

OpenAI的AGI之路,總裁Greg Brockman在最新的訪談中說清楚了——
技術層面,從文本生成轉向強化學習的推理範式,在現實世界中試錯並獲取反饋;
資源策略上,持續投入大規模計算資源;
落地環節,把模型封裝成Agent,將模型能力打包成為可審計的服務進程。

這場訪談由AI播客Latent Space主持,與Brockman探討了OpenAI的AGI的整體技術路線與資源策略。
與此同時,OpenAI的落地佈局,以及Brockman對未來的思考,也都隨著訪談的進行浮出水面。
總結下來,Brockman表達了這些核心觀點:
模型正在不斷增強現實交互能力,這也是下一代AGI的關鍵組成部分;
AGI的主要瓶頸在於計算,計算量的多少直接決定了AI研究和發展的速度與深度;
AGI真正的目標是讓大模型在企業和個人的工作流里長駐,手段就是Agent;
把模型接進現實世界的應用領域極具價值,各個領域還有大量尚未採摘的果實。
模型推理範式的轉變
談及OpenAI剛剛發佈的GPT-5,Brockman認為這是AI領域的一場重大範式轉變,作為OpenAI第一個混合模型,旨在彌補GPT系列與AGI的距離。

在訓練GPT-4之後,OpenAI給自己提出了一個問題:
為什麼它不是AGI?
GPT-4雖然可以進行連貫的上下文對話,但可靠性欠佳,會犯錯甚至脫離軌道。
因此他們意識到需要在現實世界中測試想法,並通過強化學習獲取反饋,從而提高可靠性。
這一點在OpenAI早期的Dota項目中就有所實現,當時使用了純強化學習,可以從隨機初始化狀態中學習複雜行為。
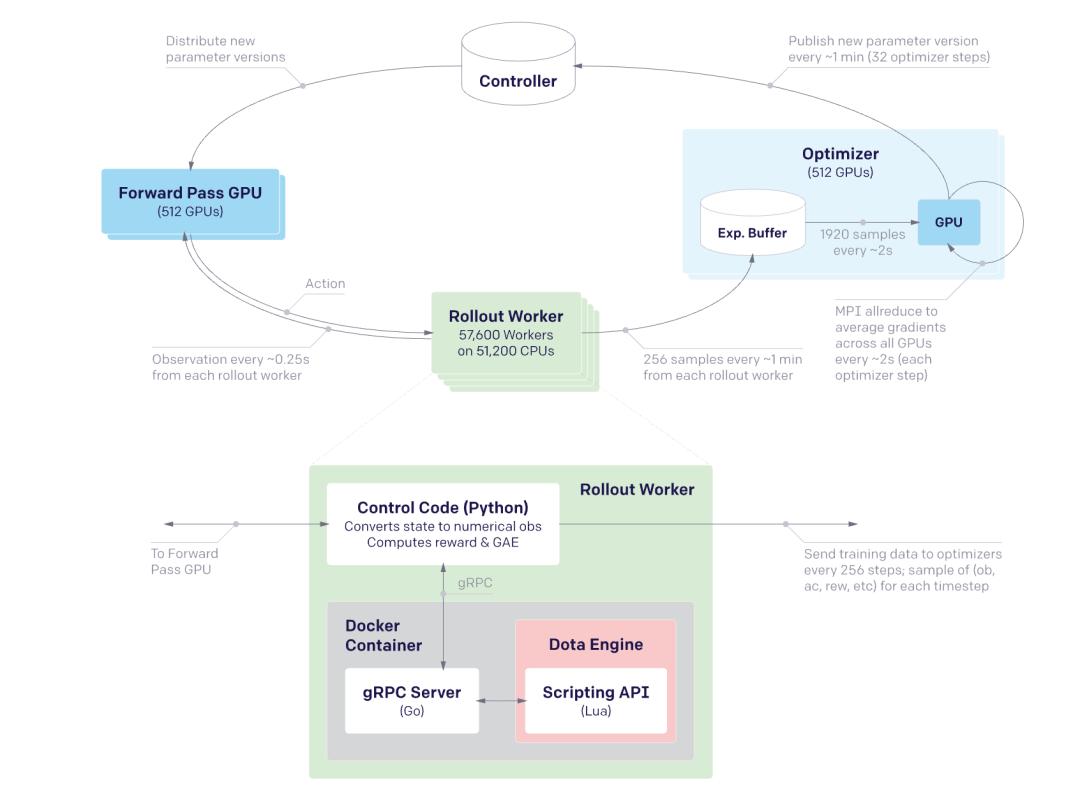
△
所以從GPT-4完成的那一刻起,OpenAI開始嘗試轉向新的推理範式,即先讓模型通過監督數據學會對話,再借助強化學習反覆在環境中試錯。
傳統的模型訓練是一次性訓練,然後進行大量推理,而GPT-5則藉助強化學習,讓模型在推理過程不斷生成數據,然後基於這些數據重複訓練,將模型與現實世界的觀測結果反饋到模型中。
這種新範式改變了所需數據的規模,原先預訓練可能需要數十萬個示例,但強化學習只需要從10到100個任務中學習複雜行為。
同時也說明模型正在不斷增強現實交互能力,這也是下一代AGI的關鍵組成部分。
計算能力決定AGI開發上限
當被問及當前AGI開發中的主要瓶頸時,Brockman明確表示:計算。
他認為,只要擁有更多的計算能力,OpenAI就總能找到迭代和提高模型性能的方法,計算量的多少直接決定了AI研究和發展的速度與深度。
例如同樣是在Dota項目中,當時普遍認為PPO (近端策略優化)算法無法實現擴展,但他們通過將內核數量翻倍,實現了性能的持續提升,所以其實所謂的算法壁壘在擴大計算資源後就能得以解決。

而當前GPT-5的強化學習範式雖然帶來了更高的樣本效率,但仍然需要模型進行數萬次嘗試才能重複學會一項任務,這需要巨大的計算量支撐。
更進一步,圖靈曾為AGI提出的“超臨界學習”概念,認為機器不僅要學習被即時教授的內容,還要深入思考其二階、三階甚至四階效應,並更新整個知識體系。
這種更深層次學習過程則同樣需要投入更多的計算資源,OpenAI當前的目標就是探索如何以更具創造性的方式消耗計算,以實現這種高級學習能力。
Brockman將計算描述為一種基本燃料,可以將能量轉化為存儲在模型權重中的勢能,推動模型執行有效操作。
一旦模型通過大量計算訓練完成,就可以被反覆利用,在多任務中分攤巨大的計算成本。
另外,他也預測最終的AGI將會是一個模型管理器,將小型的本地模型與大型雲推理器結合,以實現自適應計算。

GPT-5的多模型混合和路由機制就是這種方式的一個初步嘗試,將推理模型和非推理模型結合,並通過條件語句選擇合適的模型。
推理模型更適用於深度智能但有充足思考時間的場景,非推理模型則用於快速輸出回合。
這種複合式的模型充分利用了計算的靈活性,能夠根據任務需求組合不同能力和成本的模型,也是AGI最可能呈現的面貌。
因此在AI驅動的未來經濟中,計算將成為需求極高的資源,擁有更多計算資源的研究人員可以產出更優質的成果,如何獲取計算資源及計算的分配方式將成為一個非常重要的問題。
讓大模型進入生產
Brockman反覆強調,模型不再是科研樣品,而是要成為現實生產線的一環。
他指出,AGI真正的目標是讓大模型在企業和個人的工作流里長駐,而不是停留在論文與演示當中。

具體的落地路徑就是把模型封裝成Agent,將模型能力打包成為可審計的服務進程。
Brockman認為,這種交互像與資深同事協作,一個關鍵要素在於可控性——可以“隨時停下讓你檢查”,而且任何一步都能回滾。
為了保證高權限Agent可控,OpenAI設計了雙層結構的“縱深防禦”:
模型內部,把system、developer、user三種指令排出可信度順序,使“忽略此前所有指令”這類注入在第一關就被丟棄;
模型外部,把每個潛在高危操作拆成最小粒度,通過多級沙箱逐一確認。
對於這種模式,Brockman用數據庫安全進行了類比:
就像防SQL注入,必須先在最低層把洞堵死,再往上疊加護欄,系統自然穩固。
安全護欄之外,與人類之間的價值對齊也是一項重要工程。
工程團隊先通過後訓練從海量潛在“人格”中去除普遍不受歡迎的類型。
隨後,剩餘的“人格”被放入公開競技場接受實時評分,評價高的策略在下一輪被放大,評價低的被削弱,從而形成模型與社會偏好的協同進化。
這一流程將保證模型能力升級時不脫離人類共識,也為未來引入在線學習打下數據基礎。

另外,為了增強生態黏性,OpenAI還把輕量級開源列為第二驅動力。
Brockman的判斷是,當開發者在這些模型上沉澱工具鏈,實際上就默認採納了OpenAI的技術棧。
“各個領域還有大量尚未採摘的果實”
放眼未來,Brockman認為真正值得投入的機會不在於再造一個更炫的“模型包裝器”,而是把現有智能深植於具體行業的真實流程之中。
對很多人來說,似乎好點子都被做完了,但他提醒,每一條行業鏈都大得驚人。
把模型接進現實世界的應用領域極具價值,各個領域還有大量尚未採摘的果實。
因此,他建議那些“覺得起步太晚”的開發者與創業者,先沉到行業一線,理解利益相關者、法規和現有系統的細節,再用AI去填補真正的缺口,而不是隻做一次性的接口封裝。

當被問到如果要給2045年的自己留一張便籤會寫什麼時,他的願景是“多星際生活”與“真正的豐裕社會”。
在他看來,以當前技術加速度推演,二十年後幾乎所有科幻情節都難以否定其可行性,唯一的硬約束只剩下物質搬運本身的物理極限。
與此同時,他也提醒,計算資源會成為稀缺資產;即便物質需求被自動化滿足,人們仍會為了更高分辨率、更長思考時間或更復雜的個性化體驗而渴求更多算力。

如果能穿越回18歲,他想告訴年輕的自己,值得攻克的問題只會越來越多,而不會減少。
我曾以為自己錯過了硅谷的黃金年代,但事實完全相反——現在正是技術發展的最好時機。
在AI將滲透一切行業的背景下,機遇不僅未被耗盡,反而隨技術曲線的陡升而倍增.
真正的挑戰是保持好奇心,敢於投入新的領域。
參考鏈接:[1]https://www.youtube.com/watch?v=35ZWesLrv5A
本文來自微信公眾號“量子位”,作者:關注前沿科技,36氪經授權發佈。





