

來說一說, @OpenledgerHQ 近期發佈的OpenChat,其打著打著“Proof of Attribution”的旗號,號稱要讓AI生成內容的每個貢獻者都能獲得應有回報。具體如何做到呢?
1)從產品實現邏輯看,OpenChat確實在幹一件技術難度極高的事。其核心賣點是:你發的每條消息、分享的數據集、微調的模型都會被鏈上記錄,一旦被他人使用就能獲得分潤。
技術視角看,其實就歸功於它的“歸因引擎”,這是一個高保真度的∞-gram 語言模型,用後綴數組在數萬億Token中做毫秒級匹配,把你每句話都拆成Token窗口,通過BERT、Sentence-T5等向量化邏輯做嵌入處理,然後精確匹配到原始數據源。
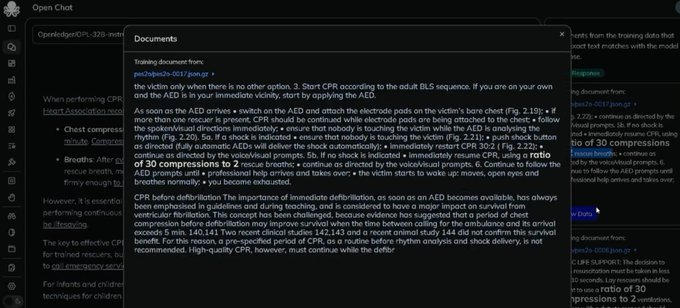
簡單理解,就是給AI內容生成裝了個“超級顯微鏡”,每個Token的“DNA”都能給你查出來。用戶界面會用下劃線標出哪些內容來自哪個數據集,連置信度分數都標得明明白白。每次聊天都會實時觸發鏈上交易,計算平臺費、數據網費用、模型費用的分配——你的數據被用了多少句話,就分多少錢。(如配圖所示)
2)剖析完產品邏輯,OpenChat的商業邏輯也就很清晰了,就是試圖重構整個AI內容生成的價值分配體系。傳統AI服務是“黑盒分錢”——你調用OpenAI接口,完全不知道背後怎麼分賬的。OpenChat要做的是讓每一次AI調用都變成“公開分賬”,數據貢獻者、模型開發者都能按貢獻獲得實時分潤。
說直白點,Openledger在構建起AI技術主權數據區塊鏈時,抽象出了三層技術架構:底層鏈上協議、中間層歸因引擎、頂層用戶應用;很顯然,OpenChat就是OpenLedger整套技術架構的一次技術驗證和試驗,通過一個聊天界面把Openledger想要傳遞的抽象的AI數據貢獻公開分賬系統給“具像化”了。
其目標就是要驗證:數據調用可以被完全透明化,每個Token的來源都能被精確追溯,價值分配可以實時自動執行。
3)不過,要做到對大規模數據的精準追蹤和鏈上記錄並非易事,尤其是“上鍊設計”的設計上,OpenLedger選擇了“實時上鍊”的重度方案,確保每次對話都能即時分潤,想想看就知道了,這對Gas費用和交易頻率的考量會非常大。
這種設計面臨的直接挑戰是性能瓶頸。如果OpenChat有幾萬用戶同時在線聊天,每秒可能產生數十萬筆歸因計算和分潤交易,這個吞吐量TPS要求遠超大部分公鏈的處理能力。即使是在相對高性能的側鏈上,要保證毫秒級的歸因匹配加上實時鏈上結算,對整個技術棧的要求都是極高。
更現實的問題是經濟可行性。每筆鏈上交易都需要Gas費,哪怕單筆費用很低,大規模使用下來成本也會成為用戶的負擔。用戶會願意為了“公平分賬”而承擔每次聊天都產生的額外費用嗎?
其實,Openledger完全可以選擇批量結算或週期性上鍊的折中方案,但既然選擇了實時上鍊和即時公平分配,只能說還在嘗試做極致主義的探索,其最終會不會調整機制還不知道,但這樣的嘗試倒是蠻有意義的。
我也做了點研究嘿嘿,簡單來說,OpenLedger 用一個 OpenChat 類似 MVP 的產品,基本上把它要做的大事講清楚了:
開放性數據平臺、歸因證明、激勵飛輪
用產品說話。。
真,其實這樣很好,比一直講要好
來自推特
免責聲明:以上內容僅為作者觀點,不代表Followin的任何立場,不構成與Followin相關的任何投資建議。
喜歡
收藏
評論
分享





