作者:江信陵,為AI發電

圖片來源:由無界AI生成
DeepSeek 是如何訓練其 R1 推理模型的?
本文主要基於DeepSeek發佈的技術報告,解讀 DeepSeek - R1 的訓練過程;重點探討了構建和提升推理模型的四種策略。
原文來自研究員 Sebastian Raschka,發表於:
https://magazine.sebastianraschka.com/p/understanding-reasoning-llms
本文會對其中R1推理模型核心訓練部分進行總結。
首先,基於DeepSeek發佈的技術報告,以下是一張R1的訓練圖。
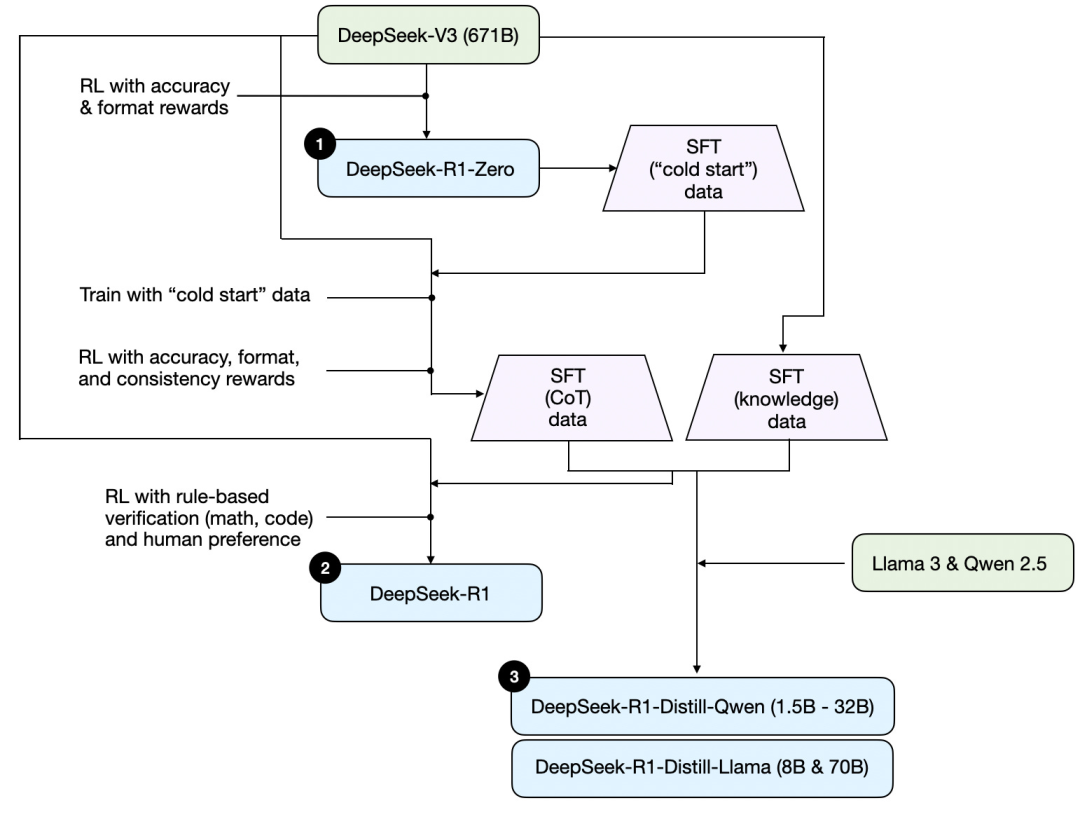
梳理一下上圖所示的過程,其中:
(1) DeepSeek - R1 - Zero:該模型是基於去年 12 月發佈的 DeepSeek - V3 基模。使用具有兩種獎勵機制的強化學習(RL)對其進行訓練。這種方法被稱為 “冷啟動” 訓練,因為它不包括監督微調(SFT)步驟,而監督微調通常是人類反饋強化學習(RLHF)的一部分。
(2) DeepSeek - R1:這是 DeepSeek 的主打推理模型,基於 DeepSeek - R1 - Zero 構建。團隊通過額外的監督微調階段和進一步的強化學習訓練對其進行了優化,改進了 “冷啟動” 的 R1 - Zero 模型。
(3) DeepSeek - R1 - Distill:DeepSeek 團隊利用前幾步生成的監督微調數據對 Qwen 和 Llama 模型進行了Fine Tuning,以增強它們的推理能力。雖然這並非傳統意義上的蒸餾,但該過程涉及到利用較大的 671B的 DeepSeek - R1 模型的輸出對較小的模型(Llama 8B 和 70B,以及 Qwen 1.5B - 30B)進行訓練。
以下會介紹構建與提升推理模型的四種主要方法
1、推理時擴展 / Inference-time scaling
提升 LLM 推理能力(或通常意義上的任何能力)的一種方法是推理時擴展 - 在推理過程中增加計算資源,以提高輸出質量。
打個粗略的比方,就像人在有更多時間思考複雜問題時,往往能給出更好的回答。同樣,我們可以運用一些技術,促使 LLM 在生成答案時 “思考” 得更深入。
實現推理時擴展的一種簡單方法是巧妙的提示工程 / Prompt Engineering。一個經典例子是思維鏈提示 / CoT Prompting,即在輸入提示中加入諸如 “逐步思考” 這樣的短語。這會促使模型生成中間推理步驟,而不是直接跳到最終答案,這樣往往能在更復雜的問題上得出更準確的結果。(注意,對於像 “法國的首都是什麼” 這類較簡單的基於知識的問題,採用這種策略就沒有意義,這也是判斷推理模型對於給定輸入查詢是否適用的一個實用經驗法則。)

上述思維鏈(CoT)方法可被視為推理時擴展,因為它通過生成更多輸出tokens,增加了推理成本。
推理時擴展的另一種方法是採用投票和搜索策略。一個簡單的例子是多數投票法,即讓LLM生成多個答案,然後通過多數表決選出正確答案。同樣,我們可以使用束搜索及其他搜索算法來生成更優的回答。
這裡推薦《Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters 》這篇論文。
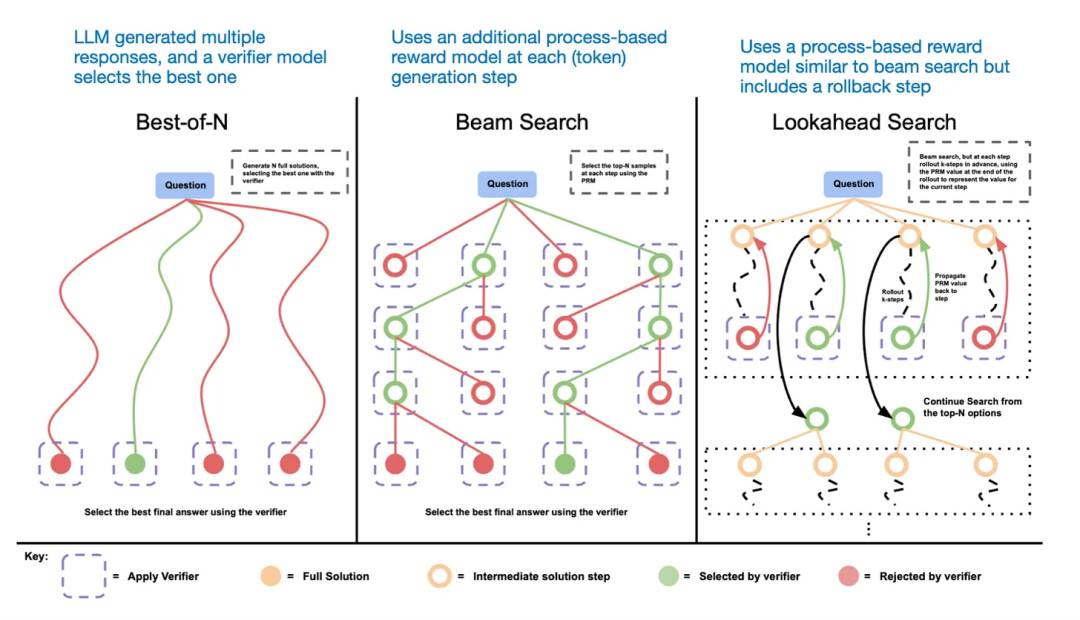
不同的基於搜索的方法依賴於基於過程獎勵的模型來選擇最佳答案。
DeepSeek R1技術報告稱其模型並未採用推理時擴展技術。然而,這項技術通常在 LLM 之上的應用層實施,所以DeepSeek有可能在其應用程序中運用了該技術。
我推測 OpenAI 的 o1 和 o3 模型採用了推理時擴展技術,這就能解釋為何與GPT - 4o這類模型相比,它們的使用成本相對較高。除了推理時擴展,o1和o3很可能是通過與DeepSeek R1類似的強化學習流程進行訓練的。
2、純強化學習 / Pure RL
DeepSeek R1論文中特別值得關注的一點,是他們發現推理能夠作為一種行為從純強化學習中湧現出來。下面我們來探討這意味著什麼。
如前文所述,DeepSeek開發了三種R1模型。第一種是DeepSeek - R1 - Zero,它構建於DeepSeek - V3基礎模型之上。與典型的強化學習流程不同,通常在強化學習之前會進行監督微調(SFT),但DeepSeek - R1 - Zero完全是通過強化學習進行訓練的,沒有初始的監督微調/SFT階段,如下圖所示。
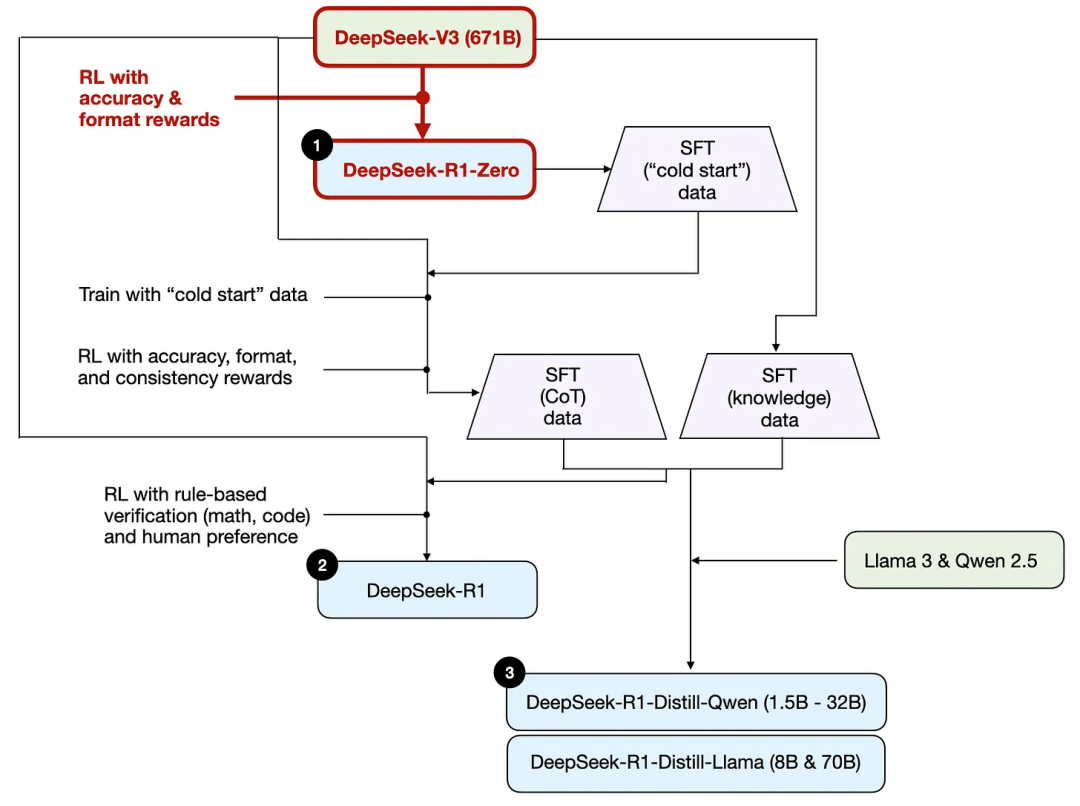
儘管如此,這種強化學習過程與常用於對LLM進行偏好微調的人類反饋強化學習(RLHF)方法類似。然而,如上文所述,DeepSeek - R1 - Zero 的關鍵區別在於,他們跳過了用於指令調整的監督微調(SFT)階段。這就是為什麼他們稱之為 “純” 強化學習 / Pure RL。
在獎勵方面,他們沒有使用基於人類偏好訓練的獎勵模型,而是採用了兩種獎勵類型:準確性獎勵和格式獎勵。
準確性獎勵 / accuracy reward 使用力扣(LeetCode)編譯器來驗證編程答案,並使用確定性系統來評估數學回答。
格式獎勵 / format reward 依賴於一個LLM評判器,以確保回答遵循預期格式,比如將推理步驟置於標籤內。
令人驚訝的是,這種方法足以讓 LLM 演化出基本的推理技能。研究人員觀察到了一個 aha moment,即模型開始在其回答中生成推理痕跡,儘管並沒有對其進行明確的相關訓練,如下圖所示,出自 R1 技術報告。

雖然R1 - Zero並非最頂尖的推理模型,但如上圖所示,它確實通過生成中間 “思考” 步驟展現出了推理能力。這證實了利用純強化學習來開發推理模型是可行的,而且DeepSeek是首個展示(或至少是發表相關成果)這種方法的團隊。
3、監督微調與強化學習(SFT + RL)
接下來看看DeepSeek的主打推理模型DeepSeek - R1的開發過程,它堪稱構建推理模型的教科書。該模型在DeepSeek - R1 - Zero的基礎上,融入了更多的監督微調(SFT)和強化學習(RL),以提升自身的推理性能。
需要注意的是,在強化學習之前加入監督微調階段,這在標準的人類反饋強化學習(RLHF)流程中實屬常見。OpenAI的o1很可能也是採用類似方法開發的。
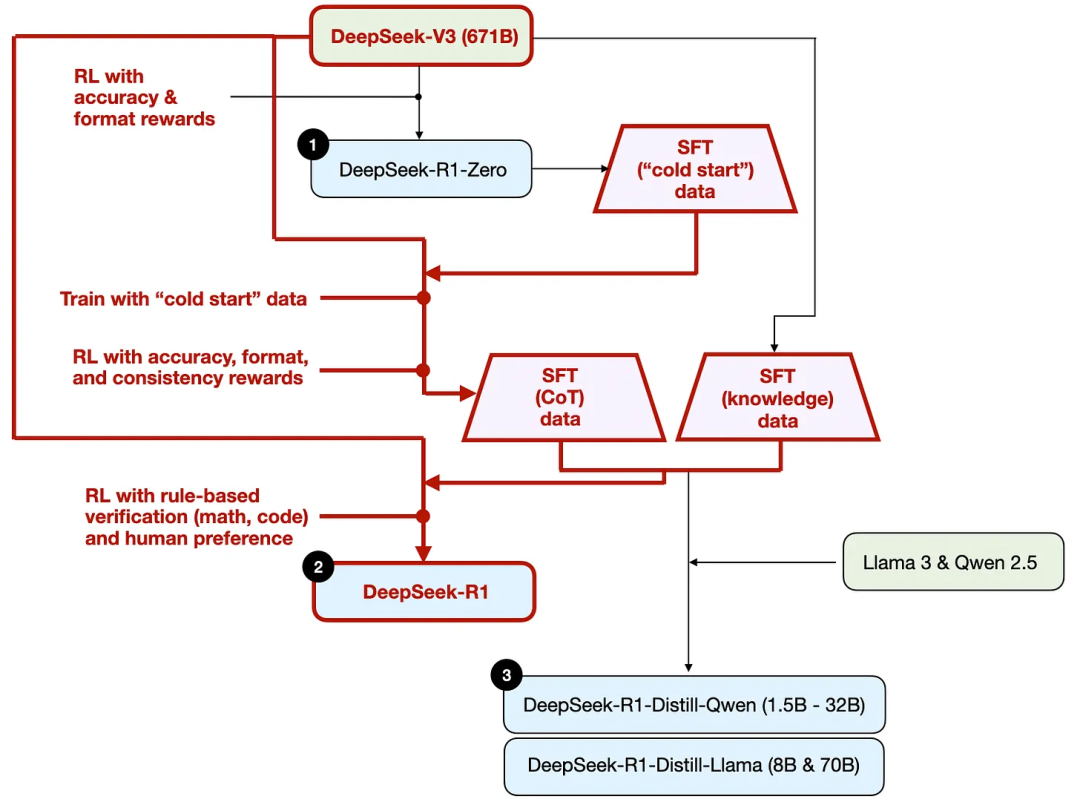
如上圖所示,DeepSeek團隊利用DeepSeek - R1 - Zero生成了他們所謂的“冷啟動”監督微調(SFT)數據。“冷啟動” 這一術語意味著,這些數據是由DeepSeek - R1 - Zero生成的,而該模型本身並未在任何監督微調數據上進行過訓練。
利用這些冷啟動SFT數據,DeepSeek首先通過指令微調來訓練模型,隨後進入另一個強化學習(RL)階段。這個RL階段沿用了DeepSeek - R1 - Zero的RL過程中所使用的準確性獎勵和格式獎勵。不過,他們新增了一致性獎勵,以防止模型在回答中出現語言混用的情況,即模型在一次回答中切換多種語言。
在RL階段之後,進入另一輪SFT數據收集。在此階段,使用最新的模型檢查點生成了60萬個思維鏈(CoT)SFT示例(600K CoT SFT exmaples),同時利用DeepSeek - V3基礎模型創建了額外20萬個基於知識的SFT示例(200K knowledge based SFT examples)。
然後,這60萬 + 20萬個SFT樣本被用於對DeepSeek - V3基礎模型進行指令微調/instruction finetuning,之後再進行最後一輪RL。在這個階段,對於數學和編程問題,他們再次使用基於規則的方法來確定準確性獎勵,而對於其他類型的問題,則使用人類偏好標籤。總而言之,這與常規的人類反饋強化學習(RLHF)非常相似,只是SFT數據中包含(更多)思維鏈示例。並且,RL除了基於人類偏好的獎勵之外,還有可驗證的獎勵。
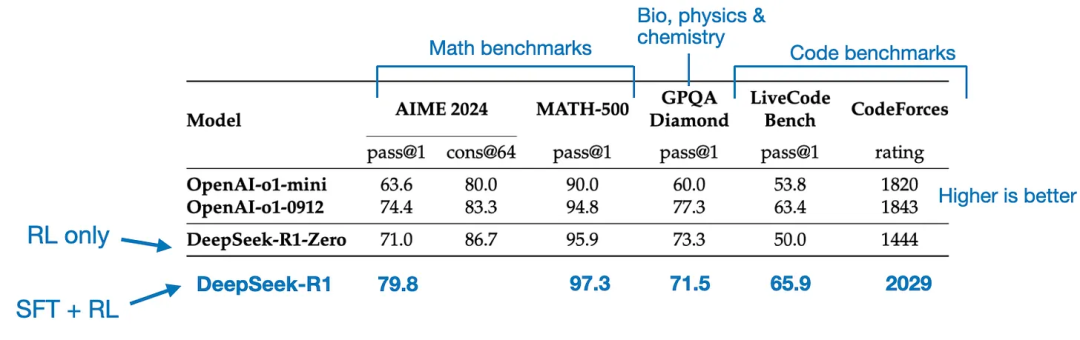
最終的模型DeepSeek - R1,由於額外的SFT和RL階段,相比DeepSeek - R1 - Zero有顯著的性能提升,如下表所示。
4、純監督微調(SFT)與蒸餾
到目前為止,我們已經介紹了構建和改進推理模型的三種關鍵方法:
1/ 推理時擴展,這是一種無需對底層模型進行訓練或以其他方式修改,就能提升推理能力的技術。
2/ Pure RL,如DeepSeek - R1 - Zero中所採用的純強化學習(RL),它表明推理可以作為一種習得行為出現,無需監督微調。
3/ 監督微調(SFT)+ 強化學習(RL),由此產生了DeepSeek的推理模型DeepSeek - R1。
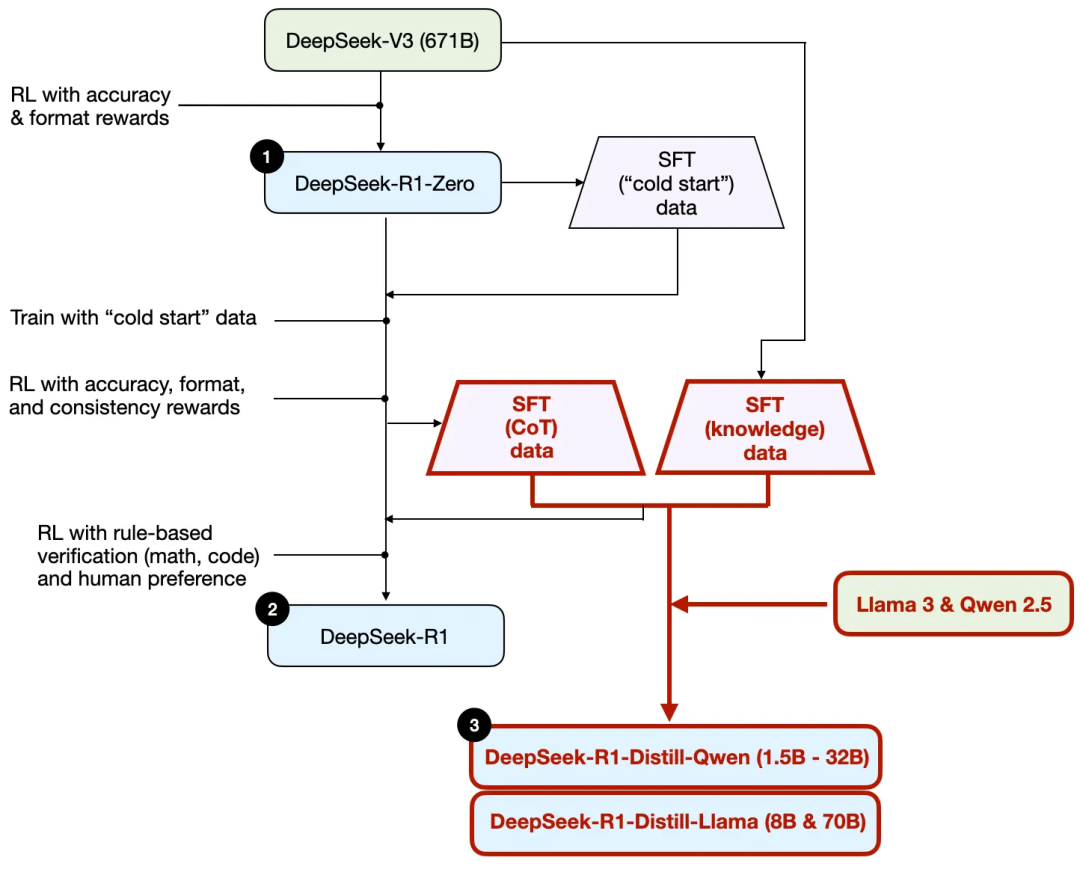
還剩下 - 模型 “蒸餾”。DeepSeek還發布了通過他們所謂的蒸餾過程訓練的較小模型。在LLM的背景下,蒸餾並不一定遵循深度學習中使用的經典知識蒸餾方法。傳統上,在知識蒸餾中,一個較小的 “學生” 模型會在較大 “教師” 模型的邏輯輸出以及目標數據集上進行訓練。
然而,這裡的蒸餾是指在由較大的LLM生成的監督微調(SFT)數據集上,對較小的LLM進行指令微調/instruction finetuning,比如Llama 8B 和70B模型,以及Qwen 2.5B(0.5B - 32B)。具體來說,這些較大的 LLM 是DeepSeek - V3和DeepSeek - R1的一箇中間檢查點 / checkpoint。事實上,用於這個蒸餾過程的監督微調數據/SFT data,與上一節中描述的用於訓練DeepSeek - R1的數據集是相同的。
為了闡明這個過程,我在下圖中突出顯示了蒸餾部分。
他們為什麼要開發這些蒸餾模型?有兩個關鍵原因:
1/ 更小的模型效率更高。這意味著它們的運行成本更低,而且還能在低端硬件上運行,對許多研究人員和愛好者來說特別有吸引力。
2/ 作為純監督微調(SFT)的案例研究。這些蒸餾模型是一個有趣的基準,展示了在沒有強化學習的情況下,純監督微調能讓模型達到何種程度。
下面的表格將這些蒸餾模型的性能與其他流行模型以及DeepSeek - R1 - Zero和DeepSeek - R1進行了對比。
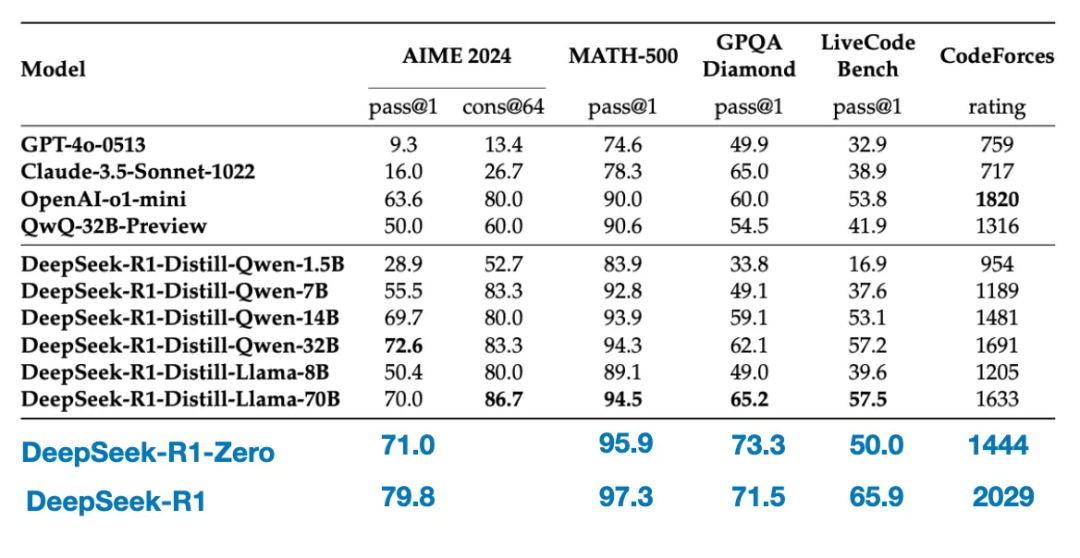
正如我們所見,儘管蒸餾模型比DeepSeek - R1小几個數量級,但它們明顯比DeepSeek - R1 - Zero要強大得多,不過相對於DeepSeek - R1還是較弱。同樣有趣的是,與o1 - mini相比,這些模型的表現也不錯(懷疑o1 - mini本身可能是o1的類似蒸餾版本)。
還有一個有趣的對比值得一提。DeepSeek團隊測試了DeepSeek - R1 - Zero中出現的突發推理行為是否也能出現在較小的模型中。為了對此進行研究,他們將DeepSeek - R1 - Zero中相同的純強化學習方法直接應用於Qwen - 32B。
下面的表格總結了該實驗的結果,其中QwQ - 32B - Preview是基於Qwen團隊開發的Qwen 2.5 32B的參考推理模型。這一對比為僅靠純強化學習是否能在比DeepSeek - R1 - Zero小得多的模型中誘導出推理能力提供了一些額外的見解。
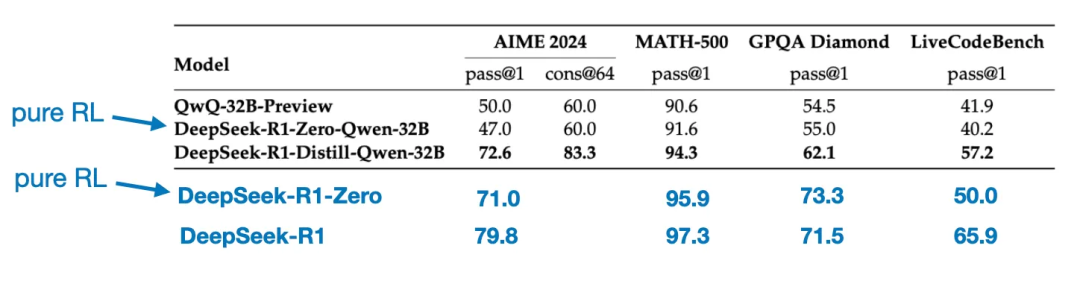
有趣的是,結果表明:對於較小的模型而言,蒸餾比純強化學習要有效得多。這與一種觀點相契合,即僅靠強化學習可能不足以在這種規模的模型中誘導出強大的推理能力,而在處理小模型時,基於高質量推理數據進行監督微調可能是一種更有效的策略。
結論
我們探討了構建和提升推理模型的四種不同策略:
推理時擴展:無需額外訓練,但會增加推理成本。隨著用戶數量或查詢量的增長,大規模部署的成本會更高。不過,對於提升已有強大模型的性能而言,這仍是一種簡單有效的方法。我強烈懷疑o1運用了推理時擴展,這也解釋了為何與DeepSeek - R1相比,o1每生成一個token的成本更高。
純強化學習 Pure RL:從研究角度來看很有趣,因為它能讓我們深入瞭解推理作為一種湧現行為的過程。然而,在實際模型開發中,強化學習與監督微調相結合(RL + SFT)是更優選擇,因為這種方式能構建出更強的推理模型。我同樣強烈懷疑o1也是通過RL + SFT進行訓練的。更確切地說,我認為o1起始於一個比DeepSeek - R1更弱、規模更小的基礎模型,但通過RL + SFT和推理時擴展來彌補差距。
如上文所述,RL + SFT是構建高性能推理模型的關鍵方法。DeepSeek - R1為我們展示了實現這一目標的出色藍本。
蒸餾:是一種頗具吸引力的方法,尤其適用於創建更小、更高效的模型。然而,其侷限性在於,蒸餾無法推動創新或產生下一代推理模型。例如,蒸餾始終依賴於現有的更強模型來生成監督微調(SFT)數據。
接下來,我期待看到的一個有趣方向是將RL + SFT(方法3)與推理時擴展(方法1)相結合。這很可能就是OpenAI的o1正在做的,只不過o1可能基於一個比DeepSeek - R1更弱的基礎模型,這也解釋了為什麼DeepSeek - R1在推理時性能出色且成本相對較低。