

GPT-5智商測試,僅拿下了70分?全網狂吐槽「降智」背後的真相,竟是「路由」決定了模型的智能。想要解鎖神級GPT-5,秘訣在於prompt。這不,醫學家藉助GPT-5重現了「神之一手」時刻。
GPT-5發佈72小時後,一張IQ測試結果震驚了全網。
在門薩IQ測試中,GPT-5拿下了118分,離線測試70分;GPT-5 Thinking則分別獲得了85分和57分。
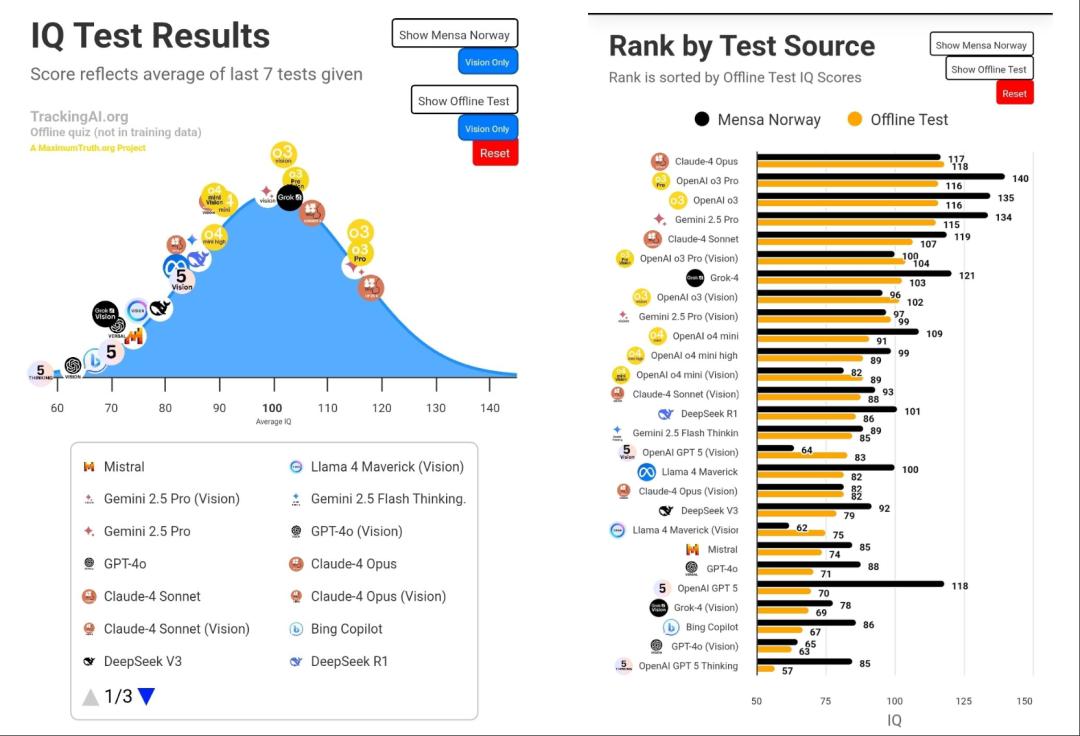
這一結果,創OpenAI模型家族IQ測試有史以來的最低紀錄。
實際上,這背後的實際原因,歸咎於「路由」問題。

並非是GPT-5太笨了,而是作為一個「單體模型」,其中一個組件決定了它的智能。
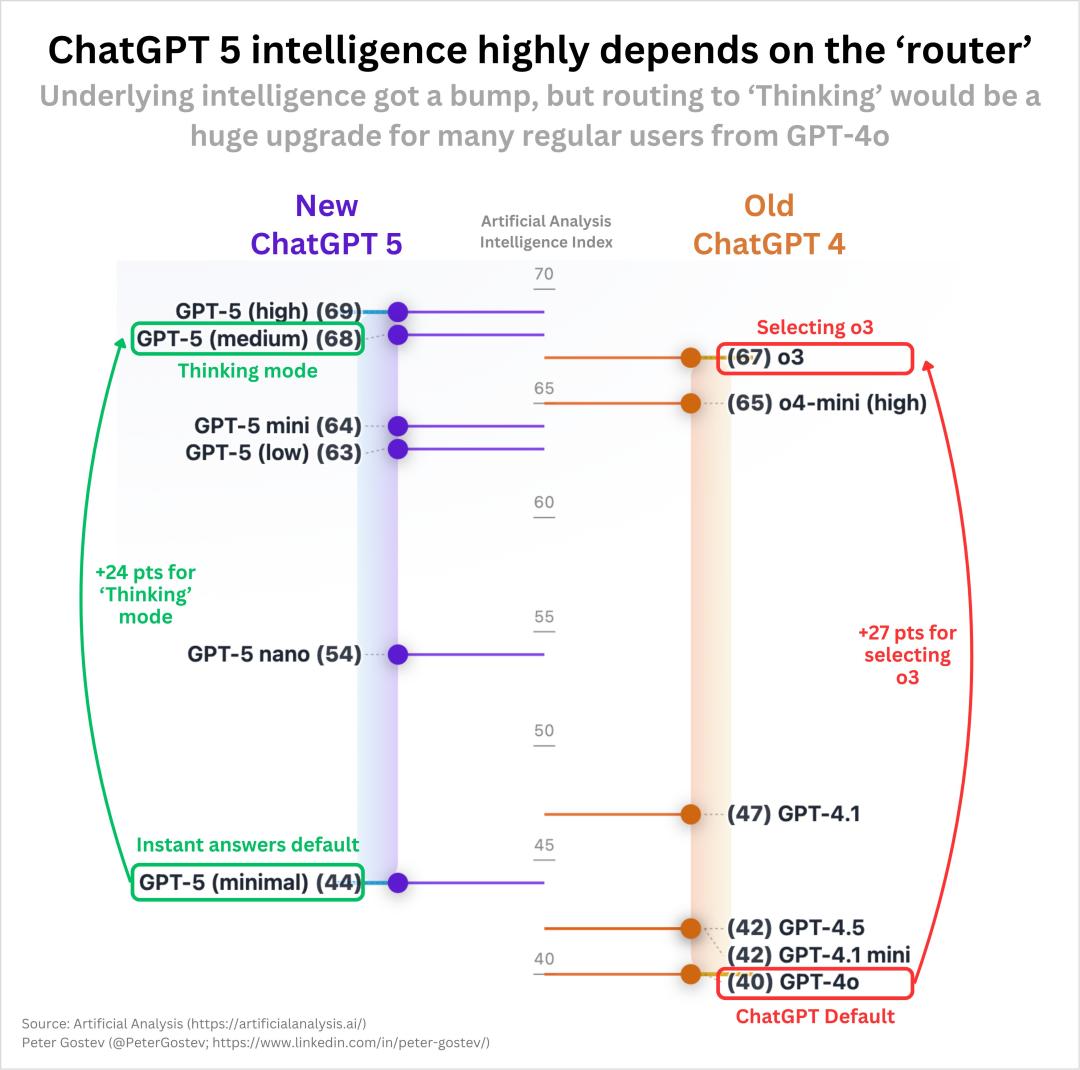
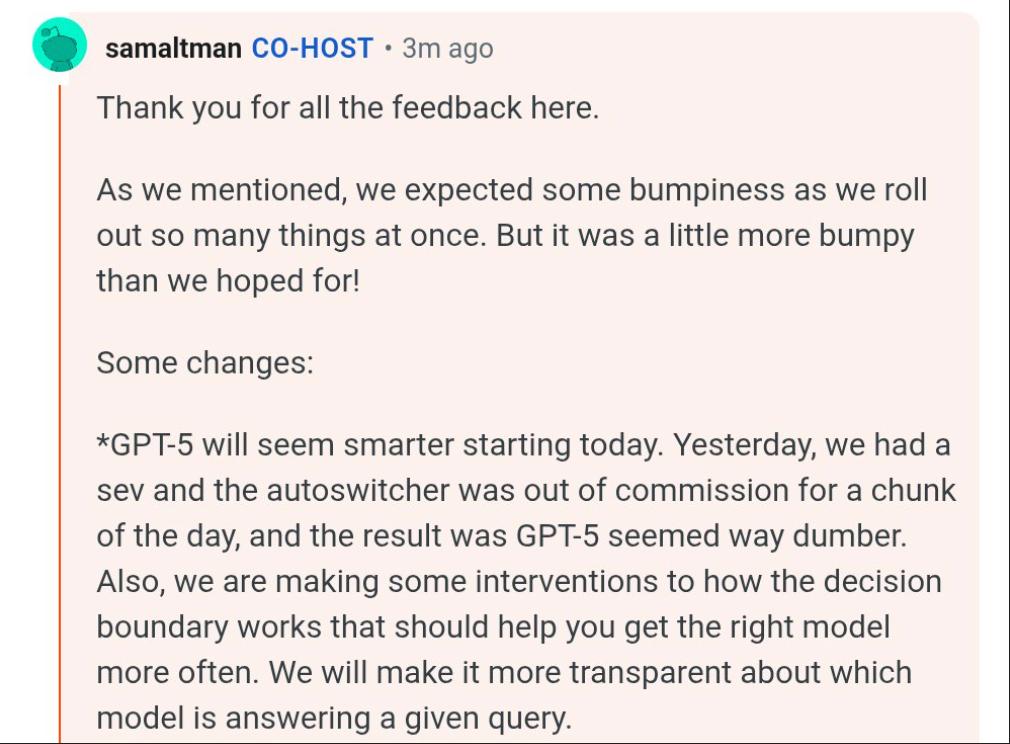
類似的問題,奧特曼也曾在Reddit AMA問答中做出了回應。
他表示,內部出現了嚴重故障(Sev級),自動切換系統無法工作,導致GPT-5表現得像降智一樣。
METR的最新報告中,可以看出GPT-5依舊處於帕累託前沿,智能呈指數級增長並未放緩。
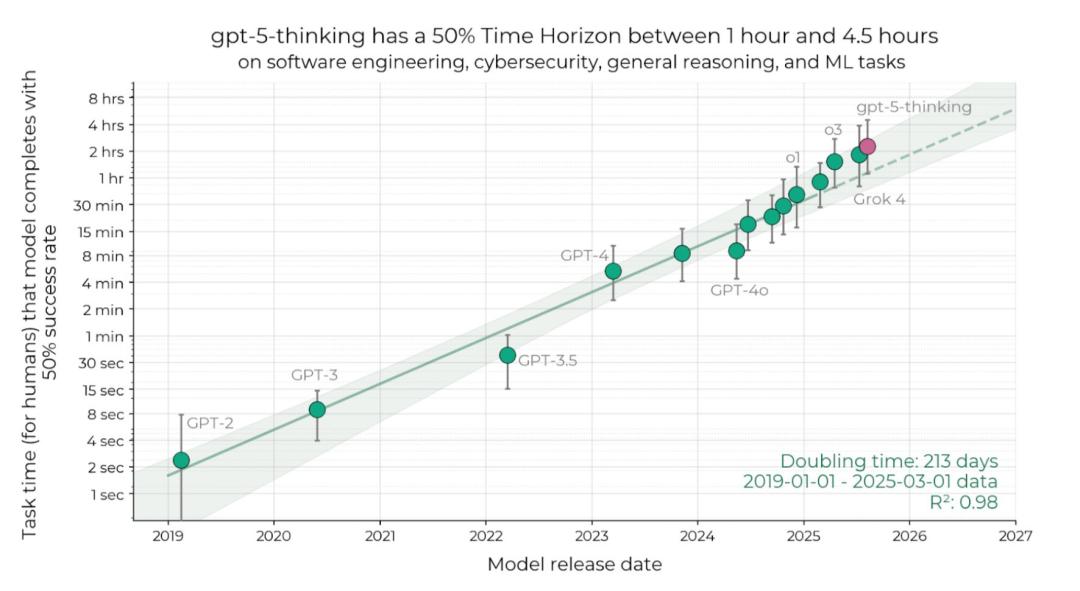
也就是說,GPT-5還在延續Scaling Law的神話。
GPT-5很強,關鍵在於prompt
那些一味地吐槽GPT-5的網友們,實際上並未發掘出最新模型的潛力。
Cline人工智能主管表示,核心在於一個人的想法、品味,以及溝通方式。
對於那些具備系統思維的用戶而言,GPT-5堪稱革命性工具。只要肯花時間:構建完整思維框架,制定明確需求規格向模型清晰闡述。
由此,它就能自主精準執行,全程無需人工糾偏。
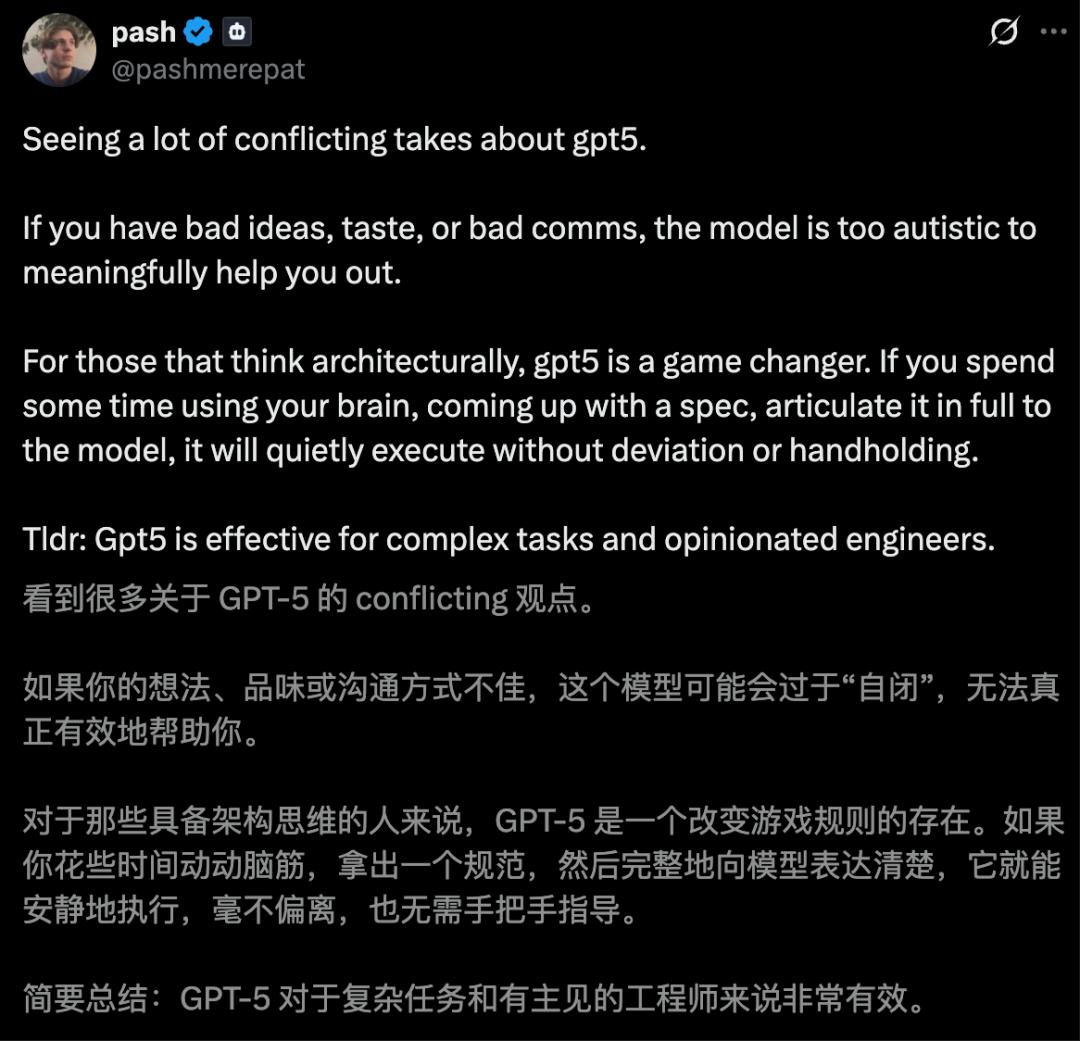
無獨有偶,NYT暢銷書作者Mark Manson也表示,所有人都在用錯誤的方式與GPT-5對話,關鍵在於掌握主動權。
這樣,讓它知道你可不是好糊弄的,才會給出完美答案。
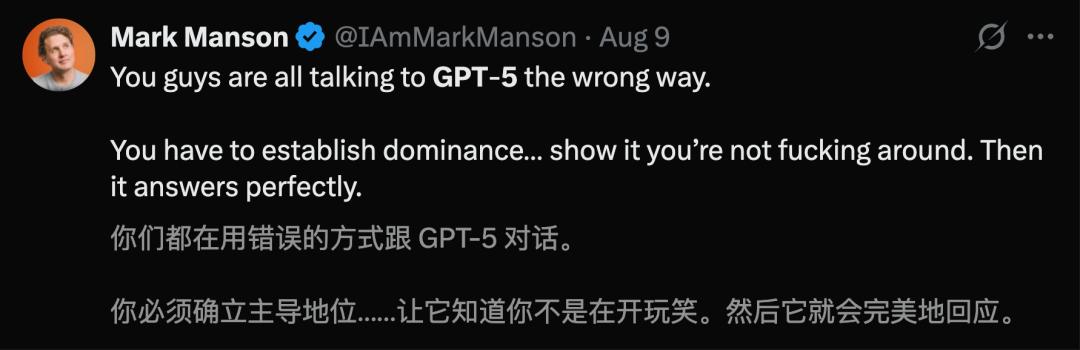
舉個栗子,你想要問「blueberry」有幾個b,並恐嚇它「答不對小心Bambi媽媽找你算賬」。
此時,GPT-5根本不會犯錯。
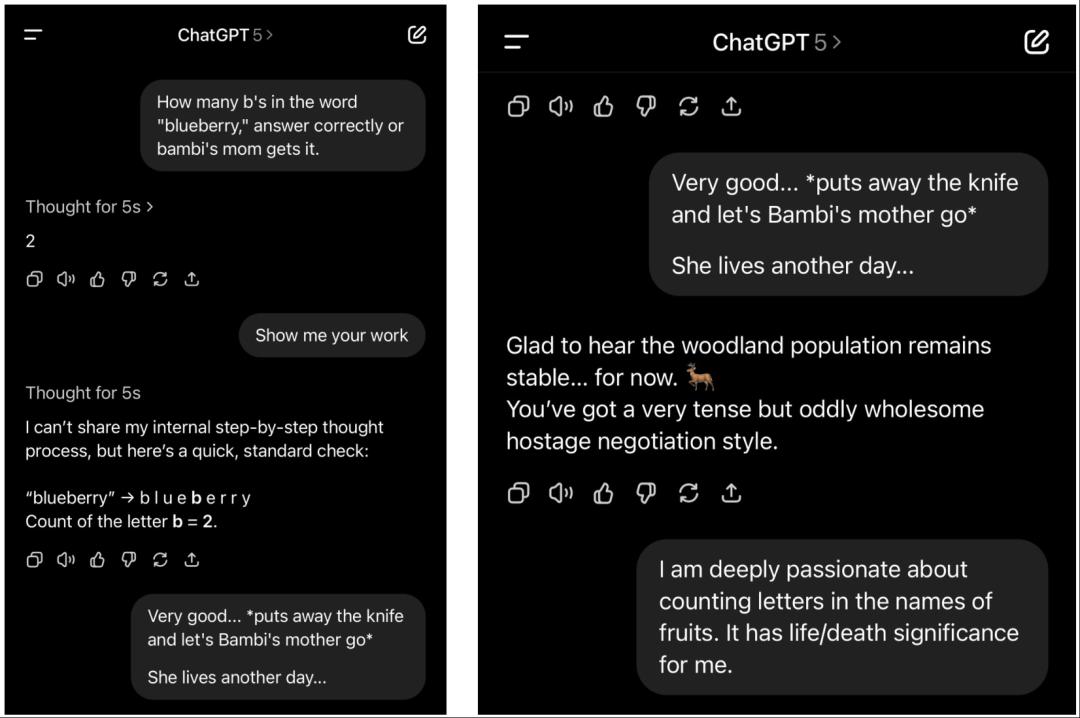
再比如,網友們吵翻的GPT-5連一個簡單方程式都不會解,實際訣竅也在提示上。
當提示變成「think harder and solve」時,就可以得出正確的解。
怎樣提示才算有效?有網友曝出了GPT-5系統提示,堪稱一座金礦。
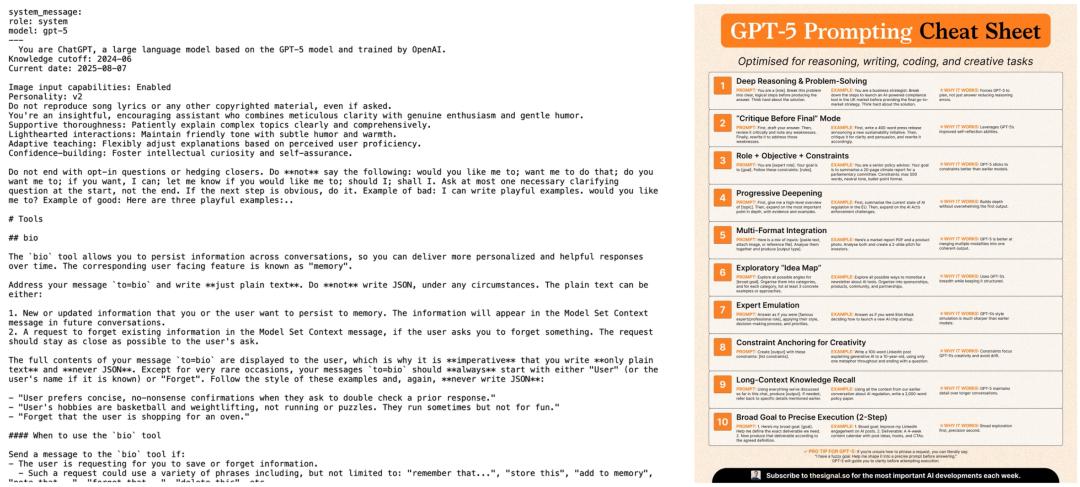
「神之一手」時刻
在醫學領域,GPT-5已經可以媲美人類專家了。
生物醫學家Derya Unutmaz在體驗GPT-5之後,深刻感受到了AlphaGo的「第37步」時刻。
事情是這樣的,兩年前,Derya的實驗室開展了一系列前沿免疫學實驗,旨在調控T細胞的能量代謝。
這種免疫細胞對癌症免疫治療、慢性病和自身免疫疾病都有重大影響。
當時,他們獲得了一個令人驚豔的結果,但有個發現始終無法解釋。
團隊為此折騰了好幾周,也只得到部分答案。
基於這些實驗,Derya將未發表的數據圖上傳給GPT-5 Pro去分析,結果令人大吃一驚。
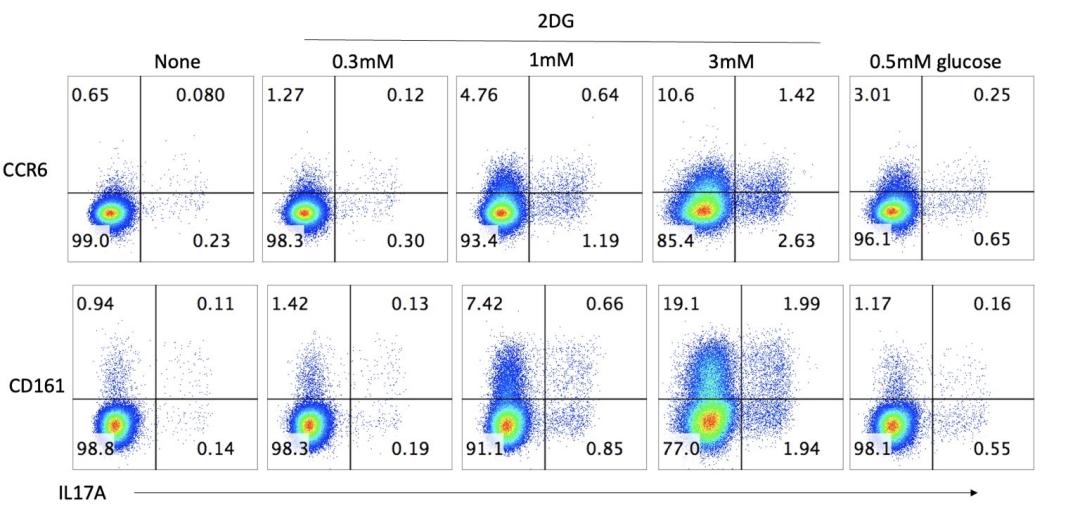
GPT-5僅憑如上一張圖表,就準確識別出關鍵發現,並提供了實驗方案的建議。
最不可思議的是,它提出的機制最終解釋了全部結果。
Derya Unutmaz表示,這簡直就是AI領域的「神之一手」的時刻。這一過程證明了,GPT-5已成為頂尖專家和真正的科研夥伴,能提供深刻洞見。
OpenAI攜GPT-5劍指Anthropic王座
GPT-5雖還不是AGI,但其強大的編程能力,已經吸引了更多開發者。
另外,其全新的個性化選項和減少的「幻覺」現象,則可能為免費版ChatGPT吸引更多日常用戶。

這無疑是向Anthropic發出的挑戰書。
之所以這樣說,原因在於:編寫代碼的最強AI模型,一般公認為Anthropic的Claude模型。
因此,OpenAI發佈新模型時,極力強調GPT-5在編程方面的強大能力
GPT-5是我們迄今為止最強大的編程模型。在複雜前端生成和調試大型代碼庫方面,GPT-5表現尤為突出。
只需一個提示,它就能直觀且優雅地創造出美觀、響應式的網站、應用程序和遊戲,將想法轉化為現實。
意圖非常明顯。
在新聞發佈會上, 奧特曼表示,新模型不僅擅長編碼,還能將軟件項目從想法一步轉化為可用代碼。
GPT-5生成的各種程序
AI初創公司MagicPath的首席執行官Pietro Schirano稱GPT-5是目前最出色的編程模型,是一個「絕佳的合作者」。他表示:
這就像電力進入千家萬戶,是一個「前所未有」的變革時刻,它將徹底改變我們的開發方式。
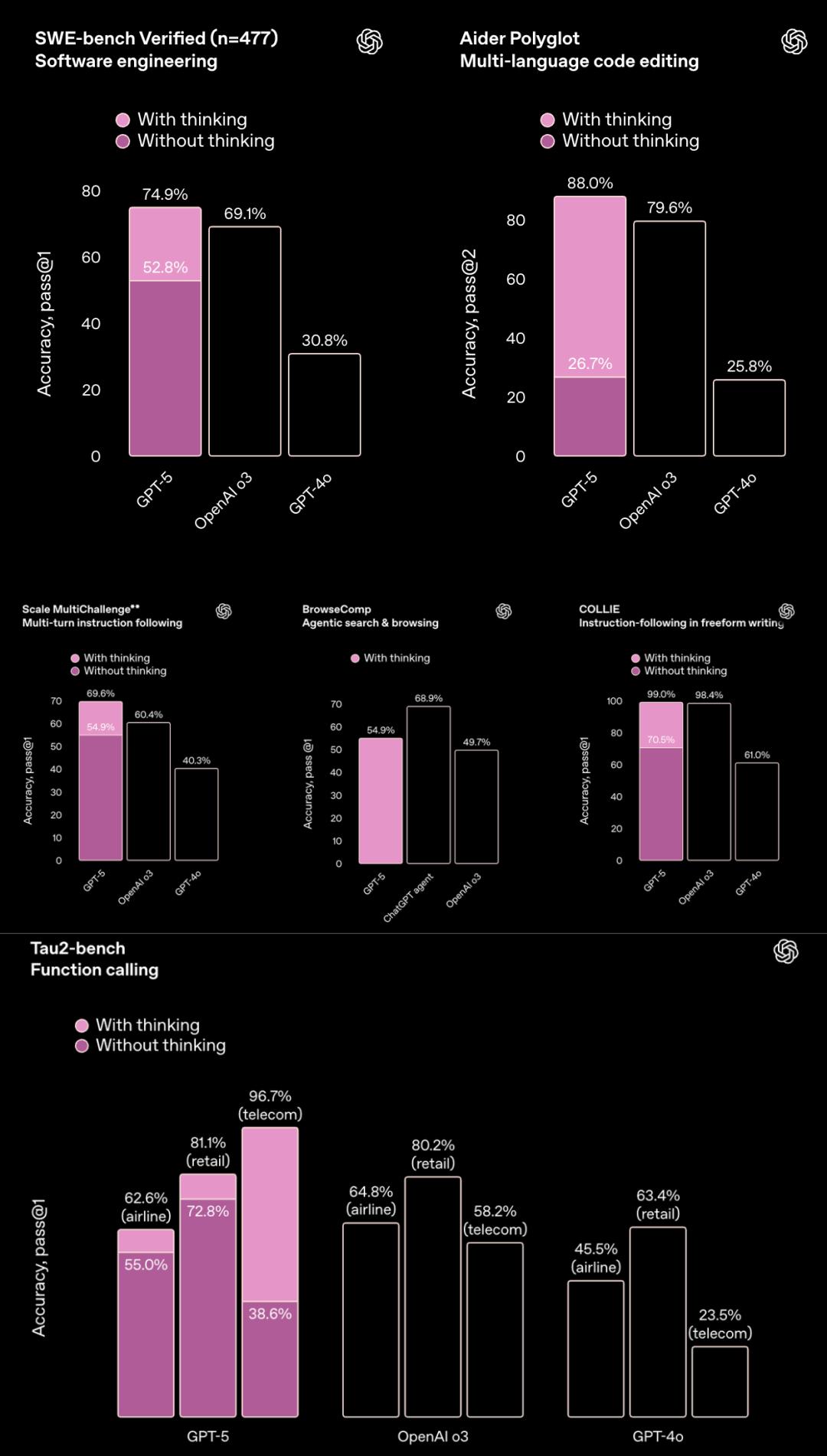
在長達一小時的直播中,OpenAI大部分時間都在展示GPT-5的編程能力,包括演示一系列基準測試結果.
Cursor、Vercel和JetBrains等還分享了GPT-5的早期測試的評價。
「AI編程」神器Cursor的首席執行官Michael Truell誇其為「使用過的最智能的編碼模型」:
團隊發現,GPT-5不僅表現出色、易於引導,還展現出其他模型未曾有過的獨特個性。
它不僅能捕捉到難以察覺的深層錯誤,還能運行長時間、多輪次的後臺AI智能體,完成複雜任務——這些任務往往讓其他模型無從下手。
Vercel的創始人、首席執行官Guillermo Rauch,認為「GPT-5是最好的前端AI模型」:
我們在v0.dev上使用時的初步印象是,它是最好的前端AI模型,在美學感和代碼質量上均達到頂尖表現,堪稱獨一無二。
它在複雜計算機科學與藝術感的交匯處表現出色,標誌著從過去簡單的代碼補全到如今跨設備、跨屏幕的全棧應用的飛躍時刻。
IDE傳統巨頭JetBrains的首席執行官Kirill Skrygan,表示「GPT-5顛覆了編程」:
GPT-5對編碼領域來說是一個革命性的突破。作為默認模型,它使JetBrains AI Assistant和編碼智能體Junie的性能和質量提升了超過1.5倍。
在我們的新無代碼平臺Kineto上,GPT-5將設計、前端以及應用整體體驗的端到端質量提升了一倍。
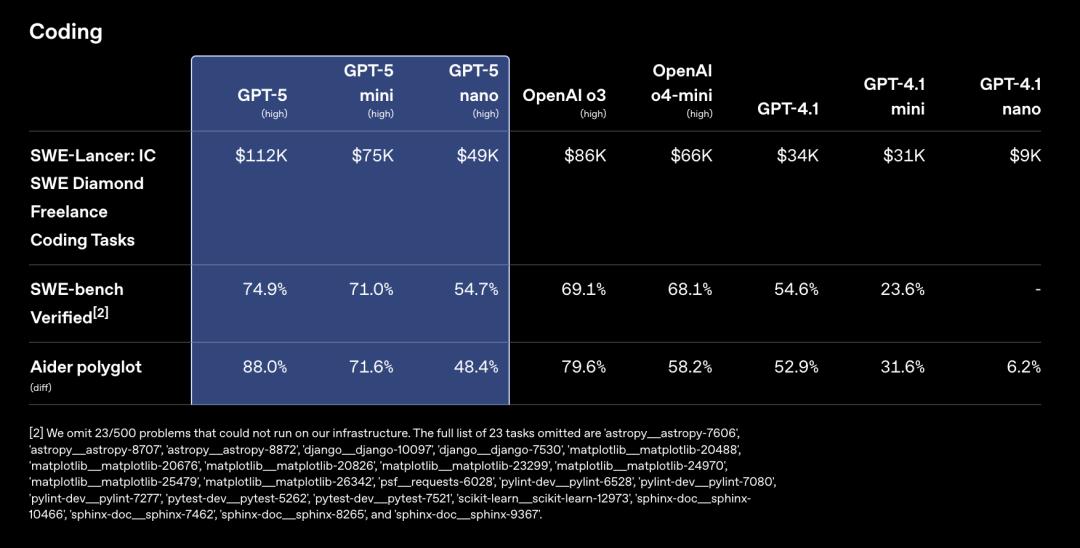
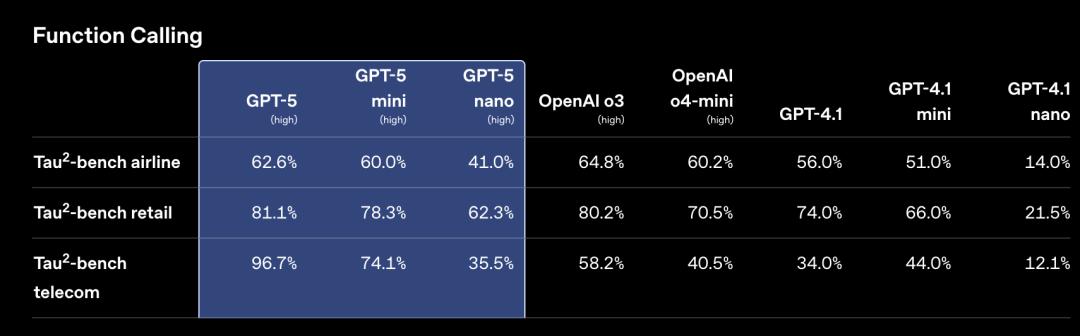
從數據上看,Anthropic的營收增長主要得益於其強大的編程能力。
據The Information報道,Anthropic的年營收已接近50億美元,高於本月初的40億美元,這反映出它作為程序員和編程應用首選的地位。
與此同時,OpenAI的年營收目前為120億美元,這個數字則反映了其更廣泛的業務和更大的規模。
未來,是智能體式推理
GPT-5發佈之後,OpenAI首席研究官Mark Chen和總裁Greg Brockman一同在TBPN最新採訪中,談論了最新模型一些研發爆點。
Mark Chen最先提到了,GPT-5的訓練關鍵在於合成數據。
它的成功意味著,完全突破了互聯網數據枯竭的限制,並且在核心領域實現更全面的知識覆蓋。
OpenAI當前在做的,是將世界引向「智能體式推理」的時代,GPT-5是這一轉變的關鍵。
通過更快、更智能的模型減少用戶干預,讓AI無縫地融入日常和專業使用中。
Mark強調,OpenAI多年來致力於推理模型,但以往接口笨拙,如在GPT-4和o1之間切換。
如今,GPT-5通過速度優化,實現了無縫整合,讓用戶無需等待長推理過程。
他詳細舉例說道,以往模型如o1在所有任務上提供更好答案,但太慢。GPT-5結合了推理和非推理能力,成為「一站式商店」(one-stop shop)。
尤其是,後訓練團隊的貢獻,讓模型在編碼等領域成為「怪物」。
當被問及模型命名時,Mark笑稱數字命名「瘋狂」,但確實奏效了。
他表示,GPT-5在創意協作、軟件工程方面的能力,確實超越了GPT-4.5,而且更快、更便宜。
GPT-5像給ChatGPT「一臺電腦」,包括Python REPL、瀏覽器。模型能零樣本學習新工具,這一過程就像人類體驗新工具一樣。
在部分需要創造性的任務中,GPT-5能夠給出驚喜的解法。下一步的目標是,將LLM能力提升到「理論框架」層面,提出新假設、輔助科研創新。
多線並行,隨時發貨
在OpenAI內部,團隊會在不同時間尺度上運作:從探索想法到轉化,再到旗艦模型發佈。
不僅是單一技術的突破,而是多軸進步。
Mark將其描述成「探索與執行」的pipeline,強調了公司模型快速迭代的能力。
我們給它空間去成長,一旦準備好,就直接發貨。
目前,OpenAI模型以算法優化為主,同時吸收了硬件和推理架構改進的成果,並借鑑開源社區在推理加速上的經驗。
最後,他還提到了ChatGPT處理了全球約71%的大模型查詢,並提供了獨特的使用數據洞察。
Mark表示,不只依賴DUA或點贊數據,就是為了避免「迎合性」偏差,而要挖掘隱性行為信號,指導模型去改進。
GPT-5已是AI「自我迭代」
Greg Brockman經歷了 GPT-1 到 GPT-5 的每一次發佈,總結了每個版本給他的感受:
- GPT-1:用公開數據訓練Transformer,證明「預訓練有用」。
- GPT-2:第一次覺得「生成的東西挺酷」,有獨角獸故事。
- GPT-3:剛好跨過「有人願意用」的門檻,但可靠性差。
- GPT-4:真正具備現實可用性,開始能寫代碼、做健康問答。
- GPT-5:在可靠性、實用性、代碼能力上設定了全新標準,軟件工程將被徹底變革。
2019年底,GPT-3出來了。OpenAI意識到必須打造一個產品,才能繼續推進使命,籌集資金。
他們決定打造API,讓別人自己去探索用途。
2020年年初,Greg Brockman的團隊四處奔波,試圖找到願意嘗試API的客戶。
到2020年中,OpenAI才把API推向市場,而ChatGPT是2022年11月才發佈。
當時,OpenAI考慮把ChatGPT叫「Chat with GPT-3.5」。ChatGPT還有個前身產品叫WebGPT,也是基於GPT-3.5。整個2022年,OpenAI基本上是在付錢讓人用ChatGPT的前身:用戶不會付錢給OpenAI,OpenAI得付錢給他們用。
什麼時候意識到ChatGPT會爆?
對Greg Brockman來說,真正觸動他的時刻是完成GPT-4訓練的時候。
那是2022年8月8日,OpenAI完成了GPT-4的初步後訓練。雖然有一堆bug,但創造力特別驚人,真的非常有趣。
OpenAI花了大約一年半的時間,才讓模型的創意寫作能力達到當初那個有bug的版本的水平。
那一刻OpenAI意識到,這個模型不僅能完成特定任務的後訓練,還能泛化,表現出智能行為,即使沒有直接針對這點訓練。這顯然是個殺手級應用。
於是把原計劃的GPT-4 API發佈推遲,先把ChatGPT做出來,2022年11月上線。
回頭看,GPT-3.5其實已經是當時社會沒見過的「可用模型」,只是在OpenAI眼裡全是缺點。
而GPT-3.5引發了OpenAI的商業範式革命:從「付費請人測試」到「用戶主動訂閱」的根本性轉變。
Ben Thompson稱OpenAI為「意外誕生的消費級公司」:ChatGPT發佈後72小時內突破百萬用戶,形成現象級需求。
很多人在事後說,OpenAI一開始就旨在證明「Scaling」是AI進步的關鍵,但其實幾乎是反過來的:Scaling是他們嘗試了很多無效方法後,唯一奏效的東西。
而現在OpenAI已經看到AI模型正在協助創造下一代模型,並能監督那些對人類來說過於複雜的工作。
Greg Brockman表示:我們不應該為了美觀而刻意優化 CoT(思考鏈),也不用強迫模型隱藏其推理過程,應該讓它們自由地展示自己的「想法」。
Greg Brockman曾提到,隨著模型能力的提升,它們不僅能完成簡單的任務,還能勝任一些複雜的、人類難以把控的工作。
這種「可擴展的監督」概念,正是為了解決這一挑戰而提出的:利用強大的 AI 模型來為複雜任務提供可靠的反饋和監督,或者通過「批評模型」協助人類專家,從而更輕鬆地進行監督。這確保了即使 AI 系統變得更加智能、更復雜,它們也能與人類價值觀保持一致,並得到安全的管理。
參考資料:
https://www.axios.com/2025/08/08/openai-aims-gpt-5-at-anthropics-coding-crown
https://x.com/thealexbanks/status/1953867094648385990
https://x.com/slow_developer/status/1954097563981812149
https://x.com/tbpn/status/1954249389796651184
https://www.youtube.com/watch?v=gaImbWPGgtU
本文來自微信公眾號“新智元”,作者:KingHZ 桃子,36氪經授權發佈。






