

Open AI 開源模型 gpt-oss 信息洩露! 這是一個操作系統系列模型,最小參數 20B 最大參數 120B 模型的配置文件也被洩露: MoE Transformer:36 層,128 個專家,Top-4 路由 注意力:64 個注意力頭、每頭 64 維;GQA 總參數(稀疏總量)≈ 116B 訓練/基礎上下文:initial_context_length: 4096 RoPE 長上下文擴展:可將可用上下文擴至約 4096×32 ≈ 131k tokens 滑動窗注意力:sliding_window: 128 表示主要採用 局部注意力窗口 128 KV 緩存佔用:每 token 每層 K+V 元素數 ≈ 72 KB/token。GQA 已顯著降低佔用。 總結:大規模稀疏 MoE(總參 ~116B,活躍 ~5.1B)的長上下文模型(~128k 級別,帶 NTK RoPE),採用 GQA + 滑動窗注意力 以降低內存與計算;注意力投影寬於隱藏維以增加容量。適合高吞吐與長文場景,在解碼側具有較優的 KV 開銷與並行特性。

Jimmy Apples
@acc
08-01
So before people take credit, I found the oai os a min after they uploaded and saved the config and other stuff before it was removed.
It’s an OS model and coming soon so kinda feels like ruining a surprise
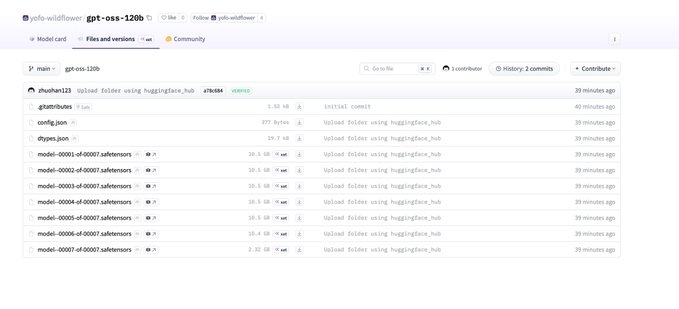
來自推特
免責聲明:以上內容僅為作者觀點,不代表Followin的任何立場,不構成與Followin相關的任何投資建議。
喜歡
收藏
評論
分享





