

瞭解區塊鏈系統中鍵值查找的實際磁盤 I/O 成本
在實際區塊鏈狀態工作負載下對 Pebble 進行實證研究
抽象的
許多區塊鏈分析和性能模型都假設鍵值(KV)存儲讀取操作的磁盤 I/O 複雜度為O(log N) (例如TrieDB 、 QMDB ),尤其是在使用 Pebble 或 RocksDB 等 LSM 樹引擎時。這一假設源於 SST 遍歷的最壞情況,即查找操作需要訪問多個層級,並且在每個層級都要檢查布隆過濾器、索引塊和數據塊。
然而,我們發現這種模型並不能反映真實世界的行為。實際上,緩存通常會保存大部分的過濾塊和索引塊,這可以顯著減少 I/O 操作。
為了解基於 LSM 的數據庫在實際緩存條件下的磁盤 I/O 行為,我們使用 Pebble 作為代表性引擎進行了大量的受控實驗,數據集大小從22 GB 到 2.2 TB ( 2 億到 200 億個鍵),結果表明:
- 一旦布隆過濾器(不包括LLast )和Top-Index都加載到緩存中,大多數否定查找將不會產生磁盤 I/O ,並且每次 Get 操作的 I/O 次數會迅速下降到 ~2。
(讀取 1 個索引塊和 1 個數據塊)。 - 當所有索引塊都能放入緩存時,每次 Get 操作的 I/O 次數將進一步收斂到~1.0–1.3 ,並且很大程度上與數據庫總大小無關。
- 在純隨機讀取工作負載下,數據塊緩存對整體 I/O 的影響微乎其微。
總體而言,當緩存足以容納布隆過濾器(不包括 LLast)和 Top-Index 時,情況就是如此。
在類似區塊鏈的工作負載下,Pebble 的磁盤 I/O 性能僅佔數據庫總大小的約 0.1%–0.2% ,對於隨機讀取操作,其磁盤 I/O 性能表現出有效的 O(1) 特性,這挑戰了常見的磁盤 I/O 性能。
假設每次鍵值查找都必然消耗O(log N)次物理 I/O。這會對區塊鏈 trie 數據庫和執行層存儲系統的性能建模和設計產生直接影響。
動機
區塊鏈執行層通常依賴於 LSM 樹鍵值存儲來處理數十億個隨機訪問的密鑰。一個常見的假設是:
“LSM 樹中每次 KV 查找的成本為
O(log N)磁盤 I/O。”
然而,在實際的區塊鏈系統中,這些假設往往並不成立。現代基於 LSM 的鍵值引擎(例如 Pebble)嚴重依賴於:
- 布隆過濾器可以消除大部分否定查找;
- 小型、高度可重複使用的索引結構;
- 塊緩存和操作系統頁面緩存將頻繁訪問的元數據保存在內存中。
因此,KV 查找的實際物理 I/O 行為通常受限於一個很小的常數(≈1-2 次 I/O),並且一旦布隆過濾器和索引塊能夠放入緩存,它就很大程度上與數據庫總大小無關。
這些觀察結果引出了一個重要的實際問題:
在實際的區塊鏈場景中,隨機鍵值查找的實際磁盤 I/O 成本是多少?
本研究旨在通過直接的實證測量來回答這個問題,以便:
- 驗證或質疑常見的
O(log N)KV 查找假設, - 量化實現近乎恆定的讀取 I/O 實際需要多少緩存,
- 為區塊鏈執行層持久鍵值存儲後端(包括狀態存儲和快照鍵值存儲)提供經驗緩存大小建議。
我們如何驗證假設
本節描述了我們如何驗證我們的假設:在實際緩存條件下,Pebble 的實際讀取 I/O 成本主要取決於元數據的緩存駐留時間,而非如最壞情況 O(log N) 模型所預測的那樣取決於 LSM 樹的深度。我們首先分析 Pebble 的讀取路徑,以確定具體的 I/O 來源;然後引入兩個由緩存驅動的拐點,用於表徵讀取行為中 I/O 成本的變化;最後,我們概述了用於實證觀察這些階段並量化其對每次 Get 操作 I/O 次數影響的實驗設置。
瞭解卵石
Pebble 讀取路徑和 I/O 源
Pebble 中的Get操作按以下步驟進行:
1. Lookup MemTable / Immutable MemTables and return value if found ( in memory) 2. Lookup MANIFEST to find candidate SST files ( in memory) 3. For each SST:a) Load Top - level index at reader initialization (used to locate internal index blocks after filter check )b) Table - level Bloom filter check ( except LLast) → skip SST if key absentc) Internal index block lookup → locate data blockd) Data block lookup → read value and return上述讀取路徑引用了本文中出現的幾個內部組件。為了清晰起見,我們在此簡要介紹一下這些組件。
頂級指數(簡稱頂級指數)
每個 SST 的極小頂級索引指向內部索引塊。
幾乎每次查找都會用到它,而且通常會完全緩存。
內部索引塊(簡稱索引塊)
每個 SST 中的索引塊將鍵範圍映射到數據塊。
在成功通過篩選檢查後即可訪問它們,如果未進行緩存,則可能會產生一次磁盤 I/O。
最後
LSM樹的最深層。它存儲了大部分數據,並且在查找過程中不使用布隆過濾器。
因此,到達 LLast 的查找遵循完整路徑:頂級索引 → 索引塊 → 數據塊。
為什麼篩選條件會排除 LLast
為 LLast 設置布隆過濾器會非常龐大,緩存成本高昂,而且在實踐中收益有限,因為大多數正例查找最終都會探測 LLast。因此,Pebble不會使用布隆過濾器來查找 LLast。
兩個實際緩存拐點
從上述讀取路徑可以看出, Get操作會反覆查詢一組定義明確的小型元數據組件。這些組件是否駐留在緩存中直接決定了讀取路徑的哪些部分會產生物理 I/O。基於此觀察以及每個元數據類的緩存佔用總量,我們定義了兩個緩存大小閾值(稱為緩存拐點),它們將作為後續章節分析讀取 I/O 行為的基礎。
拐點 1 — Filter + Top-Index
緩存可以容納:
- 所有布隆過濾器(非LLast)
- 所有 Top-Index 塊
→ 否定查找幾乎總是在內存中解決。
拐點 2 — Filter + All-Index
緩存可以容納:
- 所有布隆過濾器(非LLast)
- 所有級別的所有索引塊
→ 正向查找避免索引未命中,並接近最小 I/O。
組件定義
- 過濾器:所有非 LLast級別的 Bloom 過濾器
- 頂級索引:所有頂級 SST 索引塊
- 所有索引:頂層索引 + 所有內部索引塊
緩存驅動的讀取 I/O 行為的三個階段
根據上面定義的兩個緩存拐點,我們將緩存大小劃分為三個階段,並描述每個階段的預期讀取 I/O 行為。
第一階段——
Cache Size < Inflection Point 1
過濾器和頂部索引未命中頻繁 → 許多不必要的 SST 檢查 →更高的預期讀取 I/O 成本。第二階段——
Inflection Point 1 < Cache Size < Inflection Point 2
過濾器和 Top-Index 被緩存 → 否定查找主要在內存中解決 → 隨著索引塊開始駐留在緩存中,讀取 I/O預計會減少。第三階段——
Cache Size > Inflection Point 2
過濾器和所有索引塊都被緩存 → 剩餘的 I/O預計主要來自數據塊→ 超過這一點收益遞減。
實驗裝置
本節描述了用於評估 Pebble 在類似區塊鏈工作負載下實際隨機讀取 I/O 性能的實驗方法。它總結了實驗環境、數據集、工作負載以及用於測量緩存駐留時間和每次 Get 操作 I/O 次數的指標,重點關注穩態隨機讀取性能。
硬件和軟件
- CPU:32個核心
- 內存:128 GB
- 磁盤:7 TB NVMe RAID0
- 操作系統:Ubuntu
- 存儲引擎:Pebble v1.1.5
注意:所有實驗均在 Pebble v1.1.5 上進行。Pebble v2+ 的讀取路徑行為、過濾器佈局或緩存行為可能有所不同,應單獨評估。
所有基準測試代碼、Pebble 儀器數據和原始實驗日誌均已公開。
可在bench_kvdb上查看,以便進行復現。
數據集
| 數據集 | 小的 | 中等的 | 大的 |
|---|---|---|---|
| 鑰匙 | 2億把鑰匙 | 2B 鑰匙 | 20B 鑰匙 |
| 數據庫大小 | 22 GB | 224 GB | 2.2 TB |
| 文件數量 | 1418 | 7105 | 34647 |
| 篩選器 + 頂部索引 | 32 MB (0.14%) | 284 MB (0.12%) | 2.52 GB (0.11%) |
| 篩選(包括 LLast) | 238 MB | 2.3 GB | 23 GB |
| 所有索引 | 176 MB | 1.7 GB | 18 GB |
| 篩選器 + 全索引 | 207 MB (0.91%) | 2.0 GB (0.89%) | 20.5 GB (0.91%) |
密鑰:32 字節哈希值
值:110 字節(大約是 geth trie 節點的平均 RLP 大小)
工作量
- 純隨機讀取
- 每次測試 1000 萬次獲取操作
- 熱身:0.05% 的鍵空間
- 不進行範圍掃描
- 沒有併發的大量寫入或壓縮操作
筆記。
所有實驗都側重於單個節點上的穩態純隨機讀取工作負載,沒有併發的大量寫入、壓縮壓力或範圍掃描。
指標
我們依靠 Pebble 的內部統計數據來描述閱讀行為,包括:
- 布隆過濾器命中率
- 頂級指數命中率
- 索引塊命中率
- 數據塊命中率
- 總體塊緩存命中率
- 每次獲取操作的 I/O 次數——最終目標指標
在 Pebble 中, Get操作期間的所有塊讀取(過濾器、Top-Index、索引和數據塊)
所有請求都通過塊緩存進行路由。每次查找都會首先查詢緩存,如果塊緩存未命中,通常只會導致一次底層物理讀取,且預讀和壓縮的干擾極小。
其中BlockCacheMiss是所有塊類型中塊緩存未命中的總數。
(布隆過濾器、Top-Index 塊、索引塊和數據塊), GetCount是已完成的Get操作的數量。
因此, BlockCacheMiss能夠緊密跟蹤實際的物理讀取壓力,並提供穩定、與實現一致的每次查找 I/O 成本度量。
結果
我們首先分析緩存大小如何影響布隆過濾器、Top-Index 塊和索引塊的命中率。然後,我們展示這些影響如何轉化為整體塊緩存命中率,並最終轉化為每次 Get 操作的 I/O次數指標。
在本節中,拐點 1 (IP1)指的是保存所有非 LLast Bloom 過濾器和 Top-Index 塊所需的緩存大小(在我們的基準數據集中約為數據庫大小的 0.11%–0.14% ),而拐點 2 (IP2)指的是保存所有非 LLast Bloom 過濾器和所有索引塊所需的緩存大小(在我們的基準數據集中約為數據庫大小的 0.9% )。
布隆過濾器和頂級索引命中率
| 緩存大小 | 小數據集 (篩選命中率) | 中等數據集 (篩選命中率) | 大型數據集 (篩選命中率) | 小數據集 (頂級指數命中率) | 中等數據集 (頂級指數命中率) | 大型數據集 (頂級指數命中率) |
|---|---|---|---|---|---|---|
| 在 IP1 | 98.5% | 99.6% | 98.9% | 96.4% | 97.8% | 95.4% |
| 超出 IP1(≈0.2% DB) | 100% | 100% | 100% | 100% | 100% | 100% |
一旦緩存超過拐點 1 ,布隆過濾器和頂級索引的命中率都接近 100%,並且否定查找在內存中得到解決。
索引塊命中率
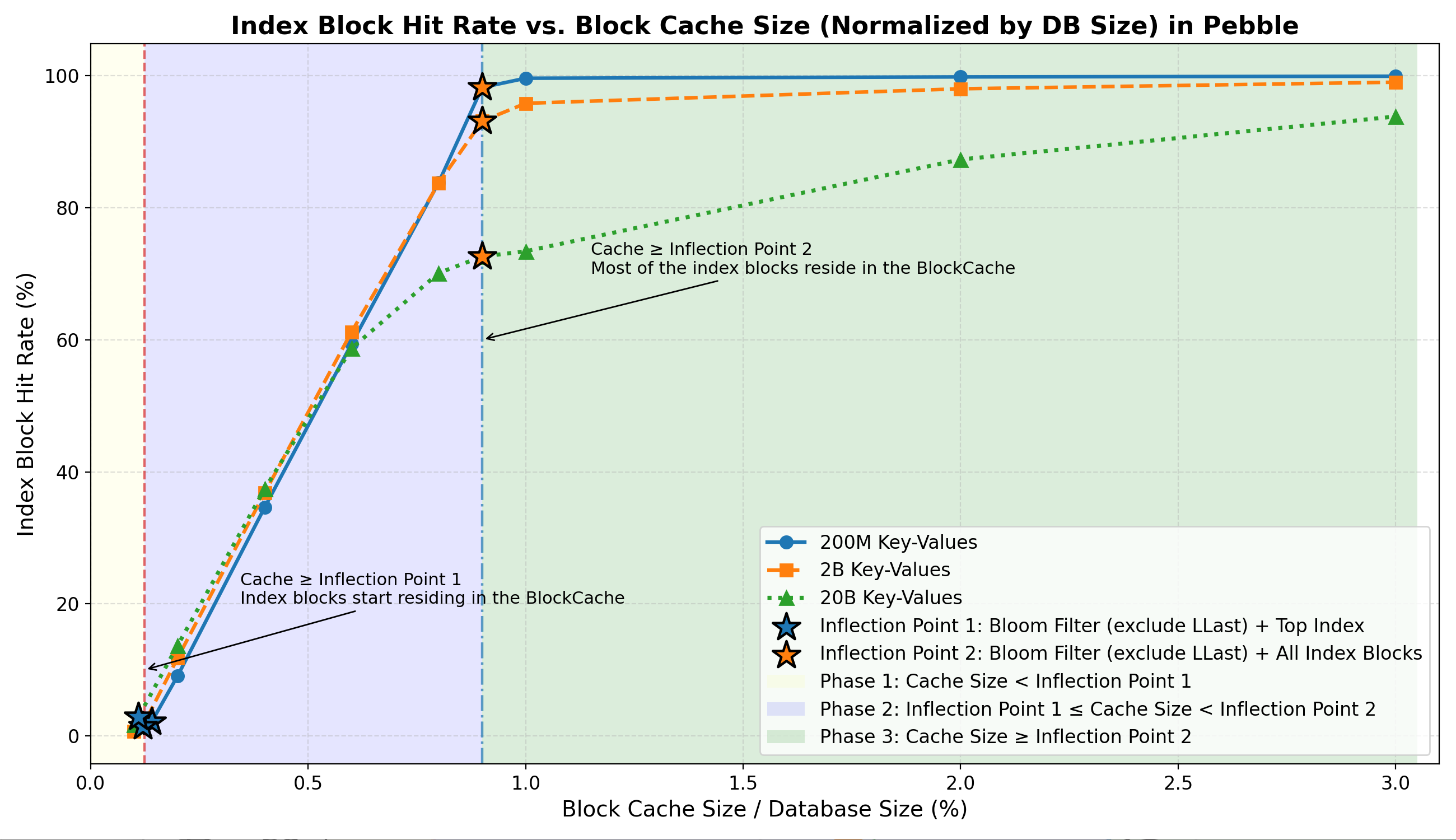
- 第一階段:緩存的索引塊非常少(可能約 1%–3% )。
- 第二階段:隨著緩存接近拐點 2,索引命中率急劇上升至約 70-99%。
- 第三階段:大部分索引塊駐留在內存中,命中率達到一個較高的平臺期(~70%–99%),之後只有很小的提升空間。
數據塊命中率
| 緩存大小 | 小數據集 (數據塊命中率) | 中等數據集 (數據塊命中率) | 大型數據集 (數據塊命中率) |
|---|---|---|---|
| 在 IP1 | 1.0% | 0.7% | 1.3% |
| 超出 IP1(≈0.2% DB) | 1.2% | 0.9% | 1.6% |
| 在 IP2 | 1.4% | 1.1% | 2.4% |
| 超出 IP2(≈3% DB) | 3.2% | 3.0% | 4.3% |
在所有三個階段中,數據塊命中率始終很低,數據塊緩存對隨機讀取工作負載中觀察到的 I/O 減少貢獻甚微。
總體塊緩存命中率
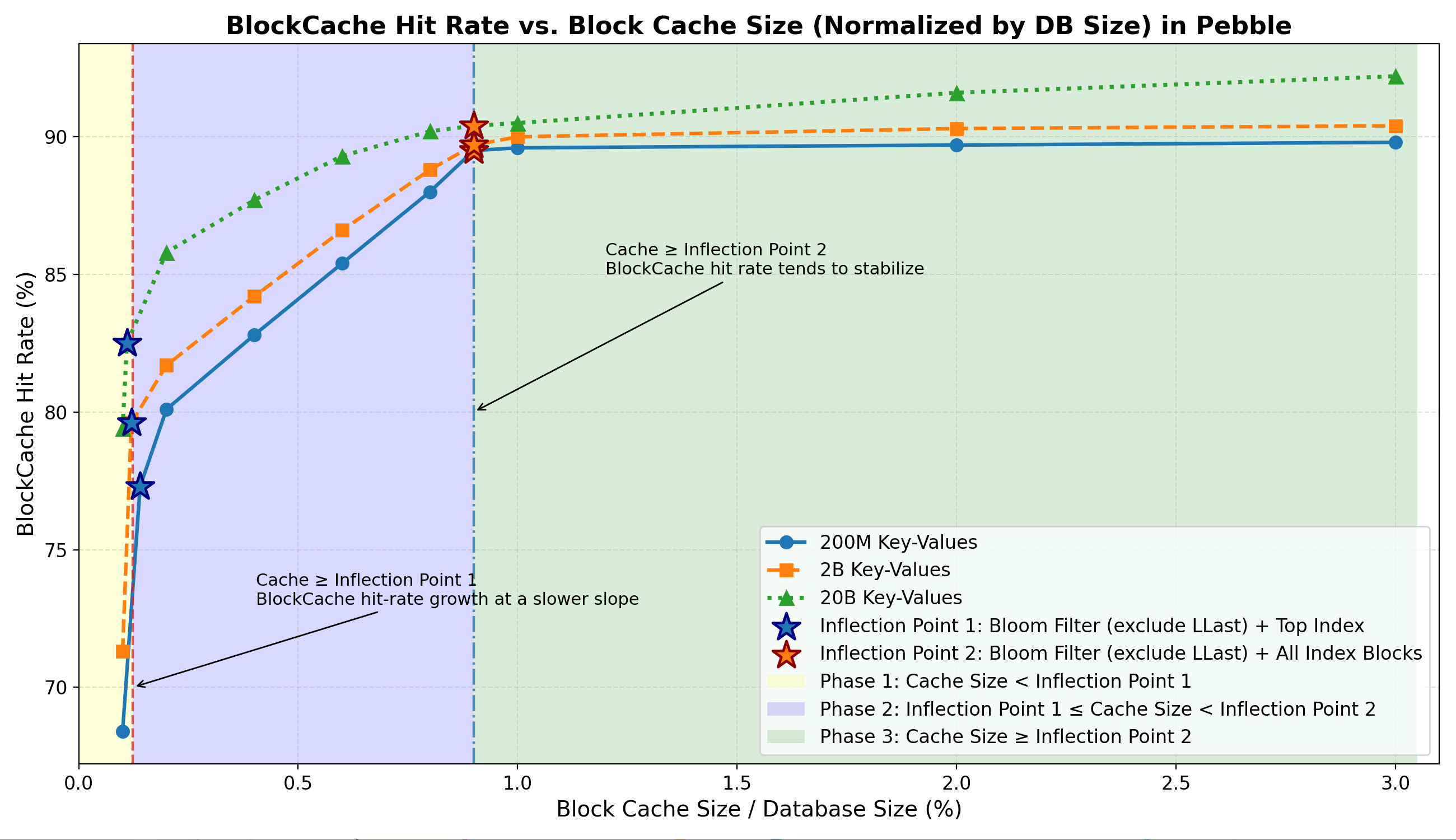
- 第一階段:命中率急劇上升,這是由於布隆過濾器和頂級索引在內存中的快速駐留所致。
- 第二階段:由於索引塊駐留,命中率增長速度放緩。
- 第三階段:命中率趨於穩定,因為在隨機讀取工作負載下,數據塊緩存的貢獻很小。
每次獲取的讀取 I/O 成本(關鍵結果)
本節總結了不同元數據組件的緩存駐留最終如何轉化為端到端隨機讀取 I/O 成本。
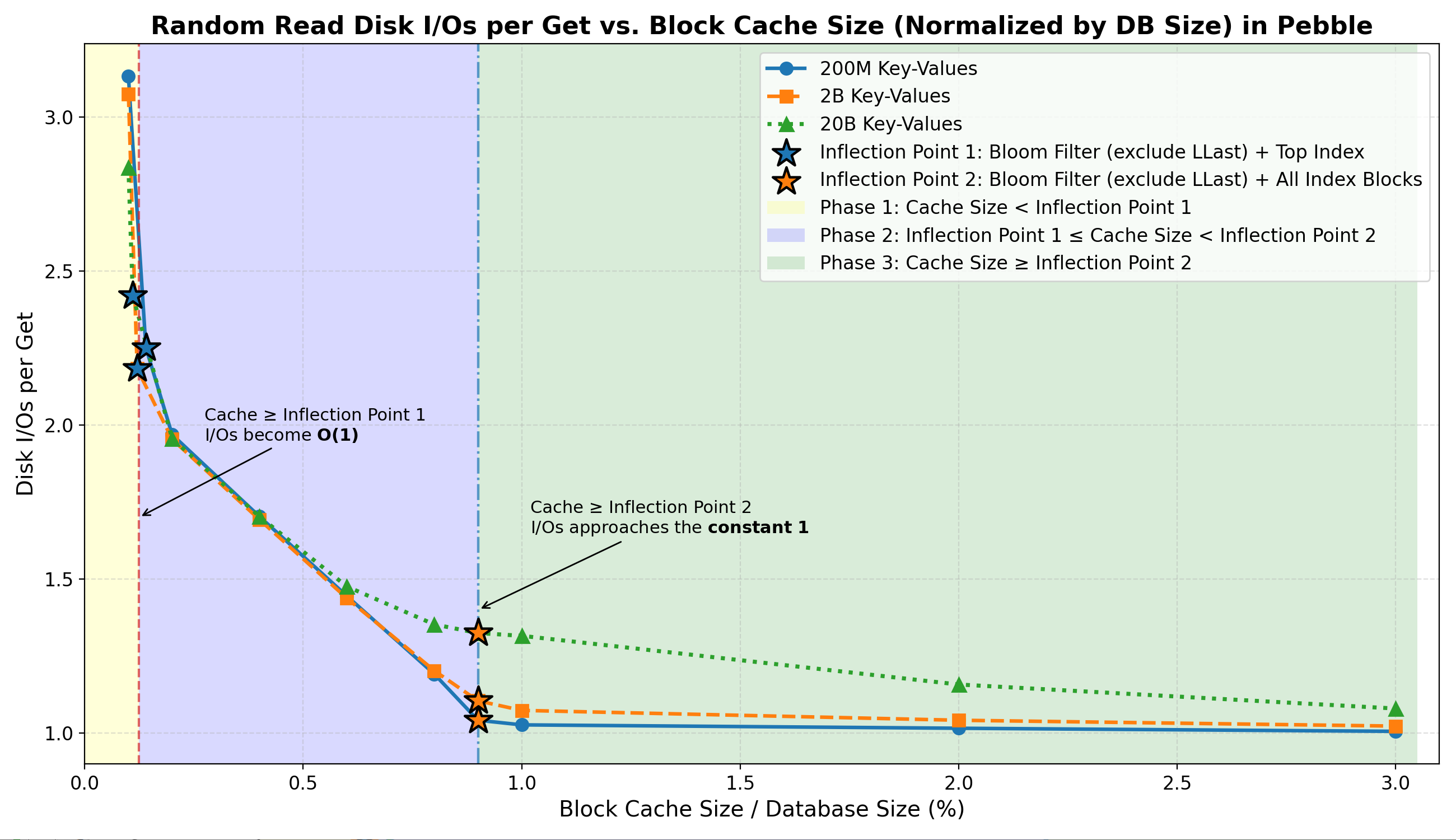
- 拐點 1(
Filter + Top-Index)
當緩存到達這一點時:- 篩選和熱門索引命中率達到~100% 。
- 大多數否定查詢完全在內存中完成。
-
I/Os per Get穩定在 ~2.2–2.4(有效 O(1) 查找)。
- 第二階段(兩個拐點之間)
在這個過渡區域:- 索引塊駐留率迅速增長,索引塊命中率急劇上升至約 70%–99% 。
- 每 Get 的 I/O 次數急劇下降至 1.0–1.3。
- 拐點 2(
Filter + All-Index)
再往後:-
I/Os per Get次數接近緊下限 ~1 。 - 進一步增加緩存容量只會帶來微乎其微的 I/O 減少。
-
- 在所有階段,數據塊緩存都微不足道。
- 不同數據集大小(22 GB – 2.2 TB)的行為一致:
這證實了:
總體而言,隨機讀取 I/O 主要受布隆過濾器和索引駐留的限制。
結論與建議
雖然 Pebble 的理論最壞情況讀取複雜度為O(log N) ,但在實際的緩存配置下,這一界限在實踐中很少能觀察到。
如果布隆過濾器(不包括 LLast)和索引塊有足夠的緩存駐留時間,Pebble 的實際讀取 I/O 行為實際上是 O(1) ,並且每次 Get 操作都會穩定地收斂到 1-2 次 I/O 。
緩存配置建議
我們的結果表明,Pebble 的讀取 I/O 開銷主要取決於哪些元數據組件適合緩存,而不是 LSM 樹的深度。因此,在實踐中,可以直接根據所需的讀取性能來選擇緩存大小。
讀取性能接近恆定(每次 Get 操作約 2 次 I/O)
緩存超過拐點 1 (布隆過濾器排除 LLast + Top-Index 塊)。
這隻需要一個很小的緩存(通常小於數據庫大小的 0.2% ),並消除了大部分否定查找 I/O。
適用於內存受限且需要可預測讀取性能的部署環境。接近單次 I/O 讀取(每次 Get 操作約 1.0–1.3 次 I/O)
緩存超過拐點 2 (布隆過濾器 + 所有索引塊)。
這隻需要一個較小的緩存(通常小於數據庫大小的 1.5% ),並且使讀取次數接近實際的下限。
適用於對延遲要求嚴格的執行層和讀取密集型工作負載。
超過拐點 2後,在隨機讀取工作負載下,進一步增加緩存大小只能提供微乎其微的 I/O 減少。






