

抽象的
我們希望通過按需採樣方法,而不是像 Celestia、SPAR 或 Peer/Full DAS 等主流 DAS 方法那樣從固定編碼集中採樣,來推動無速率編碼(特別是隨機線性網絡編碼 (RLNC))的使用,從而提高採樣效率。
為什麼選擇固定費率代碼?
最初使用編碼進行分佈式感知系統 (DAS) 的動機是,在匿名性條件下,從未編碼數據中採樣只能線性降低假陰性概率(驗證者錯誤地認為數據可用,即使實際上不可用),其降低速度與採樣數量呈線性關係,即從k未編碼數據塊中抽取 s 個樣本,其關係式為1 - s/k 。然而,如果我們應用例如(n,k) RS 編碼,則s採樣(不放回)的假陰性概率下降速度將超過(k-1/n)^s
通過無速率編碼提高採樣效率
通過採用固定速率編碼,驗證器(輕客戶端)本質上只能從預先編碼的n符號集中進行採樣。觀察上述從固定速率編碼數據中採樣的漏檢概率,自然會產生一個問題:為什麼不盡可能增大n值,以便即使樣本數量較少,漏檢概率也足夠低呢?這樣做存在一些缺點,包括:
這裡使用的碼通常是像 RS 碼這樣的碼,它們對
n的大小以及(n,k)的可能組合都有固有的限制。數據生產者的存儲和計算成本會隨著將採樣數據分發到保管節點(例如 PeerDAS)的帶寬成本的增加而無意中增加。
解決此問題的自然方案是按需生成樣本,以避免存儲和分發瓶頸。這自然而然地引導我們考慮無速率碼,因為在n趨於無窮大的極限情況下,無速率碼可以被視為最大距離可分 (MDS) 碼。RLNC 就是這樣一種無速率碼,它通過對原始數據進行隨機線性組合來構建編碼包。
按需採樣(例如從 RLNC 編碼)的假陰性概率為(1/q)^s其中q表示編碼係數域的基數。本文對其中一種協議進行了完整描述:《從索引到編碼: 數據可用性採樣的新範式》。
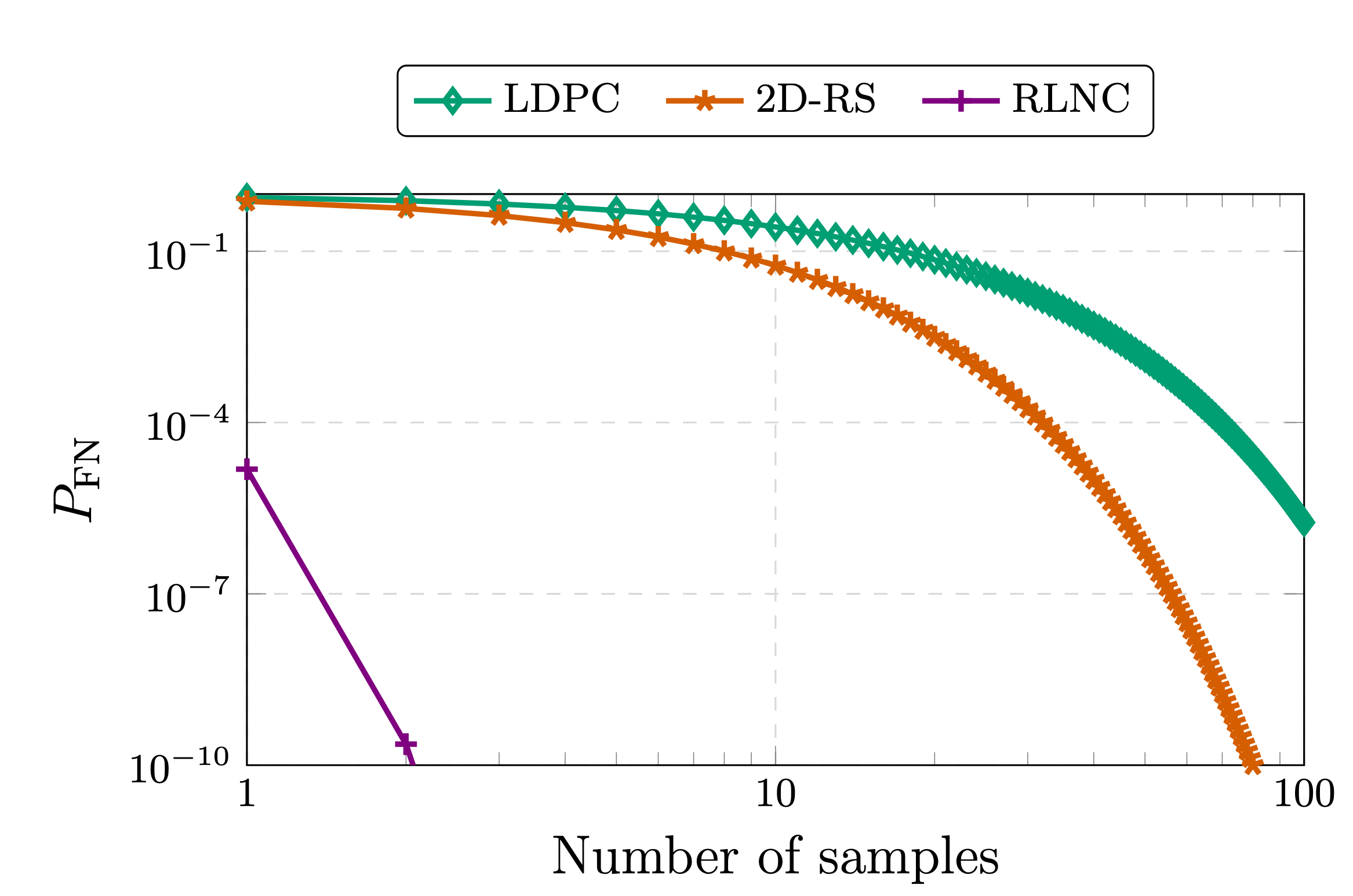
從編碼數據中採樣時出現假陰性(未檢測到底層有效載荷的不可解碼性)的概率(參見[1],[2])。
真正去中心化的潛力
固定速率編碼數據的另一個缺點是樣本是獨立的,這會導致修復過程成本高昂。例如,對於 PeerDAS 中使用的 1D RS 碼,由於 RS 碼局部性較差,丟失 RS 編碼數據塊中的單個單元格需要下載相當於整個數據塊的數據才能重建數據。引入張量碼後情況會有所改善,但像 RLNC 這樣的非結構化編碼也可以提供更去中心化的分佈式託管方案。
@Nashatyrev提出了一種使用 RLNC的去中心化託管協議,該協議在修復帶寬以及傳播和存儲開銷方面表現出良好的特性。
參考
[1] Al-Bassam, Mustafa 等。“欺詐和數據可用性證明:檢測輕客戶端中的無效區塊。”國際金融密碼學和數據安全會議。柏林,海德堡:Springer Berlin Heidelberg,2021 年。
[2] Yu, Mingchao 等。“編碼默克爾樹:解決區塊鏈中的數據可用性攻擊。”國際金融密碼學與數據安全會議。Cham:Springer International Publishing,2020。





