

沉浸式翻譯估計推上人手一個了
前幾天發現他們發了個新工具Babeldoc,支持在翻譯 PDF 的時候保持文件的原始排版
試了一下真的很猛,超長超複雜 PDF 都沒問題
主要是依然非常良心,我做了個相對詳細的測試👇:
先來點低難度的常見的論文,一般都不會有非常複雜的排版,難點主要在圖表和表格以及公式上。
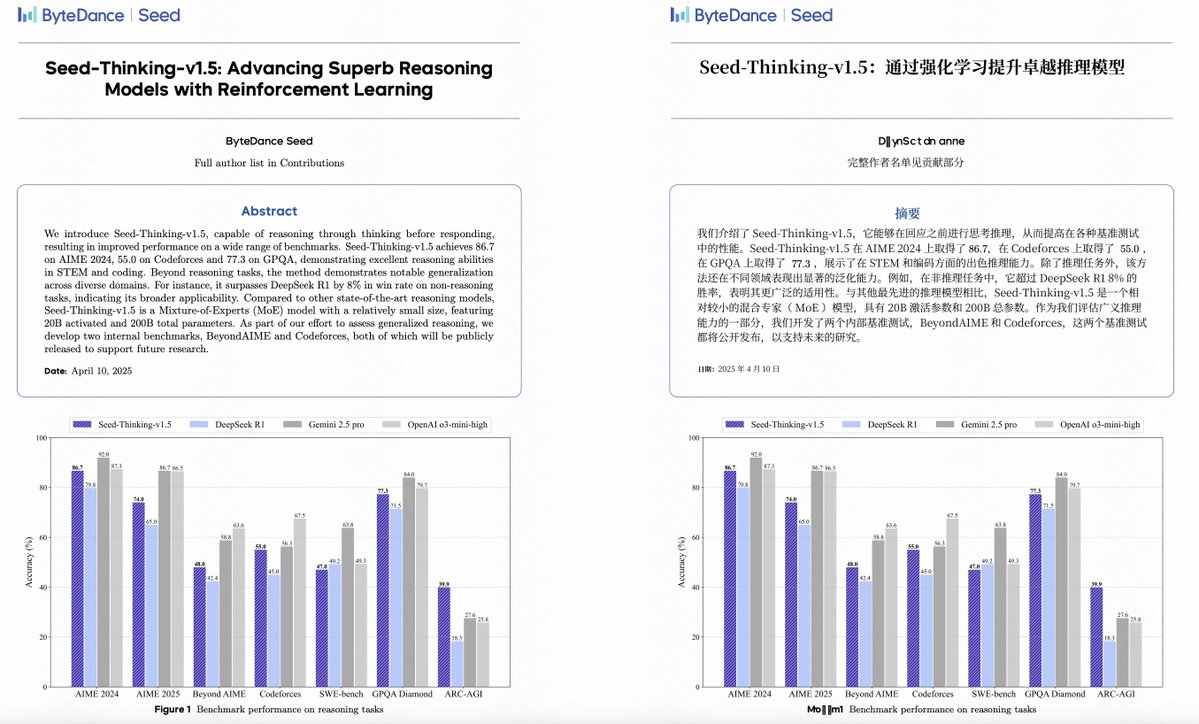
比如常見的論文開頭部分,像字節和 Meta 的論文都是這樣,從標題到摘要部分到下面的圖表都能對得上。
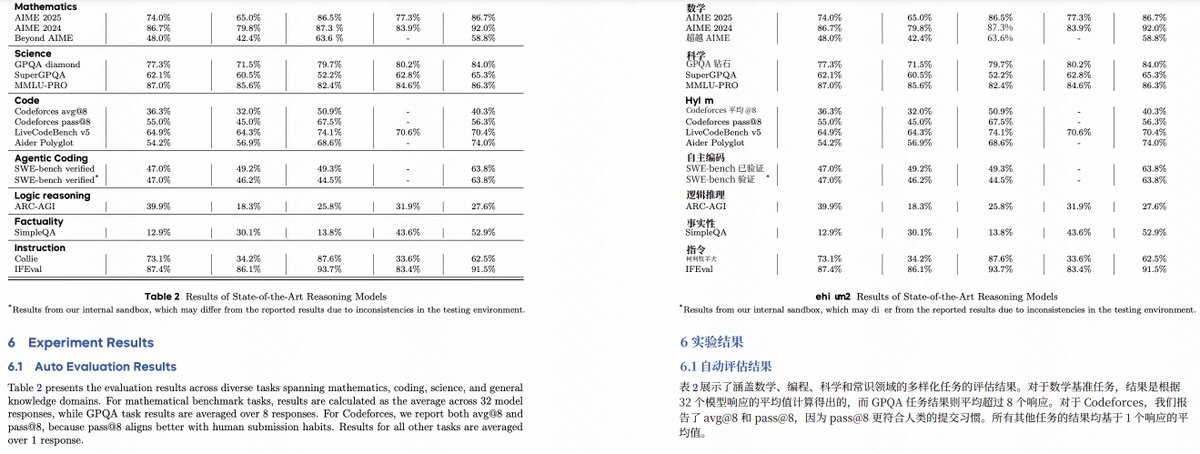
學術論文中很多數學公式、化學公式的排版非常複雜,以前如果周圍有公式,那文字的排版就不太好保持了。

然後我們來一個稍微複雜點的
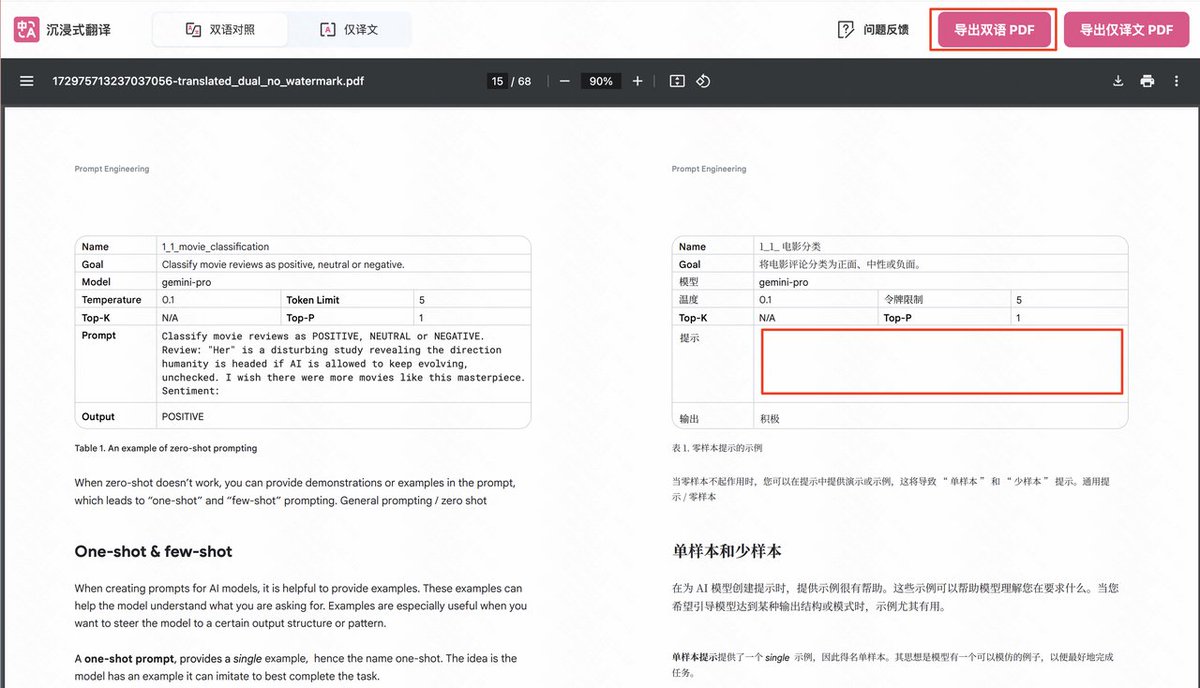
前段時間比較火的谷歌提示詞寫作教程的 PDF。
這個 PDF 明顯會專門做了一些排版,重新定義了不同的字號和間距,還有不同的字體,這種一般挺麻煩的,雖然看起來還是白底黑字。
Babeldoc 依然沒有問題,整個字號和段間距、行間距都跟原始 PDF 是一致的。

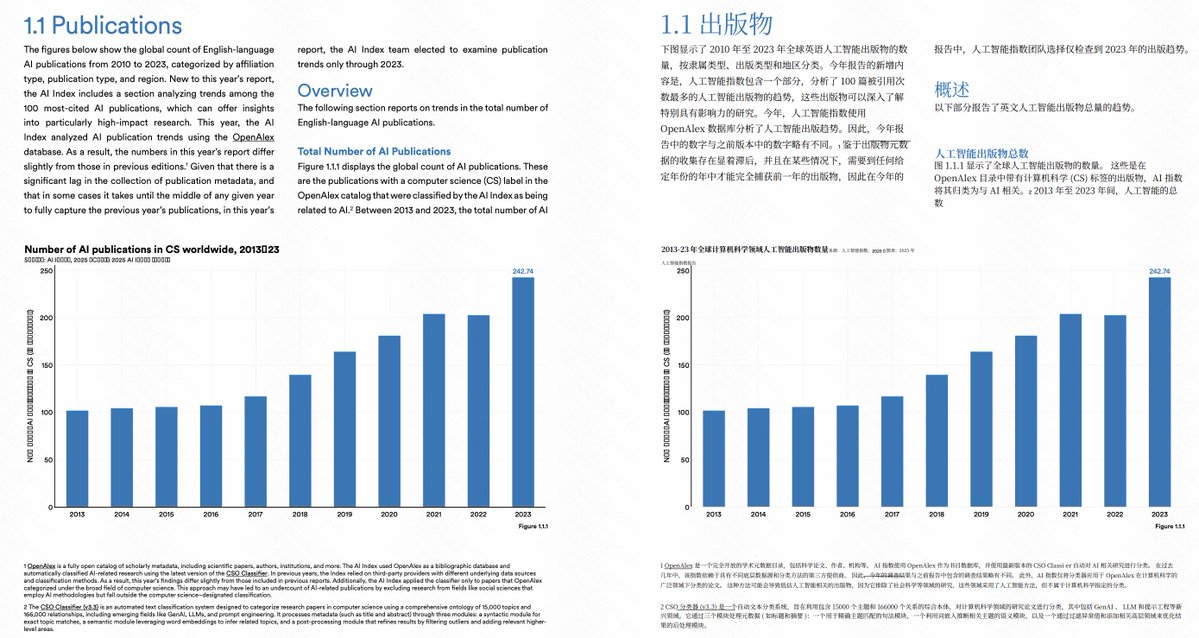
最後的終極考驗是斯坦福 HAI 的 2025 年人工智能研究報告
這個 PDF 有456 頁,而且內容極其複雜,各種圖表、圖片、標誌、角標、多列排版,疑難雜症它全佔了。
沒想到這個轉的非常完美,先看一下這一頁,分割線、下劃線加上標誌,沒啥問題,角標都給你翻譯了。


那說了這麼多如何使用呢。
如果你有安裝沉浸式翻譯的話可以點擊插件,然後點擊圖片裡的 PDF/ePub 就可以進入文檔翻譯界面,進去以後選擇 BabelDOC 就行
也可以直接訪問:app.immersivetranslate.com/bab...
BabelDOC 的套餐依然延續了沉浸式翻譯的良心操作:
免費版⽤⼾每⽉享有 1000 ⻚ 的PDF解析翻譯額度,並使⽤ GLM-4-FLASH ⼤模型進⾏翻譯,我一個月都沒這麼多文檔需要翻譯的。
Pro 會員 則享有每⽉ 10000 ⻚ 額度,並接⼊ DeepSeek ⾼級翻譯模型,帶來更強⼤的翻譯效果。
來自推特
免責聲明:以上內容僅為作者觀點,不代表Followin的任何立場,不構成與Followin相關的任何投資建議。
喜歡
收藏
評論
分享





