抽樣,即使大多數 VN 都是惡意的*。*因此,我們以緊密分叉選擇模型為目標,這意味著某個時隙委員會中的誠實 VN 必須在該時隙的四秒內完成投票前的隨機抽樣。
目標 2)靈活的構建者播種策略:鑑於不同的構建者可以擁有不同的資源,我們的設計允許The Block構建者靈活地實施不同的 blob 分發策略,每種策略在安全性和資源使用之間都有不同的權衡。為了獲得更高的安全性,構建者可以向驗證者節點發送更多 blob 單元的副本,從而確保更高的可用性。相反,為了最大限度地減少資源使用,構建者最多可以分發每個單元的單個副本,以降低安全性為代價減少帶寬使用。這種靈活的方法允許構建者在確保數據可用性和優化帶寬之間進行權衡,同時激勵驗證者節點認為The Block可用並接受該區塊。
目標 3) 允許不一致的節點視圖:我們的目標是確保 VN 和構建者無需就 VN 列表達成共識。雖然我們的目標是讓 VN 和構建者大致同意系統中的 VN 集,但 VN 不必保持嚴格一致的視圖,也不必讓構建者和 VN 的視圖完全同步。
PANDAS 設計
持續對等發現:為了實現目標 3,系統中的節點與下面的協議階段並行執行持續對等發現,以維護包含其他對等點的最新“視圖”。構建者和 VN 旨在發現具有有效驗證器證明的所有 VN。我們希望構建者和 VN 都能對系統中的所有 VN 有一個接近但不完美的視圖。
運行對等發現協議的成員服務將新的(已驗證的)VN 插入視圖,並最終收斂為完整的 VN 集。對等發現消息被搭載到示例請求消息中,以減少發現開銷。
PANDAS 協議有兩個(不協調的)階段,在每個時隙期間重複:
階段 1 )播種,
第 2 階段)行/列合併和抽樣
在播種階段,構建器將行/列的子集直接推送到 VN,其中行/列分配基於確定性函數。一旦 VN 從構建器收到樣本,它就會合並分配給它的整個行/列(通過從分配給相應行/列的其他 VN 請求缺失的單元格)並同時執行隨機採樣。
VN 無需協調即可開始合併和採樣。因此,完成第 1 階段的節點可以立即開始第 2 階段,而無需與其他節點協調。作為時隙委員會成員的 VN 必須在時隙開始後的 4 秒內完成播種和隨機採樣。
下面,我們詳細解釋我們的協議的兩個階段。
階段 1 - 播種:構建器使用確定性函數將 VN 分配給各個行/列,該函數使用哈希空間,如下所述。VN 到各個行/列的映射是動態的,並且在每個槽中都會發生變化。映射允許節點在本地和確定性地將節點映射到行/列,而無需知道節點的數量或完整列表。
Builder 準備並向 VN 分發種子樣本,如下所示:
1.a)將行/列映射到哈希空間中的靜態區域:如圖 1 上部所示,將各個行和列分配到哈希空間中的靜態區域。
1.b)將 VN 映射到哈希空間:構建器使用抽籤函數 FNODE(NodeID, epoch, slot, R) 將每個 VN 分配給哈希空間中的鍵。該函數採用的參數包括 NodeID(即節點的標識符,即對等 ID)、epoch 和 slot 編號,以及從上一個 slot 的The Block的頭部派生的隨機值 R。
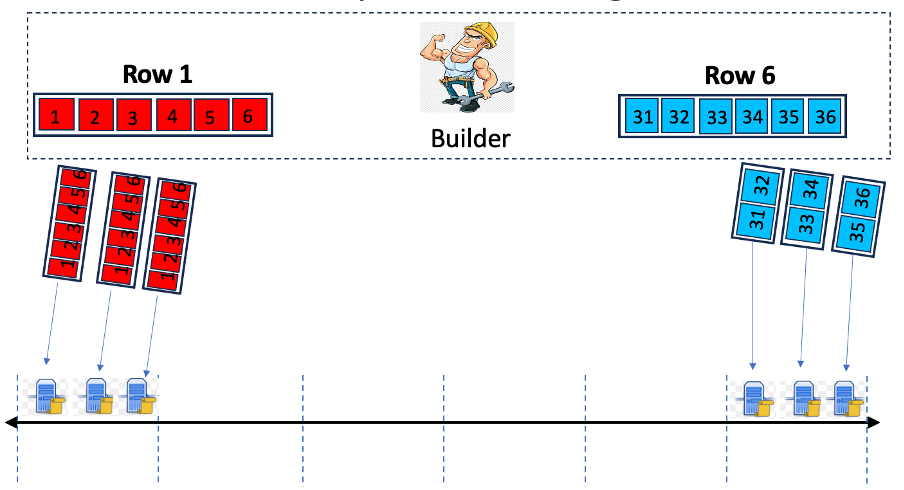
圖 1:行樣本到 VN 的分配。列樣本的映射方式類似。
分配給行區域的 VN 將從構建器接收屬於該行的單元格子集。由於 VN 在每個槽位期間使用 FNODE 重新映射到哈希空間,因此它們的行/列分配也會發生變化。
注意:在基於八卦的播種方法中,不可能按時隙動態地分配行和列給 VN,因為每行和每列的八卦通道必須隨時間保持相對穩定。
1.c)行/列樣本分佈:對於每一行和每一列,構建器採用盡力而為的分佈策略,將每一行/列的子集推送到映射到相應行/列區域的 VN。構建器使用直接通信方法,特別是基於 UDP 的協議,將每行/列的單元格直接分發到 VN。
直接溝通的理由*:*我們的目標是儘快完成播種階段,以便委員會成員有時間在投票前完成隨機抽樣(目標 1)。
行/列分佈策略:我們允許構建器根據目標 2 的資源可用性選擇分佈策略。不同的分佈策略在資源使用和數據可用性之間存在權衡。考慮圖 2 中分佈兩行的示例。在一個極端情況下(左側),構建器將整個第 1 行分佈到該行區域中的每個 VN,以提高數據可用性,但代價是更高的資源使用率。在另一個極端情況下,構建器將第 6 行的非重疊行片段發送到該行區域中的每個 VN,這需要更少的資源,但導致單個單元的可用性降低。
我們目前正在評估不同的分佈策略,包括可以確定性地將行/列的各個單元映射到行/列區域中的各個 VN 的策略。
注意:建造者僅參與播種階段。
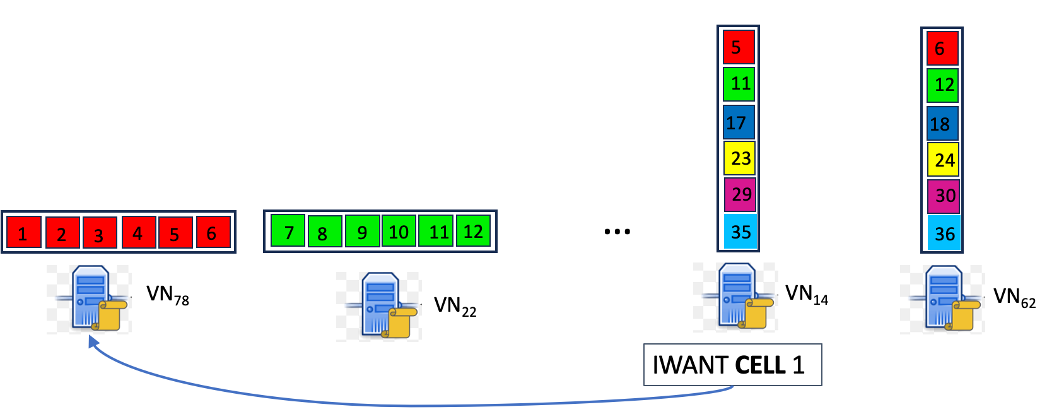
圖 2:將行樣本分發到相應行區域中的 VN 的兩種(極端)策略。
第 2 階段 - 行/列合併和採樣:當前時段委員會的 VN 旨在在時段的前四秒內(即投票截止時間)完成隨機採樣。為了提高單元的可用性,特別是對於必須在四秒內執行(隨機)採樣的時段委員會成員,VN 還會進行合併,即根據 FNODE 映射檢索分配給它們的整行和整列,作為行/列採樣的一部分。
2.a) VN 隨機抽樣:當前時段委員會中的 VN 在從建造者處收到種子樣本後,立即嘗試檢索73 個隨機選擇的單元。
使用確定性分配 FNODE,VN 可以在本地確定預計最終保管給定行或列的節點。
採樣算法:其中一些節點可能處於離線狀態或無響應。按順序發送單元請求可能會錯過委員會成員的 4 秒截止時間。
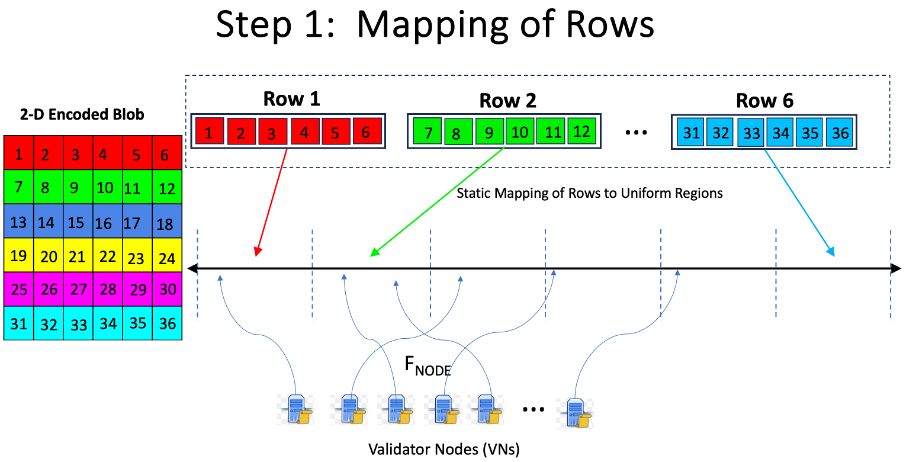
圖 3:樣本獲取示例:分配給每個 VN 的行和列顯示在相應 VN 的頂部。根據映射 FNODE 的知識,VN14 知道向 VN78 發送請求以檢索單元格一。
同時,向所有持有副本的對等點發送請求會導致網絡中消息激增,並承擔擁塞風險。因此,獲取必須在並行和冗餘請求的使用與延遲約束之間尋求平衡。我們的方法採用自適應單元獲取策略,通過基於 UDP(無連接)的協議在節點之間進行直接通信。獲取算法可以容忍丟失和離線節點。
2.b) VN 行/列合併:如果 VN 從構建器收到的其指定行或列的單元格少於一半(這是構建器選擇的分配策略的結果),它會向其他 VN 請求缺失的單元格。在行/列合併期間,VN 僅向分配給同一行/列區域的 VN 請求單元格。當 VN 擁有某一行或某一列的一半單元格時,它可以在本地重建整行或整列。
合併行/列的理由:
- 重建缺失細胞:在執行行/列採樣時,VN 重建缺失細胞。
- 提高單元格的可用性:給定確定性映射(FNODE),構建器可以選擇任何分發策略將行和列的子集發送到 VN。行/列合併旨在提高樣本的可用性,以便能夠按時完成隨機抽樣。
理想情況下,構建器應選擇一種種子樣本分佈策略,使 VN 能夠有效地合併行和列。為了實現這一點,構建器可以向每個 VN 推送一個地圖(連同種子樣本),該地圖詳細說明了行/列中的各個單元格如何分配給該行/列區域內的 VN,這是構建器分佈策略的一部分。藉助此地圖,VN 可以快速識別和檢索缺失的單元格以重建完整的行,從而提高數據的可用性。
注意:在某些 DAS 方法中,術語“行/列採樣”是指節點在對 blob 的可用性進行投票之前檢索多行和多列。在我們的方法中,節點檢索行和列以增強數據可用性,支持必須在投票前進行隨機採樣的驗證者。
我們將其稱為“行/列合併”而不是“行/列抽樣”,因為在 PANDAS 中,委員會成員基於隨機抽樣進行投票,並且他們不會直接對整行或整列進行抽樣。
那麼常規節點(RN)怎麼樣?
與 VN 不同,RN 不會從構建器獲取種子行/列樣本。構建器將初始種子樣本發送到使用驗證器證明方案的抗 Sybil 的 VN 組。目前沒有機制讓 RN 證明它們不是 Sybil;因此,來自構建器的樣本的初始分佈僅使用 VN。
使用公共確定性函數 FNODE,RN 可以類似地映射到單個行/列區域。映射到某個區域後,RN 可以(可選)執行行/列合併以檢索整個行和列,並響應對其指定區域內單元格的查詢。
與其他節點一樣,RN 必須執行對等發現。一般來說,RN 的目標是發現所有 VN,也可以嘗試發現其他 RN。通過對等發現瞭解其他對等點後,RN 可以通過直接通信執行隨機採樣。與 VN 不同,RN 完成採樣的時間不受嚴格限制 — 它們可以在 VN 之後開始採樣,例如,在收到當前時隙的The Block塊頭後。
討論和正在進行的工作
我們假設理性的建造者有動機削減成本(並減少供應),但同時,他們的目標是提供區塊(以獲得獎勵)。這意味著建造者將努力使行/列合併儘可能高效,即通過高效合併(提高單元的可用性),建造者可以在播種階段發送更少的每個單元副本以降低成本。
我們目前正在試驗不同的分發策略,其中惡意 VN 會保留樣本並試圖破壞對等發現。我們的 DAS 模擬代碼可在DataHop GitHub 存儲庫中找到。
[1] 英國蘭卡斯特大學
2 英國倫敦城市大學
3 天主教魯汶大學 (UCLouvain)
4 DataHop 實驗室





