以下報告旨在收集數據,希望這些數據能夠幫助 ACD 就 EIP-7907 做出決定。
此外,這有望建立一種新的方法,即用盡可能多的數據來支持 EIP 或提案,這肯定有助於在確定分支範圍時做出更好、更明智的決策。
我要感謝@rjl493456442提交的 PR,他在 Geth 中添加了相關指標,並在基準測試數據收集過程中提供了極大的幫助和建議。我希望最終能將這些指標標準化,以便在所有客戶端中通用,方便我們輕鬆比較和收集數據,從而為重新定價和擴展規模的決策提供依據。
相關問題:** EIP-7907
日期: 2026年1月13日
基準測試環境: Geth(開發模式),數據庫規模與主網相同(約 2400 萬個區塊),內部緩存已禁用。
測試配置:每個區塊約 18,106 次 EXTCODESIZE 操作(所有字節碼合約均不同),約 50M gas
硬件: WD Black SN850X NVMe (8TB)
執行摘要
本報告分析了在禁用 Geth 內部代碼緩存的情況下,讀取不同字節碼大小(0.5KB 至 64KB)合約時EXTCODESIZE操作碼的性能。這代表了最壞情況下的攻擊場景,攻擊者部署數千個不同的合約來強制執行冷磁盤讀取。
該迭代還具有最低的開銷,從而避免了CREATE2確定性地址生成的問題。
更多相關信息請參見:
- 新增功能:為部署 EXTCODESIZE 基準合約添加 extcodesize_setup 場景,作者:CPerezz · Pull Request #161 · ethpandaops/spamoor · GitHub
- feat(benchmark): 添加 EXTCODESIZE 字節碼大小基準測試,用於冷訪問測試,作者:CPerezz · Pull Request #1961 · ethereum/execution-specs · GitHub
主要發現
| 尋找 | 價值 |
|---|---|
| 代碼讀取時間範圍 | 107毫秒 - 904毫秒(約18000次代碼讀取) |
| 每次通話延遲範圍 | 5.9微秒 - 49.9微秒 |
| 代碼讀取時間縮放 | 增長8.5倍(0.5KB → 64KB) |
| 64KB 數據塊執行時間 | 約1006毫秒 |
| 代碼讀取佔塊時間的百分比 | 51% (0.5KB) → 90% (64KB) |
| Geth 效率對比原始 NVMe | 24-51% |
EIP-7907 裁決
| 尺寸 | 塊時間 | 1秒預算的百分比 | 判決 |
|---|---|---|---|
| 24KB(當前) | 535毫秒 | 54% | 安全的 |
| 32KB | 685毫秒 | 69% | 安全的 |
| 64KB | 1006毫秒 | 約100% | 在60M氣體條件下可行 |
| 128KB+ | 預計1.5秒以上 | 100%以上 | 可能需要重新調整天然氣價格。在 BALs 和 ePBS 之後,我們需要更多數據。 |
建議:將新的最大合約大小設定為 64KB。超過 64KB 則需要在 BAL 和 ePBS 的優化功能部署到所有客戶端後重新收集數據。
如果在上述數據收集之後需要重新定價,則此類定價還需要能夠對其他客戶進行基準測試,並參考其他EXTCODE*操作碼。
1. 方法論與基準測試設置
1.1 測試環境
| 範圍 | 價值 |
|---|---|
| Geth 版本 | v1.16.8-不穩定版(包含大量修改) |
| 數據庫 | 主網已同步(約2400萬個區塊) |
| Geth 緩存 | 已禁用(強制磁盤讀取) |
| 合同規模測試 | 0.5、1、2、5、10、24、32、64 KB |
| EXTCODESIZE 操作 | 每塊約 18,106 個 |
| 每塊氣體 | 約5000萬 |
| 已部署合同 | 每種規模的合同超過 18,100 份。 |
| 每個尺寸的迭代次數 | 8 |
| 硬件 | WD Black SN850X NVMe 8TB |
1.2 攻擊場景設計
此基準測試代表了針對EXTCODESIZE最壞情況攻擊:
- 每個規模部署超過 18,100 個獨特的合約(導致代碼緩存未命中)
- 每個區塊都會從所有唯一合約中讀取字節碼,且讀取次數不得少於一次。
- 代碼緩存命中率:<2%(實際上已禁用)
- 基準測試運行之間清除操作系統頁面緩存
1.3 原始磁盤基線 (fio)
為了確定理論上的最大性能,我們測量了NVMe的原始性能:
| 塊大小 | IOPS | 吞吐量 | 平均延遲 |
|---|---|---|---|
| 512B | 337K | 172 MB/s | 95 微秒 |
| 1KB | 320K | 328 MB/s | 100 微秒 |
| 4KB | 272K | 1.1 GB/s | 117 微秒 |
| 24KB | 171K | 4.2 GB/s | 185 微秒 |
| 32KB | 155K | 5.1 GB/s | 204 微秒 |
| 64KB | 85K | 5.6 GB/s | 366 微秒 |
2. 基準測試結果
2.1 代碼讀取時間與字節碼大小
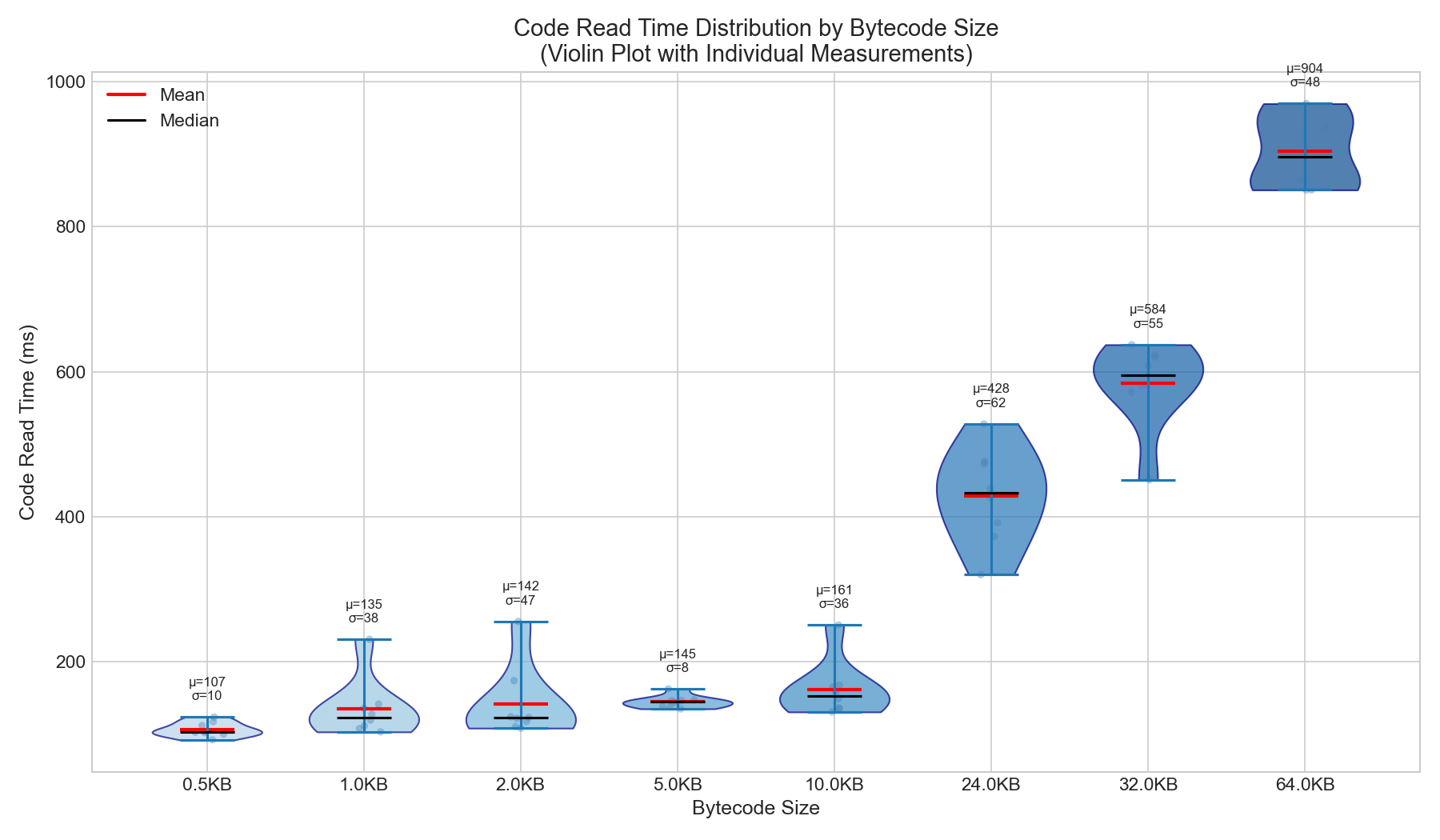
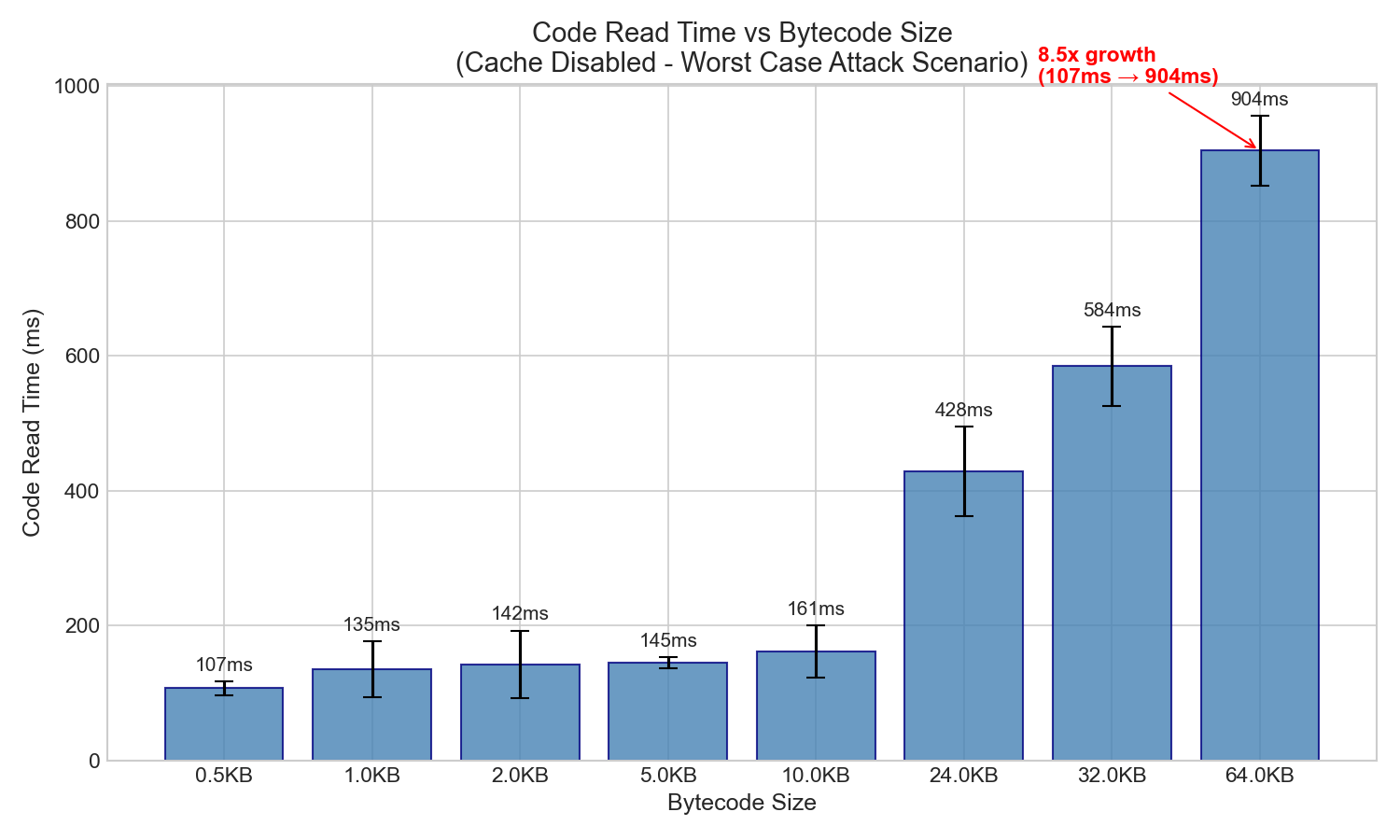
核心發現:當緩存無效時,代碼讀取時間與字節碼大小成正比。
| 尺寸 | 代碼讀取時間(毫秒) | 增長量(相對於 0.5KB) |
|---|---|---|
| 0.5KB | 107毫秒 | 1.0倍(基線) |
| 1KB | 135毫秒 | 1.3倍 |
| 2KB | 142毫秒 | 1.3倍 |
| 5KB | 145毫秒 | 1.4倍 |
| 10KB | 161毫秒 | 1.5倍 |
| 24KB | 428毫秒 | 4.0x |
| 32KB | 584毫秒 | 5.5倍 |
| 64KB | 904毫秒 | 8.5倍 |
關鍵發現:字節碼大小增長 128 倍時,代碼讀取時間增長 8.5 倍。這是亞線性增長(並非 1:1),但絕對時間影響非常顯著。
2.2 字節讀取時間與代碼讀取時間(相關性)
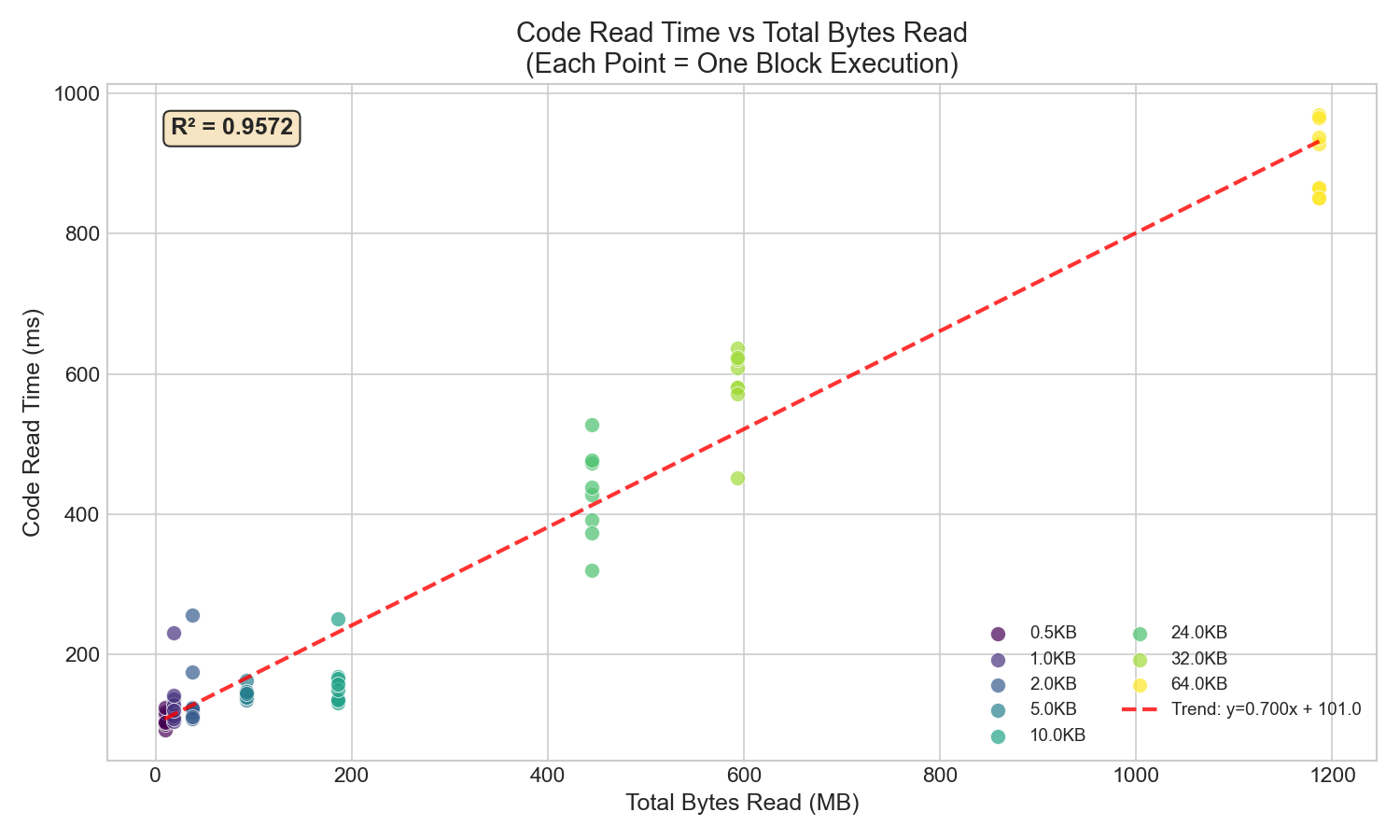
強正相關性(R² ≈ 0.96)證實,當緩存無效時,代碼讀取時間與讀取的總字節數成正比。
2.3 每次呼叫延遲
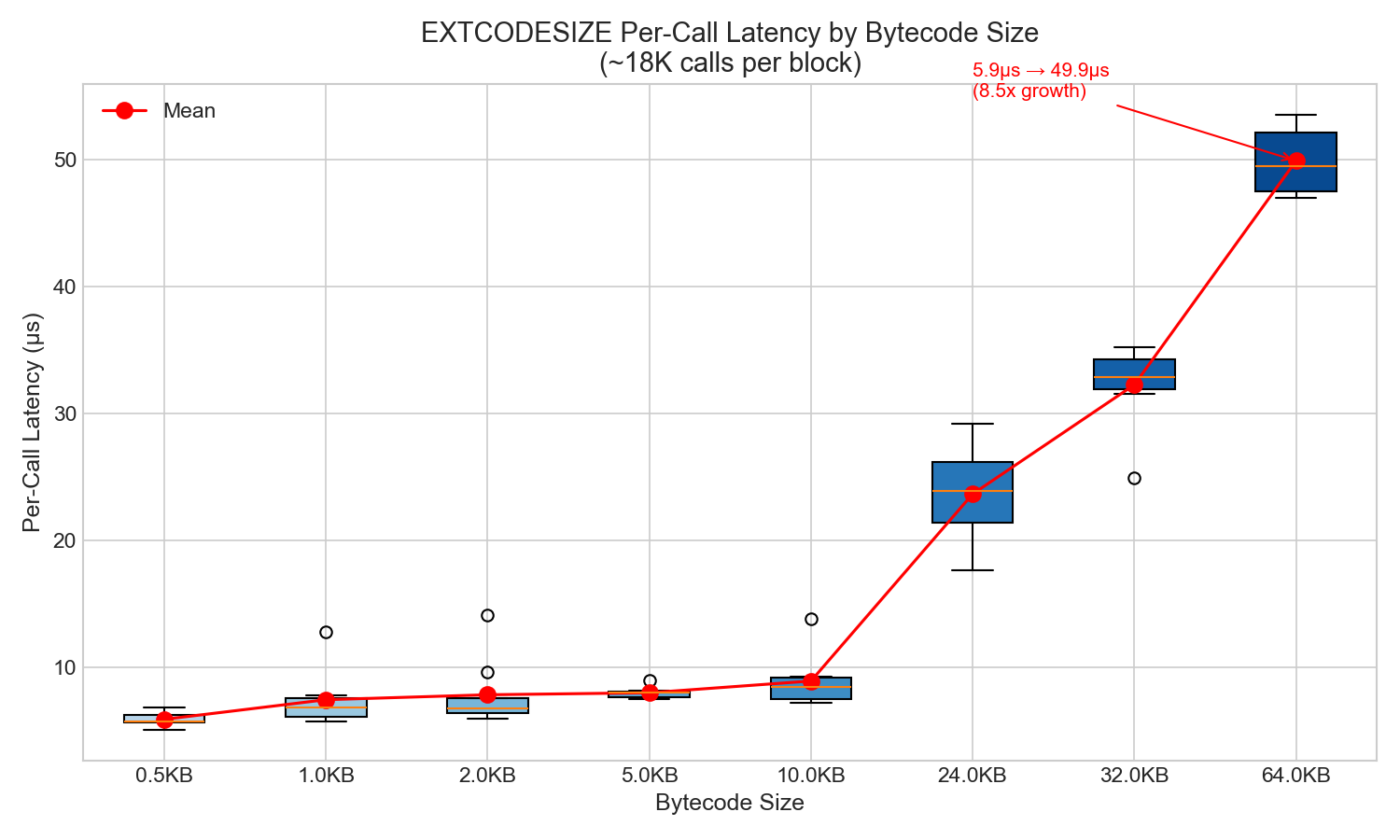
每次調用延遲隨字節碼大小的增加而增加:
| 尺寸 | 每次呼叫延遲 | 生長 |
|---|---|---|
| 0.5KB | 5.9 微秒 | 1.0x |
| 1KB | 7.5 微秒 | 1.3倍 |
| 10KB | 8.9 微秒 | 1.5倍 |
| 24KB | 23.7 微秒 | 4.0x |
| 32KB | 32.3 微秒 | 5.5倍 |
| 64KB | 49.9 微秒 | 8.5倍 |
3. 執行時間細分
3.1 成分分析
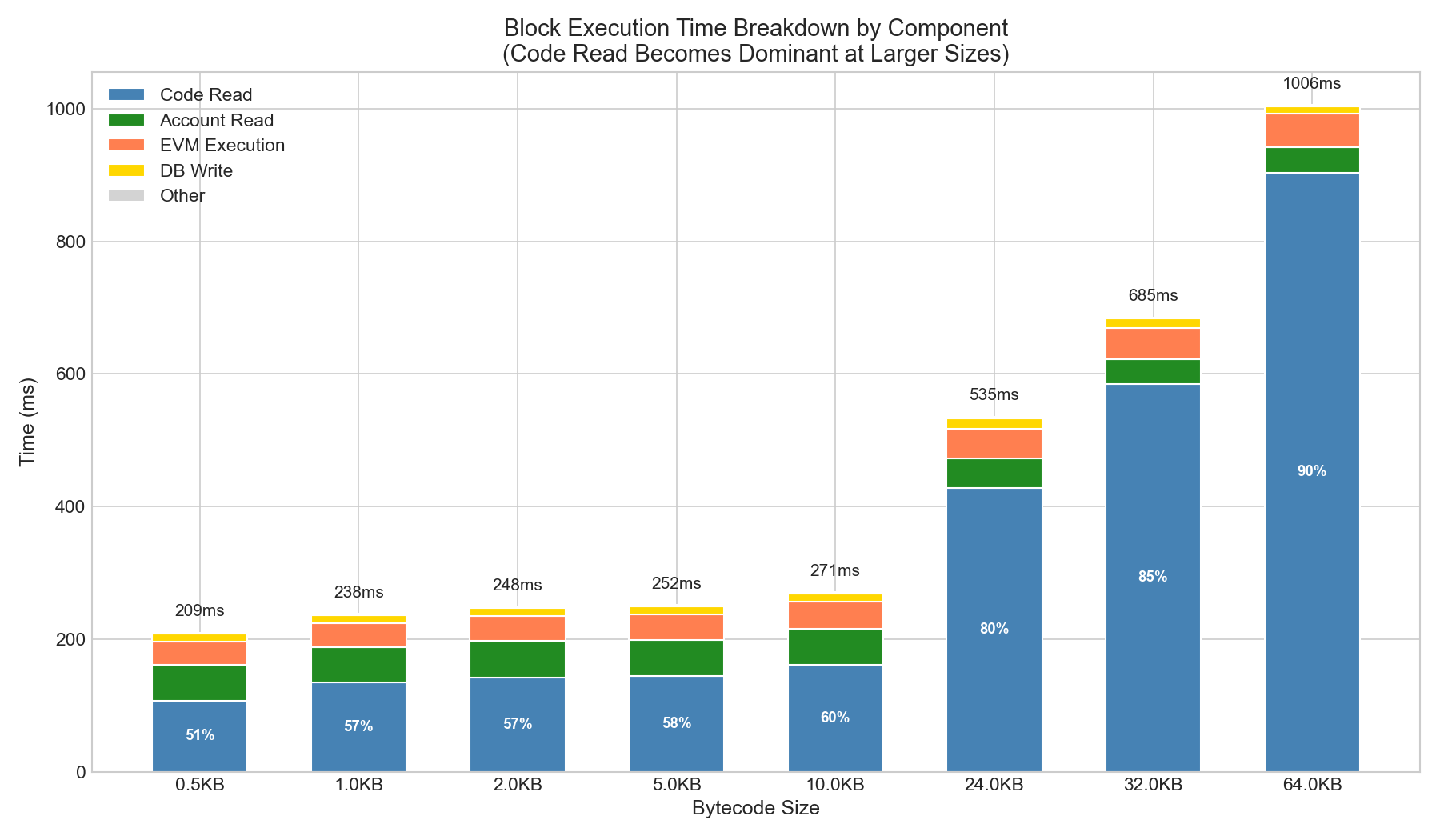
字節碼尺寸較大時,代碼讀取量成為主要因素:
| 尺寸 | 代碼讀取 | 賬戶讀取 | EVM執行 | 數據庫寫入 | 其他 | 全部的 |
|---|---|---|---|---|---|---|
| 0.5KB | 107毫秒(51%) | 54毫秒 | 34毫秒 | 12毫秒 | 2毫秒 | 209毫秒 |
| 1KB | 135毫秒(57%) | 53毫秒 | 37毫秒 | 12毫秒 | 1毫秒 | 238毫秒 |
| 10KB | 161毫秒(59%) | 53毫秒 | 40毫秒 | 12毫秒 | 5毫秒 | 271毫秒 |
| 24KB | 428毫秒(80%) | 44毫秒 | 46毫秒 | 15毫秒 | 2毫秒 | 535毫秒 |
| 32KB | 584毫秒(85%) | 38毫秒 | 47毫秒 | 13毫秒 | 3毫秒 | 685毫秒 |
| 64KB | 904毫秒(90%) | 38毫秒 | 51毫秒 | 12毫秒 | 1毫秒 | 1006毫秒 |
觀察:在 64KB 緩存大小下,代碼讀取消耗了 90% 的塊執行時間。這與熱緩存場景下代碼讀取僅佔 8-10% 的情況截然不同。
4. 時間塊預算分析(EIP-7907 重點)
4.1 時間與預算目標
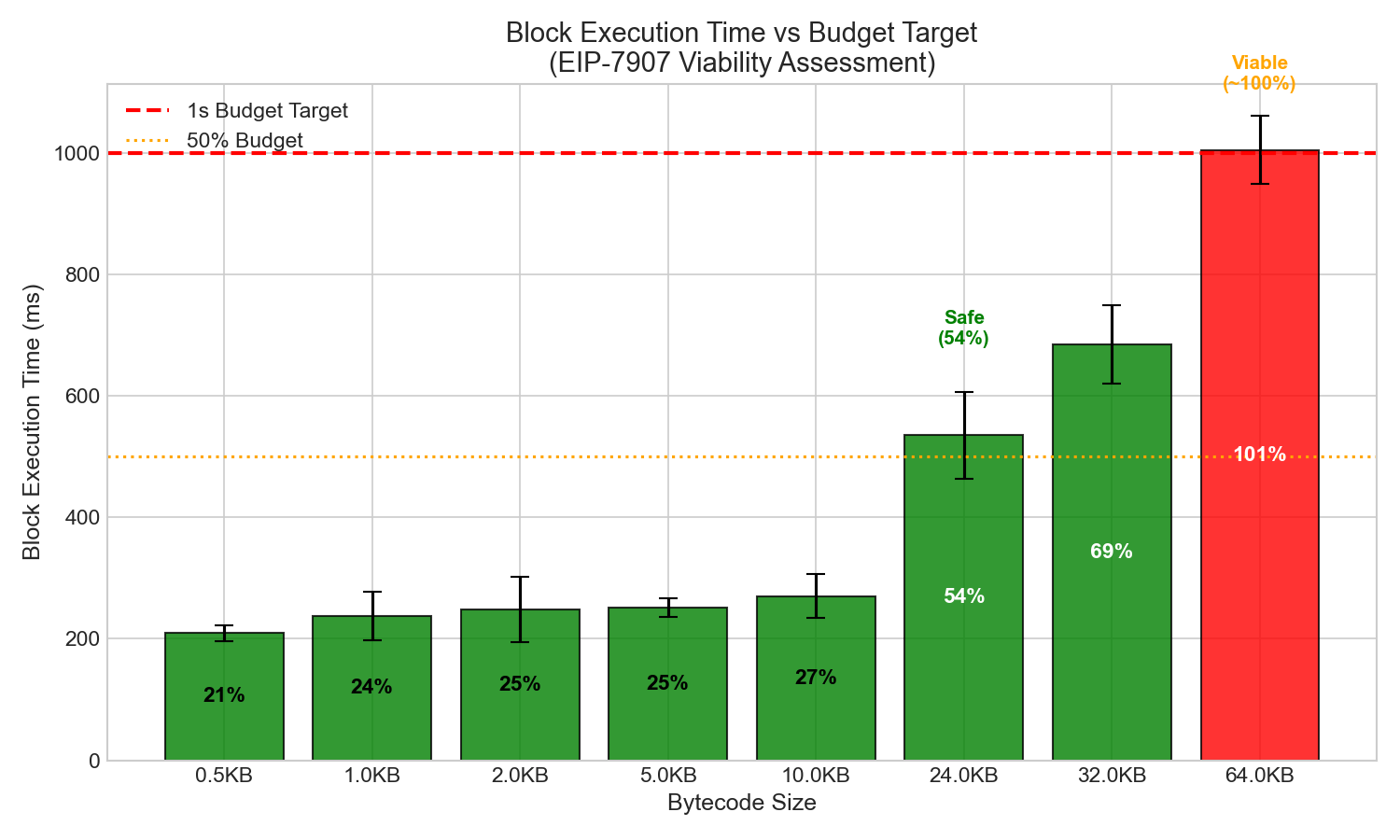
使用 1 秒作為區塊執行目標:
| 尺寸 | 塊時間 | 1秒預算的百分比 | 地位 |
|---|---|---|---|
| 0.5KB | 209毫秒 | 21% | 遠低於預算 |
| 1KB | 238毫秒 | 24% | 遠低於預算 |
| 2KB | 248毫秒 | 25% | 遠低於預算 |
| 5KB | 252毫秒 | 25% | 遠低於預算 |
| 10KB | 271毫秒 | 27% | 遠低於預算 |
| 24KB | 535毫秒 | 54% | 預算內 |
| 32KB | 685毫秒 | 69% | 預算內 |
| 64KB | 1006毫秒 | 約100% | 極限 |
結論:在6000萬gas區塊的最壞攻擊條件下,64KB合約是可行的。約1秒的執行時間雖然接近預算極限,但尚可接受。需要注意的是,考慮到ePBS和BAL很可能在不久的將來改變我們對安全預算的定義,這個極限相當保守。
4.2 天然氣處理率(定價錯誤分析)
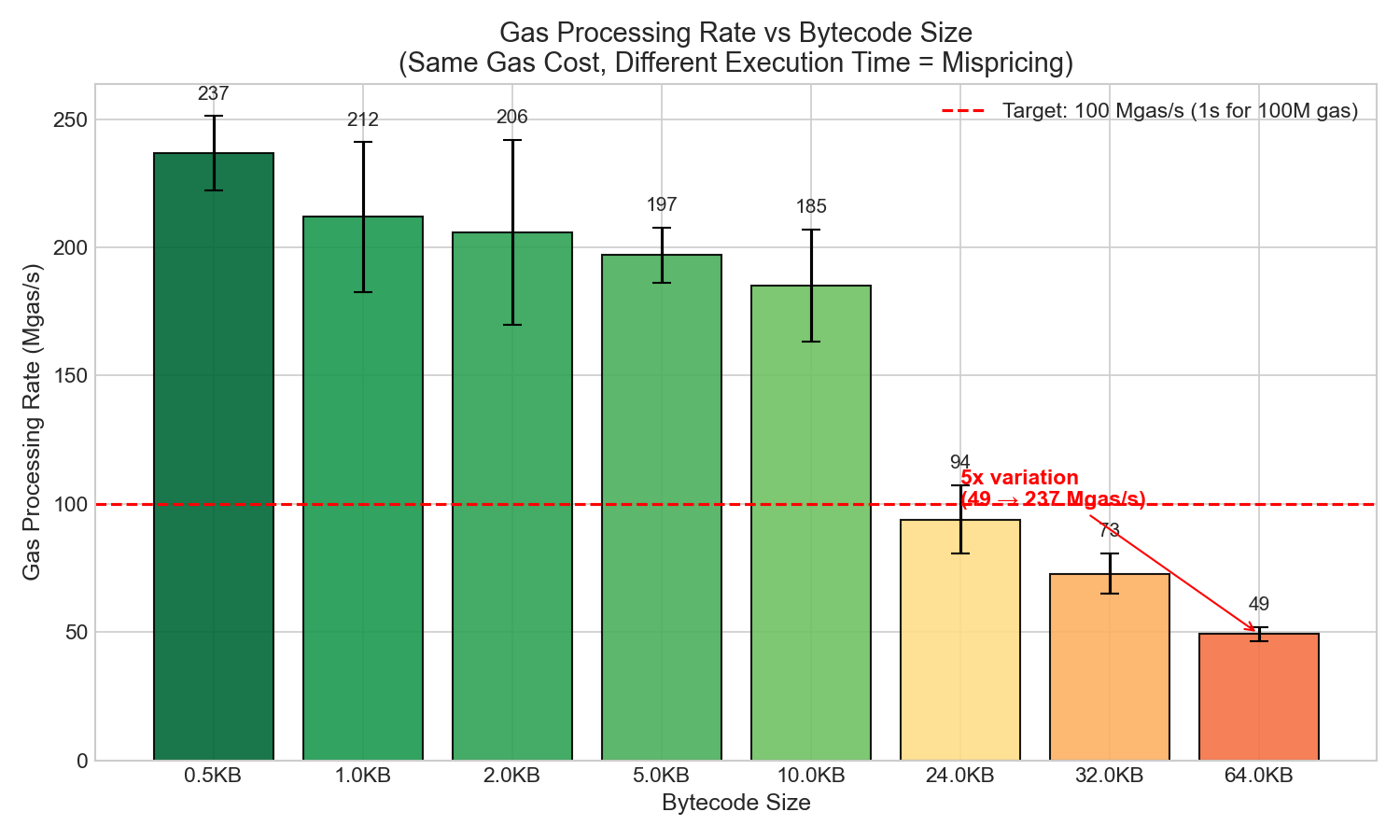
| 尺寸 | 燃氣使用 | 塊時間 | 兆氣體/秒 |
|---|---|---|---|
| 0.5KB | 4940萬 | 209毫秒 | 236 |
| 1KB | 4940萬 | 238毫秒 | 208 |
| 10KB | 4940萬 | 271毫秒 | 182 |
| 24KB | 4940萬 | 535毫秒 | 92 |
| 32KB | 4940萬 | 685毫秒 | 72 |
| 64KB | 4940萬 | 1006毫秒 | 49 |
發現定價錯誤: gas 成本相同,但執行時間卻相差 5 倍(236 Mgas/s → 49 Mgas/s)。這表明,在最壞情況下,規模更大的合約會給驗證者帶來不成比例的更高成本。
對 128KB 以上文件的影響:超過 64KB 後,需要對 gas 模型進行調整——可能是一個基本成本加上一個與大小相關的組件。
請注意,這還是相當保守的估計。因為要“癱瘓”網絡或“嚴重影響慢速驗證者”,所需的設置數量將是 18000 個獨立合約的數百倍。這將帶來巨大的成本(我們無法重複使用這些合約,因為它們會在第一個區塊執行後被緩存)。
5. 原始磁盤基準(Geth 與 NVMe 效率對比)
5.1 效率比較
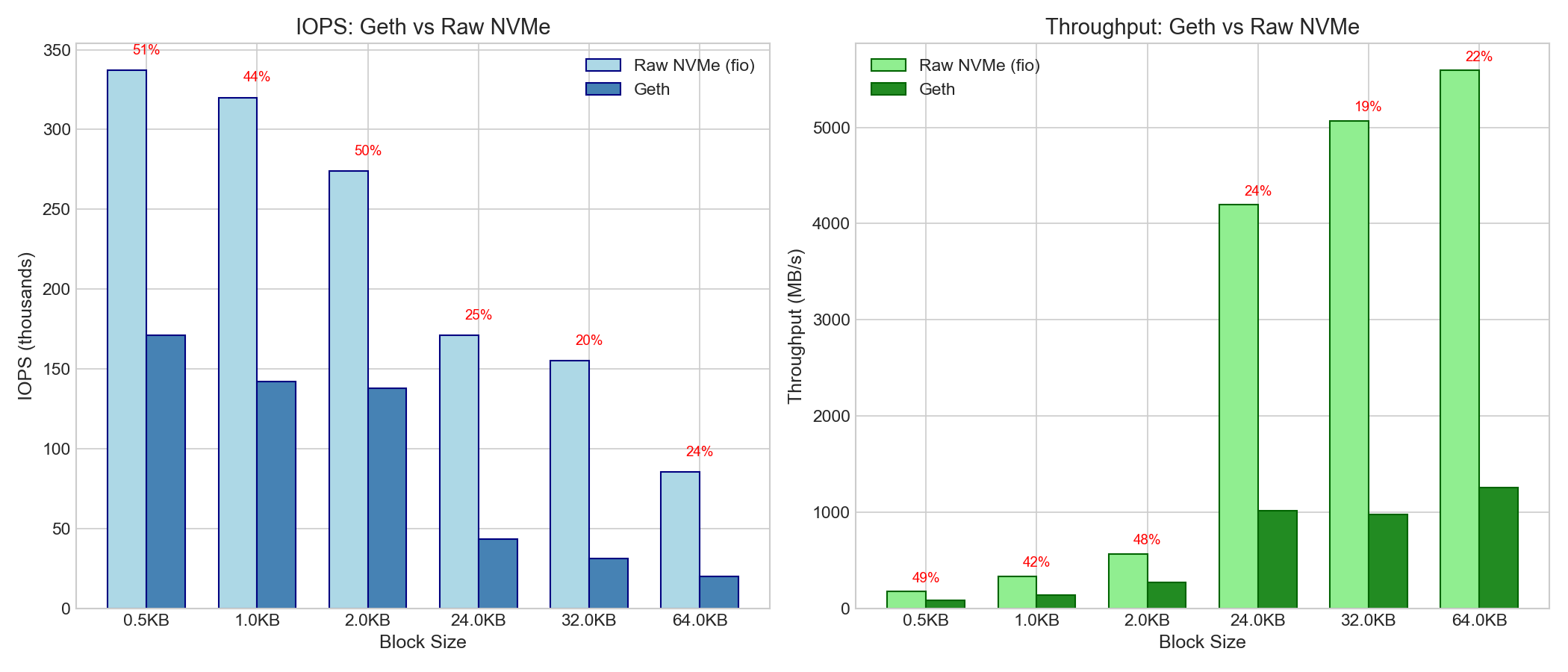
| 尺寸 | Geth IOPS | 原始 NVMe IOPS | 效率 | Geth 吞吐量 | 原始 NVMe | 效率 |
|---|---|---|---|---|---|---|
| 0.5KB | 171K | 337K | 51% | 83 MB/s | 172 MB/s | 48% |
| 1KB | 142K | 320K | 44% | 139 MB/s | 328 MB/s | 42% |
| 24KB | 43K | 171K | 25% | 1.0 GB/s | 4.2 GB/s | 24% |
| 32KB | 31K | 155K | 20% | 979 MB/s | 5.1 GB/s | 19% |
| 64KB | 2萬 | 85K | 24% | 1.26 GB/s | 5.6 GB/s | 23% |
觀察結果: Geth 僅能達到磁盤原始性能的 20% 至 51%。造成這種差距的原因可能是:
- Pebble/LevelDB 開銷(索引遍歷、布隆過濾器)
- 密鑰哈希和查找
- 值反序列化
6. 與熱緩存場景的比較
6.1 緩存與非緩存性能比較
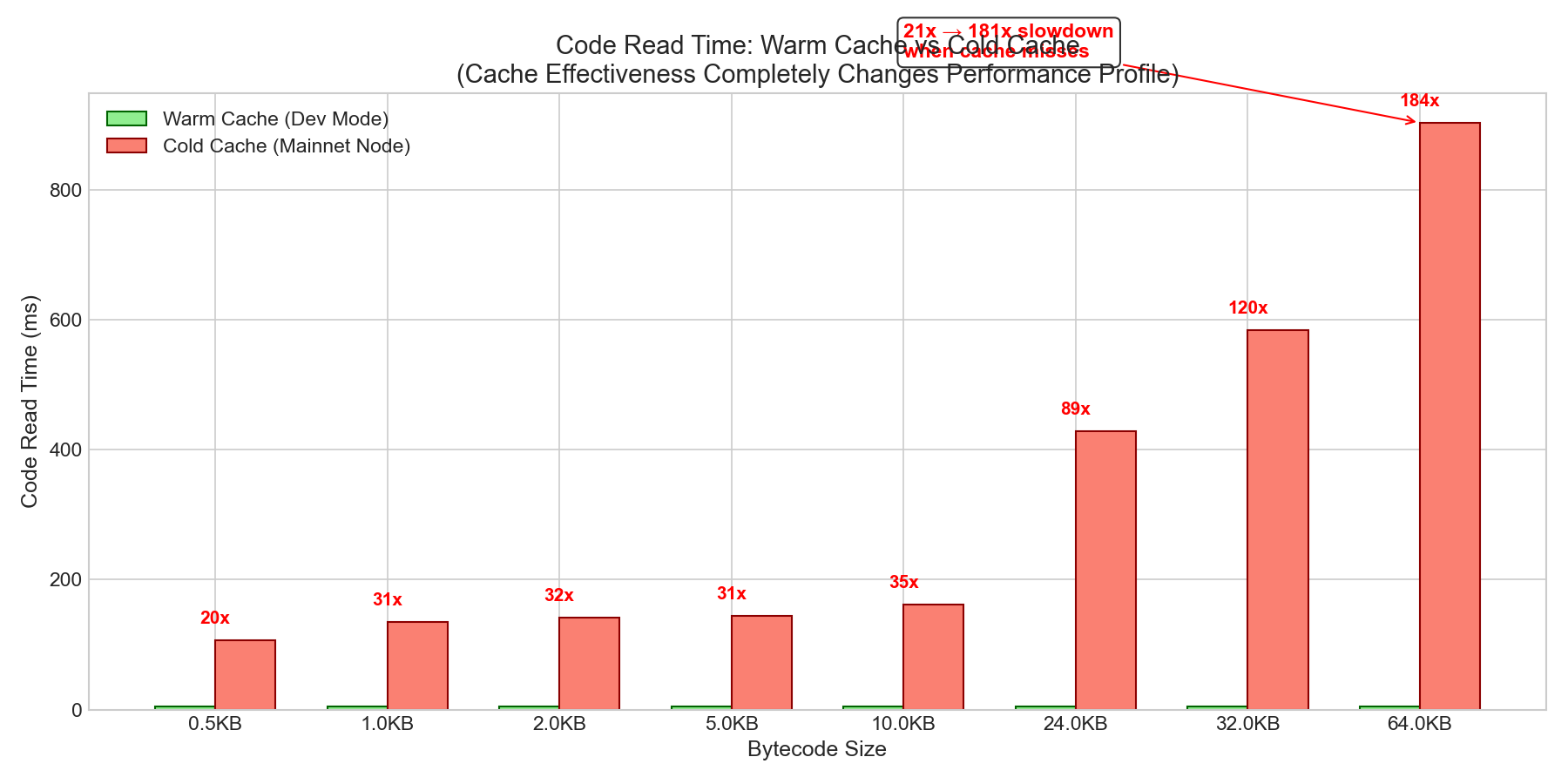
| 尺寸 | 暖緩存 | 冷緩存 | 減速 |
|---|---|---|---|
| 0.5KB | 5.3毫秒 | 107毫秒 | 21倍 |
| 1KB | 4.4毫秒 | 135毫秒 | 31倍 |
| 2KB | 4.5毫秒 | 142毫秒 | 32倍 |
| 5KB | 4.6毫秒 | 145毫秒 | 31倍 |
| 10KB | 4.7毫秒 | 161毫秒 | 34倍 |
| 24KB | 4.8毫秒 | 428毫秒 | 89倍 |
| 32KB | 4.9毫秒 | 584毫秒 | 119x |
| 64KB | 4.9毫秒 | 904毫秒 | 181倍 |
在正常操作情況下,基於熱緩存基準測試得出的“固定成本”結論仍然有效。冷緩存條件則需要極端攻擊場景(超過 18,000 個獨立合約)。
7. 對 EIP-7907 的影響及建議
7.1 研究結果總結
- 在攻擊條件下,代碼讀取時間隨代碼大小而增加(從 0.5KB 到 64KB 增加到 8.5 倍)。
- 64KB 的數據在 6000 萬個 gas 塊的情況下是可行的——最壞情況下執行時間約為 1 秒,在預算範圍內。
- 這代表了最糟糕的情況——部署和維護 18000 多個獨特的合約是不切實際的(每次要運行攻擊的區塊都需要一個新的合約集)。
- 正常運行不受影響——熱緩存場景下開銷約為 5 毫秒。
- Gas定價錯誤問題正受到攻擊(相同gas的執行時間差異可達5倍)
7.2 EIP-7907 建議
| 行動 | 推薦 |
|---|---|
| 64KB限制 | 繼續執行——在最壞情況下的攻擊下仍然可行。無需 EIP。 |
| 128KB+限制 | 需要使用支氣管肺泡灌洗液 (BAL) 和電子磷酸鹽緩衝液 (ePBS) 進行重新測量。 |
看來我們可以“保持簡單”,在不改變協議本身的情況下,為智能合約開發者提供代碼大小限制方面的良好升級,除了 64kB 的限制和 initcode 大小的增加之外。
一旦 BAL 和 ePBS 達到更完善的狀態,我們將能夠利用數據更好地指導我們做出關於重新定價/直接進入 256kB 的良好決策。
但即使在最糟糕的情況下,這東西也並不需要重新定價,所以現在重新定價似乎沒有必要。
7.3 為什麼 64KB 是可以接受的
攻擊不切實際:部署超過 18000 個唯一的 64KB 合約需要:
- 每個合約部署約需 1300 萬 gas(3.2 萬基礎 gas + 6.4 萬 gas × 200 gas/字節)
- 僅設置階段就需要數百個模塊。
- 維護攻擊面需要持續投入大量成本
阻塞時間在預算範圍內:即使最壞情況下約 1 秒,對於 6000 萬個 gas 塊來說也是可以接受的。
緩存實際有效性:主主網區塊會複用合約;代碼緩存命中率通常很高。
亞線性擴展:規模增長 128 倍所需時間僅為 8.5 倍,這表明攤銷仍然有效。